QQ空間爬蟲分享(一天可抓取 400 萬條資料)
程式碼請移步GitHub:QQSpider
爬蟲功能:
QQSpider 使用廣度優先策略爬取QQ空間中的個人資訊、日誌、說說、好友四個方面的資訊,詳細可見資料庫說明。
判重使用“記憶體位”判重,理論上億數量級的QQ可瞬間判重,記憶體只佔用400M+。
爬蟲速度可達到單機每天400萬條資料以上(具體要考慮網速、網路頻寬、穩定性等原因。我在學校是400萬+,但在公司那邊卻只有六成的速度,普通家庭網路可能會更慢)。
環境、架構:
開發語言:Python2.7
開發環境:64位Windows8系統,4G記憶體,i7-3612QM處理器。
資料庫:MongoDB 3.2.0
(Python編輯器:Pycharm 5.0.4;MongoDB管理工具:MongoBooster 1.1.1)
主要使用 requests 模組抓取,部分使用 BeautifulSoup 解析。
多執行緒使用 multiprocessing.dummy 。
抓取 Cookie 使用 selenium 和 PhantomJS 。
判重使用 BitVector 。
使用說明:
啟動前配置:
MongoDB安裝好 能啟動即可,不需要配置。
Python需要安裝以下模組(注意官方提供的模組是針對win32系統的,64位系統使用者在使用某些模組的時候可能會出現問題,所以儘量先找64位模組,如果沒有64的話再去安裝32的資源):
requests、BeautifulSoup、multiprocessing、selenium、itertools、BitVector、pymongo
另外我們需要使用到 PhantomJS,這並不是 Python 的模組,而是一個exe可執行檔案,我們可以利用它模擬瀏覽器去獲取 Cookie 。使用方法:將 phantomjs-2.0.0-windows.zip 壓縮包裡面的 phantomjs.exe 放到你的 Python 目錄下就行了。
啟動程式:
- 進入 myQQ.txt 寫入QQ賬號和密碼(用一個空格隔開,不同QQ換行輸入),一般你開啟幾個QQ爬蟲執行緒,就至少需要兩倍數量的QQ用來登入,至少要輪著登入嘛。
