機器學習系列(7)_機器學習路線圖(附資料)
作者: 龍心塵 && 寒小陽
時間:2016年2月。
出處:http://blog.csdn.net/longxinchen_ml/article/details/50749614
http://blog.csdn.net/han_xiaoyang/article/details/50759472
宣告:版權所有,轉載請聯絡作者並註明出處
1. 引言
也許你和這個叫『機器學習』的傢伙一點也不熟,但是你舉起iphone手機拍照的時候,早已習慣它幫你框出人臉;也自然而然點開今日頭條推給你的新聞;也習慣逛淘寶點了找相似之後貨比三家;亦或喜聞樂見微軟的年齡識別網站結果刷爆朋友圈。恩,這些功能的核心演算法就是機器學習領域的內容。
套用一下大神們對機器學習的定義,機器學習研究的是計算機怎樣模擬人類的學習行為,以獲取新的知識或技能,並重新組織已有的知識結構使之不斷改善自身。簡單一點說,就是計算機從資料中學習出規律和模式,以應用在新資料上做預測的任務。近年來網際網路資料大爆炸,資料的豐富度和覆蓋面遠遠超出人工可以觀察和總結的範疇,而機器學習的演算法能指引計算機在海量資料中,挖掘出有用的價值,也使得無數學習者為之著迷。
但是越說越覺得機器學習有距離感,雲裡霧裡高深莫測,我們不是專家,但說起算有一些從業經驗,做過一些專案在實際資料上應用機器學習。這一篇就我們的經驗和各位同仁的分享,總結一些對於初學者入門有幫助的方法和對進階有用的資料。
#2. 機器學習關注問題
並非所有的問題都適合用機器學習解決(很多邏輯清晰的問題用規則能很高效和準確地處理),也沒有一個機器學習演算法可以通用於所有問題。我們們先來了解了解,機器學習,到底關心和解決什麼樣的問題。
從功能的角度分類,機器學習在一定量級的資料上,可以解決下列問題:
1.分類問題
- 根據資料樣本上抽取出的特徵,判定其屬於有限個類別中的哪一個。比如:
- 垃圾郵件識別(結果類別:1、垃圾郵件 2、正常郵件)
- 文字情感褒貶分析(結果類別:1、褒 2、貶)
- 影像內容識別識別(結果類別:1、喵星人 2、汪星人 3、人類 4、草泥馬 5、都不是)。
2.迴歸問題
- 根據資料樣本上抽取出的特徵,預測一個連續值的結果。比如:
- 星爺《美人魚》票房
- 大帝都2個月後的房價
- 隔壁熊孩子一天來你家幾次,寵幸你多少玩具
3.聚類問題
- 根據資料樣本上抽取出的特徵,讓樣本抱抱團(相近/相關的樣本在一團內)。比如:
- google的新聞分類
- 使用者群體劃分
我們再把上述常見問題劃到機器學習最典型的2個分類上。
- 分類與迴歸問題需要用已知結果的資料做訓練,屬於**“監督學習”**
- 聚類的問題不需要已知標籤,屬於**“非監督學習”**。
如果在IT行業(尤其是網際網路)裡溜達一圈,你會發現機器學習在以下熱點問題中有廣泛應用:
1.計算機視覺
- 典型的應用包括:人臉識別、車牌識別、掃描文字識別、圖片內容識別、圖片搜尋等等。
2.自然語言處理
- 典型的應用包括:搜尋引擎智慧匹配、文字內容理解、文字情緒判斷,語音識別、輸入法、機器翻譯等等。
3.社會網路分析
- 典型的應用包括:使用者畫像、網路關聯分析、欺詐作弊發現、熱點發現等等。
4.推薦
- 典型的應用包括:蝦米音樂的“歌曲推薦”,某寶的“猜你喜歡”等等。
#3. 入門方法與學習路徑
OK,不廢話,直接切重點丟乾貨了。看似學習難度大,曲線陡的機器學習,對大多數入門者也有一個比較通用的學習路徑,也有一些優秀的入門資料可以降低大家的學習門檻,同時激發我們的學習樂趣。
簡單說來,大概的一個學習路徑如下:
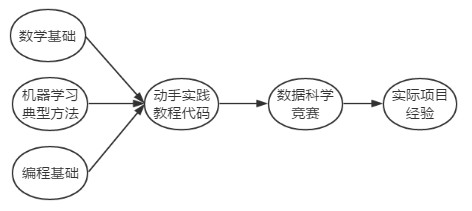
簡單說一點,之所以最左邊寫了『數學基礎』『典型機器學習演算法』『程式設計基礎』三個並行的部分,是因為機器學習是一個將數學/演算法理論和工程實踐緊密結合的領域,需要紮實的理論基礎幫助引導資料分析與模型調優,同時也需要精湛的工程開發能力去高效化地訓練和部署模型和服務。
