特徵提取之Haar特徵
特徵提取之Haar特徵
一、前言(廢話)
很久沒有寫部落格了,一晃幾年就過去了,為了總結一下自己看的一些論文,以後打算寫一些自己讀完論文的總結。那麼,今天就談一談人臉檢測最為經典的演算法Haar-like特徵+Adaboost。這是最為常用的物體檢測的方法(最初用於人臉檢測),也是用的最多的方法,而且OpenCV也實現了這一演算法,可謂路人皆知。另外網上寫這個演算法的人也不在少數。
二、概述
首先說明,我主要看了《Rapid Object Detection using a Boosted Cascade of Simple Features》和《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》這兩篇論文。
2.1為什麼需要Haar特徵,為什麼要結合Adaboost演算法
我們知道人臉檢測是很不容易的,我們在實際進行人臉檢測的時候,需要考慮演算法的執行速度,以及演算法的準確度,單單實現這兩個指標就已經很不容易了。傳統的人臉檢測方法(指的是在Haar-like特徵出來之前的方法,也就是2001年之前了)一般都是基於畫素級別進行的,常見的方法有基於皮膚顏色的方法,這些方法的缺點就是速度慢,幾乎不能實現實時性。
2.2演算法的大體流程
首先給出訓練過程
輸入影像->影像預處理->提取特徵->訓練分類器(二分類)->得到訓練好的模型
接著給出測試過程
輸入影像->影像預處理->提取特徵->匯入模型->二分類(是不是所要檢測的物體)。
接下來就對演算法的關鍵的步驟進行介紹。
3具體介紹
3.1影像預處理(歸一化或者稱為光照修正)
我們知道不同的光照對於所處理的影像有影響,為了減低這種影響我們需要首先對影像進行歸一化(在《Rapid Object Detection using a Boosted Cascade of Simple Features》中稱之為歸一化,而在《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》中稱之為Lighting Correction,即光照修正)。
那麼如何進行光照修正:
上述公式中
其實這裡我看到《Rapid Object Detection using a Boosted Cascade of Simple Features》中第六頁它寫成了
3.2提取特徵
首先介紹一下Haar-like特徵。如下圖所示,Haar-like特徵是很簡單的,無非就是那麼幾種,首先介紹論文《Rapid Object Detection using a Boosted Cascade of Simple Features》中提到的三種特徵,分為兩矩形特徵、三矩形特徵、對角特徵。當然還有很多分類方法,這裡先不介紹,下面在繼續講。先介紹如何計算特徵。
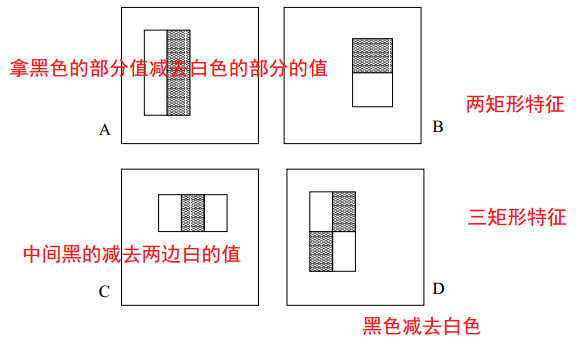
圖1 三種型別的Haar-like特徵
計算特徵很簡單,就是拿黑色部分的所有的畫素值的和減去白色部分所有畫素值的和。得到的就是一個特徵值。
說的很簡單,但是在工程中需要進行快速計算某個矩形內的畫素值的和,這就需要引入積分圖的概念。
(1)使用積分圖加速計算特徵
需要注意的是這裡的積分圖輸入的影像是經過歸一化的影像哈。與上面用到的符號不一樣了。
首先給出積分圖的定義:
上述含義是指在位置
那麼我們實現的時候是如何進行計算積分圖的呢?
初始值
上面這兩個遞迴公式是什麼意思呢?就是首先每一行都遞迴計算s(x,y)(公式中也可以看出是按行計算的),每一行首先都是計算s,計算完畢之後在每一列都計算ii(x,y)。這樣掃描下去就可以計算好了積分圖了。這種方法跟動態規劃的思想有點類似。
好了計算好了積分圖,我們接下來就可以利用積分圖來加速計算某個方塊內部的畫素的和了。
(2)計算方塊內的畫素和
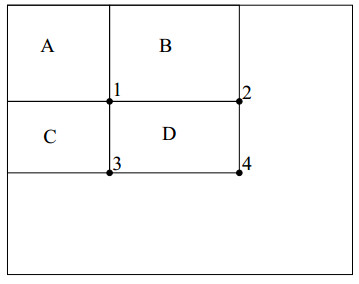
圖2 計算某個方塊內的畫素和
圖中的大框是積分圖,為了講解如何計算任意矩形內的畫素值,我們畫出四個區域A、B、C、D,並且圖中有四個位置分別為1、2、3、4。我們要計算D區域內部的畫素和該怎麼計算?
