深入理解 SQL Server 2008 的鎖機制
相比於 SQL Server 2005(比如快照隔離和改進的鎖與死鎖監視),SQL Server 2008 並沒有在鎖的行為和特性上做出任何重大改變。SQL Server 2008 引入的一個主要新特性是在表級控制鎖升級行為的能力。新的LOCK_ESCALATION表選項允許你啟用或禁用表級鎖升級。這個新特效能夠減少鎖競爭並且改善併發性,特別是對於分割槽表(partitioned tables)。
SQL Server 2008 的另一個改變是不再支援Locks configuration設定。同樣不再被支援的還有timestamp資料型別,它已被rowversion資料型別取代。
任何關聯式資料庫必須支援事務的ACID屬性,即原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永久性(Durability)。ACID屬性確保資料庫中的資料更改被正確地收集到一起,並且資料將保持在與所採取動作相一致的狀態。
鎖的主要作用是提供事務所需的隔離。隔離確保事務之間不會相互干擾,即,一個給定的事務不會讀取或修改正在被另一個事務修改的資料。此外,鎖提供的隔離性有助於保證事務間的一致性。沒有鎖,一致的事務處理是不可能的。
SQL Server 2008 支援6種隔離級別,分別是
Lock Manager 負責決定適當的鎖型別(如shared, exclusive, update)和鎖粒度(如row, page,table),根據正在執行的操作型別和所影響的資料量。
Lock Manager還管理試圖訪問同一資源的鎖型別之間的相容性,解決死鎖,必要時升級鎖到一個更高的級別。
Lock Manager 為共享資料和內部系統資源管理鎖。對於共享資料,Lock Manager 管理表以及資料頁、文字頁、葉級索引頁上的行級鎖、頁級鎖和表級鎖。內部地,Lock Manager使用門閂(latch)來管理索引行和頁上的鎖控制對內部資料結構的訪問,以及在某些情況下,用於取回單個的資料行。門閂提供了更好的系統效能,因為它不像鎖那般資源密集。門閂也提供了比鎖更好的併發性。門閂典型地用於像頁拆分、索引行的刪除、索引中行的移動等操作。鎖與門閂之間最主要的區別在於,鎖在整個事務存續期間都被持有,而門閂僅在需要它的操作存續期間被持有。鎖用於保證資料的邏輯一致性,而門閂用於保證資料和資料結構的物理一致性。
共享鎖不僅與其他共享鎖相容,也與更新鎖相容。共享鎖不會阻止其他程式在一個給定的行或頁上獲取額外的共享鎖或更新鎖。任何時候事務多個事務或程式可以持有多個共享鎖,這些事務不會影響資料的一致性。然而,共享鎖確實會阻止獨佔鎖的獲取。當行或頁上持有共享鎖的時候,任何試圖修改其資料的事務將被阻塞,直到 所有的共享鎖被釋放。

SQL Server中的更新鎖就是用來防止此類死鎖場景的。更新鎖是部分獨佔的,就是說在任何時候任何資源上只能獲取唯一的更新鎖。然而,更新鎖相容於共享鎖,即它們可以同時被同一資所獲取。事實上,更新鎖意味著一個程式想要修改某記錄,並且將也想修改該記錄的其他程式排除在外。然而,更新鎖允許其他程式獲取共享鎖以便讀取資料,直到UPDATE或DELETE語句完成被影響記錄的定位。之後,程式嘗試將每一個更新鎖升級為獨佔鎖。這時候,程式等待該記錄上當前被持有的所有共享鎖釋放。當共享鎖全部釋放以後,共享鎖就被升級為獨佔鎖。接著執行資料修改,獨佔鎖在事務的餘下時間內一直被持有。
獨佔鎖與其他的所型別不相容。如果資源持有了獨佔鎖,那麼任何其他程式對該資源的讀取或修改請求都將強制等待直到獨佔鎖釋放為止。同樣地,如果其他程式當前持有該資源的讀取鎖(共享鎖或更新鎖),獨佔鎖請求也被強制排隊等待直到資源變得可用為止。
意向鎖提升了SQL Server鎖的效能。它允許在表級別檢查鎖來決定在該表的行或頁級持有的鎖型別,而不是在表中的行或頁級查遍多個鎖。
當監視鎖活動時典型地你將看到3種型別的意向鎖:意向共享鎖(IS)、意向獨佔鎖(IX)、意向獨佔共享鎖(SIX)。
IS鎖表明,在低階別資源(行或頁)上,程式當前持有或有意圖持有共享鎖。
IX鎖表明,在低階別資源上,程式當前持有或有意圖持有獨佔鎖。
SIX鎖出現在特殊情況下,當一個事務在資源上持有共享鎖,後來又需要意向獨佔鎖(IX),這時候,S鎖被轉換成SIX鎖。
架構穩定性鎖(Sch-S)- 當事務引用了索引或資料頁時,SQL Server在物件上加Sch-S鎖。這確保當其他程式仍然引用著該物件時,沒有其他事務能夠修改該物件的Schema,如刪除索引或刪除、修改儲存過程或表。
架構修改鎖(Sch-M) - 當一個程式需要修改某物件的結構(如修改表,重編譯儲存過程)時, Lock Manager在物件上加Sch-M鎖。在鎖存在期間,沒有其他任何事務能夠引用該物件,直到(物件結構的)修改完成並提交為止。
當前,SQL Server透過在行或更高階別加鎖來平衡效能和併發性。基於各種因素,如key的分佈,行的數量,行的密度,查詢引數(SARGs)等等,Query Optimizer內部地做出鎖粒度選擇,程式設計師不需要為此擔心。SQL Server提供了大量T_SQL擴充套件,使你能從鎖的角度來更好地控制查詢行為。