需要多說一句的是,在網際網路領域從事機器學習的人,有2類背景的人比較多,其中一部分(很大一部分)是程式設計師出身,這類同學工程經驗相對會多一些,另一部分是學數學統計領域的同學,這部分同學理論基礎相對紮實一些。因此對比上圖,2類同學入門機器學習,所欠缺和需要加強的部分是不一樣的。
下面就上述圖中的部分,展開來分別扯幾句:
##3.1 數學基礎
有無數激情滿滿大步向前,誓要在機器學習領域有一番作為的同學,在看到公式的一刻突然就覺得自己狗帶了。是啊,機器學習之所以相對於其他開發工作,更有門檻的根本原因就是數學。每一個演算法,要在訓練集上最大程度擬合同時又保證泛化能力,需要不斷分析結果和資料,調優引數,這需要我們對資料分佈和模型底層的數學原理有一定的理解。所幸的是如果只是想合理應用機器學習,而不是做相關方向高精尖的research,需要的數學知識啃一啃還是基本能理解下來的。至於更高深的部分,恩,博主非常願意承認自己是『數學渣』。
基本所有常見機器學習演算法需要的數學基礎,都集中在微積分、線性代數和概率與統計當中。下面我們先過一過知識重點,文章的後部分會介紹一些幫助學習和鞏固這些知識的資料。
###3.1.1 微積分
- 微分的計算及其幾何、物理含義,是機器學習中大多數演算法的求解過程的核心。比如演算法中運用到梯度下降法、牛頓法等。如果對其幾何意義有充分的理解,就能理解“梯度下降是用平面來逼近區域性,牛頓法是用曲面逼近區域性”,能夠更好地理解運用這樣的方法。
- 凸優化和條件最優化 的相關知識在演算法中的應用隨處可見,如果能有系統的學習將使得你對演算法的認識達到一個新高度。
###3.1.2 線性代數
- 大多數機器學習的演算法要應用起來,依賴於高效的計算,這種場景下,程式設計師GG們習慣的多層for迴圈通常就行不通了,而大多數的迴圈操作可轉化成矩陣之間的乘法運算,這就和線性代數有莫大的關係了
- 向量的內積運算更是隨處可見。
- 矩陣乘法與分解在機器學習的主成分分析(PCA)和奇異值分解(SVD) 等部分呈現刷屏狀地出現。
###3.1.3 概率與統計
從廣義來說,機器學習在做的很多事情,和統計層面資料分析和發掘隱藏的模式,是非常類似的。
- 極大似然思想、貝葉斯模型 是理論基礎,樸素貝葉斯(Na?ve Bayes )、語言模型(N-gram)、隱馬爾科夫(HMM)、隱變數混合概率模型是他們的高階形態。
- 常見分佈如高斯分佈是混合高斯模型(GMM)等的基礎。
3.2 典型演算法
絕大多數問題用典型機器學習的演算法都能解決,粗略地列舉一下這些方法如下:
- 處理分類問題的常用演算法包括:邏輯迴歸(工業界最常用),支援向量機,隨機森林,樸素貝葉斯(NLP中常用),深度神經網路(視訊、圖片、語音等多媒體資料中使用)。
- 處理迴歸問題的常用演算法包括:線性迴歸,普通最小二乘迴歸(Ordinary Least Squares Regression),逐步迴歸(Stepwise Regression),多元自適應迴歸樣條(Multivariate Adaptive Regression Splines)
- 處理聚類問題的常用演算法包括:K均值(K-means),基於密度聚類,LDA等等。
- 降維的常用演算法包括:主成分分析(PCA),奇異值分解(SVD) 等。
- 推薦系統的常用演算法:協同過濾演算法
- 模型融合(model ensemble)和提升(boosting)的演算法包括:bagging,adaboost,GBDT,GBRT
- 其他很重要的演算法包括:EM演算法等等。
我們多插一句,機器學習裡所說的**“演算法”**與程式設計師所說的“資料結構與演算法分析”裡的“演算法”略有區別。前者更關注結果資料的召回率、精確度、準確性等方面,後者更關注執行過程的時間複雜度、空間複雜度等方面。 。當然,實際機器學習問題中,對效率和資源佔用的考量是不可或缺的。
