轉:Oracle RAC學習筆記:基本概念及入門
RAC Architecture and Concepts
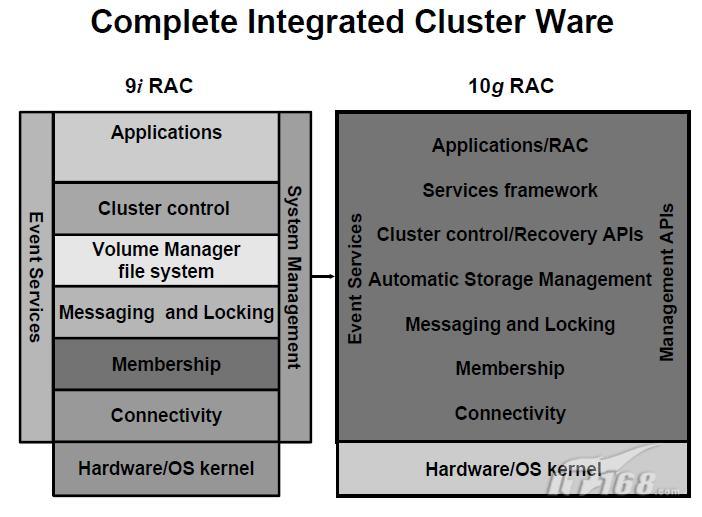
1、RAC軟體原理
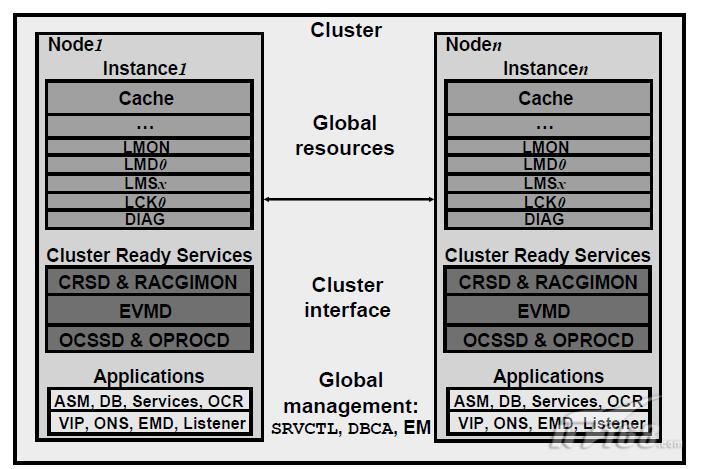
在一個RAC Instance中,會見到一些普通Instance中不存在的後臺程式,它們主要是用於維持Database在每個Instance中的一致性。管理全域性資源,具體如下:
* LMON:全域性佇列服務監控程式——Global Enqueue Service Monitor
* LMD0:全域性佇列服務守護程式——Global Enqueue Service Daemon
* LMSx:全域性緩衝服務程式,x可以從0到j——Global Cache Service Processes
* LCK0:鎖程式——Lock process
* DIAG:診斷程式——Diagnosibility process
在Cluster層,可以找到Cluster Ready Services軟體的主要程式,它們在所有平臺上提供標準的Cluster介面,並實現高可用性的操作。在每個Cluster node上都可以看到如下的程式:
* CRSD和RACGIMON:用於高可用性操作的引擎。
* OCSSD:提供成員節點和服務組的訪問
* EVMD:事件檢測程式,由oracle使用者執行管理
* OPROCD:Cluster的監控程式
此外還存在幾個工具用於管理Cluster中全域性層次上的各種資源。這些資源是ASM Instance、RAC Database、Services和CRS應用節點。本書中涉及的工具主要有Server Control(SRVCTL)、DBCA和Enterprise Manager。
2、RAC軟體儲存原理
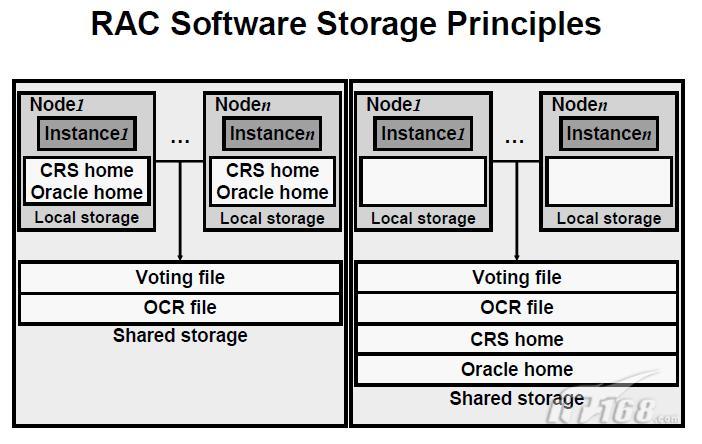
Oracle10g的RAC安裝分為兩個階段。第一階段是安裝CRS,其次是安裝帶有RAC元件的Database軟體並建立Cluster資料庫。CRS軟體使用的Oracle home必須不同於RAC軟體使用的home。儘管可以將Cluster中CRS和RAC軟體透過使用Cluster檔案系統共享儲存,但是軟體總是按一定規則安裝在每個節點的本地檔案系統中。這支援線上補丁的升級,並消除了單節點軟體造成的失敗。另外有兩個必須儲存在共享的儲存裝置中:
* voting file:其本質上是用於Cluster synchronization Services守護程式進行節點資訊的監控。大小約為20MB。
* Oracle Cluster Registry(OCR)檔案:也是CRS關鍵的組成部分。用於維護在Cluster中高可用性元件的資訊。例如,Cluster節點列表,Cluster資料庫Instance到節點的對映和CRS應用資源的列表(如Services、虛擬內部連結協議地址等)。此檔案是透過SRVCTL類似的管理工具自動維護的。其大小約100MB。
voting file和OCR file是不能被儲存在ASM中的,因為它們必須在任何Oracle Instance啟動前就可以被訪問。並且,兩者必須是在冗餘的、可靠的儲存裝置中存放,如RAID。推薦最好的做法是將這些檔案放在裸磁碟上。
3、OCR的結構
