http://www.cnblogs.com/LBSer/p/4068864.html
隨著業務快速發展,基於lucene的索引檔案zip壓縮後也接近了GB量級,而保持索引檔案大小為一個可以接受的範圍非常有必要,不僅可以提高索引傳輸、讀取速度,還能提高索引cache效率(lucene開啟索引檔案的時候往往會進行快取,比如MMapDirectory通過記憶體對映方式進行快取)。
如何降低我們的索引檔案大小呢?本文進行了一些嘗試,下文將一一介紹。
1 數值資料型別索引優化
1.1 數值型別索引問題
lucene本質上是一個全文檢索引擎而非傳統的資料庫系統,它基於倒排索引,非常適合處理文字,而處理數值型別卻不是強項。
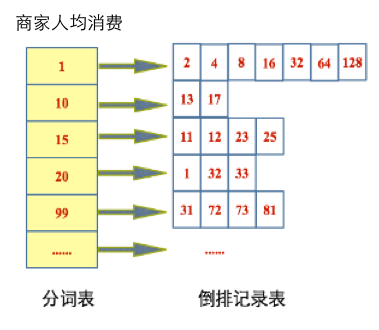
舉個應用場景,假設我們倒排儲存的是商家,每個商家都有人均消費,使用者想查詢範圍在500~1000這一價格區間內的商家。
一種簡單直接的想法就是,將商家人均消費當做字串寫入倒排(如圖所示),在進行區間查詢時:1)遍歷價格分詞表,將落在此區間範圍內的倒排id記錄表找出來;2)合併倒排id記錄表。這裡兩個步驟都存在效能問題:1)遍歷價格分詞表,比較暴力,而且通過term查詢倒排id記錄表次數過多,效能非常差,在lucene裡查詢次數過多,可能會丟擲Too Many Boolean Clause的Exception。2)合併倒排id記錄表非常耗時,說白了這些倒排id記錄表都在磁碟裡。
當然還有種思路就是將其數字長度補齊,假設所有商家的人均消費在[0,10000]這一區間內,我們儲存1時寫到倒排裡就是00001(補齊為5位),由於分詞表會按照字串排序好,因此我們不必遍歷價格分詞表,通過二分查詢能快速找到在某一區間範圍內的倒排id記錄表,但這裡同樣未能解決查詢次數過多、合併倒排id記錄表次數過多的問題。此外怎樣補齊也是問題,補齊太多浪費空間,補齊太少儲存不了太大範圍值。
1.2 lucene解決方法
為解決這一問題, Schindler和 Diepenbroek提出了基於trie的解決方法,此方法08年發表在 Computers & Geosciences (地理資訊科學sci期刊,影響因子1.9),也被lucene 2.9之後版本採用。( Schindler, U, Diepenbroek, M, 2008. Generic XML-based Framework for Metadata Portals. Computers & Geosciences 34 (12),論文:http://epic.awi.de/17813/1/Sch2007br.pdf)
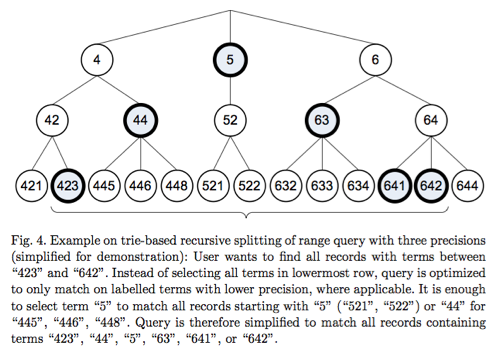
簡單來說,整數423不是直接寫入倒排,而是分割成幾段寫入倒排,以十進位制分割為例,423將被分割為423、42、4這三個term寫入, 本質上這些term形成了trie樹(如圖所示)。
如何查詢呢?假設我們要查詢[422, 642]這一區間範圍的doc,首先在樹的最底層找到第一個比422大的值,即423,之後查詢423的右兄弟節點,發現沒有便找其父節點的右兄弟(找到44),對於642也是,找其左兄弟節點(641),之後找父節點的左兄弟(63),一直找到兩者的公共節點,最終找出423、44、5、63、641、642這6個term即可。通過這種方法,原先需要查詢423、445、446、448、521、522、632、633、634、641、642這11次term對應的倒排id列表,併合並這11個term對應的倒排id列表,現在僅需要查詢423、44、5、63、641、642這6個term對應的倒排id列表併合並,大大降低了查詢次數以及合併次數,尤其是查詢區間範圍較大時效果更為明顯。
這種優化方法本質上是一種以空間換時間的方法,可以看到term數目將增大許多。