3.3 程式語言、工具和環境
看了無數的理論與知識,總歸要落到實際動手實現和解決問題上。而沒有工具所有的材料和框架、邏輯、思路都給你,也寸步難行。因此我們還是得需要合適的程式語言、工具和環境幫助自己在資料集上應用機器學習演算法,或者實現自己的想法。對初學者而言,Python和R語言是很好的入門語言,很容易上手,同時又活躍的社群支援,豐富的工具包幫助我們完成想法。相對而言,似乎計算機相關的同學用Python多一些,而數學統計出身的同學更喜歡R一些。我們對程式語言、工具和環境稍加介紹:
3.3.1 python
python有著全品類的資料科學工具,從資料獲取、資料清洗到整合各種演算法都做得非常全面。
- 網頁爬蟲: scrapy
- 資料探勘:
- pandas:模擬R,進行資料瀏覽與預處理。
- numpy:陣列運算。
- scipy:高效的科學計算。
- matplotlib:非常方便的資料視覺化工具。
- 機器學習:
- scikit-learn:遠近聞名的機器學習package。未必是最高效的,但是介面真心封裝得好,幾乎所有的機器學習演算法輸入輸出部分格式都一致。而它的支援文件甚至可以直接當做教程來學習,非常用心。對於不是非常高緯度、高量級的資料,scikit-learn勝任得非常好(有興趣可以看看sklearn的原始碼,也很有意思)。
- libsvm:高效率的svm模型實現(瞭解一下很有好處,libsvm的係數資料輸入格式,在各處都非常常見)
- keras/TensorFlow:對深度學習感興趣的同學,也能很方便地搭建自己的神經網路了。
- 自然語言處理:
- nltk:自然語言處理的相關功能做得非常全面,有典型語料庫,而且上手也非常容易。
- 互動式環境:
- ipython notebook:能直接打通資料到結果的通道,方便至極。強力推薦。
3.3.2 R
R最大的優勢是開源社群,聚集了非常多功能強大可直接使用的包,絕大多數的機器學習演算法在R中都有完善的包可直接使用,同時文件也非常齊全。常見的package包括:RGtk2, pmml, colorspace, ada, amap, arules, biclust, cba, descr, doBy, e1071, ellipse等等。另外,值得一提的是R的視覺化效果做得非常不錯,而這對於機器學習是非常有幫助的。
3.3.3 其他語言
相應資深程式設計師GG的要求,再補充一下java和C++相關機器學習package。
- Java系列
- WEKA Machine Learning Workbench 相當於java中的scikit-learn
- 其他的工具如Massive Online Analysis(MOA)、MEKA 、 Mallet 等也非常有名。
- 更多詳細的應用請參考這篇文章《25個Java機器學習工具&庫》
- C++系列
- mlpack,高效同時可擴充性非常好的機器學習庫。
- Shark:文件齊全的老牌C++機器學習庫。
3.3.4 大資料相關
3.3.5 作業系統
- mac和linux會方便一些,而windows在開發中略顯力不從心。所謂方便,主要是指的mac和linux在下載安裝軟體、配置環境更快捷。
- 對於只習慣windows的同學,推薦anaconda,一步到位安裝完python的全品類資料科學工具包。
3.4 基本工作流程
以上我們基本具備了機器學習的必要條件,剩下的就是怎麼運用它們去做一個完整的機器學習專案。其工作流程如下:
3.4.1 抽象成數學問題
- 明確問題是進行機器學習的第一步。機器學習的訓練過程通常都是一件非常耗時的事情,胡亂嘗試時間成本是非常高的。
- 這裡的抽象成數學問題,指的我們明確我們可以獲得什麼樣的資料,目標是一個分類還是迴歸或者是聚類的問題,如果都不是的話,如果劃歸為其中的某類問題。
3.4.2 獲取資料
- 資料決定了機器學習結果的上限,而演算法只是儘可能逼近這個上限。