我們記位置4的左上的所有畫素為
D位置的畫素之和就是
是不是有了積分圖,就可以很快地計算出了任意矩形內的畫素之和了?
我們前面提到有三種型別的Haar-like特徵。
其中二矩形特徵需要6次查詢積分圖中的值,而三矩形特徵需要8次查詢積分圖中的值,而對角的特徵需要9次。
(3)提取的特徵的個數有多少?
那麼,如果給定一個視窗,視窗的大小為24*24畫素,那麼我們得到的特徵有多少個呢?
計算公式如下:
可以參考本文的第一幅圖中的ABCD個特徵那幅圖。
加起來一共有大約16000多個(不止16000哈)。可以自己算一下。
3.3使用Adaboost進行訓練
在輸入影像之後首先計算積分圖,然後通過積分圖在計算上述三種特徵,如果視窗的大小為24*24畫素,那麼生成的特徵數目有16000之多。
(1)弱分類器的定義
Adaboost演算法中需要定義弱分類器,該弱分類器的定義如下:
上述公式中的
(2)adaboost演算法
假設訓練樣本影像為
首先初始化權重
For
(1).首先歸一化權重:
(2)對於每一個特徵,我們都訓練一個分類器(記為
那麼對於該特徵的誤差
(3)選擇擁有最低誤差的那個分類器記為
(4)更新權重
End For
那麼最終的強分類器為
其中
上述的訓練過程是遠遠不夠的,還需要對若干個分類器進行級聯,這樣才能夠取得更高的檢出率,並且取得較高的false positive rates。
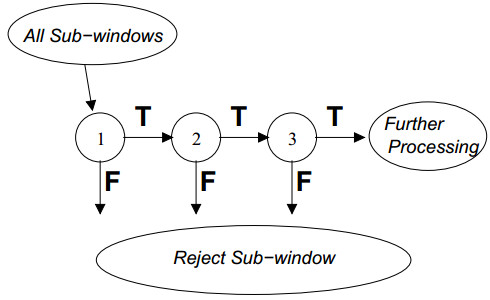
圖3 多個分類器的級聯
如圖3所示,首先第一個分類器的輸入是所有的子視窗,然後通過級聯的分類器去除掉一些子視窗,這樣能夠有效地降低視窗的數目,具體的去除方法就是如果任何一個級聯分類器提出拒絕,那麼後續的分類器就不需要處理之前分類器的子視窗。
通過這樣的一種機制能夠有效地去掉較多的子視窗,因為較大部分的子視窗中都沒有所要檢測的物體。
4其他一些引數的確定
4.1如何確定有多少個級聯的分類器,有多少個特徵,閾值如何確定的。
如圖3可以看出在訓練過程當中需要確定究竟有多少個分離器級聯才是最佳的,以及使用多少個特徵,每個弱分類器的閾值如何確定,這些引數的確定基本不可能實現。
這裡介紹一種比較簡單粗暴的方法:
我們首先指定一個檢出率和false positive rates。
每一個級聯的分類器都是通過加入不同的特徵,直到達到指定的檢出率和false positive rates才停止加入,並且有多少階段才結束是根據是否能夠達到特定的檢出率和false postive rate 來決定的。同樣,閾值也是這麼確定的。
4.2 掃描視窗的時候的縮放如何確定
假設掃描的時候的步長為
那麼當前的步長= [
4.3 合併檢測出的多個視窗
檢測到的子視窗的集合分成若干不相交的子集(每個子集中的子視窗都是相互重疊的),這些子集中的子視窗進行合併,集合中所有子視窗的左上角的座標的平均即為該集合所確定的視窗的左上角的座標。
5 補充說明
5.1 Haar-like特徵的分類(Haar-like特徵的變種)
如圖4所示為改進的特徵。
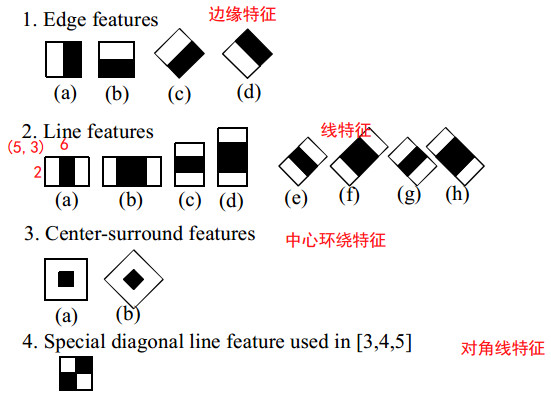
圖4 haar-like特徵
圖4中給出了四種分類分為將邊緣特徵、線特徵、中心環繞特徵以及對角線特徵。
這些特徵中的旋轉的特徵主要在《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》中得到了介紹。
特徵個數的確定通過如下公式確定
計算公式如下
對於旋轉45 °的特徵其計算公式如下:
其中
至於怎麼計算旋轉45°的特徵值,這裡先挖個坑。過一段時間在補充上來。
5.2 Adaboost的變種
