- 原文地址:How to Handle Imbalanced Classes in Machine Learning
- 原文作者:elitedatascience
- 譯文出自:掘金翻譯計劃
- 本文永久連結:github.com/xitu/gold-m…
- 譯者:RichardLeeH
- 校對者:lsvih, lileizhenshuai
如何處理機器學習中的不平衡類別
不平衡類別使得“準確率”失去意義。這是機器學習 (特別是在分類)中一個令人驚訝的常見問題,出現於每個類別的觀測樣本不成比例的資料集中。
普通的準確率不再能夠可靠地度量效能,這使得模型訓練變得更加困難。
不平衡類別出現在多個領域,包括:
- 欺詐檢測
- 垃圾郵件過濾
- 疾病篩查
- SaaS 客戶流失
- 廣告點選率
在本指南中,我們將探討 5 種處理不平衡類別的有效方法。

直觀的例子:疾病篩查案例
假如你的客戶是一家先進的研究醫院,他們要求你基於採集於病人的生物輸入來訓練一個用於檢測一種疾病的模型。
但這裡有陷阱... 疾病非常罕見;篩查的病人中只有 8% 的患病率。
現在,在你開始之前,你覺得問題可能會怎樣發展呢?想象一下,如果你根本沒有去訓練一個模型。相反,如果你只寫一行程式碼,總是預測“沒有疾病”,那會如何呢?
一個拙劣但準確的解決方案
def disease_screen(patient_data):
# 忽略 patient_data
return 'No Disease.'複製程式碼很好,猜猜看?你的“解決方案”應該有 92% 的準確率!
不幸的是,以上準確率具有誤導性。
- 對於未患該病的病人,你的準確率是 100% 。
- 對於已患該病的病人,你的準確率是 0%。
- 你的總體準確率非常高,因為大多數患者並沒有患該病 (不是因為你的模型訓練的好)。
這顯然是一個問題,因為設計的許多機器學習演算法是為了最大限度的提高整體準確率。本指南的其餘部分將說明處理不平衡類別的不同策略。
我們開始之前的重要提示:
首先,請注意,我們不會分離出一個獨立的測試集,調整超引數或者實現交叉檢驗。換句話說,我們不打算遵循最佳做法 (在我們的7 天速成課程中有介紹)。
相反,本教程只專注於解決不平衡類別問題。
此外,並非以下每種技術都會適用於每一個問題。不過通常來說,這些技術中至少有一個能夠解決問題。
Balance Scale 資料集
對於本指南,我們將會使用一個叫做 Balance Scale 資料的合成資料集,你可以從這裡 UCI 機器學習倉庫下載。
這個資料集最初被生成用於模擬心理實驗結果,但是對於我們非常有用,因為它的規模便於處理並且包含不平衡類別
匯入第三方依賴庫並讀取資料
import pandas as pd
import numpy as np
# 讀取資料集
df = pd.read_csv('balance-scale.data',
names=['balance', 'var1', 'var2', 'var3', 'var4'])
# 顯示示例觀測樣本
df.head()複製程式碼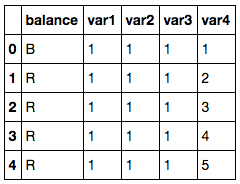
基於兩臂的重量和距離,該資料集包含了天平是否平衡的資訊。
- 其中包含 1 個我們標記的目標變數
balance .複製程式碼 - 其中包含 4 個我們標記的輸入特徵
var1 到 var4 .複製程式碼

目標變數有三個類別。
- R 表示右邊重,,當
var3*var4>var1*var2複製程式碼 - L 表示左邊重,當
var3*var4<var1*var2複製程式碼 - B 表示平衡,當
var3*var4=var1*var2複製程式碼
每個類別的數量
df['balance'].value_counts()
# R 288
# L 288
# B 49
# Name: balance, dtype: int64複製程式碼然而,對於本教程, 我們將把本問題轉化為 二值分類 問題。
我們將把天平平衡時的每個觀測樣本標記為 1 (正向類別),否則標記為 0 (負向類別):
轉變成二值分類
# 轉換為二值分類
df['balance'] = [1 if b=='B' else 0 for b in df.balance]
df['balance'].value_counts()
# 0 576
# 1 49
# Name: balance, dtype: int64
# About 8% were balanced複製程式碼正如你所看到的,只有大約 8% 的觀察樣本是平衡的。 因此,如果我們的預測結果總為 0,我們就會得到 92% 的準確率。
不平衡類別的風險
現在我們有一個資料集,我們可以真正地展示不平衡類別的風險。
首先,讓我們從 Scikit-Learn 匯入邏輯迴歸演算法和準確度度量模組。
匯入演算法和準確度度量模組
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score複製程式碼接著,我們將會使用預設設定來生成一個簡單的模型。
在不平衡資料上訓練一個模型
# 分離輸入特徵 (X) 和目標變數 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 訓練模型
clf_0 = LogisticRegression().fit(X, y)
# 在訓練集上預測
pred_y_0 = clf_0.predict(X)複製程式碼如上所述,許多機器學習演算法被設計為在預設情況下最大化總體準確率。
我們可以證實這一點:
# 準確率是怎樣的?
print( accuracy_score(pred_y_0, y) )
# 0.9216複製程式碼因此我們的模型擁有 92% 的總體準確率,但是這是因為它只預測了一個類別嗎?
# 我們應該興奮嗎?
print( np.unique( pred_y_0 ) )
# [0]複製程式碼正如你所看到的,這個模型僅能預測 0,這就意味著它完全忽視了少數類別而偏愛多數類別。
接著,我們將會看到第一個處理不平衡類別的技術:上取樣少數類別。
1. 上取樣少數類別
上取樣是從少數類別中隨機複製觀測樣本以增強其訊號的過程。
達到這個目的有幾種試探法,但是最常見的方法是使用簡單的放回抽樣的方式重取樣。
首先,我們將從 Scikit-Learn 中匯入重取樣模組:
重取樣模組
from sklearn.utils import resample複製程式碼接著,我們將會使用一個上取樣過的少數類別建立一個新的 DataFrame。 下面是詳細步驟:
- 首先,我們將每個類別的觀測樣本分離到不同的 DataFrame 中。
- 接著,我們將採用放回抽樣的方式對少數類別重取樣,讓樣本的數量與多數類別數量相當。
- 最後,我們將上取樣後的少數類別 DataFrame 與原始的多數類別 DataFrame 合併。
以下是程式碼:
上取樣少數類別
# 分離多數和少數類別
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# 上取樣少數類別
df_minority_upsampled = resample(df_minority,
replace=True, # sample with replacement
n_samples=576, # to match majority class
random_state=123) # reproducible results
# 合併多數類別同上取樣過的少數類別
df_upsampled = pd.concat([df_majority, df_minority_upsampled])
# 顯示新的類別數量
df_upsampled.balance.value_counts()
# 1 576
# 0 576
# Name: balance, dtype: int64複製程式碼正如你所看到的,新生成的 DataFrame 比原來擁有更多的觀測樣本,現在兩個類別的比率為 1:1。
讓我們使用邏輯迴歸訓練另一個模型,這次我們在平衡資料集上進行:
在上取樣後的資料集上訓練模型
# 分離輸入特徵 (X) 和目標變數 (y)
y = df_upsampled.balance
X = df_upsampled.drop('balance', axis=1)
# 訓練模型
clf_1 = LogisticRegression().fit(X, y)
# 在訓練集上預測
pred_y_1 = clf_1.predict(X)
# 我們的模型仍舊預測僅僅一個類別嗎?
print( np.unique( pred_y_1 ) )
# [0 1]
# 我們的準確率如何?
print( accuracy_score(y, pred_y_1) )
# 0.513888888889複製程式碼非常好,現在這個模型不再只是預測一個類別了。雖然準確率急轉直下,但現在的效能指標更有意義。
2. 下采樣多數類別
下采樣包括從多數類別中隨機地移除觀測樣本,以防止它的資訊主導學習演算法。
其中最常見的試探法是不放回抽樣式重取樣。
這個過程同上取樣極為相似。下面是詳細步驟:
- 首先,我們將每個類別的觀測樣本分離到不同的 DataFrame 中。
- 接著,我們將採用不放回抽樣來重取樣多數類別,讓樣本的數量與少數類別數量相當。
- 最後,我們將下采樣後的多數類別 DataFrame 與原始的少數類別 DataFrame 合併。
以下為程式碼:
下采樣多數類別
# 分離多數類別和少數類別
df_majority = df[df.balance==0]
df_minority = df[df.balance==1]
# 下采樣多數類別
df_majority_downsampled = resample(df_majority,
replace=False, # sample without replacement
n_samples=49, # to match minority class
random_state=123) # reproducible results
# Combine minority class with downsampled majority class
df_downsampled = pd.concat([df_majority_downsampled, df_minority])
# Display new class counts
df_downsampled.balance.value_counts()
# 1 49
# 0 49
# Name: balance, dtype: int64複製程式碼這次,新生成的 DataFrame 比原始資料擁有更少的觀察樣本,現在兩個類別的比率為 1:1。
讓我們再一次使用邏輯迴歸訓練一個模型:
在下采樣後的資料集上訓練模型
# Separate input features (X) and target variable (y)
y = df_downsampled.balance
X = df_downsampled.drop('balance', axis=1)
# Train model
clf_2 = LogisticRegression().fit(X, y)
# Predict on training set
pred_y_2 = clf_2.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_2 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_2) )
# 0.581632653061複製程式碼模型不再僅預測一個類別,並且其準確率似乎有所提高。
我們還希望在一個未見過的測試資料集上驗證模型時, 能看到更令人鼓舞的結果。
3. 改變你的效能指標
目前,我們已經看到通過重取樣資料集來解決不平衡類別的問題的兩種方法。接著,我們將考慮使用其他效能指標來評估模型。
阿爾伯特•愛因斯坦曾經說過,“如果你根據能不能爬樹來判斷一條魚的能力,那你一生都會認為它是愚蠢的。”,這句話真正突出了選擇正確評估指標的重要性。
對於分類的通用指標,我們推薦使用 ROC 曲線下面積 (AUROC)。
- 本指南中我們不做詳細介紹,但是你可以在這裡閱讀更多關於它的資訊。
- 直觀地說,AUROC 表示從中類別中區別觀測樣本的可能性。
- 換句話說,如果你從每個類別中隨機選擇一個觀察樣本,它將被正確的“分類”的概率是多大?
我們可以從 Scikit-Learn 中匯入這個指標:
ROC 曲線下面積
from sklearn.metrics import roc_auc_score複製程式碼為了計算 AUROC,你將需要預測類別的概率,而非僅預測類別。你可以使用如下程式碼獲取這些結果
.predict_proba() function like so:
獲取類別概率
# Predict class probabilities
prob_y_2 = clf_2.predict_proba(X)
# Keep only the positive class
prob_y_2 = [p[1] for p in prob_y_2]
prob_y_2[:5] # Example
# [0.45419197226479618,
# 0.48205962213283882,
# 0.46862327066392456,
# 0.47868378832689096,
# 0.58143856820159667]複製程式碼那麼在 AUROC 下 這個模型 (在下采樣資料集上訓練模型) 效果如何?
下采樣後資料集上訓練的模型的 AUROC
Python
print( roc_auc_score(y, prob_y_2) )
# 0.568096626406複製程式碼不錯... 這和在不平衡資料集上訓練的原始模型相比,又如何呢?
不平衡資料集上訓練的模型的 AUROC
prob_y_0 = clf_0.predict_proba(X)
prob_y_0 = [p[1] for p in prob_y_0]
print( roc_auc_score(y, prob_y_0) )
# 0.530718537415複製程式碼記住,我們在不平衡資料集上訓練的原始模型擁有 92% 的準確率,它遠高於下采樣資料集上訓練的模型的 58% 準確率。
然而,後者模型的 AUROC 為 57%,它稍高於 AUROC 為 53% 原始模型的 (並非遠高於)。
注意: 如果 AUROC 的值為 0.47,這僅僅意味著你需要翻轉預測,因為 Scikit-Learn 誤解釋了正向類別。 AUROC 應該 >= 0.5。
4. 懲罰演算法 (代價敏感學習)
接下來的策略是使用懲罰學習演算法來增加對少數類別分類錯誤的代價。
對於這種技術,一個流行的演算法是懲罰性-SVM:
支援向量機
from sklearn.svm import SVC複製程式碼訓練時,我們可以使用引數
class_weight='balanced' 來減少由於少數類別樣本比例不足造成的預測錯誤。
我們也可以包含引數
probability=True ,如果我們想啟用 SVM 演算法的概率估計。
讓我們在原始的不平衡資料集上使用懲罰性的 SVM 訓練模型:
SVM 在不平衡資料集上訓練懲罰性-SVM
# 分離輸入特徵 (X) 和目標變數 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 訓練模型
clf_3 = SVC(kernel='linear',
class_weight='balanced', # penalize
probability=True)
clf_3.fit(X, y)
# 在訓練集上預測
pred_y_3 = clf_3.predict(X)
# Is our model still predicting just one class?
print( np.unique( pred_y_3 ) )