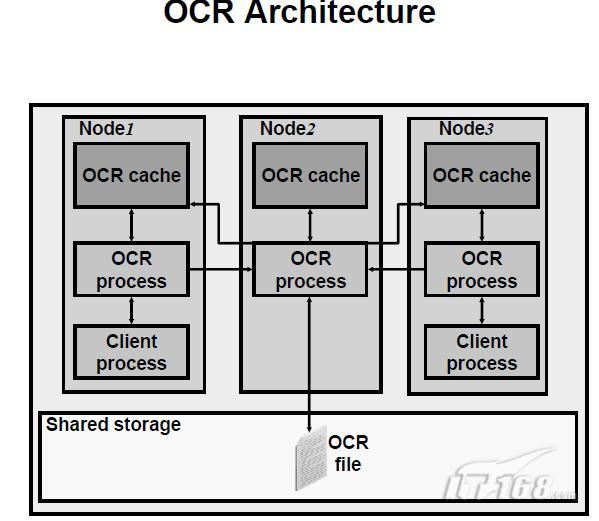
Cluster的配置資訊是在OCR中維護的。OCR依賴分散式的共享快取結構用於最佳化關於Cluster知識庫的查詢。在Cluster中的每個節點都透過OCR程式訪問OCR快取在其記憶體中維護著一個副本。事實上在Cluster中,只有一個OCR程式對共享儲存中的OCR進行讀寫操作。此程式負責重新整理(refresh)其自己擁有的本地快取以及Cluster中其他節點的OCR cache。對於涉及到Cluster知識庫的訪問,OCR客戶端直接訪問本地OCR程式。當客戶端需要更新OCR時,它們將透過本地OCR程式與那個扮演讀寫OCR檔案的程式進行互動。
OCR客戶端應用有:Oracle通用安裝器(OUI)、SRVCTL、企業管理器(EM)、DBCA、DBUA、NetCA和虛擬網路協議助理(VIPCA)。此外,OCR維護管理著CRS內部中定義的各種應用程式的資源的依賴和狀態資訊,特別是Database、Instance、Services和節點的應用程式。
配置檔案的名字是ocr.loc,並且配置檔案變數是ocrconfig_loc。Cluster 知識庫的位置是不受限於裸裝置的。可以將OCR放置在由Cluster file system管理的共享儲存裝置上。
note:OCR也可用於在ASM的單Instance中作為配置檔案,每個節點有一個OCR。
4、RAC Database儲存原理
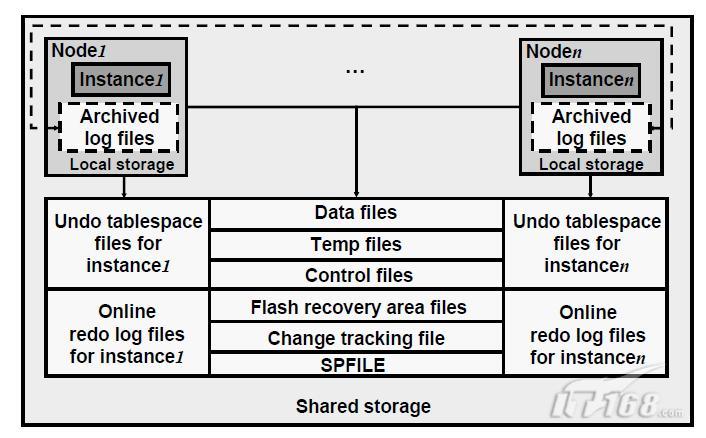
與single-Instance Oracle的儲存方式最主要的不同之處在於RAC儲存必須將所有RAC中資料檔案存放在共享裝置中(裸裝置或是Cluster檔案系統)以便於訪問相同Database的Instance能夠共享。必須為每個Instance建立至少兩個redo log組,並且所有的redo log組必須也儲存在共享裝置中,從而為了crash恢復的目的。每個Instance的線上redo log groups被稱作一個Instance的線上redo 執行緒。
此外,必須為每個Instance建立一個共享的undo表空間用於Oracle推薦的undo自動管理特點。每個undo表空間必須是對所有Instance共享的,主要用於恢復的目的。
歸檔日誌不能被存放在裸裝置上,因為其命名是自動產生的,並且每個是不一致的。因此需要儲存在一個檔案系統中。如果使用Cluster file system(CFS),則可以在任何時間在任何node上訪問這些歸檔檔案。如果沒有使用CFS,就不得不使其他Cluster成員在恢復時那些歸檔日誌是可用的,例如透過網路檔案系統(NFS)來實現。如果使用推薦的flash recovery area特性,則其必須被儲存在共享目錄下,以便於所有的Instance能夠訪問。(共享目錄可以是一個ASM磁碟組,或是一個CFS)。
5、RAC和共享儲存技術
儲存是網格技術中的關鍵組成部分。傳統上,儲存都直接依附在每個Server(directly attached to each individual Server DAS)上。在過去的幾年來,更靈活的儲存出現並得到應用,主要是透過儲存空間網路或是正規的乙太網來實現訪問。這些新的儲存方式使得多個Servers訪問相同的磁碟集合成為可能,在分散式環境中,可以獲得簡單的存取。
