爬蟲專案(一)爬蟲+jsoup輕鬆爬知乎
爬蟲+jsoup輕鬆爬知乎
爬知乎是為了測試除錯爬蟲,而且知乎很好爬,也建議新手爬一爬知乎和百度知道之類的網站入門。
最近對大資料很感興趣,趁著寫爬蟲的勁把java也學了。本人之前很少接觸面相物件的程式語言,只有少量的VB基礎。瞭解java之後才發現面嚮物件語言之美。(對我這樣只是把程式設計當愛好的fish而言)java最美妙的地方即是有豐富的jar包可以呼叫,還有大神更新源源不斷的jar包,比起以前寫C語言,每一行程式碼都自己敲,現在寫java,敲一個點,n多功能函式直接呼叫,而且程式碼質量都很高,簡直就是搬磚屌絲到摸腿高富帥的升級!
我最開始寫的爬蟲沒用jsoup包,直接用java自帶的httpconnect獲取,用parttern,matcher加正則語法篩選標籤和元素。正則語法看的暈,parttern定義的模板通用性很差。做出來的爬蟲整體程式碼冗長,完全沒有程式碼的美感。
本次寫的爬蟲呼叫了jsoup jar包,jsoup是優秀的HTML解析器,可通過DOM,CSS以及類似於jQuery的操作方法來取出和運算元據,而且封裝了get方法,可以直接呼叫獲取頁面。結合谷歌瀏覽器抓取頁面元素快感不斷。下面簡單介紹一下用法順便貼個知乎爬知乎的程式碼。
jsoup包的import就不說了,jsoup最主要用到的就是的elements類和select()方法。elements類相當於網頁元素中的標籤,而select()方法用於按一定條件選取符合條件的標籤,組成符合條件的標籤陣列。element支援轉成字串或者文字等。總之功能很強大。只需要瞭解一下select()方法的過濾規則即可上手用了。但是有了谷歌瀏覽器!過濾規則都不用管了,直接上手用!
來個示例:
1.開啟谷歌瀏覽器,右鍵單機想要抓取的元素,比如我右擊了“Spring的JavaConfig註解這篇文章”選擇檢查,自動跳出原始碼框,並且定位到右鍵的元素的位置。
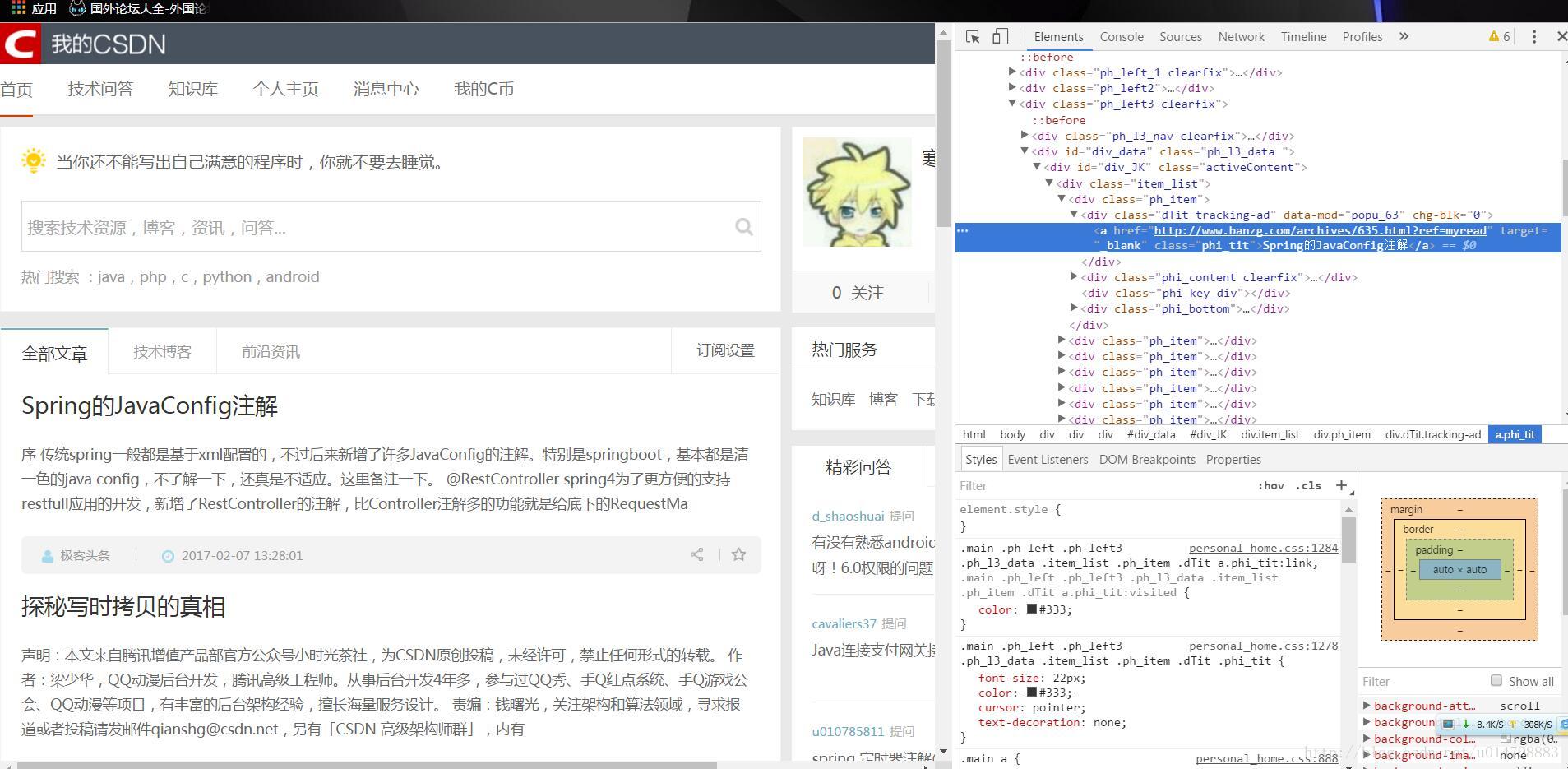
2.右鍵點選程式碼行,copy–>copy selector

3.這時候我們可以貼出來看看copy到的東西:
#div_JK > div.item_list > div:nth-child(1) > div.dTit.tracking-ad > a表明了目標在網頁程式碼中的位置,每個>前後面都代表一個檢索條件。那麼我們要得到這個標籤,只要這樣寫:
//下載網頁
String URL="輸入網址";
Document document=Jsoup.cnnect("URL");
//在下載的document裡進行檢索的語句
elements test=document.select("#div_JK")
.select("div.item_list").select("div:nth-child(1)").select("div.dTit.tracking-ad").select("a");