《Empirical Analysis of Detection Cascades of Boosted Classifiers for Rapid Object Detection》中介紹了三種變種分為Real Adaboost ,Discrete Adaboost以及Gentle Adaboost。差別不是很大。具體參考該論文。
6 參考文獻
[1] Viola P, Jones M J. Robust real-time face detection[J]. International journal of computer vision, 2004, 57(2): 137-154.
[2] Jones M. Rapid Object Detection using a Boosted Cascade of Simple[J].
[3] Lienhart R, Kuranov A, Pisarevsky V. Empirical analysis of detection cascades of boosted classifiers for rapid object detection[M]//Pattern Recognition. Springer Berlin Heidelberg, 2003: 297-304.
7 想要說的話
後期會分析一下Haar進行人臉檢測的程式碼(matlab和OpenCV的實現),看時間允許不允許了。
http://www.mathworks.com/matlabcentral/fileexchange/29437-viola-jones-object-detection
其實想詳細介紹Adaboost的證明的,考慮到是Haar是主角,這裡沒有詳細介紹Adaboost。此外Haar 特徵的變種也是個坑,還需要詳細介紹。
基本就這麼多,有講的不明白的地方歡迎留言反饋。
相關文章
- 影象特徵提取之HoG特徵特徵HOG
- 特徵值與特徵向量特徵
- 特徵值和特徵向量特徵
- 計算機視覺—人臉識別(Haar特徵+Adaboost分類器)(7)計算機視覺特徵
- 特徵工程:互動特徵與多項式特徵理解特徵工程
- 特徵工程之特徵表達特徵工程
- 特徵工程之特徵選擇特徵工程
- 特徵值 和 特徵向量,thrive特徵
- 08 特徵工程 - 特徵降維 - LDA特徵工程LDA
- 影像特徵計算——紋理特徵特徵
- 特徵工程之特徵預處理特徵工程
- 機器學習 特徵工程之特徵選擇機器學習特徵工程
- 特徵模型和特徵-這是什麼?特徵模型
- 矩陣的特徵值和特徵向量矩陣特徵
- 特徵工程特徵工程
- HOF特徵特徵
- 特徵工程 特徵選擇 reliefF演算法特徵工程演算法
- 機器學習的靜態特徵和動態特徵機器學習特徵
- 特徵融合與特徵互動的區別特徵
- Haar、pico、npd、dlib等多種人臉檢測特徵及演算法結果比較特徵演算法
- 特徵工程系列:(三)特徵對齊與表徵特徵工程
- 特徵選擇和特徵生成問題初探特徵
- [特徵工程系列三]顯性特徵的衍生特徵工程
- 從高斯消元法到特徵值特徵向量特徵
- 機器學習-特徵提取機器學習特徵
- 機器學習 | 特徵工程機器學習特徵工程
- Cobaltstrike去除特徵特徵
- 機器學習——特徵工程機器學習特徵工程
- 特徵提取-map特徵
- 特徵工程梗概特徵工程
- 機器學習特徵工程機器學習特徵工程
- 特徵工程思路特徵工程
- 特徵檢測特徵
- webshell流量特徵Webshell特徵
- sift、surf、orb 特徵提取及最優特徵點匹配ORB特徵
- [特徵工程系列一] 論特徵的重要性特徵工程
- xgboost 特徵選擇,篩選特徵的正要性特徵
- 【特徵值 / 特徵向量】- 圖解線性代數 11特徵圖解