storage area network(SAN)代表了資料儲存技術在這一點的演進。傳統上,C/S系統中,資料被儲存在Server內部或是依附它的裝置中。隨後,進入了network attached storage(NAS)階段,這使得儲存裝置與Server和直接連線它們的網路向分離。它在SAN遵循的原則進一步允許儲存裝置存在於各自的網路中,並直接透過高速的媒介進行交換。使用者可以透過Server系統對儲存裝置的資料進行訪問,Server 系統與本地網路(LAN)和SAN相互連線。
檔案系統的選擇是RAC的關鍵。傳統的檔案系統不支援多系統的並行掛載。因此,必須將檔案儲存在沒有任何檔案系統的裸卷標或是支援多系統併發訪問的檔案系統中。
因此,三個主要的方法用於RAC的共享儲存有:
* 裸卷標:既是一些直接附加的裸裝置,需要用於儲存,並以block模式程式操作。
* Cluster file system:也需要以block模式程式存取。一個或多個Cluster file 系統可以被用於儲存所有的RAC檔案。
* 自動儲存管理(ASM):對於Oracle Database files,ASM是一個輕便的、專用的、最佳化的Cluster file system。
6、Oracle Cluster file system
Oracle Cluster file system(OCFS)是一個共享檔案系統,專門為Oracle RAC設計。OCFS排除了Oracle Database files被連線到邏輯磁碟上的需要,並使得所有的節點共享一個ORACLE Home,而不需每個node在本地有一個副本。OCFS卷標可以橫跨一個或多共享disks,用於冗餘和效能的增強。
下面時可放入OCFS中的檔案類表:
* Oracle software的安裝檔案:在10g中,此設定只在windows 2000中支援。說是後面的版本會提供在Linux中的支援,但我還沒具體看。
* Oracle 檔案(控制檔案、資料檔案、redo logs檔案,bfiles等)
* 共享配置檔案(spfile)
* 在Oracle執行期間,由Oracle建立的檔案。
* voting和OCR檔案
Oracle Cluster file system對開發人員和使用者時免費的。可從官方網站下載。
7、自動儲存管理(ASM)
是10g的新特性。它提供了一個縱向的統一管理的檔案系統和卷標管理器,專門用於建立Oracle Database 檔案。ASM可以提供單個SMP機器的管理或是貫穿多個Oracle RAC的Cluster節點。
ASM無需再手動調節I/O,會自動的分配 I/O 負載到所有的可用資源中,從而最佳化效能。透過允許增加Database大小而不需shutdown資料庫來調節儲存分配,來輔助DBA管理動態資料庫環境。
ASM可以維護資料的冗餘備份,從而提高故障的容錯。它也可以被安裝到可靠的儲存機制中。
8、選擇RAW或CFS
* CFS的優點:對於RAC的安裝和管理非常簡單;對RAC使用Oracle managed files(OMF);single Oracle軟體安裝;在Oracle data files上可以自動擴充套件;當物理節點失敗時,對歸檔日誌的統一訪問。
* 裸裝置的使用:一般會用於CFS不可用或是不被Oracle支援的情況下;它提供了最好的效能,不需要在Oracle和磁碟之間的中間層;如果空間被耗盡,裸裝置上的自動擴充套件將失敗;ASM、邏輯儲存管理器或是邏輯卷標管理其可以簡化裸裝置的工作,它們也允許載入空間到線上的裸裝置上,可為裸裝置建立名字,從而便於管理。
