周志華《機器學習》課後習題解答系列(六):Ch5.10 - 卷積神經網路實驗
本系列相關答案和原始碼託管在我的Github上:PY131/Machine-Learning_ZhouZhihua.
卷積神經網路實驗 - 手寫字元識別

注:本題程實現基於python-theano(這裡檢視完整程式碼和資料集)。
1. 基礎知識回顧
1.1. 核心思想
卷積神經網路(Convolutional Neural Network, CNN)是“深度學習”的代表模型之一,是一種多隱層神經網路,正被廣泛用於影象處理、語音識別等熱點領域。
卷積神經網路的原理和特點,集中體現在以下三個核心思想當中:
- 區域性感受野(Local Receptive Fields)
- 權值共享(weight sharing)
- 時間或空間的亞取樣
在整合了上述三大特點之後,卷積神經網路具備了很強的畸變容忍能力,能夠從複雜的物件中隱式地進行特徵提取與學習。
1.2. 結構和功能
卷積神經網路同多層感知機(MLP)一樣,通過設定多個隱層來實現對複雜模型的學習。如下圖所示是一個手寫字元識別的卷積神經網路結構示意圖(書p114):
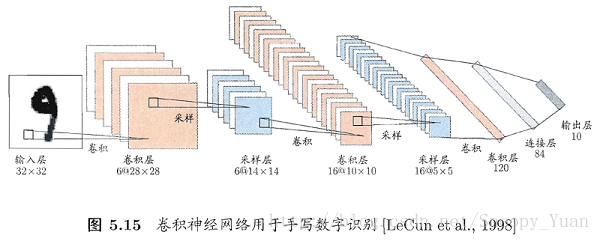
從圖中可以看到卷積層(convolutional layer)和取樣層(pooling layer)的複合,其功能簡述如下:
- 卷積層包含多個特徵對映(feature map),它們採用相應的卷積濾波器從輸入中提取特徵;
- 取樣層基於區域性相關性原理對卷積層進行亞取樣,從而在保留有用資訊的同時減少資料量;
通過多層複合,隱層最終輸出目標維特徵向量,通過連線層和輸出層輸出結果。
1.3. 引數技巧
神經網路的引數設計十分重要,關於CNN模型的一些引數的考慮(如隱層特徵圖數目和大小、濾波器大小等),可參考Convolutional Neural Networks (LeNet)文章最後Tips and Tricks的內容。
2. 手寫字元識別實驗
這裡,我們採用python-theano深度學習庫來實現基於MNIST資料的字元識別實驗。關於theano的基礎使用可參考:深度學習基礎 - 基於Theano-MLP的字元識別實驗(MNIST)或是Deep Learning Tutorials。
2.1. 資料獲取及預處理
這裡我們採用經過規約的資料集mnist.pkl.gz,給出該資料集的部分資訊如下:
- 維度屬性:資料集包含3個子資料集,對應train_set、valid_set、test_set,樣本規模分別為50000、10000、10000;每條樣本包含:輸入向量[1*784],對應輸入圖片灰度矩陣[28*28];輸出值,對應圖片類別標籤(數字0-9);
- 完整度:樣本完整;
- 平衡度:未知;
- 更多資訊:手寫字元所覆蓋的灰度已被人工調整到了圖片的中部。
下面是一些樣例圖片:

通過對資料集的分析,確定此處該資料集已無需額外的預處理即可使用,只是在使用時注意維度變換即可。
2.2. 基於theano實現網路模型
基於theano來訓練一個卷積神經網路需要完成的內容包括:
- 引數初始化,採用
theano.shared來達到權值共享,基於資料資訊設計相關引數(隱層規模、濾波器大小、學習率、迭代次數限、若取樣MSGD演算法還需設定mini-batch大小等); - 相關輔助函式,如採用
theano.function實現tanh/sigmoid、似然損失函式等; - 卷積操作(Convolution)和池化操作(pooling),採用
theano.tensor.signal.conv2d實現二維(2D)卷積;採用theano.tensor.signal.pool.pool_2d實現最大池化(max-pooling), - 訓練過程優化機制,如加入不同時間尺度的驗證、測試機制,早停機制;
- 實現迭代訓練程式並得出模型(即最優引數);
進一步地:
- 將卷積層與池化層(取樣層)整個為一個複合層,稱為卷積-池化層(
class LeNetConvPoolLayer); - 將模型的訓練、驗證、測試整合在一個程式塊中,方便早停判斷;
這裡還需進一步說明各層規模和濾波器大小的設定:
以當前樣本為例,輸入層大小[28*28],若採用5*5的濾波器進行卷積,則第一個卷積層的特徵圖大小為[24*24](ps. 28-5+1=24),若緊接著的亞取樣模版大小為[2*2],那麼該池化層特徵圖大小為[12*12](ps. 24/2=12)。同理,可計算出下一個卷積池化的特徵圖大小為[8*8]和[4*4],再往後就只需要一個面向連線層的一維卷積層了,其節點數為當前的feature maps數。然後按照MLP模型給出連線層和輸出層即可。
各層規模設定的樣例程式如下:
layer1 = LeNetConvPoolLayer(
rng,
input=layer0.output,
image_shape=(batch_size, nkerns[0], 12, 12),
filter_shape=(nkerns[1], nkerns[0], 5, 5),
poolsize=(2, 2)
)
layer2_input = layer1.output.flatten(2)
# construct a fully-connected sigmoidal layer
layer2 = HiddenLayer(
rng,
input=layer2_input,
n_in=nkerns[1] * 4 * 4,
n_out=500,
activation=T.tanh
)
# classify the values of the fully-connected sigmoidal layer
layer3 = LogisticRegression(input=layer2.output, n_in=500, n_out=10)給出該訓練程式簡化樣例如下檢視完整程式:
def evaluate_lenet5(learning_rate=0.1, # 學習率
n_epochs=200, # 迭代批數
dataset='mnist.pkl.gz', # 資料集檔案
nkerns=[20, 50], # 每隱層特徵圖數目序列
batch_size=500): # mini-batch大小(for MSGD)
# 載入資料,生成訓練集/驗證集/測試集
datasets = load_data(dataset)
train_set_x, train_set_y = datasets[0]
valid_set_x, valid_set_y = datasets[1]
test_set_x, test_set_y = datasets[2]
...