- 進入 init_messages.py 進行爬蟲引數的配置,例如執行緒數量的多少、設定爬哪個時間段的日誌,哪個時間段的說說,爬多少個說說備份一次等等。
- 執行 init.py 檔案開啟爬蟲專案。
- 爬蟲開始之後首先根據 myQQ.txt 裡面的QQ去獲取 Cookie(以後登入的時候直接用已有的Cookie,就不需要每次都去拿Cookie了,遇到Cookie失效也會自動作相應的處理)。獲取完Cookie後爬蟲程式會去申請四百多兆的記憶體,申請的時候會佔用兩G左右的記憶體,大約五秒能完成申請,之後會掉回四百多M。
- 爬蟲程式可以中途停止,下次可開啟繼續抓取。
執行截圖:
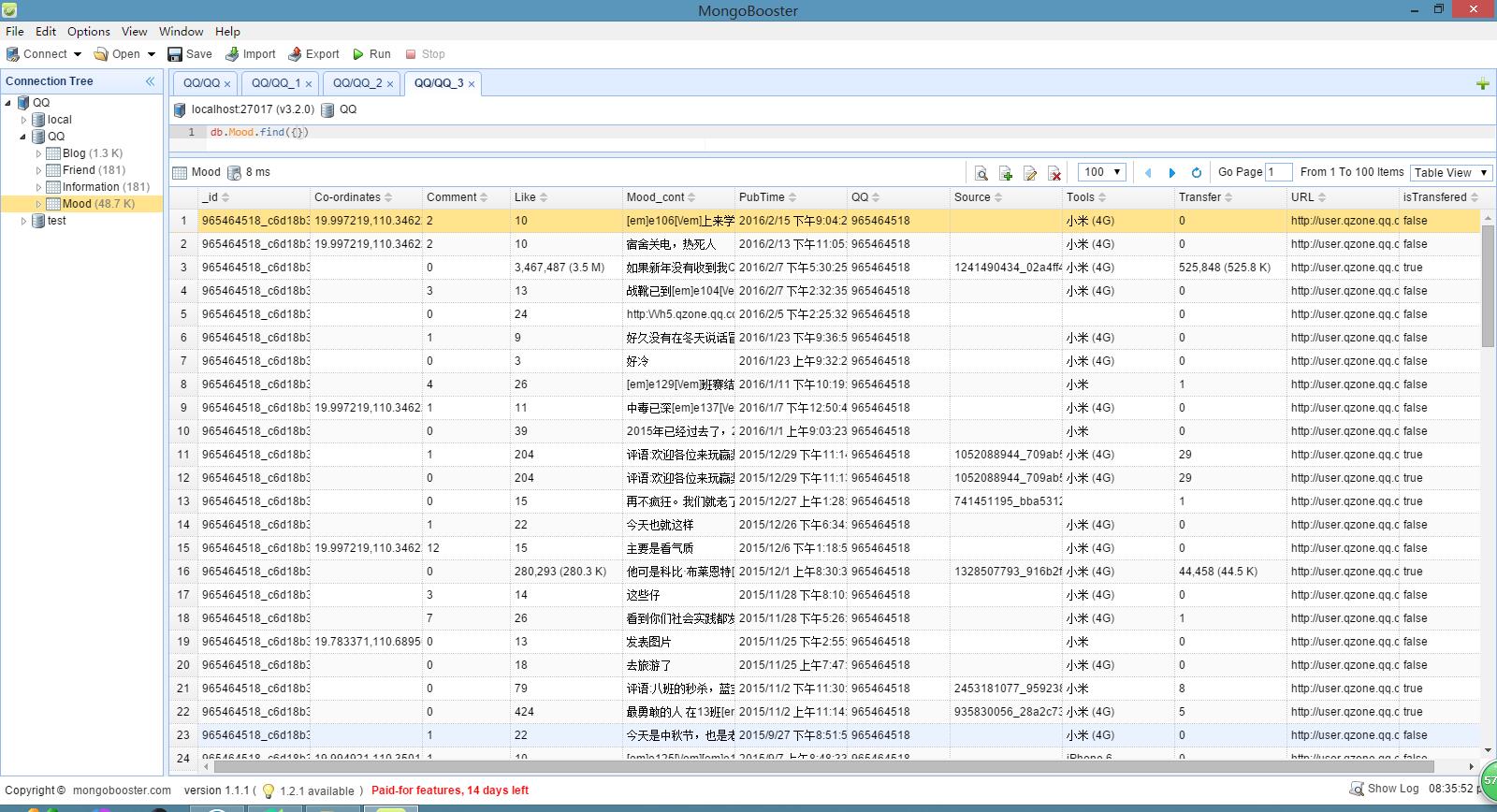
說說資料:
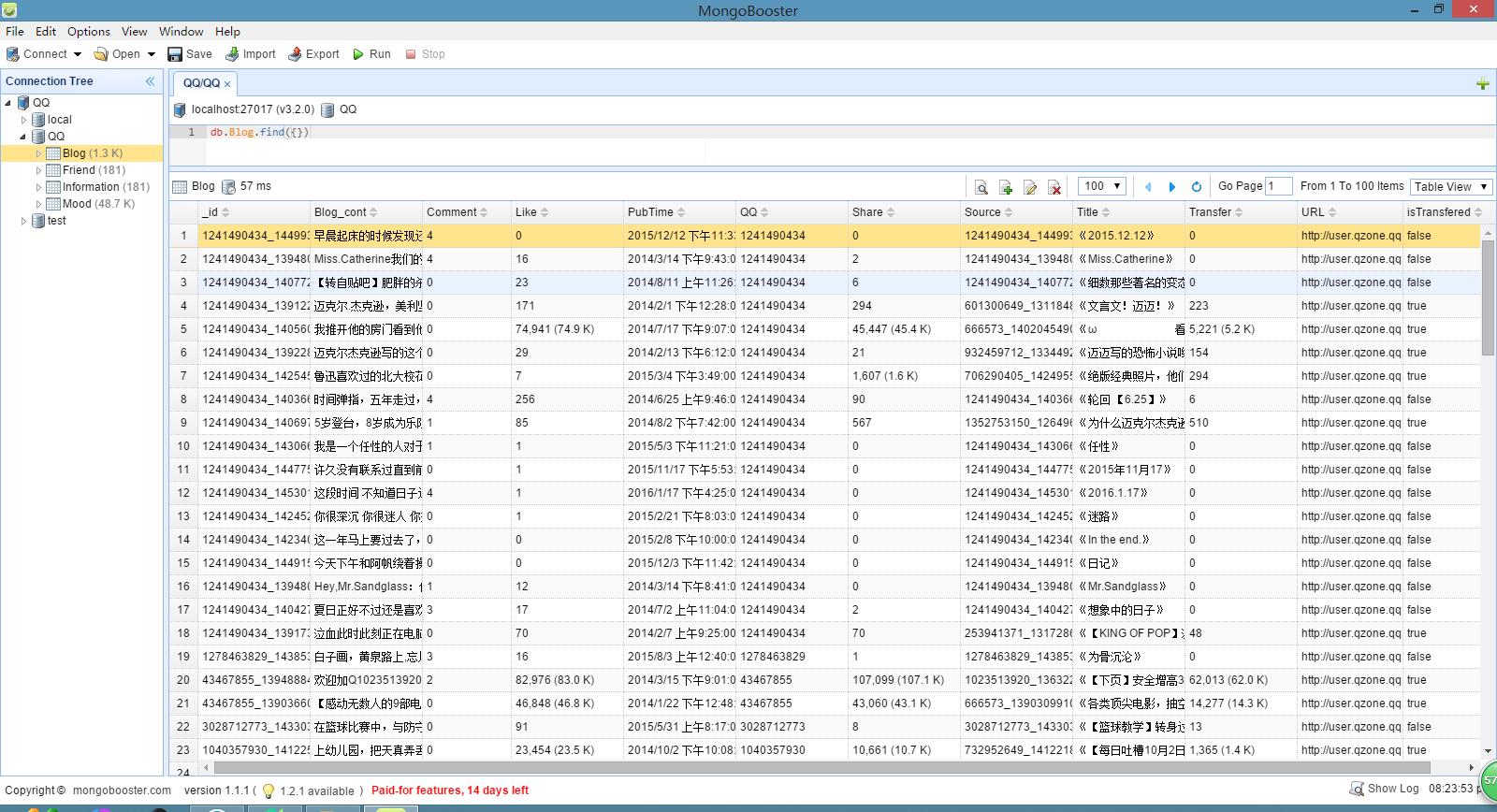
日誌資料:
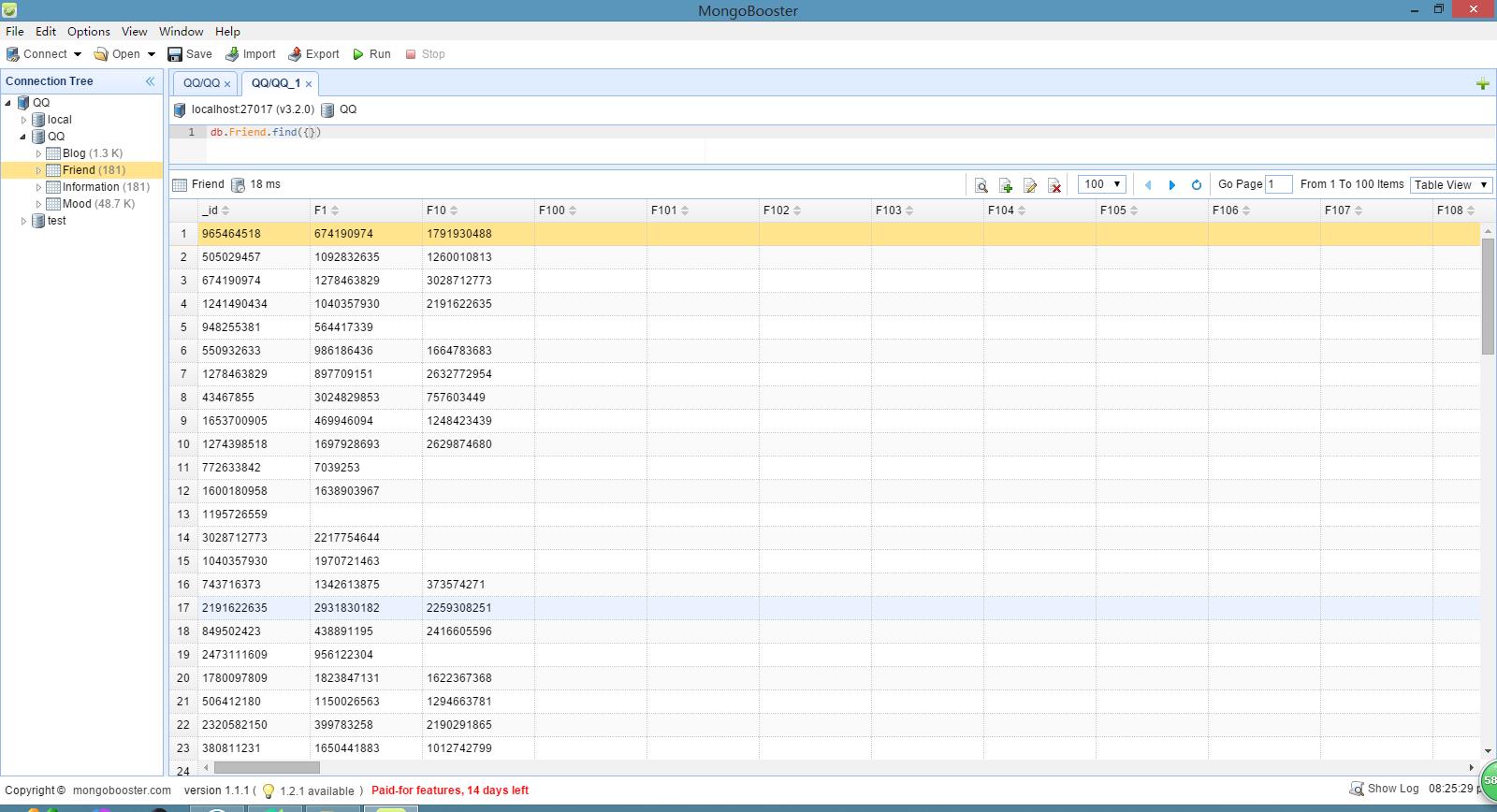
好友關係資料:
