Oracle RAC入門和提高
【IT168 技術文件】
Oracle RAC 產品概述
Oracle Real Application Server,真正應用叢集,簡稱Oracle RAC ,是Oracle的並行叢集,位於不同伺服器系統的Oracle例項同時訪問同一個Oracle資料庫,節點之間通過私有網路進行通訊,所有的控制檔案、聯機日誌和資料檔案存放在共享的裝置上,能夠被叢集中的所有節點同時讀寫。其系統架構如下圖: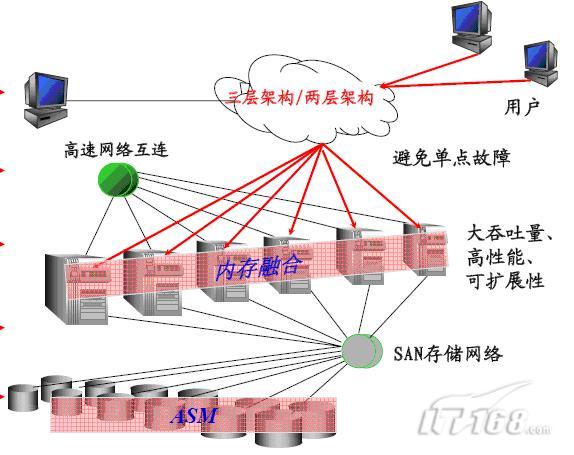
RAC提供的好處包括:
(1)多節點負載均衡;
(2)提供高可用:故障容錯和無縫切換功能,將硬體和軟體錯誤造成的影響最小化,下表是RAC與傳統的雙機熱備方式切換時間的對比:
(3)通過並行執行技術提高事務響應時間----通常用於資料分析系統;
(4)通過橫向擴充套件提高每秒交易數和連線數 ;----通常對於聯機事務系統;
(5)節約硬體成本,可以用多個廉價PC伺服器代替昂貴的小型機或大型機,同時節約相應維護成本;
(6)可擴充套件性好,可以方便新增刪除節點,擴充套件硬體資源;
RAC的缺點有:
相對單機,管理更復雜,要求更高;
在系統規劃設計較差時效能甚至不如單節點;
可能會增加軟體成本(如果使用高配置的pc伺服器,Oracle一般按照CPU個數收費)
在Oracle9i之前,RAC的名稱是OPS (Oracle parallel Server)。RAC 與 OPS 之間的一個較大區別是,RAC採用了Cache Fusion(快取記憶體合併)技術。在 OPS 中,節點間的資料請求需要先將資料寫入磁碟,然後發出請求的節點才可以讀取該資料。使用Cache fusion時,RAC的各個節點的資料緩衝區通過高速、低延遲的內部網路進行資料塊的傳輸。
Oracle RAC在中國各行各業使用都比較廣泛,包括通訊移動、金融服務、社會保障和電子商務等, 據Oracle統計,2007財年中國有500多家企業使用Oracle實時應用叢集,考慮到未登記資訊,實際數字更高於這一數字。典型的使用者包括:中彩線上/OLTP/4節點/10gR2/AIX5.3、淘寶/DataWarehouse/4節點/10gR2/RHEL4、北京社保/6節點/HP_Alpha/ MA8000、建行證券系統/2節點/IBM_P595/EMC_DMX3、上海電力/2節點/Alpha_GS160、廣東移動、山東網通等。
Oracle RAC/Clusterware的結構和元件
一、RAC主要元件, 軟硬體兩部分
(1) 伺服器 >= 2
(2) 作業系統,推薦使用Oracle認證的系統;版本不要太老,也不要太新
(3) CPU/記憶體 根據業務需要,記憶體至少1G
(4) 本地磁碟空間,>=30G
(5) 網路卡 >=2 ,推薦4個以上千兆網路卡
(6) 私有乙太網路,推薦千兆交換機以上
(7) HBA卡 ,如果是SAN,推薦2個冗餘HBA
(8) 共享儲存裝置,推薦SAN裝置
(9) 儲存管理, ASM/Cluster LV/裸分割槽/CFS,不推薦用OCFS,卷管理軟體、多路徑軟體等
(10) 第三方叢集軟體: 可選
(11) Oracle Clusterware 軟體
(12) Oracle RDBMS 軟體
二、Clusterware主要程式
(1)crsd: 負責管理叢集的高可用操作。管理的crs資源包括資料庫、例項、監聽、虛擬IP,ons,gds或者其他,操作包括啟動、關閉、監控及故障切換。改程式由root使用者管理和啟動。crsd如果有故障會導致系統重啟。
(2)cssd,管理各節點的關係,用於節點間通訊,節點在加入或離開叢集時通知叢集。該程式由oracle使用者執行管理。發生故障時cssd也會自動重啟系統。
(3)oprocd – 叢集程式管理 —Process monitor for the cluster. 用於保護共享資料IO fencing。
僅在沒有使用vendor的叢集軟體狀態下執行
(4)evmd :事件檢測程式,由oracle使用者執行管理
三、Clusterware使用的共享裝置
(1) Oracle Cluster Registry(OCR):記錄叢集的配置資訊;