在實際操作中,lucene將數字轉換成2進位制來處理,而且實際上這顆trie樹也無需儲存資料結構,傳統trie一個節點會有指向孩子節點的指標, 同時會有指向父節點的指標,而在這裡只要知道一個節點,其父節點、右兄弟節點都可以通過計算得到。此外lucene也提供了precisionstep這一欄位用於設定分割長度,預設情況下int、double、float等數字型別precisionstep為4,就是按4位二進位制進行分割。precisionstep長度設定得越短,分割的term越多,大範圍查詢速度也越快,precisionstep設定得越長,極端情況下設定為無窮大,那麼不會進行trie分割,範圍查詢也沒有優化效果,precisionstep長度需要結合自身業務進行優化。
1.3 索引檔案大小優化方案
我們的應用中很多field都是數值型別,比如id、avescore(評價分)、price(價格)等等,但是用於區間範圍查詢的數值型別非常少,大部分都是直接查詢或者為進行排序使用。
因此優化方法非常簡單,將不需要使用範圍查詢的數字欄位設定precisionstep為Intger.max,這樣數字寫入倒排僅存一個term,能極大降低term數量。
1 public final class CustomFieldType { 2 public static final FieldType INT_TYPE_NOT_STORED_NO_TIRE = new FieldType(); 3 static { 4 INT_TYPE_NOT_STORED_NO_TIRE.setIndexed(true); 5 INT_TYPE_NOT_STORED_NO_TIRE.setTokenized(true); 6 INT_TYPE_NOT_STORED_NO_TIRE.setOmitNorms(true); 7 INT_TYPE_NOT_STORED_NO_TIRE.setIndexOptions(FieldInfo.IndexOptions.DOCS_ONLY); 8 INT_TYPE_NOT_STORED_NO_TIRE.setNumericType(FieldType.NumericType.INT); 9 INT_TYPE_NOT_STORED_NO_TIRE.setNumericPrecisionStep(Integer.MAX_VALUE); 10 INT_TYPE_NOT_STORED_NO_TIRE.freeze(); 11 } 12 }
doc.add(new IntField("price", price, CustomFieldType.INT_TYPE_NOT_STORED_NO_TIRE));//人均消費
1.4 效果
優化之後效果明顯,索引壓縮包大小直接減少了一倍。
2 空間資料型別索引優化
.1 地理資料索引問題
還是一樣的話,lucene基於倒排索引,非常適合文字,而對於空間型別資料卻不是強項。
舉個應用場景,每一個商家都有唯一的經緯度座標(x, y),使用者想篩選附近5千米的商家。
一種直觀的想法是將經度x、維度y分別當做兩個數值型別欄位寫到倒排裡,然後查詢的時候遍歷所有的商家,計算與使用者的距離,並保留小於5千米的商家。這種方法缺點很明顯:1)需要遍歷所有的商家,非常暴力;2)此外球面距離計算非涉及到大量的三角函式計算,效率較低(博主研發了一種快速距離計算方法,能提高至少10倍計算速度:地理空間距離計算優化)。
簡單的優化方法使用矩形框對這些商家進行過濾,之後對過濾後的商家進行距離計算,保留小於5千米的商家,這種方法儘管極大降低了計算量,但還是需要遍歷所有的商家。

2.2 lucene解決方法
lucene採用geohash的方法對經緯度進行編碼(geohash介紹參見:GeoHash)。簡單描述下,geohash對空間不斷進行劃分並對每一個劃分子空間進行編碼,比如我們整個北京地區被編碼為“w”,那麼再對北京一分為4,某一子空間編碼為“WX”,對“WX”子空間再進行劃分,對各個子空間再進行標識,例如“WX4”(簡單可以這麼理解)。