SQL Server 提供以下的鎖級別:
另一方面,行級鎖比頁級鎖佔用更多的資源(記憶體和CPU),因為表中的行比頁數量更多。如果程式需要訪問頁上的所有行,鎖定整個頁比每行獲取一個鎖更加高效。這將減少Lock Manager需要管理的記憶體中鎖結構的數量。
哪一個更優 -- 更好的併發性還是較低的管理開銷?如前所述,這二者間需要平衡。當鎖的粒度變小,併發性就會得到提升,但效能會因額外的開銷而降低。隨著鎖粒度變大,效能因管理開銷的降低而得到提升,但是併發性降低了。取決於應用程式、資料庫設計和資料(量的大小),行級鎖與頁級鎖哪個更合適得具體分析。
SQL Server 在執行時自動地做出決一開始是鎖定行、頁還是整個表,基於查詢的性質、表的大小、預計被影響的行的數量。一般地,SQL Server 更經常地嘗試先應用行級鎖而非頁級鎖,以便提供最佳的併發性。今天有了更快速的CPU和更大記憶體的支援,行級鎖的管理開銷不再像過去那樣昂貴。然而,當查詢程式和實際被鎖定的資源數量超過一定的閥值,SQL Server可能會嘗試從低階別鎖升級至適當的更高階別。
當一個事務請求的鎖型別與該資源上現存的鎖型別不相容時,鎖競爭就發生了。預設地,程式無限期地等待鎖資源變得可用。如果客戶端應用程式中來自 SQL Server 的響應明顯不足,你應該警惕鎖競爭(問題)。
下圖演示了一個鎖競爭的例子。

SET LOCK_TIMEOUT 5000
如果請求鎖資源超時的話,語句將會中止,你將得到以下Error Message:
Server: Msg 1222, Level 16, State 52, Line 1
Lock request time out period exceeded.
檢視當前 LOCK_TIMEOUT 設定,可以使用系統函式@@lock_timeout。
select @@lock_timeout
如果你希望當不能獲得鎖時程式立即中止,則 set
LOCK_TIMEOUT 0
如果你想要將timeout重新置為無限期,則 set
LOCK_TIMEOUT -1
儘可能然事務保持執行時間短和簡潔。事務持有鎖的時間越短,鎖競爭發生的機會就越少;將不是事務所管理的工作單元鎖必需的命令移出事務。
將組成事務的語句作為一個的單獨的批命令處理,以消除 BEGIN TRAN 和 COMMIT TRAN 語句之間的網路延遲造成的不必要的延遲。
考慮完全地使用儲存過程編寫事務程式碼。典型地,儲存過程比批命令執行更快。
在遊標中儘可早地Commit更新。因為遊標處理比面向集合的處理慢得多,因此導致鎖被持有的時間更久。
使用每個程式所需的最低階別的鎖隔離。比如說,如果髒讀是可接受的並且不要求結果必須精確,那麼可以考慮使用事務隔離級別0(Read Uncommitted),僅在絕對必要時才使用Repeatable Read or Serializable隔離級別。
在 BEGIN TRAN 和 COMMIT TRAN 語句之間,絕不允許使用者互動,因為這樣做可能鎖被持有無限期的時間。
最小化表中的“熱點”。當表中的大多數Update活動發生在少量的頁中時,熱點出現了。
SQL Server 中可能發生2種型別的死鎖:

SQL Server自動地偵測何時死鎖情況發生。SQL Server 中一個獨立的程式叫做LOCK_MONITOR,大約每5秒鐘檢查一次系統是否存在死鎖。
按照一致的順序訪問多個表的資料以避免迴圈死鎖。
最小化HOLDLOCK的使用,或者最小化執行於Repeatable Read 或者 Serializable 隔離模式下的查詢。這將有助於避免轉換死鎖。
明智而審慎地選擇事物隔離級別。選擇較低的隔離級別或許能減少死鎖。
用於改變表級鎖隔離、粒度或者鎖型別的表提示,透過 SELECT, UPDATE, INSERT, 和 DELETE 語句的 WITH 運算子提供。
注意: 儘管許多表提示是可以組合使用的,但是,你不能一次在一個表上組合超過一個隔離級別或者鎖粒度的提示。另外,NOLOCK, READUNCOMMITTED, 和 READPAST 提示不能用於 INSERT, UPDATE, MERGE, 或 DELETE 語句的目標表上。
在這類應用程式中,你不願使用如SERIALIZABLE或HOLDLOCK鎖模式來鎖定資料,因為從使用者讀取資料到提交更新的期間,沒有人能更改它。這違背了最小化鎖競爭和死鎖的原則--不允許事務中的使用者互動。在多使用者的OLTP環境下,由於所阻塞和鎖競爭,無限期持有共享鎖將對併發性和應用的整體效能有重大影響。
另一方面,如果不在被讀取的行上加鎖,在這期間另一個程式可能會更新其中某一行資料,當第一個程式提交它的更新時,將覆蓋另一個程式先前所做的更改,從而導致Lost Update。
那麼,該如何實現這樣的應用程式呢?怎樣讓使用者讀取資料而無需鎖定資料並仍能保證不會發生Lost Update呢?