(2) Voting disk : 即投票盤,儲存節點的成員資訊,當配置多個投票盤的時候個數必須為奇數,每個節點必須同時能夠連線半數以上的投票盤才能夠存活;
四、安裝路徑的選擇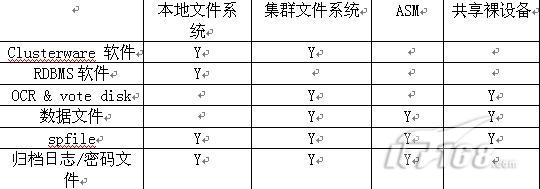
注:
(1)在Oracle RAC中,軟體不建議安裝在共享檔案系統上;包括CRS_HOME和ORACLE_HOME,尤其是CRS軟體,推薦安裝在本地檔案系統中,這樣在進行軟體升級,以及安裝patch和patchset的時候可以使用滾動升級(rolling upgrade)的方式,減少計劃當機時間。另外如果軟體安裝在共享檔案系統也會增加單一故障點。
(2)如果使用ASM儲存,需要為asm單獨安裝ORACLE軟體,獨立的ORACLE_HOME,易於管理和維護,比如當遇到asm的bug需要安裝補丁時,就不會影響RDBMS檔案和軟體。
(3)在Oracle 11gR2中將新增儲存選項:acfs (Oracle ASM Cluster File System)
第三方叢集
在Oracle9i中,除了Windows和Linux,在安裝RAC之前必須先安裝vendor clusterware,即第三方叢集,包括IBM的HACMP, HP的ServiceGuard for oracle RAC, Sun cluster,Veritas SFRAC等,這一類的叢集軟體為Oracle RAC提供了下面的功能:
(1)共享的邏輯卷管理或者叢集檔案系統用於存放資料檔案;
(2)提供了統一的叢集的成員組管理;
(3)使用更健壯的SCSI-3 PGR機制來防止心跳故障(即裂腦split brain)導致的資料損壞,這種功能一般叫做IO fencing;
(4)提供效率更高的、更低延遲的心跳網路用於cache fusion,可以相對減少TCP/IP的開銷,包括:
HP SGeRAC: HMP (Hyper Messaging Protocol),
Sun Cluster: RSM (Remote Shared Memory),
Veritas SFRAC: LLT (low-latency transport),
Compac True Cluster: RDG (reliable data grams);
通常如果要使用第三方叢集的心跳協議,需要將$ORACLE_HOME/lib/libskgxpX.so檔案替換為第三方叢集
軟體提供的libskgxpX.so檔案(其中X代表Oracle版本號9/10/11),skgxp 是System Kernel Generic Interface Inter-Process Communications的縮寫,是oracle開放的一個應用介面,用於傳輸GCS和GES 的資料。Oracle自帶的libskgxp檔案定義的傳輸協議是UDP/IP。
(5)提供擴充套件的容災方案,例如campus cluster/metro cluster/extended RAC;如下圖, 以Veritas的SFRAC為例,它提供兩種Oracle Extended RAC方案,方案一是使用Veritas Volume Manager對底層陣列進行映象,提供同城容災級別的實時資料保護;方案二使用GCO/VVR對資料庫進行資料複製,可以實現距離更遠、超過10km廣域網的容災;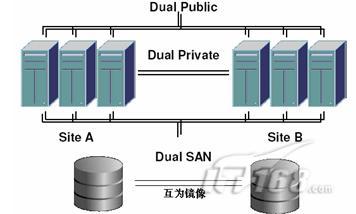
(6)Veritas SFRAC 還提供了以下特性:
補充的Oracle ODM,可以使Oracle同時擁有檔案系統的易管理和裸裝置的效能;
標準的多路徑軟體(DMP),不需要再安裝其他軟體就可支援絕大多數磁碟陣列,在異構SAN環境中有更好的相容性;
從Oracle10g起,Oracle提供了自己的叢集軟體,叫Oracle clusterware簡稱CRS,這個軟體是安裝oracle rac的前提,而上述第三方叢集則成了安裝的可選項 。同時提供了另外一個新特性叫做ASM,可以用於RAC下的共享磁碟裝置的管理,還實現了資料檔案的條帶化和映象,以提高效能和安全性 (S.A.M.E: stripe and mirror everything ) ,不再依賴第三方儲存軟體來搭建RAC系統。
那麼Oracle是如何識別第三方叢集的呢?
