一、什麼是Hive
Hive是建立在 Hadoop 上的資料倉儲基礎構架。它提供了一系列的工具,可以用來進行資料提取轉化載入(ETL),這是一種可以儲存、查詢和分析儲存在 Hadoop 中的大規模資料的機制。Hive 定義了簡單的類 SQL 查詢語言,稱為 HQL,它允許熟悉 SQL 的使用者查詢資料。同時,這個語言也允許熟悉 MapReduce 開發者的開發自定義的 mapper 和 reducer 來處理內建的 mapper 和 reducer 無法完成的複雜的分析工作。
二、Hive的體系結構
下圖一為官網提供的hive體系結構。
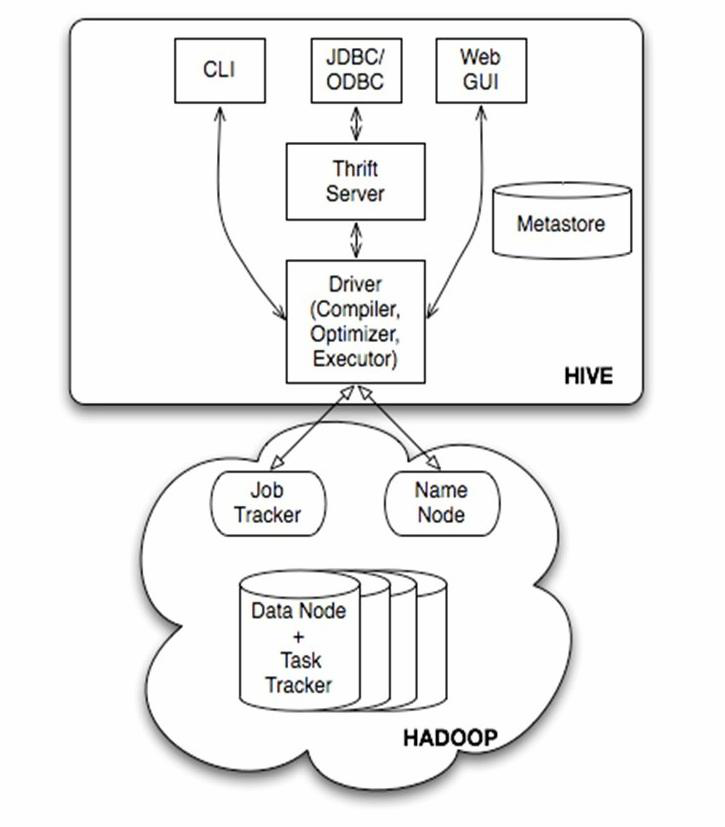
從體系結構上看,Hive是建立在 Hadoop 上的資料倉儲基礎構架。
1、hive的使用者介面為:CLI,Hiveserver,WebUI。
①CLI為命令列客戶端或者說是 命令列環境,客戶端可以直接在命令列模式下進行操作。
②Hiveserver支援jdbc/odbc方式,Hive提供了Thrift服務,Thrift客戶端目前支援C++/Java/PHP/Python/Ruby。
③webGUI介面,讓hive提供了更加直觀的web操作頁面。但是處理大量資料的時候,不推薦使用。
2、Metastore 後設資料儲存,儲存Hive所有的表與分割槽的結構化資訊,包括列與列型別資訊,序列化器與反序列化器,從而能夠讀寫hdfs中的資料。
有三種儲存方式。
①內嵌Derby方式
②Local方式
③Remote方式
關於三種儲存方式,會在以後的博文中詳細介紹。
3、Hadoop與Hive的關係
Hive是Hadoop的一個元件,作為資料廠庫,Hive的資料是儲存在Hadoop的檔案系統中的,hive為Hadoop提供SQL語句,是Hadoop可以通過SQL語句操作檔案系統中的資料。hive是依賴Hadoop而存在的。
在網上下載了一張圖片,很明瞭的介紹了他們之間的關係,如下圖:

三、Hive的安裝
1,開啟服務嚮導,選擇安裝Hive,在安裝Hive之前,請安裝好MapReduce。如下圖

2,首先我們會看到,我們會為hive選擇一組依賴關係。

3,自定義分配角色,根據實際情況,去分配角色。
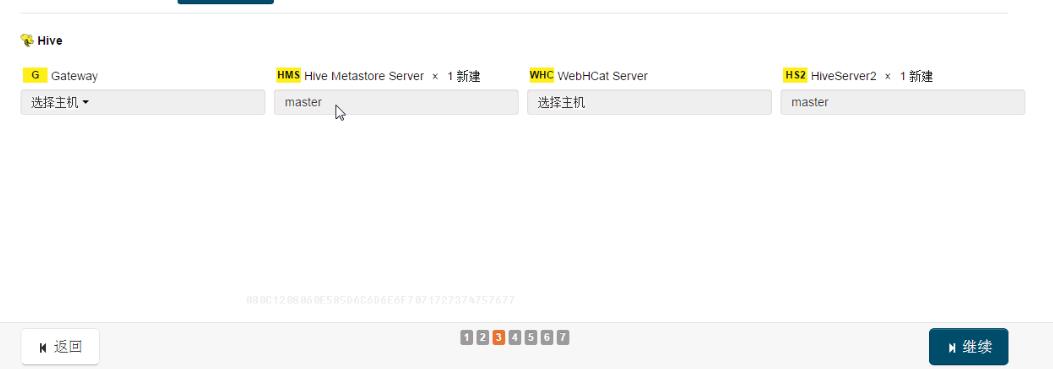
4,選擇資料庫,可以選選擇嵌入式資料庫,後期再去改。

測試連線,如果成功,點選繼續。
5,安裝進度。
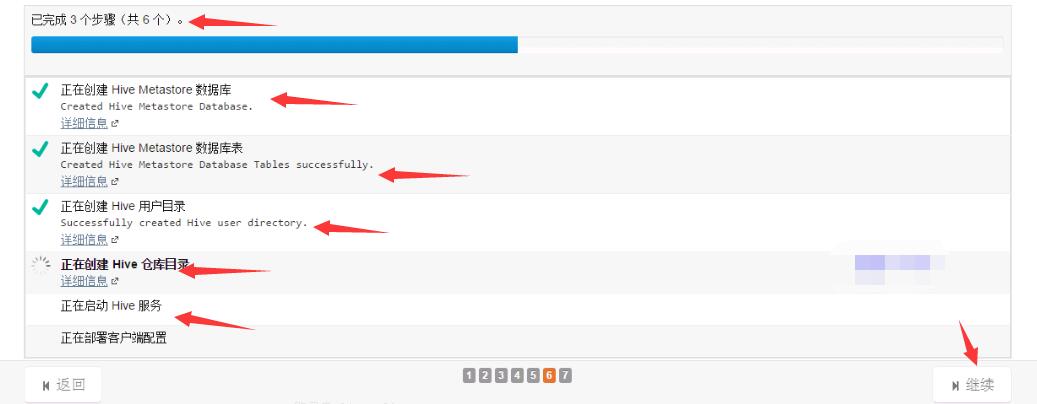
慢慢裝吧,等到下一步,就成功了。
6,成功時候的介面。

完成了以後,我們也可以配置使用自定義的資料庫了。