樂觀鎖就是在讀取資料與提交更改之間時間間隔很久的情況下使用的技術。樂觀鎖避免了一個客戶端覆蓋另一個客戶端對資料的修改並且無需持有資料庫中的鎖。
實現樂觀鎖有2個辦法,其一是使用rowversion資料型別,其二是利用snapshot隔離的樂觀併發性特性。
客戶端從表中讀取資料,確保返回的結果集中包含了主鍵和rowversion列,以及其他想要的資料列。由於查詢並不執行在事務中,一旦資料被讀取,SELECT查詢獲取的鎖即被釋放。當一段時間過後使用者想要更新某行時,必須確保在此期間該資料沒有被其他客戶端修改過。Update語句必須包含WHERE子句用以比較取回的rowversion值與資料庫中該列的當前值。如果兩個值匹配(即相同),說明該行記錄在此期間沒有被修改過。因此可以放心提交更改。如果不匹配,則說明該行記錄已經被修改過。為了避免Lost Update問題發生,不應提交本次更新。
下面是一個完整實現的示例程式碼。


參考
Microsoft SQL Server 2008 R2 Unleashed
SQL Server 2008 的另一個改變是不再支援Locks configuration設定。同樣不再被支援的還有timestamp資料型別,它已被rowversion資料型別取代。
為什麼需要鎖?
在任何多使用者的資料庫中,必須有一套用於資料修改的一致的規則。對於真正的事務處理型資料庫,當兩個不同的程式試圖同時修改同一份資料時,資料庫管理系統(DBMS)負責解決它們之間潛在的衝突。任何關聯式資料庫必須支援事務的ACID屬性,即原子性(Atomicity)、一致性(Consistency)、隔離性(Isolation)、永久性(Durability)。ACID屬性確保資料庫中的資料更改被正確地收集到一起,並且資料將保持在與所採取動作相一致的狀態。
鎖的主要作用是提供事務所需的隔離。隔離確保事務之間不會相互干擾,即,一個給定的事務不會讀取或修改正在被另一個事務修改的資料。此外,鎖提供的隔離性有助於保證事務間的一致性。沒有鎖,一致的事務處理是不可能的。
SQL Server 中的事務隔離級別
隔離級別決定了一個事務中正被訪問或修改的資料受保護並免於被他事務修改的程度。理論上,每個事務都應該完全與其他事務隔離開來。然而,出於可行性和效能方面的原因,實踐中這幾乎是不可能做到的。在併發環境中如果沒有鎖和隔離,可能發生以下4種情況:
- 丟失更新 -- 在這種情況下,事務與事務之間沒有隔離。多個事務能夠讀取同一份資料並且修改它。最後對資料集做出修改的事務將勝出,而其他所有事務所作的修改都丟失了。
- 髒讀 -- 在這種情況下,一個事務能夠讀取正被其他事務修改的資料。被第一個事務讀取的資料是不一致的,因為另一個事務可能會回滾所作的修改。
- 不可重複讀 -- 這種情況有點類似於沒有任何隔離,一個事務兩次讀取資料,但是在第二次讀取發生前,另一個事務修改了該資料;因此,兩次讀取所得到的結果是不同的。因為讀操作不能保證每次都是課重複進行的,這種情況被稱作“不可重複讀”。
- 幻讀 -- 這種情況類似於不可重複讀。然而,不是先前被讀取的實際行在事務完成前發生了改變,而是額外的行被新增到了表中,導致第二次讀取返回了不同的行集合。
SQL Server 2008 支援6種隔離級別,分別是
(詳情請參考我的另一篇blog:SQL Server 2008 R2 事務與隔離級別例項講解)
- Read Uncommitted
- Read Committed
- Repeatable Read
- Serializable
- Snapshot
- Read Committed Snapshot
鎖管理器
解決不同使用者程式間鎖衝突的職責落到了SQL Server Lock Manager身上。SQL Server 自動地給程式分配鎖,以保證資源的當前使用者擁有該資源的一致檢視,從某個特定操作的開始至結束。Lock Manager 負責決定適當的鎖型別(如shared, exclusive, update)和鎖粒度(如row, page,table),根據正在執行的操作型別和所影響的資料量。
Lock Manager還管理試圖訪問同一資源的鎖型別之間的相容性,解決死鎖,必要時升級鎖到一個更高的級別。