//這樣test標籤就是我們最開始右鍵單擊檢查的標籤
String Str=test.toString();//將標籤轉化成字串
String text=test.text();//將標籤裡的文字提取出來
//其他轉換方法省略,檢索到目標標籤,提取標籤裡的特定元素so easy下面貼一下寫的爬知乎程式碼,知乎和貼吧之類的網站都很好爬。
目標是把知乎編輯推薦的所有熱門問題的URL、問題名、問題描述、答案,都列印出來。
程式碼塊
簡單的java爬蟲程式碼:
package jsouptest;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupTest {
public static void main(String[] args) throws IOException {
//獲取編輯推薦頁
Document document=Jsoup.connect("https://www.zhihu.com/explore/recommendations")
//模擬火狐瀏覽器
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
Element main=document.getElementById("zh-recommend-list-full");
Elements url=main.select("div").select("div:nth-child(2)")
.select("h2").select("a[class=question_link]");
for(Element question:url){
//輸出href後的值,即主頁上每個關注問題的連結
String URL=question.attr("abs:href");
//下載問題連結指向的頁面
Document document2=Jsoup.connect(URL)
.userAgent("Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)")
.get();
//問題
Elements title=document2.select("#zh-question-title").select("h2").select("a");
//問題描述
Elements detail=document2.select("#zh-question-detail");
//回答
Elements answer=document2.select("#zh-question-answer-wrap")
.select("div.zm-item-rich-text.expandable.js-collapse-body")
.select("div.zm-editable-content.clearfix");
System.out.println("\n"+"連結:"+URL
