http://www.cnblogs.com/LBSer/p/4417074.html
1 背景
以商家(Poi)維度來展示各種服務(比如團購(deal)、直連)正變得越來越流行(圖1a), 比如目前美食、酒店等品類在移動端將團購資訊列表改為POI列表頁展示。
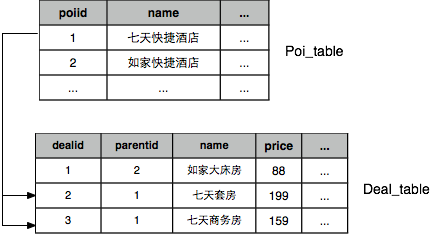
圖1 a:商家維度展示資訊; b:join示意
這給篩選帶來了複雜性。之前的篩選是平面的,如篩選poi列表時僅僅利用到poi的屬性(如評價、品類等),篩選deal列表時也僅僅根據deal的屬性(房態、價格等)。而現在的篩選是具有層次關係的,我們需要根據deal的屬性來篩選Poi,舉個例子,我們需要篩選酒店列表,這些酒店必須要有價格在100~200之間的團購。
這種篩選本質是種join操作,其核心是要將poi與deal關聯起來。從資料庫視角上看(圖1 b),我們有poi表以及deal表,deal表儲存了外來鍵(parentid)用於指示該deal所屬的poi,上述篩選分為三步:1)先篩選出價格區間在100~200的deal(得到dealid為2和3的deal);2)找出deal對應的poi(得到poiid為1和1的poi);3)去重,因為可能多個deal對應同一個poi,而我們需要返回不重複poi。
目前我們使用lucene來提供篩選服務,那麼lucene如何解決這種帶有join的篩選呢?
2 lucene join解決方案
在我們應用中,一個poi儲存為一個document,一個deal也儲存為一個document,Join的核心在於將poi以及deal的document進行關聯。lucene提供了兩種join的方式,分別是query time join和index time join,下文將分別展開。
2.1. query time join
query time join是通過類似資料庫“外來鍵“方法來建立deal和poi document的關聯關係。
a)索引
分別建立poi的document和deal的document,在建立deal document的時候用一個欄位(parentid)將deal與poi關聯起來,本例中建立了parentid這個field,裡面存的是該deal對應的poiid,可以簡單將其看做外來鍵。
public static Document createPoiDocument(PoiMsg poiMsg) {
Document document = new Document();
document.add(new StringField("poiid", String.valueOf(poiMsg.getId()), Field.Store.YES));
document.add(new StringField("name", poiMsg.getName(), Field.Store.YES));
return document;
}
public static Document createDealDocument(DealModel dealModel, PoiMsg poiMsg) {
Document document = new Document();
document.add(new StringField("did", String.valueOf(dealModel.getDid()), Field.Store.YES));
document.add(new StringField("name", dealModel.getBrandName(), Field.Store.YES));
document.add(new DoubleField("price", dealModel.getPrice(), Field.Store.YES));
document.add(new StringField("parentid", String.valueOf(poiMsg.getId()), Field.Store.YES));
return document;
}
IndexWriter writer = new IndexWriter(directory, config); writer.addDocument(createPoiDocument(poiMsg1)); writer.addDocument(createPoiDocument(poiMsg2)); writer.addDocument(createDealDocument(dealModel1, poiMsg2)); writer.addDocument(createDealDocument(dealModel2, poiMsg1)); writer.addDocument(createDealDocument(dealModel3, poiMsg1));
b)查詢
需查詢兩次:首先查詢deal document,之後通過deal中的parentId查詢poi document。
1)第一次查詢發生在JoinUtil.createJoinQuery中。首先建立了TermsCollector這個收集器, 該收集器將滿足fromQuery的doc的parentid欄位收集起來,之後建立了TermsQuery。
本例執行之後TermsCollector集合裡有兩個terms,分別是”1”和”1”;
2)執行TermsQuery,查詢toField在TermsCollector terms集合中存在的doc,最後找出toField為“1”的doc。
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
String fromFields = "parentid";
Query fromQuery = NumericRangeQuery.newIntRange("price", 100, 200, false, false);
String toFields = "poiid";
Query toQuery = JoinUtil.createJoinQuery(fromFields, false, toFields, fromQuery, indexSearcher, ScoreMode.Max);
TopDocs results = indexSearcher.search(toQuery, 10);
JoinUtil.createJoinQuery程式碼 TermsCollector termsCollector = TermsCollector.create(fromField, multipleValuesPerDocument); fromSearcher.search(fromQuery, termsCollector); return new TermsQuery(toField, fromQuery, termsCollector.getCollectorTerms());
c)優缺點
query time join優點是非常直觀且靈活;缺點是不能進行打分排序,此外由於查詢兩遍效能會下降。
2.2. index time join
query time join通過顯式的在deal document上增加一個“外來鍵”來建立關係,找到deal之後需要找出這些deal document的parentid集合,之後再次查詢找出poiId在parentid集合內的poi document。在找到deal之後如果能馬上找到對應的poi document,那將大大提高效率。index time join乾的就是這樣的事情,其通過一種精巧的方法建立了deal document id和poi document id的對映關係。
a)原理
如何通過一個deal document id來找到poi document id?