# 搭建模型網路結構(包括上面的隱層sizes推導)
# 輸入
layer0_input = x.reshape((batch_size, 1, 28, 28))
# 第一層 - 複合
layer0 = LeNetConvPoolLayer(
rng,
input=layer0_input,
image_shape=(batch_size, 1, 28, 28),
filter_shape=(nkerns[0], 1, 5, 5),
poolsize=(2, 2)
)
# 第二層 - 複合
layer1 = LeNetConvPoolLayer( ... )
# 第三層 - 隱層
layer2_input = layer1.output.flatten(2)
layer2 = HiddenLayer( ... )
# 全連線輸出
layer3 = LogisticRegression(input=layer2.output, n_in=500, n_out=10)
# 似然損失函式
cost = layer3.negative_log_likelihood(y)
...
# 引數更新機制
updates = [
(param_i, param_i - learning_rate * grad_i)
for param_i, grad_i in zip(params, grads)
]
# 模型訓練函式體
train_model = theano.function(
[index],
cost,
updates=updates,
givens={
x: train_set_x[index * batch_size: (index + 1) * batch_size],
y: train_set_y[index * batch_size: (index + 1) * batch_size]
}
)
########## 模型訓練 ##########
# 早停機制設定
patience = 10000 # 迭代次數耐心上限
patience_increase = 2 # 耐心上限擴充步長
improvement_threshold = 0.995 # 精度明顯提升判斷
# 驗證週期
validation_frequency = min(n_train_batches, patience // 2)
...
# 迴圈
while (epoch < n_epochs) and (not done_looping):
epoch = epoch + 1
# mini-batch迭代
for minibatch_index in range(n_train_batches):
...
# 模型訓練(損失計算+引數更新)
cost_ij = train_model(minibatch_index)
# 模型驗證(a batch訓練完成)
if (iter + 1) % validation_frequency == 0:
# 計算0-1損失 - 驗證誤差
validation_losses = [validate_model(i) for i in range(n_valid_batches)]
this_validation_loss = numpy.mean(validation_losses)
...
# 如果取得更好模型(驗證精度提升)
if this_validation_loss < best_validation_loss:
# 若精度提升明顯,但耐心迭代次數上限達到,則提高迭代次數上限
if this_validation_loss < best_validation_loss * improvement_threshold:
patience = max(patience, iter * patience_increase)
...
# 進行測試(在驗證精度提升時)以方便我們對比觀測
test_losses = [
test_model(i)
for i in range(n_test_batches)
]
test_score = numpy.mean(test_losses)
...
# 早停判斷
if patience <= iter:
done_looping = True
break
...