+"\n"+"標題:"+title.text()
+"\n"+"問題描述:"+detail.text()
+"\n"+"回答:"+answer.text());
}
}
}抓取效果圖:

eclipse編輯器不支援自動換行,所以文字都堆在一行,可以用file類把抓取到的資料儲存到本地txt檔案或doc之類的檔案裡。
寫爬蟲的第一個目標是抓攜程之類的機票資料,當然不是為了做大資料分析,就是給自己用。大家都知道攜程途牛之類,機票最便宜的時候不是起飛前一天,也不是起飛前一個月,大概是起飛前十天十幾天,這時候機票價格有個波谷。因此想寫個機票爬蟲部署到伺服器上,順手再寫個安卓app傳遞爬取目標到伺服器,讓爬蟲爬。爬的次數也不多,一天爬兩三次就夠了,也省的研究反爬蟲了,機票進入期望價格或者波谷的時候,發個訊息通知我即可,手動買票。
是的,如果順利的話還會有3-4篇後續的文章,直到完成這個專案。為了可以多坐幾次飛機見小女友,祝自己成功!
相關文章
- 【爬蟲】爬蟲專案推薦 / 思路爬蟲
- 爬蟲專案爬蟲
- 不會Python爬蟲?教你一個通用爬蟲思路輕鬆爬取網頁資料Python爬蟲網頁
- 【Python學習】爬蟲爬蟲爬蟲爬蟲~Python爬蟲
- 精通Scrapy網路爬蟲【一】第一個爬蟲專案爬蟲
- 爬蟲解析庫:XPath 輕鬆上手爬蟲
- 在scrapy框架下建立爬蟲專案,建立爬蟲檔案,執行爬蟲檔案框架爬蟲
- python爬蟲初探--第一個python爬蟲專案Python爬蟲
- 爬蟲小專案爬蟲
- 爬蟲專案部署爬蟲
- 建立爬蟲專案爬蟲
- Java 爬蟲專案實戰之爬蟲簡介Java爬蟲
- python爬蟲如何爬知乎的話題?Python爬蟲
- 爬蟲專案實戰(一)爬蟲
- 爬蟲小專案(一)淘寶爬蟲
- Scrapy 輕鬆定製網路爬蟲爬蟲
- 爬蟲:多程式爬蟲爬蟲
- 網路爬蟲——爬蟲實戰(一)爬蟲
- 輕鬆利用Python爬蟲爬取你想要的資料Python爬蟲
- python 爬蟲——登入知乎Python爬蟲
- python爬蟲專案(新手教程)之知乎(requests方式)Python爬蟲
- 奇伢爬蟲專案爬蟲
- 爬蟲專案總結爬蟲
- 網路爬蟲專案爬蟲
- scrapyd 部署爬蟲專案爬蟲
- Scrapy建立爬蟲專案爬蟲
- Python爬蟲教程-31-建立 Scrapy 爬蟲框架專案Python爬蟲框架
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- 通用爬蟲與聚焦爬蟲爬蟲
- 爬蟲--Scrapy簡易爬蟲爬蟲
- 一個月入門Python爬蟲,輕鬆爬取大規模資料Python爬蟲
- 分散式爬蟲之知乎使用者資訊爬取分散式爬蟲
- Java爬蟲利器HTML解析工具-JsoupJava爬蟲HTMLJS
- [網路爬蟲] Jsoup : HTML 解析工具爬蟲JSHTML
- 反爬蟲之字型反爬蟲爬蟲
- 爬蟲進階:反反爬蟲技巧爬蟲
- 爬蟲實戰專案集合爬蟲
- 爬蟲的例項專案爬蟲