python爬蟲爬取糗事百科
最近研究python爬蟲,按照網上資料實現了python爬蟲爬取糗事百科,做個筆記。
分享幾個學習python爬蟲資料:
廖雪峰python教程 主要講解python的基礎程式設計知識
python開發簡單爬蟲 通過一個例項講解python爬蟲的整體結構
python正規表示式 講解爬蟲中匹配中所需要的正規表示式
python爬蟲系列教程 幾個訓練的例項
簡單爬蟲的架構

爬蟲的執行流程
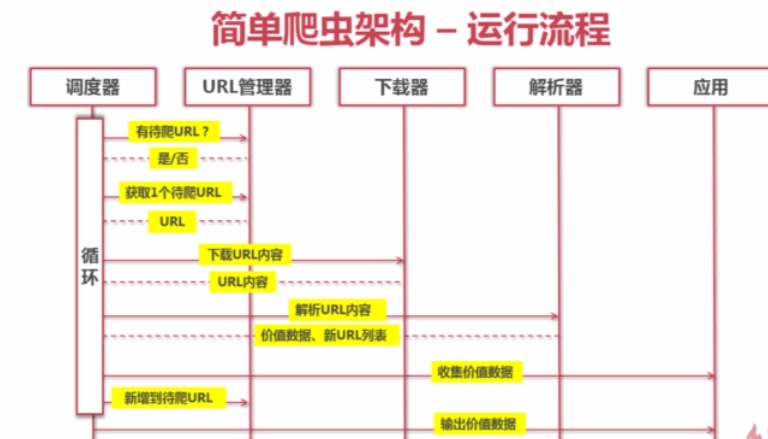
下面按照教程中的講解實現python爬蟲爬取糗事百科
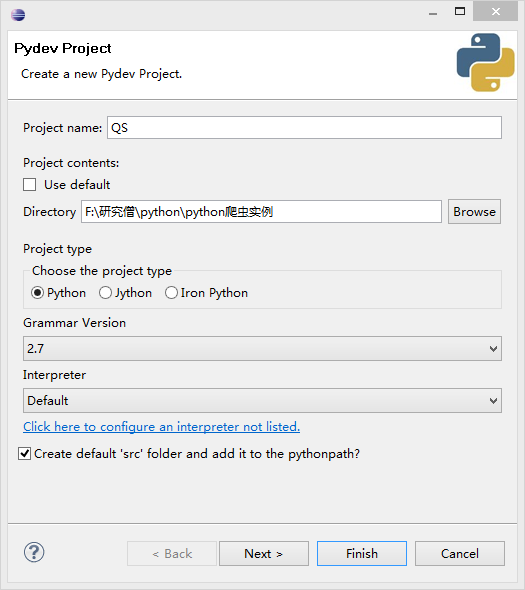
新建工程
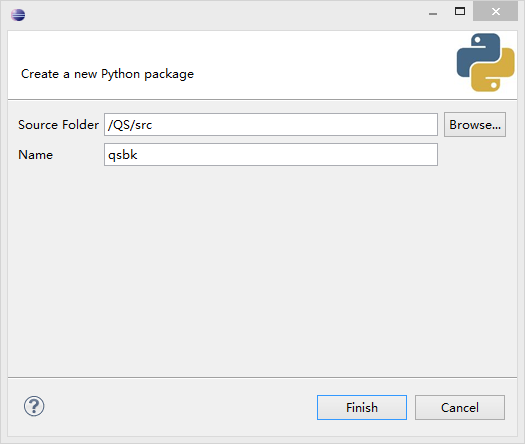
新建pydev package
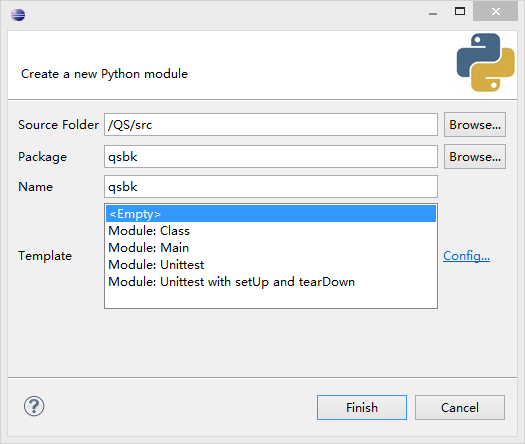
新建pydev module
編輯程式碼:
import urllib2
import re
class QSBK:
def __init__(self):
self.pageIndex =2
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
self.headers = { 'User-Agent' : self.user_agent }
self.stories = []
self.enable = False
def getPage(self,pageIndex):
try:
url = ' http://www.qiushibaike.com/hot/page/' + str(pageIndex)
request = urllib2.Request(url,headers = self.headers)
response = urllib2.urlopen(request)
pageCode = response.read().decode('utf-8')
return pageCode
except urllib2.URLError, e:
if hasattr(e,"reason"):
print u"連線糗事百科失敗,錯誤原因",e.reason
return None
def getPageItems(self,pageIndex):
pageCode = self.getPage(pageIndex)
if not pageCode:
print "頁面載入失敗...."