#返回所需資訊2.3. 訓練及測試結果
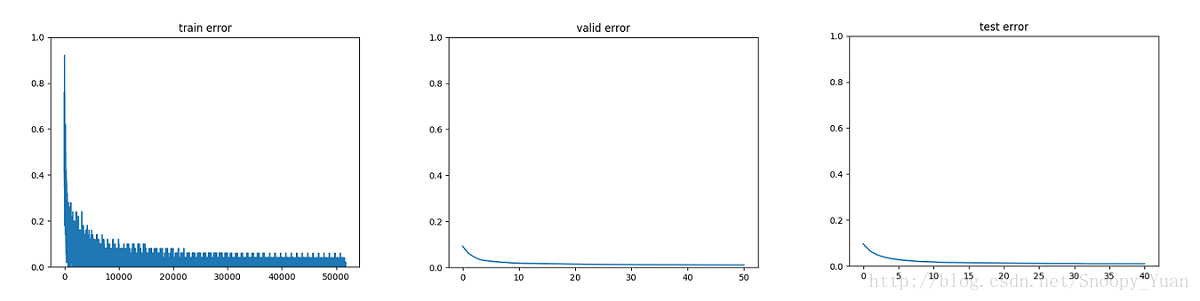
這裡採用MSGD(塊隨機梯度下降法)進行迭代尋優,下圖是經過大約5萬次迭代訓練後得到的三種誤差(訓練/驗證/測試)收斂曲線,可以看出其過程收斂性:
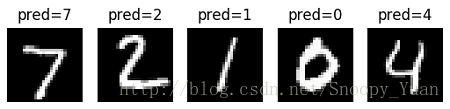
顯示出一些測試樣本的預測結果如下圖示:
最終的執行結果列印如下:
最優驗證誤差結果: Best validation score of 1.080000 %
測試誤差結果: Test performance 1.030000 %
過程時耗: The code for file Mnist_CNN.py ran for 90.23m
從這裡的結果可以看出:一方面,卷積神經網路訓練計算規模龐大(當前軟硬體環境下耗時一個半小時);另一方面,得到的模型精度很高(在測試集上實現了約99%的精度,這基本意味著MNIST問題得到了解決)。
3. 總結
通過該實驗,我們注意到:
- CNN是一種優秀的機器學習模型,能夠實現較困難的學習任務;
- 以CNN為代表的“深度學習”模型的訓練往往面臨著巨大的計算量,為優化實現,一方面需要提升軟硬體配置環境,另一方面要合理設計訓練機制,包括MSGD、早停、正則化等輔助方法的合理運用;
- 引數設定合理與否嚴重影響模型的訓練效率和實現效果;
通過該實驗,我們回顧了卷積神經網路及其所代表的深度學習概念,練習了基於python-theano計算框架下的機器學習建模方法,為進一步的學習研究積累的實踐經驗。
4. 參考
下面列出相關參考:
- 本文直接教程:深度學習基礎 - 基於Theano-MLP的字元識別實驗(MNIST)
- 本文直接教程:Convolutional Neural Networks (LeNet)
- 一個有趣的視覺化網站:“CNN-數字識別”模型視覺化
- 一個深度學習主頁:Contents - DeepLearning 0.1 documentation
相關文章
- 周志華《機器學習》課後習題解答系列(六):Ch5 - 神經網路機器學習H5神經網路
- 周志華《機器學習》課後習題解答系列(六):Ch5.8 - SOM網路實驗機器學習H5
- 周志華《機器學習》課後習題解答系列(六):Ch5.7 - RBF網路實驗機器學習H5
- 周志華《機器學習》課後習題解答系列(一):目錄機器學習
- 周志華《機器學習》課後習題解答系列(六):Ch5.5 - BP演算法實現機器學習H5演算法
- 周志華《機器學習》課後習題解答系列(四):Ch3.4 - 交叉驗證法練習機器學習
- 周志華《機器學習》課後習題解答系列(六):Ch5.6 - BP演算法改進機器學習H5演算法
- 周志華《機器學習》課後習題解答系列(四):Ch3 - 線性模型機器學習模型
- 周志華《機器學習》課後習題解答系列(五):Ch4 - 決策樹機器學習
- 機器學習-周志華-課後習題答案5.5機器學習
- 周志華《機器學習》課後習題解答系列(三):Ch2 - 模型評估與選擇機器學習模型
- 周志華《機器學習》課後習題解答系列(四):Ch3.3 - 程式設計實現對率迴歸機器學習程式設計
- 周志華《機器學習》課後習題解答系列(四):Ch3.5 - 程式設計實現線性判別分析機器學習程式設計
- 【卷積神經網路學習】(4)機器學習卷積神經網路機器學習
- 個人學習卷積神經網路的疑惑解答卷積神經網路
- 周志華《機器學習》課後習題解答系列(五):Ch4.3 - 程式設計實現ID3演算法機器學習程式設計演算法
- 周志華《機器學習》課後習題解答系列(五):Ch4.4 - 程式設計實現CART演算法與剪枝操作機器學習程式設計演算法
- Coursera Deep Learning 4 卷積神經網路 第四周習題卷積神經網路
- 卷積神經網路卷積神經網路
- 吳恩達《卷積神經網路》課程筆記(1)– 卷積神經網路基礎吳恩達卷積神經網路筆記
- 第四周:卷積神經網路 part 3卷積神經網路
- 機器學習-周志華機器學習
- 【深度學習篇】--神經網路中的卷積神經網路深度學習神經網路卷積
- 5.2.1 卷積神經網路卷積神經網路
- 卷積神經網路概述卷積神經網路
- 解密卷積神經網路!解密卷積神經網路
- 卷積神經網路CNN卷積神經網路CNN
- 卷積神經網路初探卷積神經網路
- 卷積神經網路-1卷積神經網路
- 卷積神經網路-2卷積神經網路
- 卷積神經網路-3卷積神經網路
- 深度學習三:卷積神經網路深度學習卷積神經網路
- 卷積神經網路學習資料卷積神經網路
- 【機器學習基礎】卷積神經網路(CNN)基礎機器學習卷積神經網路CNN
- 卷積神經網路四種卷積型別卷積神經網路型別
- 周志華 機器學習ppt機器學習
- 深度學習筆記------卷積神經網路深度學習筆記卷積神經網路
- 卷積神經網路CNN-學習1卷積神經網路CNN