- 資料要有代表性,否則必然會過擬合。
- 而且對於分類問題,資料偏斜不能過於嚴重,不同類別的資料數量不要有數個數量級的差距。
- 而且還要對資料的量級有一個評估,多少個樣本,多少個特徵,可以估算出其對記憶體的消耗程度,判斷訓練過程中記憶體是否能夠放得下。如果放不下就得考慮改進演算法或者使用一些降維的技巧了。如果資料量實在太大,那就要考慮分散式了。
3.4.3 特徵預處理與特徵選擇
- 良好的資料要能夠提取出良好的特徵才能真正發揮效力。
- 特徵預處理、資料清洗是很關鍵的步驟,往往能夠使得演算法的效果和效能得到顯著提高。歸一化、離散化、因子化、缺失值處理、去除共線性等,資料探勘過程中很多時間就花在它們上面。這些工作簡單可複製,收益穩定可預期,是機器學習的基礎必備步驟。
- 篩選出顯著特徵、摒棄非顯著特徵,需要機器學習工程師反覆理解業務。這對很多結果有決定性的影響。特徵選擇好了,非常簡單的演算法也能得出良好、穩定的結果。這需要運用特徵有效性分析的相關技術,如相關係數、卡方檢驗、平均互資訊、條件熵、後驗概率、邏輯迴歸權重等方法。
3.4.4 訓練模型與調優
- 直到這一步才用到我們上面說的演算法進行訓練。現在很多演算法都能夠封裝成黑盒供人使用。但是真正考驗水平的是調整這些演算法的(超)引數,使得結果變得更加優良。這需要我們對演算法的原理有深入的理解。理解越深入,就越能發現問題的癥結,提出良好的調優方案。
3.4.5 模型診斷
如何確定模型調優的方向與思路呢?這就需要對模型進行診斷的技術。
- 過擬合、欠擬合 判斷是模型診斷中至關重要的一步。常見的方法如交叉驗證,繪製學習曲線等。過擬合的基本調優思路是增加資料量,降低模型複雜度。欠擬合的基本調優思路是提高特徵數量和質量,增加模型複雜度。
- 誤差分析 也是機器學習至關重要的步驟。通過觀察誤差樣本,全面分析誤差產生誤差的原因:是引數的問題還是演算法選擇的問題,是特徵的問題還是資料本身的問題……
- 診斷後的模型需要進行調優,調優後的新模型需要重新進行診斷,這是一個反覆迭代不斷逼近的過程,需要不斷地嘗試, 進而達到最優狀態。
3.4.6 模型融合
- 一般來說,模型融合後都能使得效果有一定提升。而且效果很好。
- 工程上,主要提升演算法準確度的方法是分別在模型的前端(特徵清洗和預處理,不同的取樣模式)與後端(模型融合)上下功夫。因為他們比較標準可複製,效果比較穩定。而直接調參的工作不會很多,畢竟大量資料訓練起來太慢了,而且效果難以保證。
3.4.7 上線執行
- 這一部分內容主要跟工程實現的相關性比較大。工程上是結果導向,模型線上上執行的效果直接決定模型的成敗。 不單純包括其準確程度、誤差等情況,還包括其執行的速度(時間複雜度)、資源消耗程度(空間複雜度)、穩定性是否可接受。
這些工作流程主要是**工程實踐上總結出的一些經驗。並不是每個專案都包含完整的一個流程。**這裡的部分只是一個指導性的說明,只有大家自己多實踐,多積累專案經驗,才會有自己更深刻的認識。
3.5 關於積累專案經驗
初學機器學習可能有一個誤區,就是一上來就陷入到對各種高大上演算法的追逐當中。動不動就我能不能用深度學習去解決這個問題啊?我是不是要用boosting演算法做一些模型融合啊?我一直持有一個觀點,『脫離業務和資料的演算法討論是毫無意義的』。
實際上按我們的學習經驗,從一個資料來源開始,即使是用最傳統,已經應用多年的機器學習演算法,先完整地走完機器學習的整個工作流程,不斷嘗試各種演算法深挖這些資料的價值,在運用過程中把資料、特徵和演算法搞透,真正積累出專案經驗 才是最快、最靠譜的學習路徑。
那如何獲取資料和專案呢?一個捷徑就是積極參加國內外各種資料探勘競賽,資料直接下載下來,按照競賽的要求去不斷優化,積累經驗。國外的Kaggle和國內的DataCastle 以及阿里天池比賽都是很好的平臺,你可以在上面獲取真實的資料和資料科學家們一起學習和進行競賽,嘗試使用已經學過的所有知識來完成這個比賽本身也是一件很有樂趣的事情。和其他資料科學家的討論能開闊視野,對機器學習演算法有更深層次的認識。