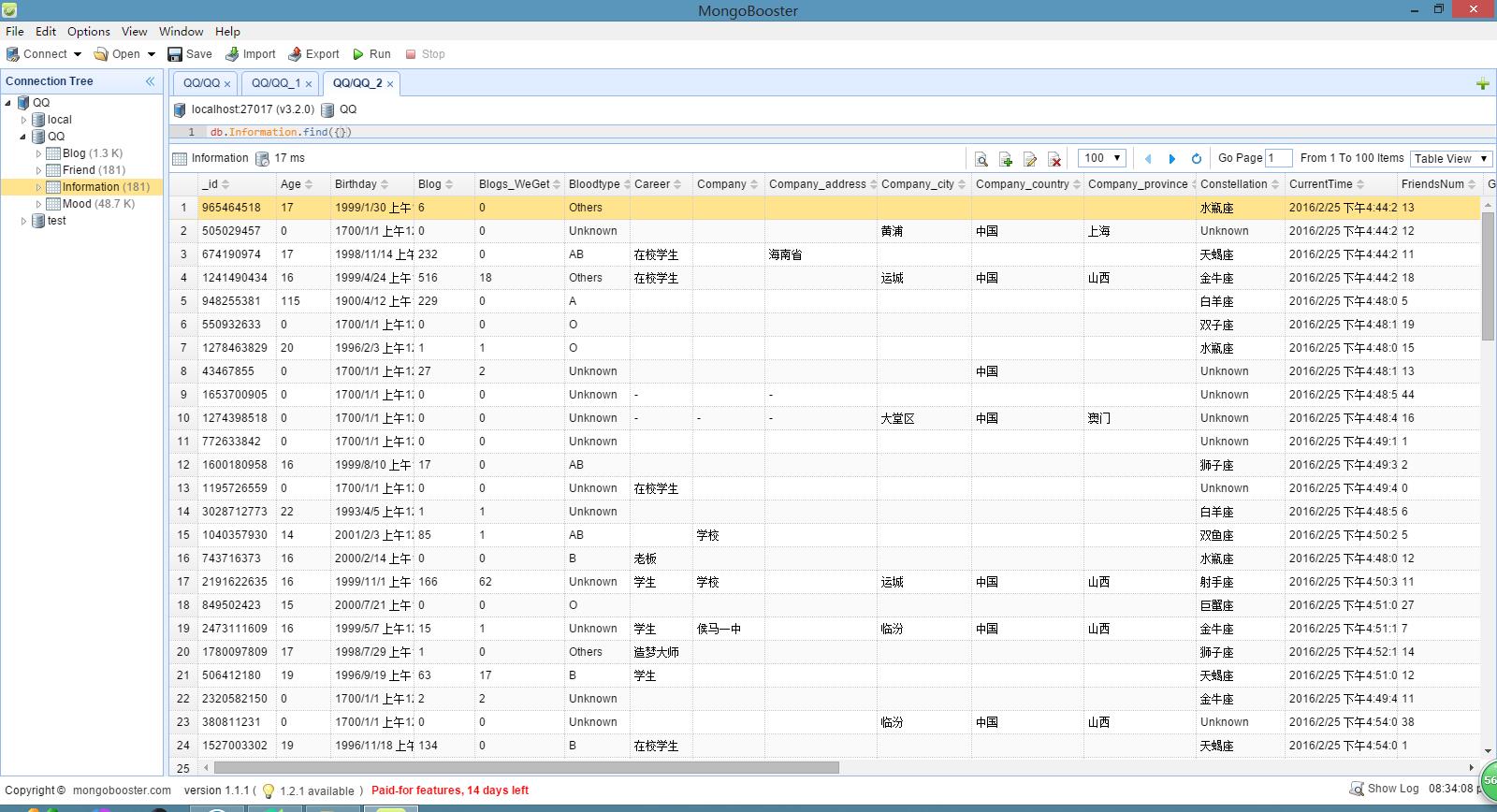
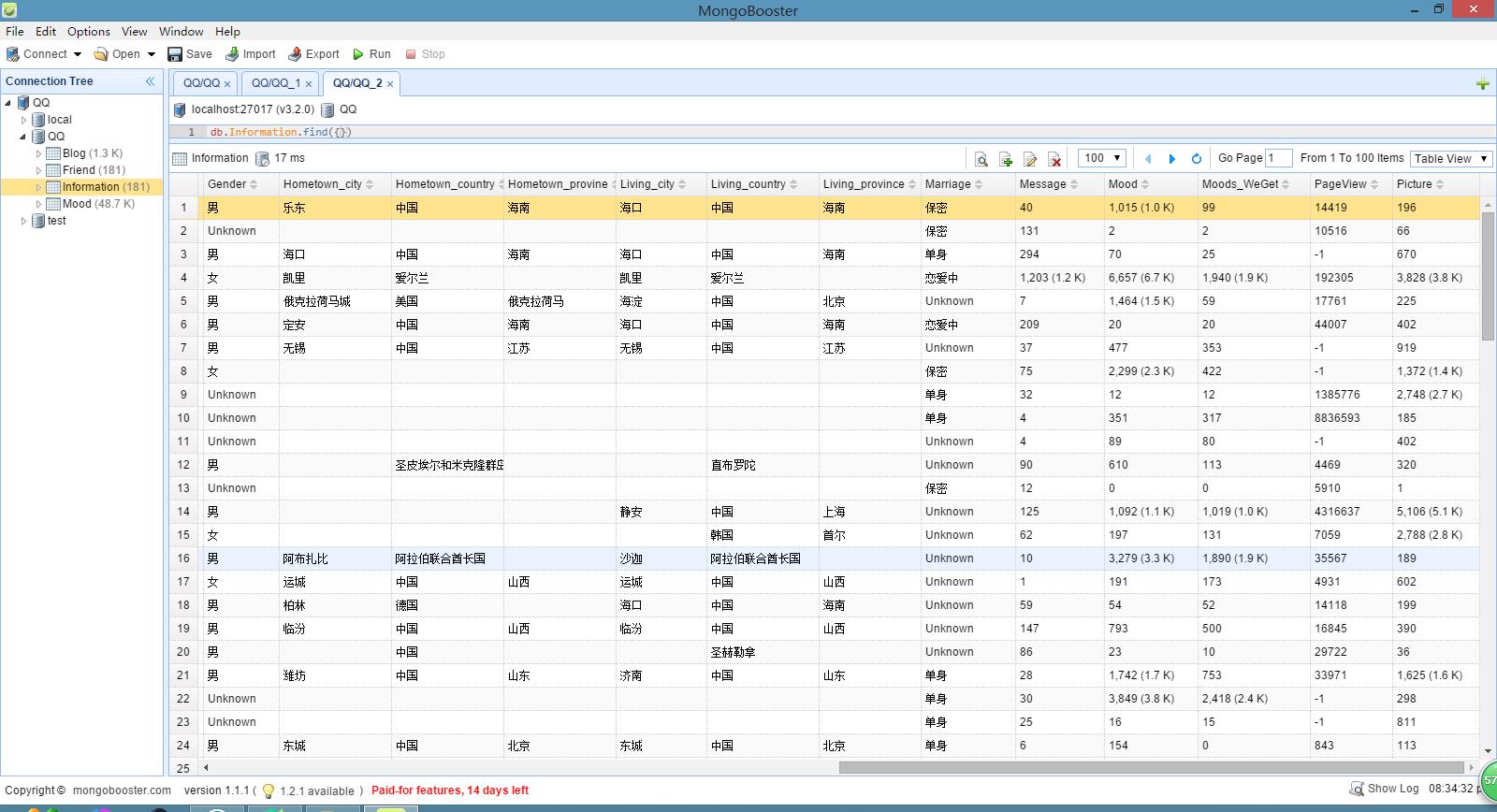
個人資訊資料:
資料庫說明:
QQSpider主要爬取QQ使用者的說說、日誌、朋友關係、個人資訊。
資料庫分別設定 Mood、Blog、Friend、Information 四張表。
Mood 表:
_id:採用 “QQ_說說id” 的形式作為說說的唯一標識。
Co-oridinates:發說說時的定位座標,呼叫地圖API可直接檢視具體方位,可識別到在哪一棟樓。
Comment:說說的評論數。
Like:說說的點贊數。
Mood_cont:說說內容。
PubTime:說說發表時間。
QQ:發此說說的QQ號。
Source:說說的根源(對於轉發的說說),採用 “QQ_說說id” 的形式標識。
Tools:發說說的工具(手機型別或者平臺)。
Transfer:說說的轉發數。
URL:說說的連結地址。
isTransfered:此說說是否屬於轉發來的。
Blog 表:
_id:採用 “QQ_日誌id” 的形式作為日誌的唯一標識。
Blog_cont:日誌內容。
Comment:日誌的評論數。
Like:日誌的點贊數。
PubTime:日誌的發表時間。
QQ:發此日誌的QQ號。
Share:日誌的分享數。
Source:日誌的根源(對於轉發的日誌),採用 “QQ_日誌id” 的形式標識。
Title:日誌的標題。
Transfer:日誌的轉發數。
URL:日誌的連結地址。
isTransfered:此日誌是否屬於轉發來的。
Friend 表:
_id:採用 QQ 作為唯一標識。
Num:此QQ的好友數(僅統計已抓取到的)。
Fx:朋友的QQ號,x代表第幾位好友,x從1開始逐漸迭加。
Information 表:
_id:採用 QQ 作為唯一標識。
Age:年齡。
Birthday:出生日期。
Blog:已發表的日誌數。
Blogs_WeGet:我們已抓取的日誌數。
Blood_type:血型。
Career:職業。
Company:公司。
Company_address:公司詳細地址。
Company_city:公司所在城市。
Company_country:公司所在國家。
Company_province:公司所在省份。
Constellation:星座。
CurrentTime:抓取當前資訊的時間(不同時間資訊會不同)。
FriendsNum:好友數(僅統計已抓取的)。
Gender:性別。
Hometown_city:故鄉所在城市。
Hometown_country:故鄉所在國家。
Hometown_province:故鄉所在省份。
Living_city:居住的城市。
Living_country:居住的國家。
Living_province:居住的省份。
Marriage:婚姻狀況。
Message:空間留言數。
Mood:已發表的說說數。
Mood_WeGet:我們已抓取的說說數。
PageView:空間總訪問量。
Picture:已發表的照片數(包括相簿裡的照片和說說裡的照片)。
結語:
自己一個人瞎搞了一個多星期,肯定還有很多地方不規範,不夠優化。不足之處請多指出!
更新版本:《QQ空間爬蟲分享(2016年11月18日更新)》。
轉載請註明出處,謝謝!(原文連結:http://blog.csdn.net/bone_ace/article/details/50771839)
相關文章
- 新浪微博爬蟲分享(一天可抓取 1300 萬條資料)爬蟲
- Python爬蟲如何去抓取qq音樂的歌手資料?Python爬蟲
- 爬蟲實戰 -- QQ空間自動點贊爬蟲
- 爬蟲原理與資料抓取爬蟲
- 如何讓Python爬蟲一天抓取100萬張網頁Python爬蟲網頁
- 爬蟲抓取網頁資料原理爬蟲網頁
- python爬蟲:批量下載qq空間裡的照片(一)Python爬蟲
- 大型爬蟲案例:爬取去哪兒網自由行資料(10萬條資料)爬蟲
- 爬蟲技術抓取網站資料方法爬蟲網站
- 如何使用代理IP進行資料抓取,PHP爬蟲抓取亞馬遜商品資料PHP爬蟲亞馬遜
- 一天時間入門python爬蟲,直接寫一個爬蟲案例,分享出來,很簡單Python爬蟲
- 讓爬蟲無障礙抓取上千萬APP資料爬蟲APP
- 爬蟲抓取UserAgent問題爬蟲
- 網路爬蟲如何獲取IP進行資料抓取爬蟲
- Python爬蟲新手教程:手機APP資料抓取 pyspiderPython爬蟲APPIDE
- Python爬蟲抓取資料,為什麼要使用代理IP?Python爬蟲
- [網路爬蟲]使用node.js cheerio抓取網頁資料爬蟲Node.js網頁
- Python爬蟲抓取股票資訊Python爬蟲
- Google 爬蟲如何抓取 JavaScript 的?Go爬蟲JavaScript
- 爬蟲app資訊抓取之apk反編譯抓取爬蟲APPAPK編譯
- IPIDEA大盤點,藉助網路爬蟲抓取資料的作用?Idea爬蟲
- node 爬蟲,使用 Google puppeteer 抓取 One一個 的網頁資料爬蟲Go網頁
- 爬蟲進階——動態網頁Ajax資料抓取(簡易版)爬蟲網頁
- Python 爬蟲QQ音樂Python爬蟲
- python爬蟲抓取哈爾濱天氣資訊(靜態爬蟲)Python爬蟲
- QQ空間資料揭秘:你根本不懂95後
- scrapy 爬電影 抓取資料
- 數美驗證碼-空間推測-爬蟲爬蟲
- 網路爬蟲之抓取郵箱爬蟲
- QQ空間前端工程前端
- 爬蟲抓取網路資料時經常遇到的六種問題爬蟲
- Python爬蟲實戰:爐石傳說卡牌、原畫資料抓取Python爬蟲
- 房產資料爬取、智慧財產權資料爬取、企業工商資料爬取、抖音直播間資料python爬蟲爬取Python爬蟲
- Python網路爬蟲抓取動態網頁並將資料存入資料庫MYSQLPython爬蟲網頁資料庫MySql
- 用Python爬蟲抓取代理IPPython爬蟲
- 爬蟲抓取網頁的詳細流程爬蟲網頁
- 分享到QQ空間、新浪微博、騰訊微博的程式碼!(收藏)
- 資料解讀:QQ空間超9000萬話題熱議《致我們終將逝去的青春》