Lock Manager 為共享資料和內部系統資源管理鎖。對於共享資料,Lock Manager 管理表以及資料頁、文字頁、葉級索引頁上的行級鎖、頁級鎖和表級鎖。內部地,Lock Manager使用門閂(latch)來管理索引行和頁上的鎖控制對內部資料結構的訪問,以及在某些情況下,用於取回單個的資料行。門閂提供了更好的系統效能,因為它不像鎖那般資源密集。門閂也提供了比鎖更好的併發性。門閂典型地用於像頁拆分、索引行的刪除、索引中行的移動等操作。鎖與門閂之間最主要的區別在於,鎖在整個事務存續期間都被持有,而門閂僅在需要它的操作存續期間被持有。鎖用於保證資料的邏輯一致性,而門閂用於保證資料和資料結構的物理一致性。
SQL Server 鎖型別
鎖在SQL Server中是自動處理的。Lock Manager 基於事務型別(如SELECT, INSERT, UPDATE, 或者DELETE)選擇鎖的型別.Lock Manager使用以下的鎖型別:除了選擇鎖型別,Lock Manager還基於所執行語句的性質以及所影響的行數自動地調整鎖粒度(如row, page, table)。
- 共享鎖
- 更新鎖
- 獨佔鎖
- 意向鎖
- 架構鎖
- 大容量更新鎖
共享鎖
預設地,SQL Server 為所有讀操作應用共享鎖。顧名思義,共享鎖不是獨佔的。理論上,在任何時刻,一個資源上可以持有無限數量的共享鎖。此外,預設情況下,一個程式僅僅當資源正被讀取期間才會鎖定該資源,這時也只有唯一的共享鎖存在。比如SELECT * from authors,當查詢開始時,先鎖定authors表中的第一行;當第一行被讀取以後,它上面的鎖被釋放,並且了第二行上的鎖;第二行讀到以後,它上面的鎖被釋放,同時獲取了第三行上的鎖;以此類推。按此方式,一個SELECT查詢允許在讀操作期間修改那些沒有正在被讀取的資料行。這增強了資料訪問的併發性。共享鎖不僅與其他共享鎖相容,也與更新鎖相容。共享鎖不會阻止其他程式在一個給定的行或頁上獲取額外的共享鎖或更新鎖。任何時候事務多個事務或程式可以持有多個共享鎖,這些事務不會影響資料的一致性。然而,共享鎖確實會阻止獨佔鎖的獲取。當行或頁上持有共享鎖的時候,任何試圖修改其資料的事務將被阻塞,直到 所有的共享鎖被釋放。
更新鎖
更新鎖用於鎖定使用者程式想要修改的行或頁。當一個事務試圖修改某行時,它必須先讀取該行以確保它正在修改合適的記錄。假如事務先在資源上加了共享鎖,要修改該記錄,最終它將需要獲取該資源上的獨佔鎖,以防止任何其他事務修改同一記錄。問題是,當多個事務試圖同時修改同一資源的時候這可能導致死鎖。如圖所示。SQL Server中的更新鎖就是用來防止此類死鎖場景的。更新鎖是部分獨佔的,就是說在任何時候任何資源上只能獲取唯一的更新鎖。然而,更新鎖相容於共享鎖,即它們可以同時被同一資所獲取。事實上,更新鎖意味著一個程式想要修改某記錄,並且將也想修改該記錄的其他程式排除在外。然而,更新鎖允許其他程式獲取共享鎖以便讀取資料,直到UPDATE或DELETE語句完成被影響記錄的定位。之後,程式嘗試將每一個更新鎖升級為獨佔鎖。這時候,程式等待該記錄上當前被持有的所有共享鎖釋放。當共享鎖全部釋放以後,共享鎖就被升級為獨佔鎖。接著執行資料修改,獨佔鎖在事務的餘下時間內一直被持有。
獨佔鎖
如前所述,當事務準備好要修改資料時,獨佔鎖被分配給它。資源上的獨佔鎖確保沒有其他任何事務能妨礙被持有獨佔鎖的事務鎖定的資料。SQL Server在事務結束時釋放獨佔鎖。獨佔鎖與其他的所型別不相容。如果資源持有了獨佔鎖,那麼任何其他程式對該資源的讀取或修改請求都將強制等待直到獨佔鎖釋放為止。同樣地,如果其他程式當前持有該資源的讀取鎖(共享鎖或更新鎖),獨佔鎖請求也被強制排隊等待直到資源變得可用為止。
意向鎖
意向鎖並不正真的構成一種鎖定方式,而是充當一種機制,用以在較高的粒度級別上指示在較低(粒度)級別上所持有的鎖型別。有3種型別的意向鎖(分別對應於之前提到的3種鎖型別):共享意向鎖、獨佔意向鎖、更新意向鎖。舉個例子來說,某程式持有的表級共享意向鎖意味著,該程式當前在該表的行或頁級持有共享鎖。意向鎖的存在防止其他事務獲取與現存的行或頁級鎖不相容的表級鎖的企圖。意向鎖提升了SQL Server鎖的效能。它允許在表級別檢查鎖來決定在該表的行或頁級持有的鎖型別,而不是在表中的行或頁級查遍多個鎖。
當監視鎖活動時典型地你將看到3種型別的意向鎖:意向共享鎖(IS)、意向獨佔鎖(IX)、意向獨佔共享鎖(SIX)。
IS鎖表明,在低階別資源(行或頁)上,程式當前持有或有意圖持有共享鎖。
IX鎖表明,在低階別資源上,程式當前持有或有意圖持有獨佔鎖。