return None
pattern = re.compile(r'<div.*?class="author.*?>.*?<a.*?</a>.*?<a.*?>(.*?)</a>.*?<div.*?class'+
'="content".*?>(.*?)</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S)
items = re.findall(pattern,pageCode)
pageStories = []
for item in items:
replaceBR = re.compile('<br/>')
text = re.sub(replaceBR,"\n",item[1])
pageStories.append([item[0].strip(),text.strip(),item[2].strip(),item[3].strip()])
return pageStories
def loadPage(self):
if self.enable == True:
if len(self.stories) < 2:
pageStories = self.getPageItems(self.pageIndex)
if pageStories:
self.stories.append(pageStories)
self.pageIndex += 1
def getOneStory(self,pageStories,page):
for story in pageStories:
input = raw_input()
self.loadPage()
if input == "Q":
self.enable = False
return
print u"第%d頁\t釋出人:%s\t贊:%s\n%s" %(page,story[0],story[3],story[1])
def start(self):
print u"正在讀取糗事百科,按回車檢視新段子,Q退出"
self.enable = True
self.loadPage()
nowPage = 0
while self.enable:
if len(self.stories)>0:
pageStories = self.stories[0]
nowPage += 1
del self.stories[0]
self.getOneStory(pageStories,nowPage)
spider = QSBK()
spider.start()執行結果:

對於不同的網頁,請右鍵“審查元素”檢視網頁程式碼,修改一下正規表示式
相關文章
- python爬蟲十二:middlewares的使用,爬取糗事百科Python爬蟲
- python爬取糗事百科Python
- Python爬取糗事百科段子Python
- 網路爬蟲——專案實戰(爬取糗事百科所有文章)爬蟲
- python3.6.5 爬取糗事百科,開心一下Python
- python多執行緒爬去糗事百科Python執行緒
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- 【Python學習】爬蟲爬蟲爬蟲爬蟲~Python爬蟲
- python 爬蟲 爬取 learnku 精華文章Python爬蟲
- Python爬蟲入門教程 50-100 Python3爬蟲爬取VIP視訊-Python爬蟲6操作Python爬蟲
- python爬蟲——爬取大學排名資訊Python爬蟲
- Python爬蟲—爬取某網站圖片Python爬蟲網站
- python爬蟲--爬取鏈家租房資訊Python爬蟲
- python 爬蟲 1 爬取酷狗音樂Python爬蟲
- 【Python爬蟲】正則爬取趕集網Python爬蟲
- 使用python爬取百度百科Python
- Python爬蟲入門【5】:27270圖片爬取Python爬蟲
- Python 第一個爬蟲,爬取 147 小說Python爬蟲
- 小白學 Python 爬蟲(25):爬取股票資訊Python爬蟲
- 爬蟲——爬取貴陽房價(Python實現)爬蟲Python
- Python爬蟲:爬取instagram,破解js加密引數Python爬蟲JS加密
- python網路爬蟲--爬取淘寶聯盟Python爬蟲
- python例項,python網路爬蟲爬取大學排名!Python爬蟲
- 使用webmagic爬蟲對百度百科進行簡單的爬取Web爬蟲
- 爬蟲之股票定向爬取爬蟲
- python就是爬蟲嗎-python就是爬蟲嗎Python爬蟲
- Python爬蟲——批次爬取douyin影片,下載到本地Python爬蟲
- 用PYTHON爬蟲簡單爬取網路小說Python爬蟲
- Python爬蟲實踐--爬取網易雲音樂Python爬蟲
- Python爬蟲爬取淘寶,京東商品資訊Python爬蟲
- Python爬蟲實戰詳解:爬取圖片之家Python爬蟲
- python爬蟲學習01--電子書爬取Python爬蟲
- Python實現微博爬蟲,爬取新浪微博Python爬蟲
- Python爬蟲入門【9】:圖蟲網多執行緒爬取Python爬蟲執行緒
- python爬蟲如何獲取表情包Python爬蟲
- python 爬蟲Python爬蟲
- python爬蟲Python爬蟲
- Python爬蟲例項:爬取貓眼電影——破解字型反爬Python爬蟲
- 不會Python爬蟲?教你一個通用爬蟲思路輕鬆爬取網頁資料Python爬蟲網頁