在安裝完第三方叢集后,會在特定目錄下生成Oracle RAC介面檔案,這個檔案的作用就是上面的第二點功能:叢集成員管理資訊(cluster membership 簡稱CM)。在HPUX下該檔案是/opt/nmapi/nmapi2/lib/pa20_64,在AIX/Solaris/Linux下這個檔案是/opt/ORCLcluster/lib/libskgxn2.so 。
當安裝CRS的的檢查階段,就會檢測是否有該檔案,如果有的話,在安裝CRS過程中生成一個軟連線檔案,檔名是ligskgxn2.so,指向上面的libskgxn2.so或pa20_64檔案,這個軟連線的位置在CRS_HOME/lib/目錄;如果沒有第三方叢集,那麼CRS安裝過程中生成自己的libskgxn2.so檔案。換句話說,在有第三方叢集存在的情況下,CRS的叢集成員資訊是來自於第三方叢集,兩套叢集的成員資訊保持一致和同步;沒有第三方叢集情況時,CRS自己管理成員資訊。
通過查詢$CRS_HOME/log/hostname/cssd/ocssd.log可以看到css識別到的第三方叢集,下面的例子分別是HACMP、SFRAC、SunCluster、ServiceGuide :
[CSSD]2008-05-27 15:09:43.456 [1029] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/IBM AIX skgxn)
[CSSD]2008-12-30 21:44:56.172 [1029] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/Veritas Cluster Server MM
[CSSD]2007-08-10 02:19:39.572 [3] >TRACE: clssnm_skgxninit: initialized skgxn version (2/2/Oracle Solaris UDLM)
[CSSD]2006-09-29 18:57:53.323 [5] >TRACE: clssnm_skgxninit: initialized skgxn version (2/0/Hewlett-Packard SKGXN 2.0)
在9i/8i中沒有css/crs,該資訊可以在後臺程式lmon的trace檔案中得到(在bdump中);
在安裝Oracle 9i RAC/8i OPS的過程中,Oracle識別叢集方法類似。
在多個平臺上,如果兩個節點沒有正確連結libskgxn2檔案,可能會導致第二個例項無法mount或出現ORA-600錯誤。
Oracle支援的RAC環境
因為Oracle RAC本身比較複雜,在安裝和管理中可能會遇到各種問題,涉及到OS、RDBMS、Cluster軟體和網路、主機、儲存等硬體,為了避免不必要的問題發生,在安裝之前,我們需要確認安裝環境是否滿足要求,包括軟體和硬體兩方面,尤其是Vendor clusterware和OS 的版本的相容性需要注意,可以從metalink中得到最新的Oracle官方認證資訊:登陸Metalink.oracle.com 選擇 Certify,選擇by product,選擇real application server,選擇對應平臺就可以得到。下面列出一些關於硬體和平臺支援的常見問題:
官方不支援的:Vmware, Sun LDOM ,Solaris Local Container/Zones
官方支援的: IBM LPAR, IBM VIOS(Virtual IO Server), Solaris Global Containers
RHEL GFS , ISCSI,
私有網路(心跳線)的支援: 不支援使用交叉線,支援 Infiniband RDS (10gR2之後)
異構環境:支援不同的硬體、但相同的軟體(OS/Oracle)組成的叢集,不支援32位與64位系統間的叢集
目前支援的NFS的server包括:
EMC Celerra
Fujitsu Filer NR1000 Series
IBM N Series
NetApp FAS, F, G Series
Pillar Data Systems Axiom 500
Sun StorageTek 5000 Series
Oracle Clusterware的心跳