9、RAC的典型Cluster棧
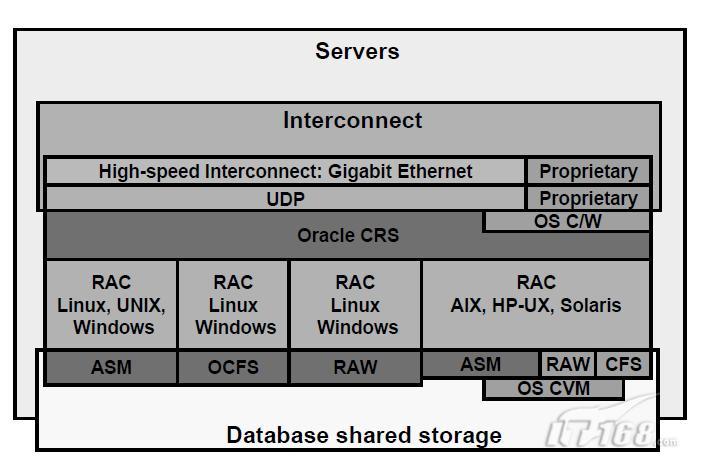
在Cluster中的每個節點都需要一個被支援的相互連線的軟體協議來支援內部Instance的互動,同時需要TCP/IP支援CRS的輪詢。所有的UNIX平臺在千兆乙太網上使用user datagram protocol(UDP)作為主要的協議並進行RAC內部Instance 的IPC互動。其他支援的特有協議包括用於SCI和Sunfire的連線互動的遠端共享記憶體協議和超文字協議,用於超光纖互動。在任何情況下,互動必須能被平臺的Oracle所辨識。
使用Oracle clusterware,可以降低安裝並支援併發症。但如果使用者使用非以太互動,或開發了依賴clusterware的應用程式在RAC上,可能需要vendor clusterware。
同互動連線一樣,共享儲存方案必須被當前平臺的Oracle所辨識。如果在目標平臺上,CFS可用,Database area和flash recovery area都可以被建立到CFS或ASM上。如果在目標平臺上,CFS不可用,則Database area可以建立在ASM或是裸裝置上(需要卷標管理器)並且flash recovery area必須被建立在ASM中。
10、RAC certification Matrix:它設計用於處理任何認證問題。可以使用matrix回答任何RAC相關的認證問題。具體使用步驟如下:
* 連線並登陸
* 點選選單欄的“certify and availability”按鈕
* 點選“view certifications by product”連線
* 選擇RAC
* 選擇正確的平臺
11、必要的全域性資源
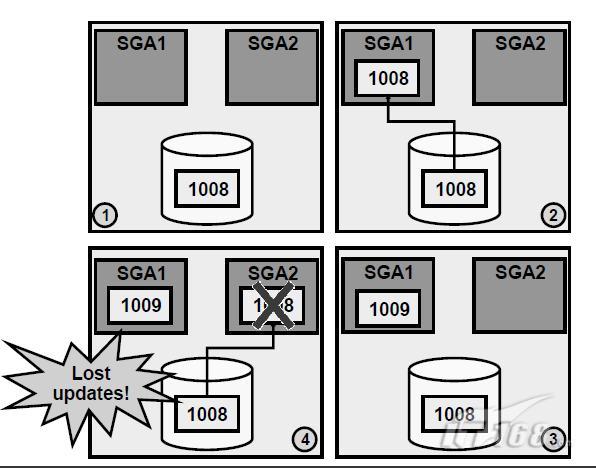
一個single-Instance環境,鎖座標通向一個共享的資源就像表中的一行。lock避免了兩個程式同事修改相同的資源。
在RAC環境中,內部節點的同步時關鍵,因為它維持著不同節點中各自程式的一致性,避免其在同時修改相同的資源資料。內部節點的同步確保每個Instance看到buffer cache中block的最近的版本。上圖中顯示了當不存在加鎖的情況。
1)全域性資源的協調
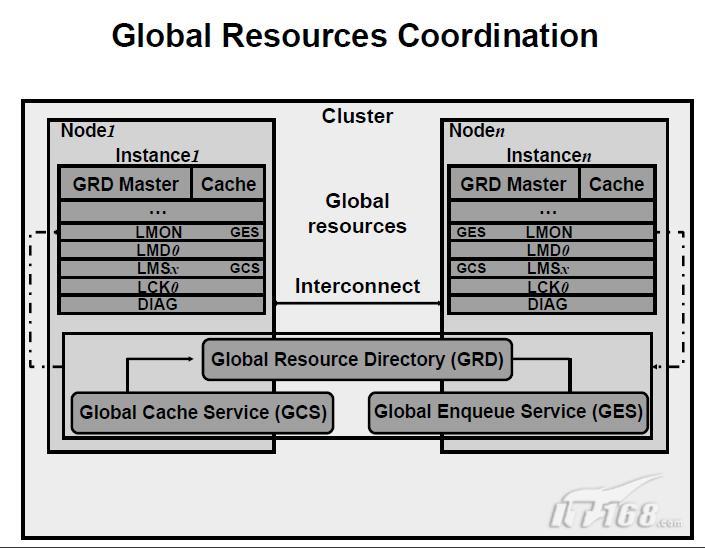
cluster操作要求在所有Instance中對控制共享資源的訪問進行同步。RAC使用Global Resource Directory來記錄cluster Database中資源的使用資訊。Global Cache Service(GCS)和Global Enqueue Service(GES)管理GRD中的資訊。
每個Instance在其本地的SGA中維護GRD的一部分。GCS和GES指定一個Instance管理特殊資源的所有資訊,它被稱為資源的master。每個Instance都知道resource的Instance masters。
維護RAC的活動中的cache的依附性(cache coherency)是非常重要的。所謂cache coherency是保持在不同Oracle Instances中的多個block版本的一致性的技術。GCS透過所謂的cache融合演算法來實現cache coherency。