有意思的是,有些平臺,比如阿里天池比賽,甚至給出了從資料處理到模型訓練到模型評估、視覺化到模型融合增強的全部元件,你要做的事情只是參與比賽,獲取資料,然後使用這些元件去實現自己的idea即可。具體內容可以參見阿里雲機器學習文件。
3.6 自主學習能力
多幾句嘴,這部分內容和機器學習本身沒有關係,但是我們覺得這方面的能力對於任何一種新知識和技能的學習來說都是至關重要的。 自主學習能力提升後,意味著你能夠跟據自己的情況,找到最合適的學習資料和最快學習成長路徑。
3.6.1 資訊檢索過濾與整合能力
對於初學者,絕大部分需要的知識通過網路就可以找到了。
google搜尋引擎技巧——組合替換搜尋關鍵詞、站內搜尋、學術文獻搜尋、PDF搜尋等——都是必備的。
一個比較好的習慣是找到資訊的原始出處,如個人站、公眾號、部落格、專業網站、書籍等等。這樣就能夠找到系統化、不失真的高質量資訊。
百度搜到的技術類資訊不夠好,建議只作為補充搜尋來用。各種搜尋引擎都可以交叉著使用效果更好。
學會去常見的高質量資訊源中搜尋東西:stackoverflow(程式相關)、quora(高質量回答)、wikipedia(系統化知識,比某某百科不知道好太多)、知乎(中文、有料)、網盤搜尋(免費資源一大把)等。
將蒐集到的網頁放到分類齊全的雲端收藏夾裡,並經常整理。這樣無論在公司還是在家裡,在電腦前還是在手機上,都能夠找到自己喜歡的東西。
蒐集到的檔案、程式碼、電子書等等也放到雲端網盤裡,並經常整理。
3.6.2 提煉與總結能力
經常作筆記,並總結自己學到的知識是成長的不二法門。其實主要的困難是懶,但是堅持之後總能發現知識的共性,就能少記一些東西,掌握得更多。
筆記建議放到雲端筆記裡,印象筆記、為知筆記都還不錯。這樣在坐地鐵、排隊等零碎的時間都能看到筆記並繼續思考。
3.6.3 提問與求助能力
機器學習的相關QQ群、論壇、社群一大堆。總有人知道你問題的答案。
但是大多數同學都很忙,沒法像家庭教師那樣手把手告訴你怎麼做。
為了讓回答者最快明白你的問題,最好該學會正確的問問題的方式:陳述清楚你的業務場景和業務需求是什麼,有什麼已知條件,在哪個具體的節點上遇到困難了,並做過哪些努力。
有一篇經典的文章告訴你怎樣通過提問獲得幫助:《提問的智慧》,強力推薦。 話鋒犀利了些,但裡面的乾貨還是很好的。
別人幫助你的可能性與你提問題的具體程度和重要性呈指數相關。
3.6.4 分享的習慣
我們深信:“證明自己真的透徹理解一個知識,最好的方法,是給一個想了解這個內容的人,講清楚這個內容。” 分享能夠最充分地提升自己的學習水平。這也是我們堅持長期分享最重要的原因。
分享還有一個副產品,就是自己在求助的時候能夠獲得更多的幫助機會,這也非常重要。
4. 相關資源推薦
文章的最後部分,我們繼續放送乾貨。其實機器學習的優質資源非常多。博主也是翻遍瀏覽器收藏夾,也問同事取了取經,整合了一部分資源羅列如下:
4.1 入門資源
首先coursera 是一個非常好的學習網站,集中了全球的精品課程。上述知識學習的過程都可以在上面找到合適的課程。也有很多其他的課程網站,這裡我們就需要學習的數學和機器學習演算法推薦一些課程(有一些課程有中文字幕,有一些只有英文字幕,有一些甚至沒有字幕,大家根據自己的情況調整,如果不習慣英文,基礎部分有很多國內的課程也非常優質):
- 微積分相關
- 線性代數
- 概率統計
Introduction to Statistics: Descriptive Statistics
Probabilistic Systems Analysis and Applied Probability
- 程式語言
Programming for Everybody:Python
DataCamp: Learn R with R tutorials and coding challenges:R
- 機器學習方法