# [0 1]
# How's our accuracy?
print( accuracy_score(y, pred_y_3) )
# 0.688
# What about AUROC?
prob_y_3 = clf_3.predict_proba(X)
prob_y_3 = [p[1] for p in prob_y_3]
print( roc_auc_score(y, prob_y_3) )
# 0.5305236678複製程式碼再說,這裡我們的目的只是為了說明這種技術。真正決定哪種策略最適合這個問題,你需要在保留測試集上評估模型。
5. 使用基於樹的演算法
最後一個策略我們將考慮使用基於樹的演算法。決策樹通常在不平衡資料集上表現良好,因為它們的層級結構允許它們從兩個類別去學習。
在現代應用機器學習中,樹集合(隨機森林、梯度提升樹等) 幾乎總是優於單一決策樹,所以我們將跳過單一決策樹直接使用樹集合模型:
隨機森林
from sklearn.ensemble import RandomForestClassifier複製程式碼現在,讓我們在原始的不平衡資料集上使用隨機森林訓練一個模型。
在不平衡資料集上訓練隨機森林
# 分離輸入特徵 (X) 和目標變數 (y)
y = df.balance
X = df.drop('balance', axis=1)
# 訓練模型
clf_4 = RandomForestClassifier()
clf_4.fit(X, y)
# 在訓練集上進行預測
pred_y_4 = clf_4.predict(X)
# 我們的模型仍然僅能預測一個類別嗎?
print( np.unique( pred_y_4 ) )
# [0 1]
# 我們的準確率如何?
print( accuracy_score(y, pred_y_4) )
# 0.9744
# AUROC 怎麼樣?
prob_y_4 = clf_4.predict_proba(X)
prob_y_4 = [p[1] for p in prob_y_4]
print( roc_auc_score(y, prob_y_4) )
# 0.999078798186複製程式碼哇! 97% 的準確率和接近 100% AUROC 是魔法嗎?戲法?作弊?是真的嗎?
嗯,樹集合已經非常受歡迎,因為他們在許多現實世界的問題上表現的非常良好。我們當然全心全意地推薦他們。
然而:
雖然這些結果令人激動,但是模型可能導致過擬合,因此你在做出最終決策之前仍舊需要在未見過的測試集上評估模型。
注意: 由於演算法的隨機性,你的結果可能略有不同。為了能夠復現試驗結果,你可以設定一個隨機種子。
順便提一下
有些策略沒有寫入本教程:
建立合成樣本 (資料增強)
建立合成樣本與上取樣非常相似, 一些人將它們歸為一類。例如, SMOTE 演算法 是一種從少數類別中重取樣的方法,會輕微的引入噪聲,來建立”新“樣本。
你可以在 imblearn 庫 中 找到 SMOTE 的一種實現
注意:我們的讀者之一,馬可,提出了一個很好的觀點:僅使用 SMOTE 而不適當的使用交叉驗證所造成的風險。檢視評論部分了解更多詳情或閱讀他的關於本主題的 部落格文章 。
組合少數類別
組合少數類別的目標變數可能適用於某些多類別問題。
例如,假如你希望預測信用卡欺詐行為。在你的資料集中,每種欺詐方式可能會分別標註,但你可能並不關心區分他們。你可以將它們組合到單一類別“欺詐”中並把此問題歸為二值分類問題。
重構欺詐檢測
異常檢測, 又稱為離群點檢測,是為了檢測異常點(或離群點)和小概率事件。不是建立一個分類模型,你會有一個正常觀測樣本的 ”輪廓“。如果一個新觀測樣本偏離 “正常輪廓” 太遠,那麼它就會被標註為一個異常點。
總結 & 下一步
在本指南中,我們介紹了 5 種處理不平衡類別的有效方法:
- 上取樣 少數類別
- 下采樣 多數類別
- 改變你的效能指標
- 懲罰演算法 (代價敏感學習)
- 使用基於樹的演算法
這些策略受沒有免費的午餐定理支配,你應該嘗試使用其中幾種方法,並根據測試集的結果來決定你的問題的最佳解決方案。
如果你喜歡本指南,我們邀請你註冊我們的 7天免費應用機器學習速成課。我們會分享在我們部落格中找不到的課程,當我們釋出類似本教程的新教程時我們會給你傳送通知。
掘金翻譯計劃 是一個翻譯優質網際網路技術文章的社群,文章來源為 掘金 上的英文分享文章。內容覆蓋 Android、iOS、React、前端、後端、產品、設計 等領域,想要檢視更多優質譯文請持續關注 掘金翻譯計劃。