GES管理所有非cache 融合演算法的內部Instance資源操作和Oracle入隊機制的狀態軌跡。GES主要的控制的資源是字典cache locks和library cache locks。同時,它還對所有死鎖敏感的佇列和資源起到死鎖檢測的作用。
2)Global cache coordination例項
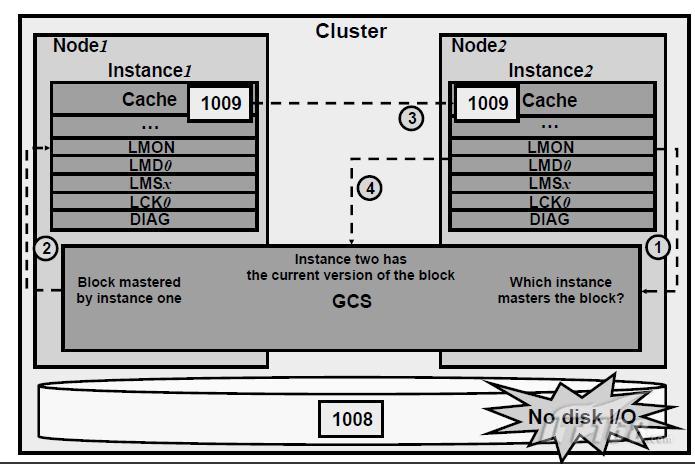
假設某data block被第一個節點修改,成為髒資料。並且在clusterwide中,只有一個block copy版本,其內容用SCN號代替了。則具體的步驟如下:
① 第二個Instance檢視修改該block,向GCS提出請求。
② GCS向block的holder(持有者)提交請求。在此,第一個Instance就是holder。
③ 第一個Instance接到訊息,並將block傳送給第二個Instance。第一個Instance儲存髒buffer用於恢復的目的。block的髒映象被稱作block的past image。一個past image block將不能進一步被改變。
④收到block後,第二個Instance通知GCS,告知已經holds該block。
3)write to disk coordination:example
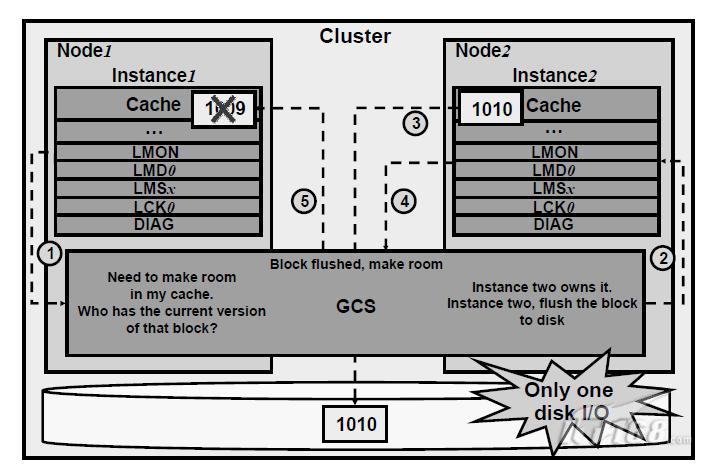
在cluster結構中的Instances中的caches中,可能存在同一個block的不同的修改版本。由GCS管理的寫協議確保了只有最近一個版本被寫入磁碟中。它同時需要確保其他之前的版本從其他cache中被清洗。一個寫磁碟的請求可以從任意一個Instance上發起,無論它是儲存了block的當前版本還是過去的版本。假設第一個Instance hold過去的block映象,請求Oracle將buffer寫入磁碟,如上圖,過程如下:
①第一個Instance傳送一個寫請求給GCS
②GCS將請求轉給第二個Instance,當前該block的holder
③第二個Instance接到寫請求後將block寫入磁碟
④第二個Instance通知GCS,告知其寫操作完成
⑤當接到GCS接到通知後,GCS命令所有的過去的映象的holders刪除其過去的映象。此映象將不會在因恢復而需要。
12、RAC和Instance/crash recovery
1)當一個Instance失敗,當該失敗被其他Instance檢測到,第二個Instance將會執行下面的恢復操作:
①在恢復的第一階段,GES重新灌入佇列
②GCS也重新灌入其資源。GCS程式只重新灌入那些失去其控制的資源。在這期間,所有的GCS資源請求和寫請求都臨時被掛起。然而,事務可以繼續修改data blocks,只要這些事務已經獲得了必要的資源。
③當佇列被重新配置後,一個活動的Instance可以獲得佔有該Instance恢復佇列。因此,當GCS資源被重新灌入的同時,SMON確定需要被恢復的blocks的集合。這個集合被稱作恢復集。因為,使用cache 融合演算法,一個Instance傳送這些blocks的內容到請求的Instance,而不需要將這些blocks寫入磁碟。這些blocks在磁碟上的版本可能不包含其他Instance程式的data的修改操作的blocks。這意味著SMON需要合併所有失敗的Instance的redo logs來確定恢復集。這是因為一個失敗的執行緒可能導致一個在redo 中的hole(洞)需要用指定的block填補。所以失敗的Instance的redo 執行緒不能被連續的應用。同時,活動的Instances的redo 執行緒不需恢復,因為SMON可以使用過去和當前的通訊緩衝的映象。