Statistical Learning®
machine learning:強烈推薦,Andrew Ng老師的課程
機器學習基石
機器學習技術:林軒田老師的課相對更有深度一些,把作業做完會對提升對機器學習的認識。
自然語言處理:史丹佛大學課程
- 日常閱讀的資源
4.2 進階資源
- 有原始碼的教程
scikit-learn中各個演算法的例子
《機器學習實戰》 有中文版,並附有python原始碼。
《The Elements of Statistical Learning (豆瓣)》 這本書有對應的中文版:《統計學習基礎 (豆瓣)》。書中配有R包。可以參照著程式碼學習演算法。網盤中有中文版。
《Natural Language Processing with Python (豆瓣)》 NLP 經典,其實主要是講 python的NLTK 這個包。網盤中有中文版。
《Neural Networks and Deep Learning》 Michael Nielsen的神經網路教材,淺顯易懂。國內有部分翻譯,不全,建議直接看原版。
- 圖書與教材
《數學之美》:入門讀起來很不錯。
《統計學習方法 (豆瓣) 》:李航經典教材。
《Pattern Recognition And Machine Learning (豆瓣) 》:經典中教材。
《統計自然語言處理》自然語言處理經典教材
《Applied predictive modeling》:英文版,注重工程實踐的機器學習教材
《UFLDL教程》:神經網路經典教材
《deeplearningbook》:深度學習經典教材。
- 工具書
《SciPy and NumPy (豆瓣) 》
《Python for Data Analysis (豆瓣) 》作者是Pandas這個包的作者
- 其他網路資料
機器學習(Machine Learning)與深度學習(Deep Learning)資料彙總: 作者太給力,量大幹貨多,有興趣的同學可以看看,博主至今只看了一小部分。
相關文章
- 機器學習導圖系列(1):資料處理機器學習
- 機器學習導圖系列(5):機器學習模型及神經網路模型機器學習模型神經網路
- 我的機器學習入門路線圖機器學習
- 人工智慧之機器學習路線圖人工智慧機器學習
- 機器學習導圖系列(2):概念機器學習
- 機器學習系列機器學習
- 機器學習導圖系列(3):過程機器學習
- 我的機器學習路線記錄機器學習
- 機器學習-資料清洗機器學習
- 機器學習 大資料機器學習大資料
- 我愛機器學習--機器學習方向資料彙總機器學習
- 吳恩達機器學習系列0——初識機器學習吳恩達機器學習
- 機器學習系列之分類機器學習
- 機器學習之清理資料機器學習
- 機器學習-- 資料轉換機器學習
- 機器學習資料彙總機器學習
- 機器學習資料精選機器學習
- 趣味機器學習入門小專案(附教程與資料)機器學習
- 吳恩達機器學習系列11:神經網路吳恩達機器學習神經網路
- 《資料探勘:實用機器學習技術》——資料探勘、機器學習一舉兩得機器學習
- 大資料路線圖大資料
- 八個機器學習資料清洗機器學習
- 機器學習資料合計(一)機器學習
- 機器學習之資料明確機器學習
- 機器學習——大資料與MapReduce機器學習大資料
- 機器學習資料合計(二)機器學習
- 機器學習、資料探勘及其他機器學習
- 7天玩轉機器學習機器學習
- 機器學習解釋模型:黑盒VS白盒(附資料連結)機器學習模型
- 機器學習-線性迴歸機器學習
- AI 學習路線:從Python開始機器學習AIPython機器學習
- 機器學習一:資料預處理機器學習
- 33個機器學習常用資料集機器學習
- 機器學習基礎-資料降維機器學習
- 機器學習筆記——資料集分割機器學習筆記
- 分散式機器學習常用資料集分散式機器學習
- 機器學習中的模型和資料機器學習模型
- huichen/mlf: 大資料機器學習框架UI大資料機器學習框架