【Lucene&&Solr】Lucene索引和搜尋流程
全文檢索:先建立索引,在對索引進行搜尋的過程
使用Lucene實現全文檢索,其流程包含兩個過程,索引建立過程和索引查詢過程
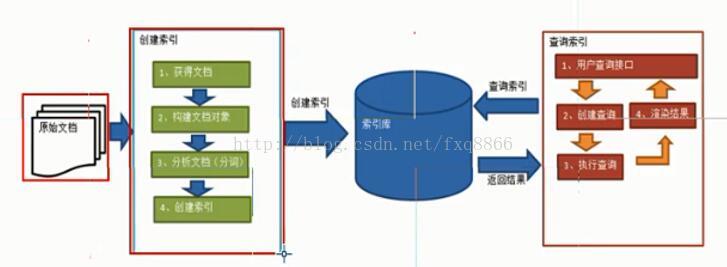
建立索引:
1.獲取文件
2.建立文件物件
3.分析文件
4.建立索引
把建立好的索引和原始文件放入到索引庫中。
查詢索引
1.使用者查詢介面
2.建立查詢
3.執行查詢,查詢索引庫
4.根據索引庫返回結果進行渲染
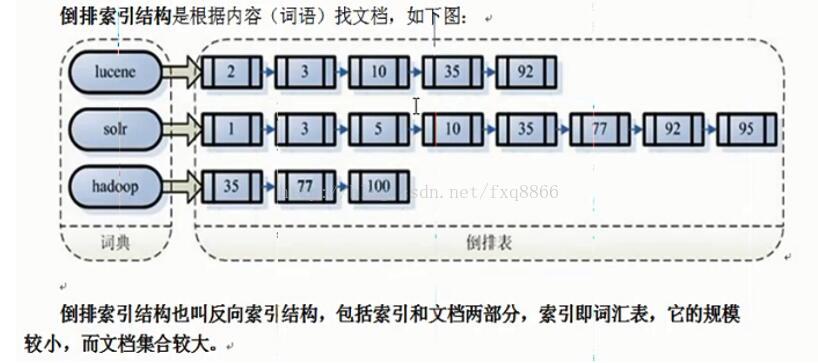
索引的目的是為了搜尋,建立索引是對語彙單元索引,通過詞語找文件,稱為倒排索引結構。
建立索引:
public IndexWriter getIndexWriter() throws Exception
{
//1.儲存到記憶體中
//Directory directory = new RAMDirectory();
//1.指定索引庫的存放位置Directory;
Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index"));
//2.指定一個分析器,對文件內容進行分析
Analyzer analyzer = new IKAnalyzer();//StandardAnalyzer();//官方推薦
IndexWriterConfig config = new IndexWriterConfig(Version.LATEST,analyzer);
return new IndexWriter(directory,config);
}
@Test
public void createIndex() throws Exception
{
//建立一個indexWriter物件
IndexWriter indexWriter = getIndexWriter();
//建立filed物件,將filed新增到document物件中
File f = new File("E:\\tempLucencsolr\\searchSource");
File[] listFiles = f.listFiles();
for (File file:listFiles) {
//建立document物件
Document document = new Document();
//檔名稱
String file_name = file.getName();
Field fileNameField = new TextField("fileName",file_name, Field.Store.YES);
//檔案大小
Long file_size = FileUtils.sizeOf(file);
Field fileSizeField = new LongField("fileSize",file_size, Field.Store.YES);
//檔案路徑
String file_path = file.getPath();
Field filePathField = new StoredField("filePath",file_path);
//檔案內容
String file_content = FileUtils.readFileToString(file);
Field fileContentField = new TextField("fileContent",file_content, Field.Store.NO);
document.add(fileNameField);
document.add(fileSizeField);
document.add(filePathField);
document.add(fileContentField);
//使用indexWriter物件將document物件寫入索引庫,此過程進行索引建立,並將
//索引和document物件寫入索引庫
indexWriter.addDocument(document);
}
System.out.println("lucene匯入索引建立成功");
//關係IndexWriter物件
indexWriter.close();
}檢索索引:
@Test
public void testSearcher() throws Exception
{
//第一步:建立一個Directory物件,索引庫存放的位置
Directory directory = FSDirectory.open(new File("E:\\tempLucencsolr\\index"));
//第二步: 建立一個indexReader物件,需要指定Directory物件
IndexReader indexreader = DirectoryReader.open(directory); //流
//第三步:建立一個indexsearcher物件,需要指定IndexReader物件
IndexSearcher indexSearcher = new IndexSearcher(indexreader);//搜尋物件
//第四步:建立一個TermQuery物件,指定查詢的域和查詢的關鍵詞
Query query =new TermQuery(new Term("fileContent","jvm"));
//第五步:執行查詢
TopDocs topDocs= indexSearcher.search(query,2);
//第六步:返回查詢結果,遍歷查詢結果並輸出
ScoreDoc[] scoreDocs= topDocs.scoreDocs; //評分之後的文件。
for (ScoreDoc scoreDoc:scoreDocs)
{
int doc= scoreDoc.doc;
System.out.println("文件編號:"+doc);
Document document = indexSearcher.doc(doc); //根據文件編號查詢文件
//檔名稱
String fileName = document.get("fileName");
System.out.println(fileName);
//檔案內容
String fileContent = document.get("fileContent");
System.out.println(fileContent);
//檔案路徑
String filePath = document.get("filePath");
System.out.println(filePath);
}
System.out.println("搜尋執行結束");
//第七步:關閉IndexReader物件
indexreader.close();
}相關文章
- Lucene建立索引流程索引
- 網站搜尋功能lucene網站
- 利用Lucene搜尋Java原始碼Java原始碼
- 【Lucene&&Solr】Windows搭建solr伺服器SolrWindows伺服器
- 請教搜尋引擎lucene怪事件事件
- Lucene原始碼解析--搜尋過程<二>原始碼
- Lucene : 基於Java的全文搜尋引擎Java
- java+lucene中文分詞,搜尋引擎搜詞剖析Java中文分詞
- 開源搜尋技術的核心引擎 —— Lucene
- MySQL InnoDB搜尋索引的StopwordsMySql索引
- 搜尋引擎索引資料結構和演算法索引資料結構演算法
- 使用者自然搜尋流程
- 談談對搜尋技術Elastic Search&Lucene的理解AST
- Tantivy與Quickwit:類似Lucene的Rust全文搜尋引擎庫UIRust
- 8 個基於 Lucene 的開源搜尋引擎推薦
- 【新書下載】征服Ajax+Lucene――構建搜尋引擎新書
- 谷歌數月內推移動搜尋索引 PC搜尋退居二線谷歌索引
- 搜尋引擎:MapReduce實戰----倒排索引索引
- Lucene輕量級搜尋引擎,真的太強了!!!Solr 和 ES 都是基於它Solr
- 搜尋引擎索引的資料結構和演算法索引資料結構演算法
- Lucene中建立索引的效率和刪除索引的實現索引
- 將Lucene搜尋查詢轉換為.NET的EF表示式
- Lucene底層原理和最佳化經驗分享(1)-Lucene簡介和索引原理索引
- Lucene是jive的搜尋引擎系統 一篇英文介紹:
- lucene第一步,lucene基礎,索引建立索引
- 產品級搜尋技術-全文字索引索引
- 搜尋引擎工作的基礎流程與原理
- 【預研】搜尋引擎基礎——inverted index(倒排索引)Index索引
- Lucene的IK分詞器學習,增加支援單個特殊符號搜尋分詞符號
- SQL Server 全文搜尋功能、全文索引方式介紹SQLServer索引
- Elasticsearch核心技術(五):搜尋API和搜尋執行機制ElasticsearchAPI
- 搜尋趨勢:微軟必應新版整合AI和實時搜尋微軟AI
- 關於mongodb和搜尋引擎??MongoDB
- hadoop異構儲存+lucene索引Hadoop索引
- lucene join解決父子關係索引索引
- 海量資料搜尋---搜尋引擎
- 啟發式搜尋的方式(深度優先,廣度優先)和 搜尋方法(Dijkstra‘s演算法,代價一致搜尋,貪心搜尋 ,A星搜尋)演算法
- 苦苦的搜尋真正工作後開發專案流程