Python簡單爬蟲專案
專案搭建過程
一、新建python專案
在對應的地址 中 開啟 cmd
輸入:scrapy startproject first
2、在pyCharm 中開啟新建立的專案,建立spider 爬蟲核心檔案ts.py
import scrapy
from first.items import FirstItem
from scrapy.http import Request # 模擬瀏覽器爬蟲
class WeisuenSpider(scrapy.Spider):
name = ‘ts’
allowed_domains = [‘hellobi.com’]
start_urls = (
‘https://edu.hellobi.com/course/100/‘,
)
# 模擬瀏覽器爬蟲
def start_requests(self):
ua={
“User-Agent”: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE’}
yield Request(‘https://edu.hellobi.com/course/100/‘,headers=ua)
def parse(self, response):
item=FirstItem()
item[“title”]=response.xpath(“//ol[@class=’breadcrumb’]/li[@class=’active’]/text()”).extract()
item[“view”]=response.xpath(“//div/span[@class=’course- view’]/text()”).extract()
yield item #用來返回
3、在items 中編輯需要爬取的內容
import scrapy
class FirstItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field() # 爬取標題
view=scrapy.Field() # 爬取觀看人數
4、在 ts.py 中利用xpath 設定爬取規則
from first.items import FirstItem
def parse(self, response):
item=FirstItem()
item[“title”]=response.xpath(“//ol[@class=’breadcrumb’]/li[@class=’active’]/text()”).extract()
item[“view”]=response.xpath(“//div/span[@class=’course-view’]/text()”).extract()
yield item #用來返回
5、在pipelines.py設定輸出
class FirstPipeline(object):
def process_item(self, item, spider):
print(item[“title”])
print(item[“view”])
return item
6、在 setting.py 中開啟 pipelines 和設定預設的爬蟲規則為False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
ITEM_PIPELINES = {
‘first.pipelines.FirstPipeline’: 300,
}
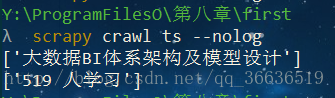
7、執行結果
總結
1、關於python直譯器的問題
pyCharm 在設定預設直譯器時有提供三種不同的方式
- Virtualenv Environment
- Conda Environment
- System Interpreter
應選擇 System Interpreter
2、關於xpath的總結
- / 表示從頂端去提取資訊
/html/head/title/text() 表示:提取 html 下面的 head 下面的 title 下面的 text() 標籤
- // 尋找所有的標籤
//ol/il/text() 表達:提取 所有 的 ol 標籤下面的 il 標籤下面的 text()標籤
- @ 提取標籤下的屬性值:
//li[@class=”hidden-xs”]/a/@href
提取 含有 class=”hidden-xs” 的li 標籤 下的 a 標籤 下的 href 屬性
3、 srapy 命令 總結
- 全域性命令(全域性命令可以在全域性使用,包括專案)
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
fetch
scrapy fetch http://www.baidu.com 作用:爬取百度網頁資訊
scrapy fetch http://www.baidu.com –nolog 不顯示日子的爬取
runspider
不依託爬蟲專案(資料夾),來執行爬蟲檔案(program.py)
在檔案所在目錄下:輸入 scrapy runspider first.py
startproject 建立一個專案
scrapy startproject 專案名
view 下載某個網頁,並且用瀏覽器來檢視的命令
scrapy view http://news.163.com
scrapy genspider -l 羅列所有的爬蟲母版
basic 基本爬蟲母版
crawl 自動爬蟲母版
csvfeed 用於csv 檔案
xmlfeed 用於xml 檔案
常用命令:
scrapy genspider -t basic 爬蟲檔名 域名
crawl 執行某個爬蟲
scrapy crawl 爬蟲名(不用加py)
4、爬蟲專案結構
first (專案名稱)
first 資料夾
scrapy.efg
first 資料夾:(核心目錄)
- spiders 資料夾
- init.py
- items.py
- pipeline.py
- settings.py
init.py 爬蟲專案的初始化檔案
items.py 爬蟲需要爬取的內容 ,是個容器
pipeline.py 爬取資訊後的過濾檔案
setting,py 對爬蟲進行設定 偽裝瀏覽器,使用者代理
相關文章
- python簡單爬蟲(二)Python爬蟲
- Java 爬蟲專案實戰之爬蟲簡介Java爬蟲
- Python爬蟲專案整理Python爬蟲
- 簡單瞭解python爬蟲Python爬蟲
- python爬蟲初探--第一個python爬蟲專案Python爬蟲
- python爬蟲:爬蟲的簡單介紹及requests模組的簡單使用Python爬蟲
- 簡單的Python爬蟲 就是這麼簡單Python爬蟲
- Python網路爬蟲實戰專案大全 32個Python爬蟲專案demoPython爬蟲
- 專案--python網路爬蟲Python爬蟲
- 網路爬蟲(python專案)爬蟲Python
- 33個Python爬蟲專案Python爬蟲
- Python爬蟲入門專案Python爬蟲
- python爬蟲簡歷專案怎麼寫_爬蟲專案咋寫,爬取什麼樣的資料可以作為專案寫在簡歷上?...Python爬蟲
- python爬蟲例項專案大全-GitHub 上有哪些優秀的 Python 爬蟲專案?Python爬蟲Github
- python爬蟲-33個Python爬蟲專案實戰(推薦)Python爬蟲
- 用PYTHON爬蟲簡單爬取網路小說Python爬蟲
- Python爬蟲學習(5): 簡單的爬取Python爬蟲
- Python爬蟲教程-31-建立 Scrapy 爬蟲框架專案Python爬蟲框架
- 爬蟲專案爬蟲
- python爬蟲實操專案_Python爬蟲開發與專案實戰 1.6 小結Python爬蟲
- Python代理IP爬蟲的簡單使用Python爬蟲
- 一個簡單的python爬蟲程式Python爬蟲
- Python爬蟲開源專案合集Python爬蟲
- 32個Python爬蟲專案demoPython爬蟲
- python爬蟲例項專案大全Python爬蟲
- 【爬蟲】爬蟲專案推薦 / 思路爬蟲
- 如何簡單高效地部署和監控分散式爬蟲專案分散式爬蟲
- 簡單的爬蟲程式爬蟲
- 不踩坑的Python爬蟲:Python爬蟲開發與專案實戰,從爬蟲入門 PythonPython爬蟲
- (python)爬蟲----八個專案帶你進入爬蟲的世界Python爬蟲
- Python爬蟲開發與專案實戰——基礎爬蟲分析Python爬蟲
- Python爬蟲開發與專案實戰 3: 初識爬蟲Python爬蟲
- 爬蟲小專案爬蟲
- 爬蟲專案部署爬蟲
- 建立爬蟲專案爬蟲
- python爬蟲簡單實現逆向JS解密Python爬蟲JS解密
- Python爬蟲 --- 2.3 Scrapy 框架的簡單使用Python爬蟲框架
- Python開發爬蟲專案+程式碼Python爬蟲