④用於恢復的緩衝空間被分配,並且那些之前讀取redo logs被辨識的資源被宣告為恢復資源。這避免了其他Instance訪問這些資源。
⑤所有在隨後的恢復操作中需要的資源被獲得,並且GRD當前是不凍結的。任何不需恢復的data block現在可以被訪問。所以當前系統時部分可用的。此時,假設有過去或當前的blocks映象需要被恢復,而其在cluster Database中的其他caches中,對於這些特殊的blocks,最近的映象是開始恢復點。如果對於要恢復的block,過去映象和當前映象緩衝都不在活動的Instance的caches中,則SMON將寫入一個log,表明合併失敗。SMON會對第三步中辨識的每個block進行恢復和寫入,在恢復之後會馬上釋放資源,從而使更多的資源在恢復時可以被使用。
當所有的block被恢復,佔用的恢復資源被釋放,則系統再次可用。
note:在恢復中,log合併的開支和失敗的Instances的數目是成比例的,並且與每個Instance的redo logs的大小有關。
2)Instance recovery和Database availability
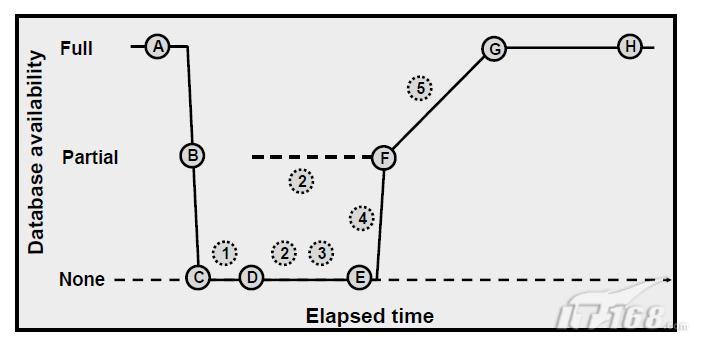
上圖顯示了在進行Instance恢復時,每一步執行時資料庫的可用程度:
A. RAC執行在多節點上
B. 有節點失敗被檢測到
C. GRD的佇列部分被重新設定;資源管理被重新分配到活動的nodes。此操作的執行比較快
D. GRD的緩衝部分被重新設定,SMON讀取失敗Instance的redo logs辨識那些需要恢復的blocks的集合
E. SMON向GRD發起請求,獲得所有在需要恢復的blocks集合中的Database blocks。當請求結束,所有的其他的blocks都可被訪問了
F. Oracle執行滾動的向前恢復。失敗執行緒的redo logs被應用到Database,並且那些被完全恢復的blocks將馬上可以被訪問
G. Oracle執行滾回恢復。對於尚未提交的事務,undo blocks被應用到Database中
H. Instance的恢復完成,所有的data可以被訪問
13、有效的內部節點行級鎖
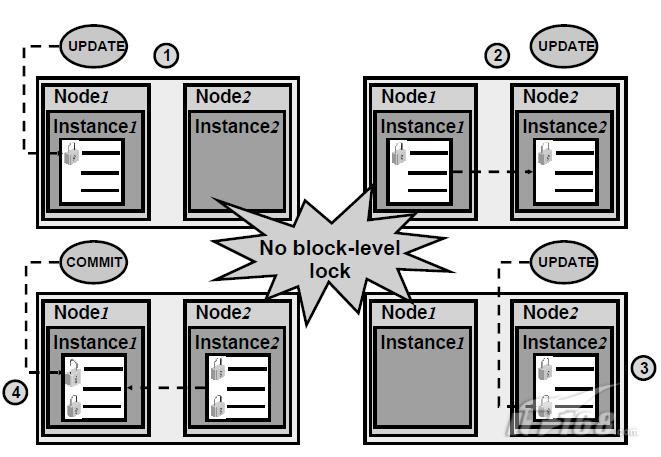
Oracle支援有效的行級鎖。這些行級鎖主要是在DML操作時被建立,例如UPDATE。這些鎖被持有,直到事務被提交或回滾。任何請求同行的lock的程式都將被掛起。
cache融合演算法的塊傳輸獨立於這些user可見的行級鎖。GCS對blocks的傳輸是一個底層的操作,無需當代行級鎖被釋放就開始進行。blocks可能被從一個Instance傳輸到其他其他Instances,同時該blocks可能被加鎖。
GCS提供對data blocks的訪問,允許多個事務的併發進行。
14、RAC的額外的記憶體需求