SIX鎖出現在特殊情況下,當一個事務在資源上持有共享鎖,後來又需要意向獨佔鎖(IX),這時候,S鎖被轉換成SIX鎖。
架構鎖
SQL Server 使用架構鎖來保持表結構的完整性。不像其他提供資料隔離的鎖型別,架構鎖提供事務中對資料庫物件如表、檢視、索引的schema隔離。Lock Manager提供2種型別的架構鎖:架構穩定性鎖(Sch-S)- 當事務引用了索引或資料頁時,SQL Server在物件上加Sch-S鎖。這確保當其他程式仍然引用著該物件時,沒有其他事務能夠修改該物件的Schema,如刪除索引或刪除、修改儲存過程或表。
架構修改鎖(Sch-M) - 當一個程式需要修改某物件的結構(如修改表,重編譯儲存過程)時, Lock Manager在物件上加Sch-M鎖。在鎖存在期間,沒有其他任何事務能夠引用該物件,直到(物件結構的)修改完成並提交為止。
大容量更新鎖(BU)
大容量更新鎖是一種特殊型別的鎖,僅用於使用bcp實用程式或者BULK INSERT命令向表中大容量複製資料時。僅僅當給bcp或BULK INSERT命令指定了TABLOCK提示,或者使用 sp_tableoption 設定了 table lock on bulk load 表選項時,BU鎖才能用於大容量資料複製操作。大容量更新 (BU) 鎖允許多個 bulk copy 程式將資料併發地大容量複製到同一表,同時防止其它不進行大容量複製資料的程式訪問該表。如果有任何其他程式在該表上持有鎖,則不能給該表施加BU鎖。SQL Server 鎖粒度
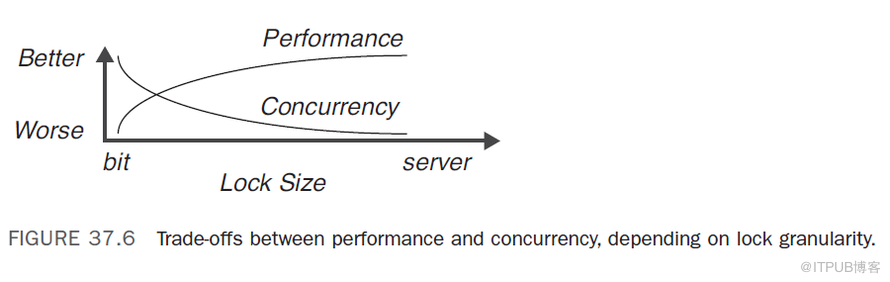
所謂所粒度,從本質上說就是,為了給事務提供完全的隔離和序列化,作為查詢或更新的一部分被鎖定的資料的總量(的大小)。Lock Manager需要在資源的併發訪問與維護大量低階別鎖的管理開銷之間取得平衡。比如,鎖的粒度越小,能夠同時訪問同一張表的併發使用者的數量就越大,不過維護這些鎖的管理開銷也越大。鎖的粒度越大,管理鎖需要的開銷就越少,而併發性也降低了。下圖說明了鎖的大小與併發性之間的權衡取捨。當前,SQL Server透過在行或更高階別加鎖來平衡效能和併發性。基於各種因素,如key的分佈,行的數量,行的密度,查詢引數(SARGs)等等,Query Optimizer內部地做出鎖粒度選擇,程式設計師不需要為此擔心。SQL Server提供了大量T_SQL擴充套件,使你能從鎖的角度來更好地控制查詢行為。
SQL Server 提供以下的鎖級別:
- DATABASE -- 無論何時當一個SQL Server 程式正在使用除master以外的資料庫時,Lock Manager為該程式授予資料庫級的鎖。資料庫級的鎖總是共享鎖,用於跟蹤何時資料庫在使用中,以防其他程式刪除該資料庫,將資料庫置為離線,或者恢復資料庫。注意,由於master和tempdb資料庫不能被刪除或置為離線,所以不需要在它們之上加鎖。
- FILE -- 檔案級的鎖用於鎖定資料庫檔案。
- EXTENT -- Extent鎖用於鎖定extents,通常僅在空間分配和重新分配的時候使用。一個extent由8個連續的資料頁或索引頁組成。Extent鎖可以是共享鎖也可以是獨佔鎖。
- ALLOCATION_UNIT -- 使用在資料庫分配單元上。
- TABLE -- 這種級別的鎖將鎖定整個表,包括資料和索引。何時將獲得表級鎖的例子包括在Serializable隔離級別下從包含大量資料的表中選取所有的行,以及在表上執行不帶過濾條件的update或delete。
- Heap or B-Tree (HOBT) -- 用於堆資料頁,或者索引的二叉樹結構。
- PAGE -- 使用頁級鎖,由8KB資料或者索引資訊組成的整個頁被鎖定。當需要讀取一頁的所有行或者需要執行頁級別的維護如頁拆分後更新頁指標時,將會獲取頁級鎖。
- Row ID (RID) -- 使用RID鎖,頁內的單一行被鎖定。無論何時當提供最大化的資源併發性訪問是有效並且可能時,將獲得RID鎖。
- KEY -- SQL Server使用兩種型別的Key鎖。其中一個的使用取決於當前會話的鎖隔離級別。對於執行於Read Committed 或者 Repeatable Read 隔離模式下的事務,SQL Server 鎖定與被訪問的行相關聯的的實際索引key。(如果是表的聚集索引,資料行位於索引的葉級。行上在這些你看到的是Key鎖而不是行級鎖。)若在Serializable隔離模式下,透過鎖定一定範圍的key值從而不允許新的行插入到該範圍內,SQL Server防止了“幻讀”。這些鎖因而被稱作“key-range lock”。
