執行計劃的代價估算
實驗:
建立表
create table t as select * from dba_objects ;
檢視段,以及塊的數目
select extents,blocks from user_segments where segment_name = 'T' ;
檢視錶,以及表的數目
select num_rows , blocks from user_tables where table_name='T' ;
建立直方圖:
SQL>exec dbms_stats.gather_table_stats(user,'t',method_opt=>'for all columns size 254');
建立直方圖後,統計資訊就會比較準
set autotrace trace exp ;
select * from t where object_id=1 ;
DBMS_STATS包和analyze命令:
analyze : 已經過時
1. 無法提供靈活的分析選項
2. 無法提供並行分析
3. 無法對分析資料進行管理
DBMS_STATS:
1. 專門為CBO提供資訊來源
2. 可以進行資料分析的多種組合
3. 可以對分割槽進行分析
4. 可以進行分析資料管理
-- 備份,恢復,刪除,設定
oracle自動資訊收集
user_tab_modification跟蹤表:這個表記錄了表的修改,當分析物件的資料修改超過10%,oracle會重新分析。
定時任務:GATHER_STATS_JOB負責重新定時
當插入到表資料以後,user_tab_modification並不會馬上記錄,會有延遲的。
如果要馬上生效,可以用SQL>exec DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO ;
檢視檢視DBA_SCHEDULER_JOB_RUN_DETAILS 來顯示JOB的執行情況。
eg: select log_id,job_name,status from dba_scheduler_job_run_details where job_name='GATHER_STATS_JOB';
表分析:
DBMS_STATS.GATHER_TABLE_STATS
eg: SQL>exec dbms_stats.gather_table_stats(user,'t');
但如果表很大,取樣比例儘量小一些,否則會消耗很多時間的。
SQL>exec dbms_stats.gather_table_stats(user,'t',cascade=>true);
這個語句表示分析表的同時,也分析索引。
索引分析:
DBMS_STATS.GATHER_INDEX_STATS
對於小表來說,可以全表掃描,而大表,儘量要小些。
granularity資料分析的力度:
這個引數用於分割槽表的取樣,它的值包含:global , partition , subpartition
global:針對整個表的資料分析
partition:針對分割槽的資料分析
subpartition: 針對分割槽表的子分割槽的分析
檢視分割槽表的塊情況
select * from user_tab_partitions where table_name='T' ;
select * from user_tables where table_name='T' ;
SQL>exec dbms_stats.gather_table_statis(user,'TG',granularity=>'partition');
表上已經有全域性統計資訊時,單獨對分割槽分析,不會更新全域性資訊。
當表上沒有全域性資訊的時候,單獨對分割槽分析,會更新全域性資訊。
刪除全域性分割槽的統計資訊命令:
SQL>exec dbms_stats.delete_table_stats(user,'t',cascade_parts=false ) ;
11g以後增量全域性分析來更新全域性資訊:
SQL>exec dbms_stats.set_table_preps(user,'t','incremental','true');
SQL>exec dbms_stats.gather_table_stats(user,'t');