RAC特有的記憶體多數是在SGA建立時從shared pool中分配的。因為blocks可能跨越Instances被緩衝,必須要求更大的緩衝區。因此,當將single Instance的Database遷移到RAC中時,保持每個Instance的請求工作量都能通single-instance時的情況,則需要對執行RAC的Instance增大10%的buffer cache和15%的shared pool。這些值只是基於RAC大小的經驗,一個初始的嘗試值。一般會大於此值。
如果正在使用推薦的自動記憶體管理特性,可以透過修改SGA_TARGET初始引數來設定。但考慮到同樣數量的user訪問被分散到多個nodes中,每個Instance的記憶體需求可以被降低。
實際資源的使用可以透過查詢每個Instance中的GCS和GES實體中的檢視V$RESOURCE_LIMIT檢視CURRENT_UTILIZATION和MAX_UTILIZATION欄位,具體語句為:
SELECT resource_name, current_utilization, max_utilization FROM v$resource_limit WHERE resource_name like ‘g%s_%’;
15、RAC與併發執行
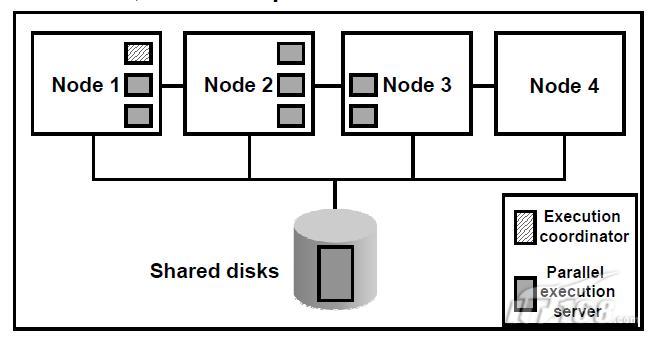
Oracle的最佳化器是基於執行訪問代價的,這就考慮了併發執行的代價,並將其作為獲得理想的執行計劃的一個部件。
在RAC環境中,最佳化器的併發選擇是由內部節點和外部節點併發兩類組成的。例如,一個特殊的查詢請求需要六個查詢程式完成,並且在本地節點有六個併發的從屬執行程式都是idle的,則查詢透過使用本地資源執行,從而獲得結果。這闡述了有效地內部節點併發,也無需多節點併發的查詢協調的開支。如果本地節點中只有兩個併發執行從屬程式可用,則這兩個程式和其他節點的四個程式共同執行查詢。在這種情況下,內部節點和外部節點併發都被使用到,從而加速查詢。
在真實環境的決策支援應用程式中,查詢不能透過各種查詢servers得到較好的劃分。所以有些併發執行servers完成其任務後先於其他servers變為idle狀態。Oracle併發執行技術動態監測idle的程式,並將超載程式的佇列表中的任務分配任務給處於idle狀態的程式。這樣,Oracle有效的再分配了所有程式的查詢工作量。RAC進一步擴充套件這個效率到整個cluster上。
16、全域性動態效能檢視
全域性動態效能檢視顯示所有開啟並訪問RAC Database的Instances相關的資訊。而標準動態效能檢視只顯示了本地Instance的相關資訊。
對於所有V$型別的檢視,都會對應一個GV$檢視,除了幾個別的特殊情況。除了V$檢視中的columns,GV$檢視中包含了一個名為INST_ID的額外的column,顯示了RAC中的Instance number。可以在任何開啟的Instance上訪問GV$。
為了查詢GV$檢視,每個Instance上的初始PARALLEL_MAX_SERVERS初始化引數至少設定為1 。這是由於對GV$的查詢使用了特殊的併發執行。併發執行的協調者執行在客戶端連線的Instance上,並且每個Instance上分配一個slave用於查詢其潛在的V$檢視。如果有一個Instance上的PARALLEL_MAX_SERVERS被設定為0,則無法獲得該node的資訊,同理,如果所有的併發servers非常忙,則也無法獲得結果。在以上兩種情況下,不會獲得提示或錯誤資訊。
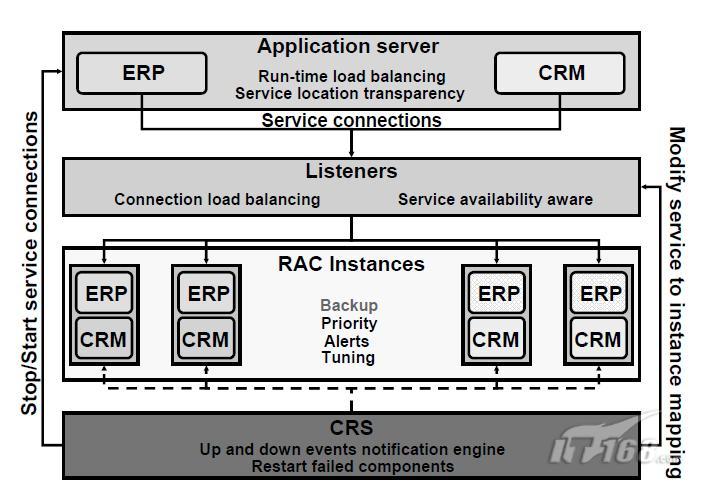