- METADATA -- 用於鎖定系統目錄資訊(後設資料)。
- APPLICATION -- 允許使用者定義他們自己的鎖,指定資源名稱、鎖模式、所有者、timeout間隔。
Serialization 與 Key-Range Locking
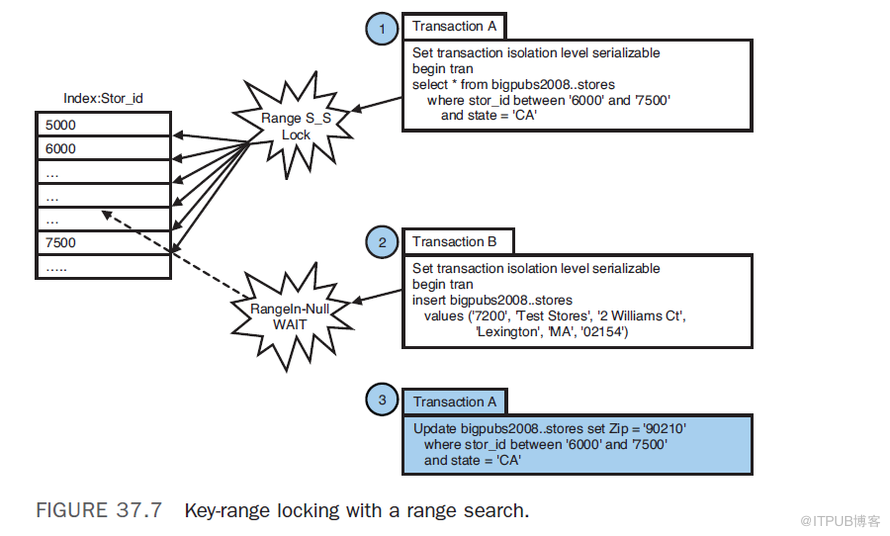
如前所述, SQL Server 透過key-range鎖防止了“幻讀”。下面將介紹key-range鎖如何與各種鎖模式一起工作。Key-Range Locking for a Range Search
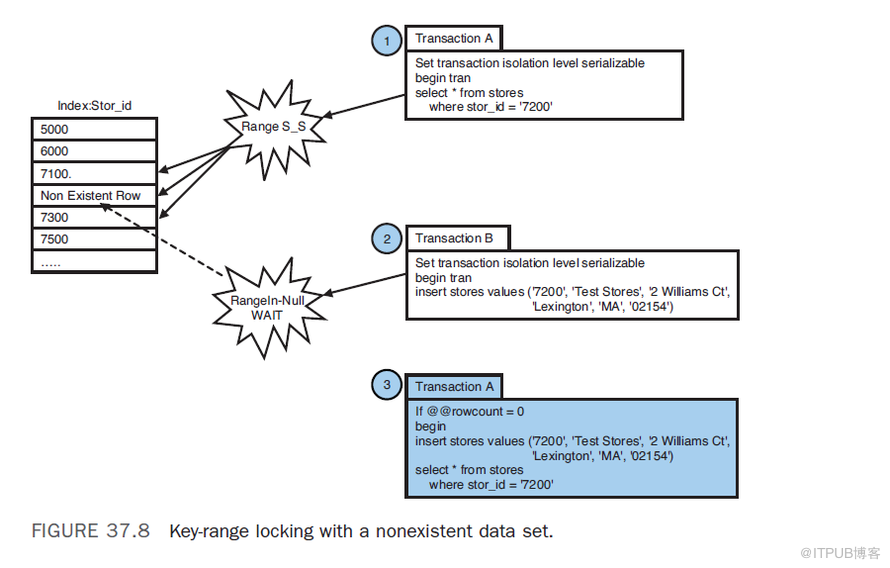
在涉及範圍查詢的key-range鎖的情況下,SQL Server 在查詢的WHERE子句所包含的資料範圍的索引頁上加鎖。(對於聚集索引,則是對錶中的實際資料行加鎖。)因為該區間被鎖定了,不允許其他事務往那個區間內插入新的行。如下圖所示。Key-Range Locking When Searching Nonexistent Rows
在涉及此種型別的鎖的情況下,如果事務試圖刪除或讀取資料庫中不存在的行,那麼在該事務的以後階段,該查詢也不應該找到任何行。如下圖所示。行級鎖與頁級鎖之比較
行級鎖是否優於頁級鎖的的爭論持續了多年,在某些圈子裡至今仍在繼續。許多人堅持認為如果資料庫和應用程式經過良好的設計和最佳化,行級鎖是不必要的。這種觀點誕生於行級鎖甚至還不存在的時候。(在SQL Server 7.0 之前,能夠鎖定的最小資料單元是頁。)然而,那時候SQL Server 中頁的大小隻有2KB。隨著頁大小擴大到8KB,單個頁中能夠包含更多數量的行(是先前的4倍)。8KB頁上的鎖可能導致更多的頁級競爭,因為不同程式請求同一個頁上資料行的可能性變得更大了。使用行級鎖將增加資料訪問的可併發性。另一方面,行級鎖比頁級鎖佔用更多的資源(記憶體和CPU),因為表中的行比頁數量更多。如果程式需要訪問頁上的所有行,鎖定整個頁比每行獲取一個鎖更加高效。這將減少Lock Manager需要管理的記憶體中鎖結構的數量。
哪一個更優 -- 更好的併發性還是較低的管理開銷?如前所述,這二者間需要平衡。當鎖的粒度變小,併發性就會得到提升,但效能會因額外的開銷而降低。隨著鎖粒度變大,效能因管理開銷的降低而得到提升,但是併發性降低了。取決於應用程式、資料庫設計和資料(量的大小),行級鎖與頁級鎖哪個更合適得具體分析。
SQL Server 在執行時自動地做出決一開始是鎖定行、頁還是整個表,基於查詢的性質、表的大小、預計被影響的行的數量。一般地,SQL Server 更經常地嘗試先應用行級鎖而非頁級鎖,以便提供最佳的併發性。今天有了更快速的CPU和更大記憶體的支援,行級鎖的管理開銷不再像過去那樣昂貴。然而,當查詢程式和實際被鎖定的資源數量超過一定的閥值,SQL Server可能會嘗試從低階別鎖升級至適當的更高階別。
鎖競爭與死鎖
SQL Server應用程式效能問題的最可能的原因是糟糕的查詢語句、糟糕的資料庫和索引設計、以及鎖競爭。前2個問題無論系統的使用者多少都會導致糟糕的應用程式效能;而鎖競爭導致的效能問題隨著使用者數量的增加而顯現出來,隨著事務越來越複雜或者執行時間越來越長而更加趨於複雜化。當一個事務請求的鎖型別與該資源上現存的鎖型別不相容時,鎖競爭就發生了。預設地,程式無限期地等待鎖資源變得可用。如果客戶端應用程式中來自 SQL Server 的響應明顯不足,你應該警惕鎖競爭(問題)。
下圖演示了一個鎖競爭的例子。
設定鎖超時間隔
如果你不想讓程式無限期等待鎖變得可用, SQL Server 允許你使用SET LOCK_TIMEOUT命令設定鎖超時間隔。你以毫秒為單位指定超時間隔。比如,如果你想讓程式在鎖變得可用前僅等待5秒,那麼執行以下命令SET LOCK_TIMEOUT 5000
如果請求鎖資源超時的話,語句將會中止,你將得到以下Error Message:
Server: Msg 1222, Level 16, State 52, Line 1
Lock request time out period exceeded.
