爬蟲福利:教你爬wap站
前言:
玩過爬蟲的朋友應該都清楚,爬蟲難度:www > m > wap (www是PC端,m和wap是移動端,現在的智慧手機一般用的是m站,部分老手機用的還是wap),原因也很簡單,現在的網站越來越多地使用AJAX載入,反爬蟲機制也厲害。而像wap這種移動端網站限制比較小,網頁結構也簡單,我們獲取、解析起來都簡單很多,理論上速度也會快很多。所以如果允許的話我們儘量採用wap站抓取。
正文:
可能很多剛接觸爬蟲的朋友也想從wap爬取,但不知道怎麼做。例如用PC端瀏覽器開啟 weibo.cn 在登入的時候會自動跳回m域名網站,甚至用requests開啟網頁時會返回403錯誤。
這是因為網站伺服器會根據你的瀏覽器表頭判斷你是從哪個平臺傳送的請求,識別到PC端的請求會給你作相應處理。所以我們只需要修改一下瀏覽器表頭(User-Agent)即可。
如果是爬蟲程式,只需要帶上舊版手機瀏覽器的User-Agent即可(例如:”Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1”)。
然而我們只看程式返回的response內容並不舒爽,我們還想在PC端用瀏覽器模擬手機瀏覽器那樣開啟網頁,怎麼辦?
我們只需要把PC瀏覽器的User-Agent改成手機的User-Agent即可。
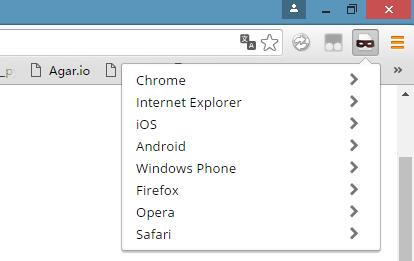
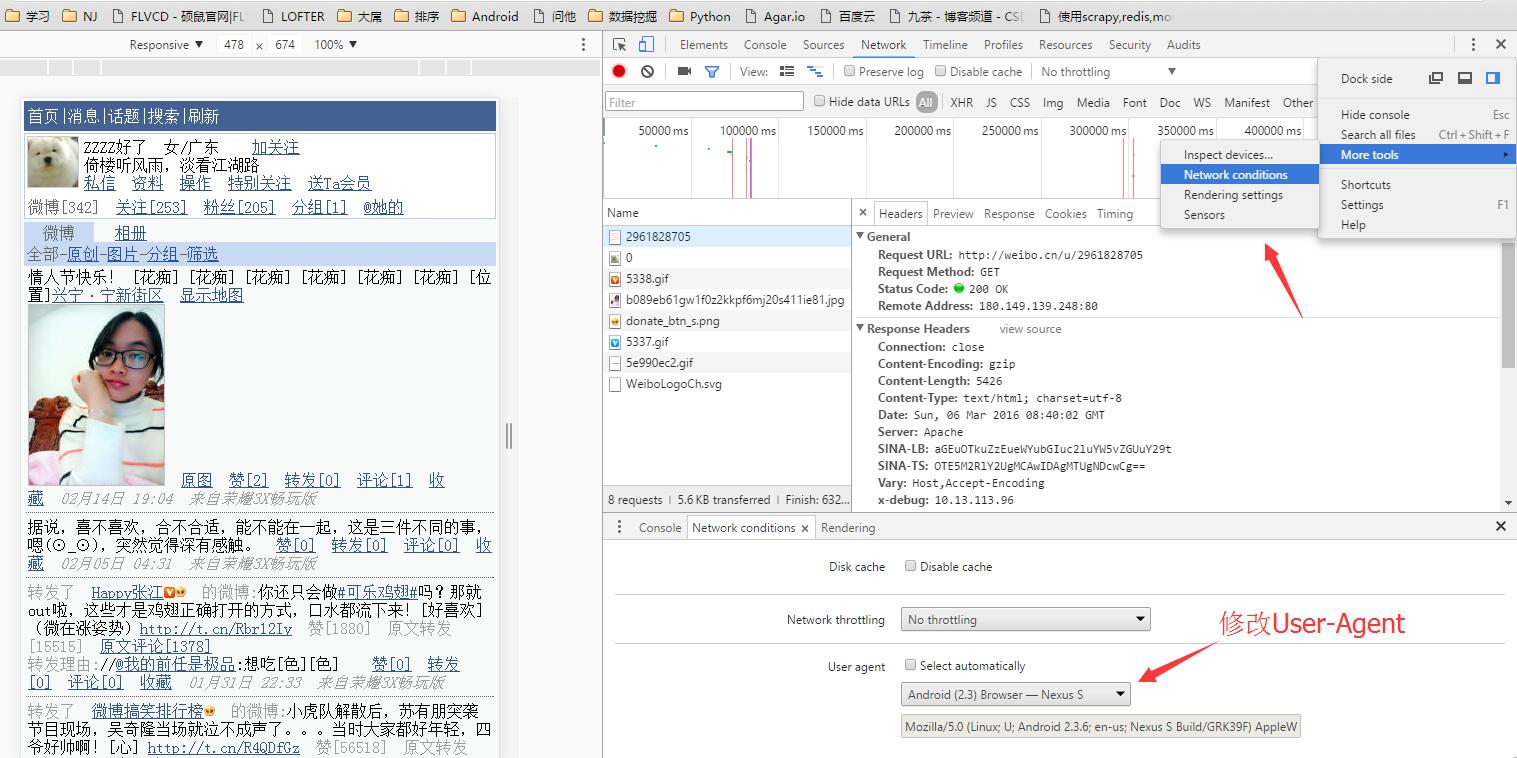