那麼一個經緯度(x,y)怎樣寫入到倒排索引呢?假設某一經緯度落在“WX4”子空間內,那麼經緯度將以“W”、“WX”、“WX4”這三個term寫入到倒排。
如何進行附近查詢呢?首先將我們附近5km劃分一個個格子,每個格子有geohash的編碼,將這些編碼當做查詢term,去倒排查詢即可,比如附近5km的geohash格子對應的編碼是“WX4”,那麼直接就能將落在此空間範圍的商家找出。

2.3 索引檔案大小優化方案
上述方法本質上也是一種以空間換時間的方法,比如一個經緯度(x,y),只有兩個欄位,但是以geohash進行編碼將產生許多term並寫入倒排。
lucene預設最長的geohash長度為24,也就是一個經緯度將以24個字串的形式來寫入到倒排中。最初採用的geohash長度為11,但實際上針對我們的需求,geohash長度為9的時候已經足夠滿足我們的需求(geohash長度為9大約代表了5*4米的格子)。
下表表示geohash長度對應的精度,摘自維基百科:http://en.wikipedia.org/wiki/Geohash
|
geohash length
|
lat bits
|
lng bits
|
lat error
|
lng error
|
km error
|
|---|---|---|---|---|---|
| 1 | 2 | 3 | ±23 | ±23 | ±2500 |
| 2 | 5 | 5 | ± 2.8 | ± 5.6 | ±630 |
| 3 | 7 | 8 | ± 0.70 | ± 0.7 | ±78 |
| 4 | 10 | 10 | ± 0.087 | ± 0.18 | ±20 |
| 5 | 12 | 13 | ± 0.022 | ± 0.022 | ±2.4 |
| 6 | 15 | 15 | ± 0.0027 | ± 0.0055 | ±0.61 |
| 7 | 17 | 18 | ±0.00068 | ±0.00068 | ±0.076 |
| 8 | 20 | 20 | ±0.000085 | ±0.00017 | ±0.019 |
1 private void spatialInit() { 2 this.ctx = SpatialContext.GEO; // 選擇geo表示經緯度座標,會按照球面計算距離,否則是平面歐式距離 3 int maxLevels = 9; // geohash長度為9表示5*5米的格子,長度過長會造成查詢匹配開銷 4 SpatialPrefixTree grid = new GeohashPrefixTree(ctx, maxLevels); // geohash字串匹配樹 5 this.strategy = new RecursivePrefixTreeStrategy(grid, "poi"); // 遞迴匹配 6 }
2.4 效果
此優化效果結果未做記錄,不過經緯度geohash編碼佔據了term數量的25%,而我們又將geohash長度從11減少到9(降低18%),相當於整個term數量降低了25%*18%=4.5%。
3 只索引不儲存
上面兩種方法本質上通過減少term數量來減少索引檔案大小,下面的方法走的是另一種方式。
從lucene查出一堆docid之後,需要通過docid找出相應的document,並找出裡面一些需要的欄位,例如id,人均消費等等,然後返回給客戶端。但實際上我們只需要獲取id,通過這些id再去請求DB/Cache獲取額外的欄位。
因此優化方法是隻儲存id等必須的欄位,對於大部分欄位我們只索引而不儲存,通過這種方法,索引壓縮檔案降低了10%左右。
1 doc.add(new StringField("price", each, Field.Store.NO));
4 小結
本文基於lucene的一些基礎原理以及自身業務,對索引檔案大小進行了優化,使得索引檔案大小下降了一半多。
檢索實踐文章系列: