python - 建立代理池
該篇文章搬運自個人部落格園:darkchii - 部落格園
主題
程式簡介
- 這是一個通過免費代理網站爬取代理ip的python程式
程式結構
結構列表
- freeProxy
__init__.pyproxypool.pyproxyweb.py
結構圖
檔案介紹
__init__.py- 該檔案中什麼也沒有。
proxypool.py- 該檔案中則是後面給出的原始碼。
簡介:
其中
ProxyIpPool類中有get_kuaidaili_proxy_ip、get_data5u_proxy_ip兩個方法提供介面可以從兩家不同的代理網站中爬取代理ip。兩個方法的介面:
get_kuaidaili_proxy_ip方法返回的是字典:{'ip':ip,'port':port,'type':type,'position':position}。get_data5u_proxy_ip方法返回的是字典:
{'ip':iplist,'port':portlist,'type':typelist,'nation':nationlist}。這意味著可以呼叫這兩個方法根據自己喜愛的方式編寫介面來連線到兩個方法。
包中還有兩個建立代理池的方法:
create_kuaidaili_proxy_ip_pool、create_data5u_proxy_ip_pool根據兩個網站的不同可以同步代理池。具體細節還請自行閱讀程式碼。
proxyweb.py- 該檔案中是代理網站的連結。
原始碼
from bs4 import BeautifulSoup
from freeProxy import proxyweb
from requests import Session
from time import sleep
import random
import re, os
class ProxyIpPool(object):
r = Session()
def __init__(self,page=None,url=proxyweb.kuaidaili):
object.__init__(self)
self.page = page
self.url = url
def get_kuaidaili_proxy_ip(self):
tablelist = ['IP', 'PORT', '型別', '位置']
ip = []
port = []
type = []
position = []
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection':'keep-alive',
'Host': 'www.kuaidaili.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Chrome/64.0.3282.168'
}
if self.page > 1:
self.url = self.url + 'inha/' + str(self.page) + '/'
request = self.r.get(self.url,headers=headers,timeout=2,)
print(request.status_code)
soup = BeautifulSoup(request.text, 'lxml')
tags = soup.find_all('td', attrs={'data-title': tablelist})
# 獲取所有IP
ip_match = re.compile(r'data-title="IP">(.+?)</td')
ip.append(ip_match.findall(str(tags)))
# 獲取所有埠
port_match = re.compile(r'data-title="PORT">(.+?)</td')
port.append(port_match.findall(str(tags)))
# 獲取所有型別
type_match = re.compile(r'data-title="型別">(.+?)</td')
type.append(type_match.findall(str(tags)))
# 獲取所有位置
position_match = re.compile(r'data-title="位置">(.+?)</td')
position.append(position_match.findall(str(tags)))
# ip、port、type、position作為字典儲存
data_title = {'ip':ip,'port':port,'type':type,'position':position}
return data_title
def get_data5u_proxy_ip(self):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Host': 'www.data5u.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Chrome/64.0.3282.168'
}
request = self.r.get(proxyweb.data5u,headers=headers,timeout=2,)
'''
print(request.url)
print(request.status_code)
'''
soup = BeautifulSoup(request.text, 'lxml')
tags = soup.find_all('ul', attrs={'class': 'l2'})
# 獲取ip
ip_match = re.compile(r'<span><li>(.{10,16})</li></span>')
iplist = ip_match.findall(str(tags))
# 獲取port
port_match = re.compile(r'port .+?">(.+?)<')
portlist = port_match.findall(str(tags))
# 獲取型別
type_match = re.compile(r'http://www.data5u.com/free/type/http.*?/index.html">(.+?)<')
typelist = type_match.findall(str(tags))
# 獲取國家
nation_match = re.compile(r'http://www.data5u.com/free/country/.+?/index.html">(.+?)<')
nationlist = nation_match.findall(str(tags))
tablelist = {'ip':iplist,'port':portlist,'type':typelist,'nation':nationlist}
return tablelist
def create_kuaidaili_proxy_ip_pool(page):
print('正在初始化代理池...請耐心等待...')
print(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16'))
try:
with open('proxyip.txt', 'a') as fp:
fp.write(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16') + '\r\n')
except:
with open('proxyip.txt', 'w') as fp:
fp.write(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16') + '\r\n')
pool = ProxyIpPool(page=page).get_kuaidaili_proxy_ip()
sleep(random.random() * 7) # 隨機sleep個0 ~ 6s減慢爬蟲速度
print('初始化完成!開始建立代理池...')
iplist = pool.get('ip')
portlist = pool.get('port')
typelist = pool.get('type')
positionlist = pool.get('position')
for i in range(len(iplist[0])):
print(format(iplist[0][i],'<22') + format(portlist[0][i],'<17') + format(typelist[0][i],'<12') + positionlist[0][i])
try:
with open('proxyip.txt','a') as fp:
fp.write(format(iplist[0][i],'<22') + format(portlist[0][i],'<17') + format(typelist[0][i],'<12') + positionlist[0][i] + '\r\n')
except FileExistsError as err:
print(err)
os._exit(2)
def create_data5u_proxy_ip_pool():
print('正在初始化代理池...請耐心等待...')
print(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16'))
try:
with open('proxyip.txt', 'a') as fp:
fp.write(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16') + '\r\n')
except:
with open('proxyip.txt', 'w') as fp:
fp.write(format('IP', '^16') + format('PORT', '^16') + format('型別', '^16') + format('位置', '^16') + '\r\n')
pool = ProxyIpPool(page=None).get_data5u_proxy_ip()
sleep(random.random() * 7) # 隨機sleep個0 ~ 6s減慢爬蟲速度
print('初始化完成!開始建立代理池...')
iplist = pool.get('ip')
portlist = pool.get('port')
typelist = pool.get('type')
nationlist = pool.get('nation')
for i in range(len(iplist)):
print(format(iplist[i], '<22') + format(portlist[i], '<17') + format(typelist[i], '<12') + format(nationlist[i], '<1'))
try:
with open('proxyip.txt', 'a') as fp:
fp.write(format(iplist[i], '<22') + format(portlist[i], '<17') + format(typelist[i], '<12') + format(nationlist[i], '<1') + '\r\n')
except FileExistsError as err:
print(err)
os._exit(2)使用方法
怎麼使用freeProxy包
- 一個簡單的用例:
from freeProxy import proxypool
if __name__ == '__main__':
for page in range(6):
proxypool.create_kuaidaili_proxy_ip_pool(page=page)
'''
# 或者
proxypool.create_data5u_proxy_ip_pool()
'''執行結果
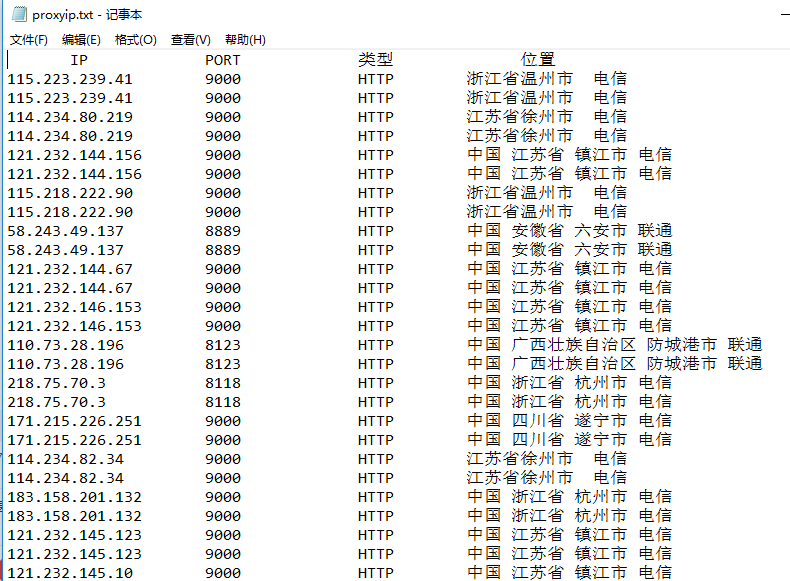
擷取部分
| IP | PORT | 型別 | 位置 |
|---|---|---|---|
| 115.223.239.41 | 9000 | HTTP | 浙江省溫州市 電信 |
| 114.234.80.219 | 9000 | HTTP | 江蘇省徐州市 電信 |
| … | … | … | … |
本地截圖
最後
談談程式的不足之處
- 程式沒有檢測爬取的代理ip的有效性
- 應該設定週期性執行程式來填充代理池
- 不能記錄上一次執行程式時爬取到哪結束
- 如果資料很量太大,把資料儲存到資料庫中更好
- 程式碼的一些細節處理並不好
謝謝觀看!歡迎大家交流學習,文章還有許多其他的不足之處,還望大家不吝指教!
相關文章
- 如何建立爬蟲代理ip池爬蟲
- python 爬蟲 代理池Python爬蟲
- Python爬蟲代理池Python爬蟲
- Python代理IP的使用和代理池的設定Python
- 手把手教你爬蟲代理ip池的建立爬蟲
- 如何用海外HTTP代理設定python爬蟲代理ip池?HTTPPython爬蟲
- Python 爬蟲IP代理池的實現Python爬蟲
- python爬蟲利用requests製作代理池sPython爬蟲
- 如何管理代理池?
- Proxypool代理池搭建
- 快速構建Python爬蟲IP代理池服務Python爬蟲
- 在Python中用concurrent.futures建立執行緒池程序池Python執行緒
- scrapy爬蟲代理池爬蟲
- 技術分享:Proxy-Pool代理池搭建IP代理
- 爬蟲如何使用ip代理池爬蟲
- 爬蟲之代理池維護爬蟲
- 代理Ip池構建及使用
- 為什麼要使用代理池?
- Golang實現的IP代理池Golang
- AOP詳解之三-建立AOP代理後記,建立AOP代理
- ElasticSearch連線池建立Elasticsearch
- 如何獲取高質量的靜態住宅ip,建立自己的靜態ip代理池?
- PHP中的代理IP池操作指南PHP
- 如何建立爬蟲IP池?爬蟲
- 為什麼python爬蟲業務要建立使用ip代理池?911s5關停該去哪兒購買ip?Python爬蟲
- "什麼是海外代理IP池?共享IP池和獨享IP池有什麼不同?"
- 代理ip池對爬蟲有多重要爬蟲
- 自建代理IP池的三大優勢
- 1.3.2.4 建立一個代理PDB
- python 物件池Python物件
- python 程式池Python
- NAS中如何建立儲存池
- 執行緒池建立方式執行緒
- Azure DevOps+Docker+Asp.NET Core 實現CI/CD(一 .簡介與建立自己的代理池)devDockerASP.NET
- IPIDEA講述代理IP以及代理IP池的概念是什麼Idea
- Python執行緒池與程式池Python執行緒
- scrapy五大核心元件和中介軟體以及UA池和代理池元件
- 高可用分散式代理IP池:架構篇分散式架構