例如我用的是Chrome50,修改瀏覽器的User-Agent有兩種辦法:一種是安裝一個外掛——User-agent Switcher,另一種是直接修改瀏覽器的表頭(僅當前頁面有效)。
User-agent Switcher外掛:
直接修改瀏覽器的User-Agent:
PS:
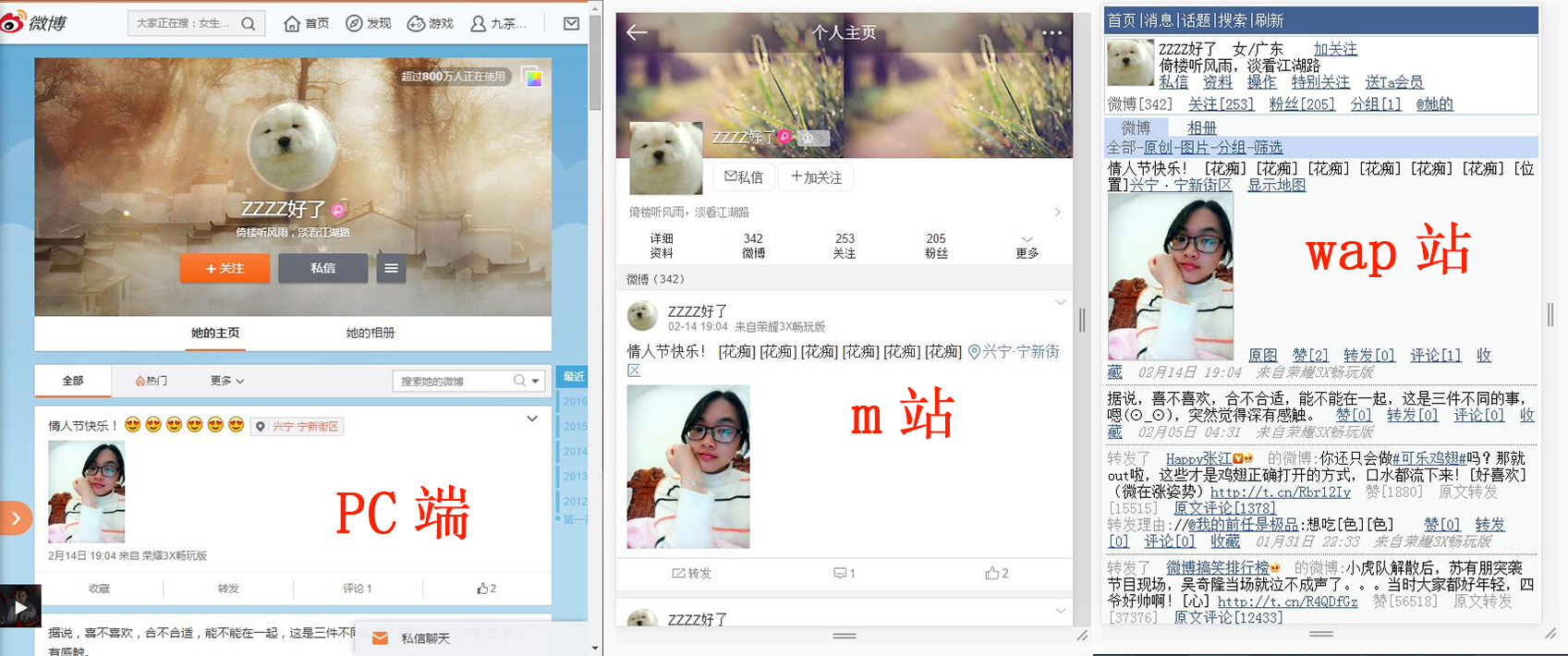
就新浪微博而言,開啟一個微博使用者的個人首頁,wap站直接返回一個HTML檔案,並不需要載入JS和CSS,而且格式、編碼都很正常;而m站返回的內容格式比較混亂,用xpath解析不了(也有可能是我的程式有問題),而且使用的是Unicode編碼格式。
之前爬蟲一直在爬PC站,第一次看到m站返回來的內容時,竟有一種莫名的喜悅和衝動,哈哈。。在此特地分享出來,大家感受一下。
轉載請註明出處,謝謝!(原文連結:http://blog.csdn.net/bone_ace/article/details/50814101)
相關文章
- Golang福利爬蟲Golang爬蟲
- 新手爬蟲,教你爬掘金(二)爬蟲
- 教你用python爬蟲爬blibili網站彈幕!Python爬蟲網站
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- 【Python學習】爬蟲爬蟲爬蟲爬蟲~Python爬蟲
- Python爬蟲:手把手教你寫迷你爬蟲架構Python爬蟲架構
- Python爬蟲爬取美劇網站Python爬蟲網站
- 手把手教你寫網路爬蟲(2):迷你爬蟲架構爬蟲架構
- scrapy + mogoDB 網站爬蟲Go網站爬蟲