17、RAC和Service
18、虛擬IP地址和RAC
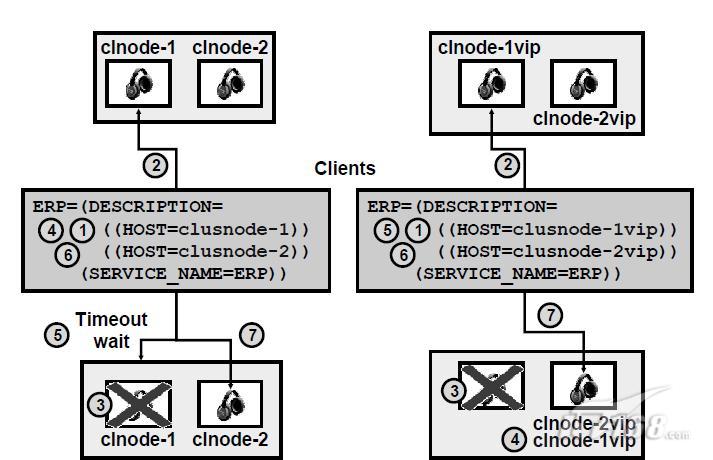
當一個node完全失敗,虛擬IP地址(VIP)是關於所有有效應用的。當一個節點失敗,其相關的VIP自動的分派到cluster中的其他node上。當這種情況出現時:
* crs在另外一個node的網路卡的MAC地址上繫結這個ip,對使用者來說是透明的。對於直接連線的客戶端,會顯示errors。
* 隨後發往VIP的資料包都將轉向新的節點,它將給客戶端傳送error RST返回包。從而使客戶端快速的獲得errors資訊,進行對其他節點的連線重試。
如果不使用VIP,則一個node失敗後,發往該節點的連線將等待10分鐘的TCP過期時間。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/30496894/viewspace-1816318/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- oracle基本概念的學習筆記(轉)Oracle筆記
- Oracle RAC 基本概念及入門Oracle
- TS入門學習筆記筆記
- 【PostgreSQL】入門學習筆記SQL筆記
- git入門學習筆記Git筆記
- Docker入門學習筆記Docker筆記
- Unity學習筆記--入門Unity筆記
- ActionScript 學習筆記(入門)筆記
- JavaScript入門學習學習筆記(上)JavaScript筆記
- Go 入門指南學習筆記Go筆記
- React入門指南(學習筆記)React筆記
- pandas 學習筆記 (入門篇)筆記
- HTML入門學習筆記(二)HTML筆記
- MySQL學習筆記---入門使用MySql筆記
- JavaScript入門-學習筆記(一)JavaScript筆記
- Dubbo學習筆記(一) 入門筆記
- golang入門學習筆記(一)Golang筆記
- Kotlin 入門學習筆記Kotlin筆記
- LDA入門級學習筆記LDA筆記
- Elasticsearch入門學習重點筆記Elasticsearch筆記
- 【MongoDB學習筆記】MongoDB 快速入門MongoDB筆記
- java學習筆記1(入門級)Java筆記
- JavaScript學習筆記1—快速入門JavaScript筆記
- 安卓學習筆記20:Fragment入門安卓筆記Fragment
- 爬蟲入門學習筆記3爬蟲筆記
- node 學習筆記 基礎入門筆記
- webpack 學習筆記:入門介紹Web筆記
- 【Laravel 入門教程】學習筆記 1Laravel筆記
- 微信小程式入門學習筆記微信小程式筆記
- 學習筆記|AS入門(六) 碎片Fragment筆記Fragment
- angular學習筆記(一)-入門案例Angular筆記
- python學習筆記(一)——入門Python筆記
- redis學習筆記1: Redis入門Redis筆記
- CANopen學習筆記(一)CANopen入門筆記
- 【kafka學習筆記】kafka的基本概念Kafka筆記
- HTTP2基本概念學習筆記HTTP筆記
- webpack4入門學習筆記(一)Web筆記
- webpack4入門學習筆記(二)Web筆記