檢視當前 LOCK_TIMEOUT 設定,可以使用系統函式@@lock_timeout。
select @@lock_timeout
如果你希望當不能獲得鎖時程式立即中止,則 set
LOCK_TIMEOUT 0
如果你想要將timeout重新置為無限期,則 set
LOCK_TIMEOUT -1
最小化鎖競爭
為了最大化併發性和應用程式效能,你應該儘可能最小化程式間的鎖競爭。下面是一些一般性指導原則:儘可能然事務保持執行時間短和簡潔。事務持有鎖的時間越短,鎖競爭發生的機會就越少;將不是事務所管理的工作單元鎖必需的命令移出事務。
將組成事務的語句作為一個的單獨的批命令處理,以消除 BEGIN TRAN 和 COMMIT TRAN 語句之間的網路延遲造成的不必要的延遲。
考慮完全地使用儲存過程編寫事務程式碼。典型地,儲存過程比批命令執行更快。
在遊標中儘可早地Commit更新。因為遊標處理比面向集合的處理慢得多,因此導致鎖被持有的時間更久。
使用每個程式所需的最低階別的鎖隔離。比如說,如果髒讀是可接受的並且不要求結果必須精確,那麼可以考慮使用事務隔離級別0(Read Uncommitted),僅在絕對必要時才使用Repeatable Read or Serializable隔離級別。
在 BEGIN TRAN 和 COMMIT TRAN 語句之間,絕不允許使用者互動,因為這樣做可能鎖被持有無限期的時間。
最小化表中的“熱點”。當表中的大多數Update活動發生在少量的頁中時,熱點出現了。
死鎖
當兩個程式各自都在等在對方當前鎖定的資源時,死鎖就發生了。兩個程式在獲得所請求資源上的鎖之前既不能前進,也不能釋放當前持有的鎖。SQL Server 中可能發生2種型別的死鎖:
人們經常以為死鎖發生在資料頁級或資料行級。事實上,死鎖經常發生在索引頁級或索引鍵級。下圖展示了由於索引鍵級的競爭引發的死鎖場景。
- 迴圈死鎖 -- 兩個進程請求不同資源上的鎖,每一個程式都需要對方持有的該資源上的鎖,這時將發生迴圈死鎖。如下圖。
- 轉換死鎖 -- 兩個或多個程式都在事務中持有同一資源上的共享鎖,並且都想把它升級為獨佔鎖,但是,誰也沒法升級直到其他的程式釋放共享鎖。 如圖所示。


SQL Server自動地偵測何時死鎖情況發生。SQL Server 中一個獨立的程式叫做LOCK_MONITOR,大約每5秒鐘檢查一次系統是否存在死鎖。
避免死鎖
遵循前文給出的最小化鎖競爭指導原則,有助於消除死鎖。此外,當設計應用程式是你還需要遵循下列指導原則:按照一致的順序訪問多個表的資料以避免迴圈死鎖。
最小化HOLDLOCK的使用,或者最小化執行於Repeatable Read 或者 Serializable 隔離模式下的查詢。這將有助於避免轉換死鎖。
明智而審慎地選擇事物隔離級別。選擇較低的隔離級別或許能減少死鎖。
Table Hints for Locking
前面提到過,你可以使用SET TRANSACTION ISOLATION LEVEL 命令為連線設定隔離級別。該命令為整個會話設定了全域性的隔離級別,如果你想要為應用程式提供一致的隔離級別,這很有用。然而,有時候你也想要許為特定的查詢或者單個查詢中的不同表指定不同的隔離級別。SQL Server 允許你在 SELECT, MERGE, UPDATE, INSERT, 和 DELETE 語句中使用表提示來實現此目的。這樣一來,你在會話級別改變了當前的隔離級別。用於改變表級鎖隔離、粒度或者鎖型別的表提示,透過 SELECT, UPDATE, INSERT, 和 DELETE 語句的 WITH 運算子提供。
注意: 儘管許多表提示是可以組合使用的,但是,你不能一次在一個表上組合超過一個隔離級別或者鎖粒度的提示。另外,NOLOCK, READUNCOMMITTED, 和 READPAST 提示不能用於 INSERT, UPDATE, MERGE, 或 DELETE 語句的目標表上。
Transaction Isolation–Level Hints
SQL Server 提供了許多提示用於在查詢中改變預設的事務隔離級別。
- HOLDLOCK -- 在語句執行期間,或者在整個事務期間(如果語句在事務中的話)保持共享鎖。該選項等同於Serializable 隔離級別。
- NOLOCK -- 使用此選項指定不對資源施加共享鎖。它類似於在0隔離級別(Read Uncommitted)下執行查詢。NOLOCK選項在對結果精度要求不嚴格的報表工作環境下很有用。
- READUNCOMMITTED -- 與指定 Read Uncommitted 隔離級別和NOLOCK提示完全一樣。
- READCOMMITTED -- 與指定 Read Committed 隔離級別一樣。
- READCOMMITTEDLOCK -- 當資料被讀取時獲得共享鎖,讀取完成時釋放共享鎖,不管是否設定了 READ_COMMITTED_SNAPSHOT 隔離級別。
- REPEATABLEREAD -- 與指定 Repeatable Read 隔離級別一樣,類似於HOLDLOCK提示。
- SERIALIZABLE -- 與指定 Serializable 隔離級別一樣,類似於HOLDLOCK提示。
- READPAST -- 讓查詢忽略被其他事務鎖定的行或頁,僅返回能夠被讀取的資料。只能用在執行於Read Committed 或 Repeatable Read 隔離級別下的事務中。
Lock Granularity Hints
用於改變鎖粒度:
- ROWLOCK -- 強制 Lock Manager 在資源上施加行級鎖而非頁級鎖或表級鎖。
- PAGLOCK -- 強制 Lock Manager 在資源上施加頁級鎖而非行級鎖或表級鎖。
- TABLOCK -- 強制 Lock Manager 在資源上施加表級鎖而非行級鎖或頁級鎖。
- TABLOCKX -- 強制 Lock Manager 在資源上施加表級獨佔鎖而非行級鎖或頁級鎖。
Lock Type Hints
用於改變SQL Server 使用的鎖型別:
- UPDLOCK -- 類似於HOLDLOCK,不過HOLDLOCK在資源上應用共享鎖,而UPDLOCK是在事務期間應用更新鎖。
- XLOCK -- 在事務期間在資源上應用獨佔鎖。它阻止其他事務獲取該資源上的鎖。
樂觀鎖
許多應用程式中,客戶端需要讀取資料用於瀏覽,然後修改其中的一些行並將修改提交回SQL Server 資料庫。讀取資料和提交更改後的資料之間的時間間隔可能很長(假如使用者讀取資料後去吃午飯了)。在這類應用程式中,你不願使用如SERIALIZABLE或HOLDLOCK鎖模式來鎖定資料,因為從使用者讀取資料到提交更新的期間,沒有人能更改它。這違背了最小化鎖競爭和死鎖的原則--不允許事務中的使用者互動。在多使用者的OLTP環境下,由於所阻塞和鎖競爭,無限期持有共享鎖將對併發性和應用的整體效能有重大影響。
另一方面,如果不在被讀取的行上加鎖,在這期間另一個程式可能會更新其中某一行資料,當第一個程式提交它的更新時,將覆蓋另一個程式先前所做的更改,從而導致Lost Update。
那麼,該如何實現這樣的應用程式呢?怎樣讓使用者讀取資料而無需鎖定資料並仍能保證不會發生Lost Update呢?
樂觀鎖就是在讀取資料與提交更改之間時間間隔很久的情況下使用的技術。樂觀鎖避免了一個客戶端覆蓋另一個客戶端對資料的修改並且無需持有資料庫中的鎖。
實現樂觀鎖有2個辦法,其一是使用rowversion資料型別,其二是利用snapshot隔離的樂觀併發性特性。
使用rowversion資料型別實現樂觀鎖
SQL Server 2008 提供了一個特殊資料型別rowversion,它可以用於在應用程式中實現樂觀鎖。rowversion資料型別在樂觀鎖模式下充當版本號。無論何時包含rowversion型別資料列的行被插入或更新時,SQL Server 自動為該列生成一個值。rowversion資料型別是8位元組的二進位制資料型別,除了保證值的唯一性和單向增長外,它的值不具有意義。你不能夠檢視它的每個位元組來搞懂它是什麼意思。客戶端從表中讀取資料,確保返回的結果集中包含了主鍵和rowversion列,以及其他想要的資料列。由於查詢並不執行在事務中,一旦資料被讀取,SELECT查詢獲取的鎖即被釋放。當一段時間過後使用者想要更新某行時,必須確保在此期間該資料沒有被其他客戶端修改過。Update語句必須包含WHERE子句用以比較取回的rowversion值與資料庫中該列的當前值。如果兩個值匹配(即相同),說明該行記錄在此期間沒有被修改過。因此可以放心提交更改。如果不匹配,則說明該行記錄已經被修改過。為了避免Lost Update問題發生,不應提交本次更新。
下面是一個完整實現的示例程式碼。
使用Snapshot隔離級別的樂觀鎖
SQL Server 2008 的Snapshot隔離模式透過自動的row versioning提供了實現樂觀鎖的另一種機制。當Snapshot隔離模式啟用時,如果一個程式在事務中讀取資料,當前版本的資料行上不會獲得或持有鎖。程式讀取的是查詢發生時候的資料版本。由於資料行沒有被鎖定,因而不會導致阻塞,其他程式在資料被讀取後可以修改它。如果另外的程式修改了該資料行,就會產生該行的一個新版本。如果第一個程式這時試圖更新該資料行,SQL Server 透過檢查 row version 自動地防止了Lost Update問題。由於 row version 不同,SQL Server阻止第一個程式修改該資料行。如果試圖修改,將出現類似於以下錯誤訊息:參考
Microsoft SQL Server 2008 R2 Unleashed
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/13651903/viewspace-1091664/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Sql Server深入的探討鎖機制SQLServer
- SQL Server之旅(14):深入的探討鎖機制SQLServer
- ORACLE鎖機制深入理解Oracle
- Sql Server之旅——第十四站 深入的探討鎖機制SQLServer
- SQL Server 2008中Analysis Services的新特性——深入SQL Server 2008SQLServer
- SQL鎖機制SQL
- [轉帖]SQL Server 鎖機制 悲觀鎖 樂觀鎖 實測解析SQLServer
- SQL Server之深入理解STUFFSQLServer
- MS SQL鎖機制SQL
- MS SQL Server資料庫事務鎖機制分析(轉)SQLServer資料庫
- 深入理解DOM事件機制事件
- 深入理解 Kafka 副本機制Kafka
- 深入理解js的執行機制JS
- 深入理解docker的link機制Docker
- 理解SQL Server 2008索引的儲存結構YDSQLServer索引
- 深入理解React:事件機制原理React事件
- 深入理解 Java 中 SPI 機制Java
- Java異常機制深入理解Java
- Android 深入理解 Notification 機制Android
- 深入理解非同步事件機制非同步事件
- 深入理解 Swift 派發機制Swift
- Analysis Services基礎知識——深入SQL Server 2008SQLServer
- 深入理解事件機制的實現事件
- 深入理解Spring的事件通知機制Spring事件
- SQL Server 鎖SQLServer
- SQL Server 的死鎖SQLServer
- 深入理解和運用Pandas的GroupBy機制——理解篇
- SQL Server重做日誌管理機制SQLServer
- 深入理解 JVM 之 垃圾回收機制JVM
- 深入理解圖注意力機制
- 深入理解Go-垃圾回收機制Go
- 深入理解OSGi類載入機制
- 深入理解JDK動態代理機制JDK
- 深入理解Java序列化機制Java
- 深入理解Android訊息機制Android
- 深入理解JVM類載入機制JVM
- 帶你深入瞭解SQL Server 2008的獨到之處SQLServer
- 深入理解瀏覽器的快取機制瀏覽器快取