- 招聘網站爬蟲模板網站爬蟲
- 爬蟲:多程式爬蟲爬蟲
- 快上車,scrapy爬蟲飆車找福利(三)爬蟲
- 快上車,scrapy爬蟲飆車找福利(一)爬蟲
- Python爬蟲—爬取某網站圖片Python爬蟲網站
- 不會Python爬蟲?教你一個通用爬蟲思路輕鬆爬取網頁資料Python爬蟲網頁
- 通用爬蟲與聚焦爬蟲爬蟲
- 爬蟲--Scrapy簡易爬蟲爬蟲
- 手把手教你寫網路爬蟲(3):開源爬蟲框架對比爬蟲框架
- 爬蟲福利----妹子圖網MM批量下載爬蟲
- 手把手教你利用爬蟲爬網頁(Python程式碼)爬蟲網頁Python
- 反爬蟲之字型反爬蟲爬蟲
- 爬蟲進階:反反爬蟲技巧爬蟲
- 爬蟲爬蟲
- 爬蟲搭建代理池、爬取某網站影片案例、爬取新聞案例爬蟲網站
- [烈格黑街][福利]第一個java爬蟲程式Java爬蟲
- 爬蟲專案(一)爬蟲+jsoup輕鬆爬知乎爬蟲JS
- 【爬蟲】爬蟲專案推薦 / 思路爬蟲
- 網路爬蟲——爬蟲實戰(一)爬蟲
- 【python爬蟲】python爬蟲demoPython爬蟲
- 爬蟲那些事-爬蟲設計思路爬蟲
- 教你用Python爬取圖蟲網Python
- 如何有效防爬蟲?教你打造安全堡壘爬蟲
- 爬蟲:HTTP請求與HTML解析(爬取某乎網站)爬蟲HTTPHTML網站
- 如何使用robots禁止各大搜尋引擎爬蟲爬取網站爬蟲網站
- Python爬蟲小專案:爬一個圖書網站Python爬蟲網站
- 爬蟲與反爬蟲技術簡介爬蟲
- 爬蟲技術(二)-客戶端爬蟲爬蟲客戶端
- 爬蟲福利二 之 妹子圖網MM批量下載爬蟲