在lucene中,doc id是自增的,每寫入一個document,doc id加1(簡單起見可以理解)。 index time join要求寫索引的時候要按先後關係寫入,先寫子document,再寫父document。比如我們有poi1和poi2兩個poi,其中poi1下有deal2和deal3,而poi2下只有deal1,這時需要先寫入deal2、deal3,再寫入deal2和deal3對應的poi1 document,依次類推,最後形成如圖2所示的結構。
這樣索引建立之後,我們得到了父document的id集合(3,5)。當我們根據deal的屬性查出deal document id時,比如我們查出滿足條件的deal是deal3,其document id=2,這時候只需要到父document id集合裡去查詢第一個比2大的id,在本例中馬上就找到3。

圖2
lucene自己實現了BitSet來儲存id,lucene內部實現程式碼如圖3所示。
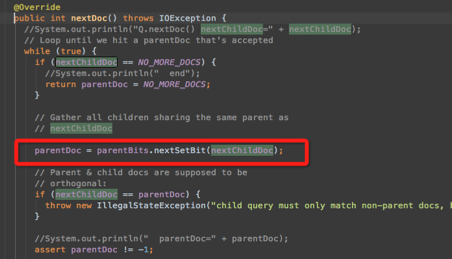
圖3 實現原理
b)索引
從上述原理得知我們需要建立有層次關係的索引。
首先建立document陣列,該陣列有個特點, 最後一個必須是poi,之前都是deal。然後呼叫writer.addDocument(documents); 將這個陣列寫入。
public static Document createPoiDocument(PoiMsg poiMsg) {
Document document = new Document();
document.add(new StringField("poiid", String.valueOf(poiMsg.getId()), Field.Store.YES));
document.add(new StringField("name", poiMsg.getName(), Field.Store.YES));
document.add(new StringField("doctype", "poi", Field.Store.YES));
return document;
}
public static Document createDealDocument(DealModel dealModel) {
Document document = new Document();
document.add(new StringField("did", String.valueOf(dealModel.getDid()), Field.Store.YES));
document.add(new StringField("name", dealModel.getBrandName(), Field.Store.YES));
document.add(new DoubleField("price", dealModel.getPrice(), Field.Store.YES));
return document;
}
IndexWriter writer = new IndexWriter(directory, config); List<Document> documents = new ArrayList<Document>(); documents.add(createDealDocument(dealModel2)); documents.add(createDealDocument(dealModel3)); documents.add(createPoiDocument(poiMsg1)); writer.addDocument(documents); documents.clear(); documents.add(createDealDocument(dealModel1)); documents.add(createPoiDocument(poiMsg2)); writer.addDocument(documents);
c)查詢
Filter poiFilter = new CachingWrapperFilter(new QueryWrapperFilter(new TermQuery(new Term(PoiLuceneField.ATTR_DOCTYPE, "poi")))); //篩選出poi
ToParentBlockJoinQuery query = new ToParentBlockJoinQuery(dealQuery, poiFilter, ScoreMode.Max);
ToParentBlockJoinCollector collector = new ToParentBlockJoinCollector(
sort, // sort
(getOffset() + getLimit()), // poi分頁numHits
true, // trackScores
false // trackMaxScore
);
collector = (ToParentBlockJoinCollector) indexSearcher.search(query, collector);
Sort childSort = new Sort(new SortField(DealLuceneField.ATTR_PRICE, SortField.Type.DOUBLE));
TopGroups hits = collector.getTopGroups(
query.getToParentBlockJoinQuery(),
childSort,
query.getOffset(), // parent doc offset
100, // maxDocsPerGroup
0, // withinGroupOffset
true // fillSortFields
);
3 實踐
官方文件顯示index time join效率更高,比query time join快30%以上。因此我們在專案中使用了index time join方式,目前服務執行良好。
檢索實踐文章系列: