從去年七月起,Google就號稱了其面向深度學習的專用積體電路(ASIC)產品——Tensor Processing Unit (TPU),然而其神秘面紗一直未被揭開。直至本週,Google公開了其向ISCA(國際計算機體系架構年會)投稿的的預錄取論文——In Datacenter Performance Analysis of a Tensor Processing Unit,TPU的技術細節才公開發表,令我們才有幸見識其真面目。雖然可能只是“猶抱琵琶半遮面”,但其作為CPU/GPU/FPGA後的另一深度學習選項,特別是TPU和tensorflow間可能存在的微妙聯絡值得我們特別關注。矽說在第一時間選編、翻譯了其中的重要部分,以饗讀者。

論文地址:(需翻牆) https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view
前言
文章具體描述了Tensor Processing Unit (TPU)的體系結構,並與目前主流的CPU(Intel Haswell Xeon)和GPU(Nvidia K80)的效能做出了比較,採用的benchmark包含了CNN,RNN(LSTM)和全連結(MLP)神經網路。其特點包括:
(1) 面向inference的專用app與硬體,強調了吞吐率上的效能
(2) TPU的不僅在面積和功耗上低於GPU,而且在乘累加的數量和儲存器容量是K80的25倍和3.5倍
(3) TPU的速度上的優勢明顯,達到GPU和CPU的15到30倍
(4) 在6個NN架構中,4種神經網路的效能瓶頸在於儲存器頻寬。若儲存器頻寬達到K80的效能,作者相信效能能提升到30到50倍
(5) TPU的能效值(TOPS/W)達到在目前其他產品的30到80倍
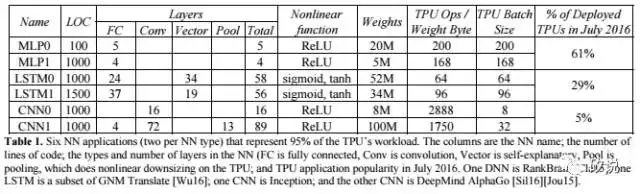
(6) CNN在TPU中工作量的比列只有5%
起源、架構與實現
早在2006年開始,Google就開始討論在資料中心部署GPU,FPGA或定製ASIC。在2013年,當DNN已經展露頭腳,以致可能會使我們的資料中心的計算需求加倍時,傳統的CPU已經被認為不合時宜了。因此,我們開始了一個高度優先的專案,以快速生成用於Inference的定製ASIC,(訓練仍使用GPU)。 目標是將效能提升10倍以上。 根據這一任務,Google的TPU的設計和驗證在短短15個月內完成,並構建並部署在資料中心。
而不是與CPU緊密整合,為了減少延遲部署的可能性,TPU被設計為PCIe I/O匯流排上的協處理器,允許它像GPU那樣插入現有的伺服器。 此外,為了簡化硬體設計和除錯,主機伺服器傳送TPU指令來執行,而不是自己提取它們。 因此,TPU在精神上比FPU(浮點單元)協處理器更接近於GPU。
TPU的目標是執行整體深度學習的神經網路模型,以減少與主機CPU的互動,並且具有足夠的靈活性,以滿足2015年及其後的NN需求,而不僅僅是2013年NN所需。

圖1是TPU的整體體系架構。TPU指令透過PCIe Gen3 x16匯流排從主機傳送到指令緩衝區。 內部塊通常透過256位元組寬的路徑連線在一起。 從右上角開始,Matrix Multiply Unit是TPU的核心。 它包含256x256個乘累加單元(MAC),可以對有符號或無符號整數執行8位乘法和加法。 求和單元(Accumulator)的輸入為16位乘積,輸出和的位寬為32,共有4906個,每個的輸入個數為256。 因此,矩陣單元每個時鐘週期產生一個256元素的部分和。
當使用8位權重和16位啟用函式的混合計算結構時,MMU的計算速度將減半,當它們都是16位,計算速度將減為四分之一。 它每個時鐘週期讀取和寫入256個值,並且可以執行矩陣乘法或卷積。 矩陣單元採用兩個64KiB的權重tile的雙緩衝設計,其中的一個僅在非稀疏模式下才會被啟用,這樣就提升了TPU對於稀疏網路的效能支援。Google相信稀疏性將在未來的設計中佔有優先地位。
矩陣單元的權重透過片上Weight FIFO進行分級,該FIFO從片外8 GiB DRAM讀取(在inference中,權重是隻讀的)。Weight FIFO儲存了四個4個tile。 中間結果儲存在24 MiB片上Unified Buffer中,可作為未來的Matrix單元的輸入。 可程式設計DMA控制器向CPU主機記憶體和Unified Buffer傳輸資料。

圖2顯示了TPU晶片的佈局圖。 24 MiB Unified Buffer幾乎是晶片的三分之一,Matrix Multiply Unit是四分之一,因此資料路徑佔到了整個晶片的三分之二。由於開發時間短,部分設計選取了簡單的值以簡化編譯器設計。 控制邏輯佔到總面積的只有2%。 圖3顯示了搭載在PCB上的TPU實現圖,期介面類似SATA磁碟,可透過PCIe直接接入資料中心。

TPU的指令是透過PCI額髮射的,遵循CISC傳統,包括重複欄位。 這些CISC指令的每個指令的平均時鐘週期(CPI)在10到20之間。它總共有大約十多個指令,這裡羅列最關鍵的五個:
(1) Read_Host_Memory
(2) Read_Weights
(3) MatrixMultiply/Convolve
(6) Activation
(5) Write_Host_Memory
其他指令是備用主機記憶體讀/寫,設定配置,兩個版本的同步,中斷主機,除錯Jtag,空操作和停止。 CISC MatrixMultiply指令為12個位元組,其中3個為Unified Buffer地址; 2是累加器地址; 4是長度(有時是卷積的2個維度); 其餘的是操作碼和標誌。TPU微架構的理念是保持MMU的繁忙。 因此,MMC的CISC指令使用4級流水線結構,其中每條指令在其中的單獨一級執行。 其目標是透過將其執行與MatrixMultiply指令重疊來隱藏其他指令(如Read_Weights等)。但,當啟用的輸入或權重資料尚未就緒,矩陣單元將進入等待模式。
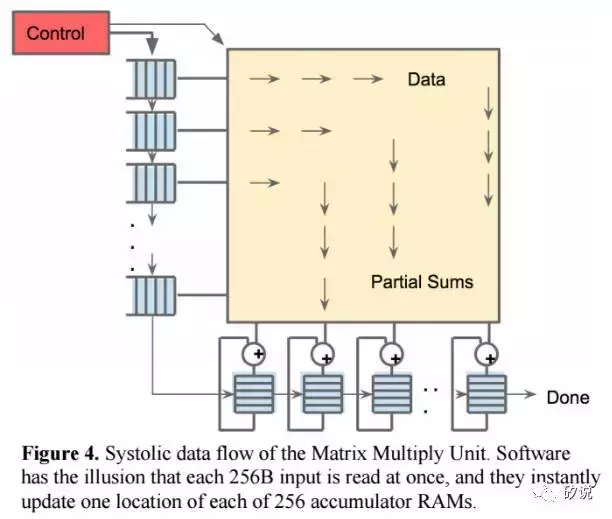
由於讀取大型SRAM資料的功耗比算術功耗高的多,所以MMU透過systolic方式減少對Unified Buffer的方位,節省功耗。 圖4顯示了TPU資料流程,輸入從左側流入,權重從頂部載入。 給定的256元乘法累加運算透過矩陣作為對角波前移動。 此過程中權重是預先載入的,並且與資料同步。透過對控制邏輯和資料流水線操作,使得對於MMU而言,256個輸入一次讀取的,並且它們立即更新到256個累加器中的一個個具體位置。 從正確的角度來看,軟體不知道硬體的systoli特性,但是卻需要對於systoilc引起的延時效果有正確的評估。
TPU軟體堆疊必須與為CPU和GPU開發的軟體棧相容,以便應用程式可以快速移植到TPU。在TPU上執行的應用程式的一部分通常寫在TensorFlow中,並被編譯成可以在GPU或TPU上執行的API。像GPU一樣,TPU堆疊分為使用者空間驅動程式和核心驅動程式。核心驅動程式是輕量級的且長期穩定的,只處理記憶體管理和中斷。使用者空間驅動程式頻繁更改。它設定和控制TPU執行,將資料重新格式化為TPU命令,將API呼叫轉換為TPU指令,並將其轉換為應用程式二進位制檔案。使用者空間驅動程式在首次評估模型時編譯模型,快取程式映像並將重量映像寫入TPU的重量儲存器; 第二次和以下評估全速執行。 對於大部分模型,TPU可以從輸入到輸出完整實現。實際操作中,同一時間通常每次進行一層的MMC計算,而其非關鍵路徑操作將被隱藏在MMU操作下。
CPU、GPU與TPU的效能比較
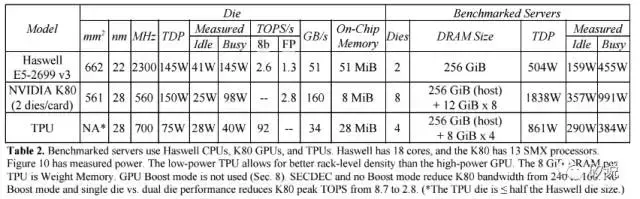
在TPU與CPU和GPU的效能比較部分,Google選擇了兩款並非最新但具有代表性的平臺——Intel Haswell架構的Xeon 5處理器和Nvidia的K80處理器,其整合板卡後的效能對比如下:
以MLP0為例子,7ms的反應時間內TPU可得到的資料處理吞吐率是CPU和GPU的數十倍(但值得指出的是,該benchmark下TPU的計算佔用率要遠遠高於GPU和CPU)。
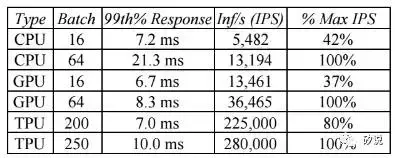
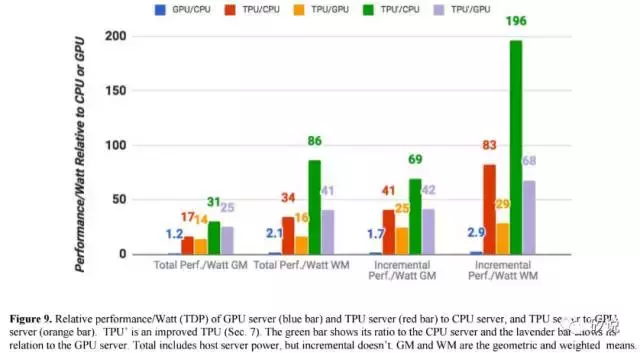
圖9將K80 GPU和TPU相對於Haswell CPU的幾何平均功耗效能進行了對比,包括兩種計算量程——第一個是“總計”效能/瓦,包括在計算GPU和TPU的效能/瓦特時由主機CPU伺服器消耗的功率。;第二個“增量”效能/瓦,僅包括預先從GPU和TPU中減去主機CPU伺服器的電源餘下的功耗。TPU伺服器的總效能/瓦特比Haswell高出17到34倍,這使得TPU伺服器的效能/ Katt伺服器的功率是14到16倍。 TPU的相對增量效能/瓦特(Google致力於定製ASIC的核心價值)為41到83,這將TPU提升到GPU的效能/瓦特的25到29倍。