select num_rows,blocks,global_stats from user_tables
where table_name='T' ;
直方圖:只有在收集了直方圖以後,oracle才知道哪個值有多少條記錄。

平衡直方圖:

frequent直方圖:
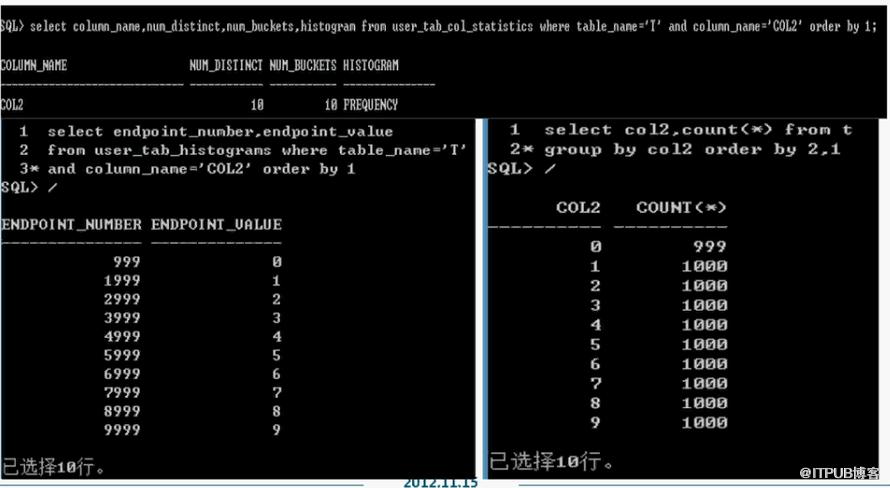
gather_table_stats.method_opt引數 :
for all columns 統計所有列
for all indexed columns 統計所有索引
for columns list size
N的取值為1-254
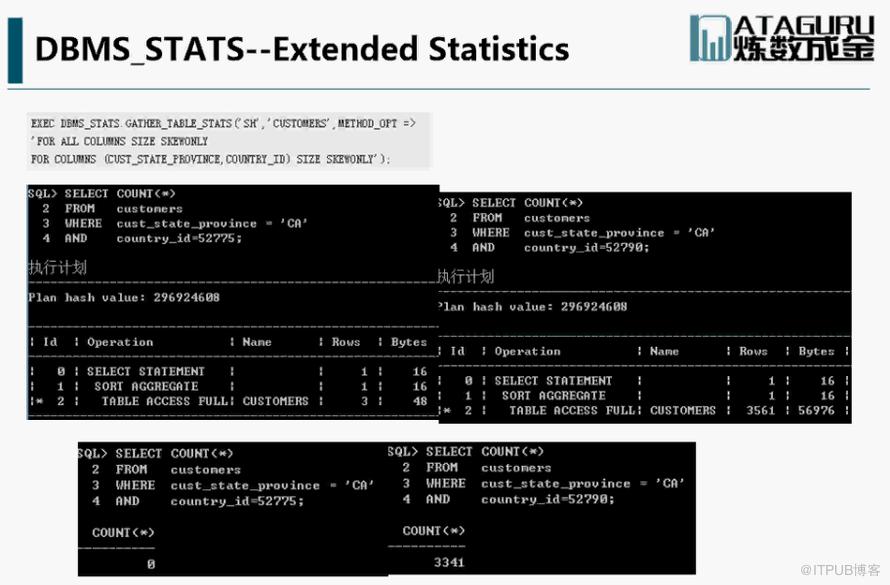
擴充套件分析 ,相關性查詢:
動態取樣:
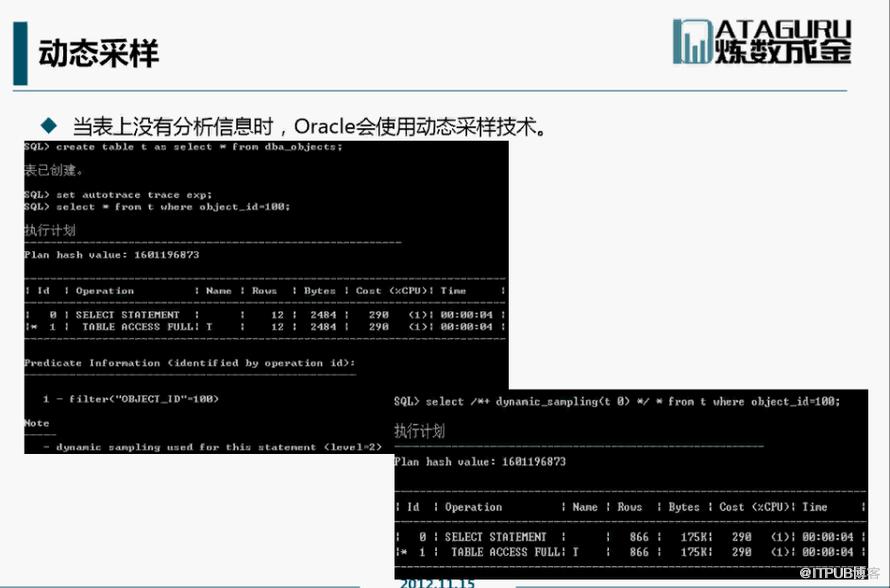
動態取樣是有級別的,1-10,級別越高,取樣 時間越長。
對於OLAP系統,沒有多少使用者去連線,反而執行計劃的結果更重要,因此OLAP系統可以將動態取樣的級別設定高一些。

建立表
create table t as select * from dba_objects ;
檢視段,以及塊的數目
select extents,blocks from user_segments where segment_name = 'T' ;
檢視錶,以及表的數目
select num_rows , blocks from user_tables where table_name='T' ;
建立直方圖:
SQL>exec dbms_stats.gather_table_stats(user,'t',method_opt=>'for all columns size 254');
建立直方圖後,統計資訊就會比較準
set autotrace trace exp ;
select * from t where object_id=1 ;
DBMS_STATS包和analyze命令:
analyze : 已經過時
1. 無法提供靈活的分析選項
2. 無法提供並行分析
3. 無法對分析資料進行管理
DBMS_STATS:
1. 專門為CBO提供資訊來源
2. 可以進行資料分析的多種組合
3. 可以對分割槽進行分析
4. 可以進行分析資料管理
-- 備份,恢復,刪除,設定
oracle自動資訊收集
user_tab_modification跟蹤表:這個表記錄了表的修改,當分析物件的資料修改超過10%,oracle會重新分析。
定時任務:GATHER_STATS_JOB負責重新定時
當插入到表資料以後,user_tab_modification並不會馬上記錄,會有延遲的。
如果要馬上生效,可以用SQL>exec DBMS_STATS.FLUSH_DATABASE_MONITORING_INFO ;
檢視檢視DBA_SCHEDULER_JOB_RUN_DETAILS 來顯示JOB的執行情況。
eg: select log_id,job_name,status from dba_scheduler_job_run_details where job_name='GATHER_STATS_JOB';
表分析:
DBMS_STATS.GATHER_TABLE_STATS
eg: SQL>exec dbms_stats.gather_table_stats(user,'t');
但如果表很大,取樣比例儘量小一些,否則會消耗很多時間的。
SQL>exec dbms_stats.gather_table_stats(user,'t',cascade=>true);
這個語句表示分析表的同時,也分析索引。
索引分析:
DBMS_STATS.GATHER_INDEX_STATS
對於小表來說,可以全表掃描,而大表,儘量要小些。
granularity資料分析的力度:
這個引數用於分割槽表的取樣,它的值包含:global , partition , subpartition
global:針對整個表的資料分析
partition:針對分割槽的資料分析
subpartition: 針對分割槽表的子分割槽的分析
檢視分割槽表的塊情況
select * from user_tab_partitions where table_name='T' ;
select * from user_tables where table_name='T' ;
SQL>exec dbms_stats.gather_table_statis(user,'TG',granularity=>'partition');
表上已經有全域性統計資訊時,單獨對分割槽分析,不會更新全域性資訊。
當表上沒有全域性資訊的時候,單獨對分割槽分析,會更新全域性資訊。
刪除全域性分割槽的統計資訊命令:
SQL>exec dbms_stats.delete_table_stats(user,'t',cascade_parts=false ) ;
11g以後增量全域性分析來更新全域性資訊:
SQL>exec dbms_stats.set_table_preps(user,'t','incremental','true');
SQL>exec dbms_stats.gather_table_stats(user,'t');
select num_rows,blocks,global_stats from user_tables
where table_name='T' ;
直方圖:只有在收集了直方圖以後,oracle才知道哪個值有多少條記錄。
平衡直方圖:
frequent直方圖:
gather_table_stats.method_opt引數 :
for all columns 統計所有列
for all indexed columns 統計所有索引
for columns list size
N的取值為1-254
擴充套件分析 ,相關性查詢:
動態取樣:
動態取樣是有級別的,1-10,級別越高,取樣 時間越長。
對於OLAP系統,沒有多少使用者去連線,反而執行計劃的結果更重要,因此OLAP系統可以將動態取樣的級別設定高一些。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/29196873/viewspace-1137314/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 執行計劃-1:獲取執行計劃
- 分析執行計劃優化SQLORACLE的執行計劃(轉)優化SQLOracle
- 執行計劃中Cardinality (Estimated Rows, E-Rows) 估算錯誤原因分析
- 【執行計劃】Oracle獲取執行計劃的幾種方法Oracle
- 【Oracle】-【索引-HINT,執行計劃】-帶HINT的索引執行計劃Oracle索引
- 分析執行計劃最佳化SQLORACLE的執行計劃(轉)SQLOracle
- 執行計劃
- SQL的執行計劃SQL
- 執行計劃的理解.
- oracle sqlprofile 固定執行計劃,並遷移執行計劃OracleSQL
- 【sql調優之執行計劃】獲取執行計劃SQL
- 並行的代價並行
- SYBASE執行計劃
- MySQL 執行計劃MySql
- MySQL執行計劃MySql
- sql 執行計劃SQL
- ORACLE執行計劃Oracle
- 生成執行計劃的方法
- Oracle中檢視已執行sql的執行計劃OracleSQL
- sql執行計劃變更和刪除快取中執行計劃的方法SQL快取
- sqm執行計劃的繫結
- SqlServer的執行計劃如何分析?SQLServer
- 看懂Oracle中的執行計劃Oracle
- 獲取執行計劃的方法
- ORACLE執行計劃的介紹Oracle
- 執行計劃的閱讀方法
- sql的執行計劃 詳解SQL
- ORACLE執行計劃的檢視Oracle
- oracle執行計劃的使用(EXPLAIN)OracleAI
- ORALCE的執行計劃穩定性
- 檢視執行計劃的方法
- 修改Process Chain的執行計劃AI
- 【PG執行計劃】Postgresql資料庫執行計劃統計資訊簡述SQL資料庫
- oracle 固定執行計劃Oracle
- Oracle sql執行計劃OracleSQL
- explain執行計劃分析AI
- mysql執行計劃explainMySqlAI
- mysql explain 執行計劃MySqlAI