Oracle clusterware 使用兩種心跳裝置來驗證成員的狀態,保證叢集的完整性;一是對voting disk的心跳,ocssd程式每秒向votedisk寫入一條心跳資訊;二是節點間的私有乙太網的心跳,兩種心跳機制都有一個對應的超時時間,分別叫做misscount和disktimeout:
misscount 用於定義節點間心跳通訊的超時,單位為秒;
disktimeout ,預設200秒,定義css程式與vote disk連線的超時時間;
reboottime ,發生裂腦並且一個節點被踢出後,這個節點將在reboottime的時間內重啟;預設是3秒;
其中misscount預設值見下表
用下面的命令檢視上述引數的實際值:1. # crsctl get css misscount
2. # grep misscount $CRS_HOME/log/hostname/cssd/ocssd.log
[CSSD]2008-11-27 22:29:42.397 [1] >TRACE: clssnmInitNMInfo: misscount set to 600
在下面兩種情況發生時,css會踢出節點來保證資料的完整,:
(1) Private Network IO time > misscount,會發生split brain即裂腦現象,產生多個“子叢集”(subcluster) ,這些子叢集進行投票來選擇哪個存活,踢出節點的原則按照下面的原則:
節點數目不一致的,節點數多的subcluster存活;節點數相同的,node ID小的節點存活。
(2) Vote Disk IO Time > disktimeout ,踢出節點原則如下:失去半數以上vote disk連線的節點將在reboottime的時間內重啟;例如有5個vote disk,當由於網路或者儲存原因某個節點與其中>=3個vote disk連線超時時,該節點就會重啟。當一個或者兩個vote disk損壞時則不會影響叢集的執行。
可以手工修改這三個引數的值,單位都是秒:(謹慎使用)
$CRS_HOME/bin/crsctl set css misscount
$CRS_HOME/bin/crsctl set css reboottime [-force]
$CRS_HOME/bin/crsctl set css disktimeout [-force]
或者重新設定成預設值:crsctl unset css misscount
Clusterware的私有網路
在Oracle 10g/11g中,Oracle的私有網路(private network)包括clusterware的私有網路和資料庫例項的私有網路:
clusterware的私有網路主要包括css資料的傳送,即用一種特殊的ping命令來檢測其他機器的狀態;
資料庫例項的私有網路,包括RDMS和ASM的,用於cache fusion(GCS/GES)資料的傳輸。
當我們只使用一個私有網路卡的時,同時傳送上面兩類的資料。如果我們在安裝時指定了兩個私有網路卡,首先使用如下面$CRS_HOME/bin/oifcfg getif命令來得到所有網路介面列表,這些資訊儲存在ocr中:
# oifcfg getif
en0 10.200.56.0 global public
en3 192.168.3.0 global cluster_interconnect
en5 192.168.5.0 global cluster_interconnect
情況會有所不同,clusterware的私有網路,目前(10g/11g)只能使用一個網路介面,對應於/etc/hosts中定義的private hostname的那個網路卡,可以通過檢視ocssd的log來確定:
當/etc/hosts 中定義private hostname為192.168.3.233時看到 :
[ CSSD]2009-01-16 17:34:12.406 [1029] >TRACE: clssgmPeerListener: Listening on (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.3.233)(PORT=45527))
這個是與其他節點css進行通訊的資訊:
[ CSSD]2009-01-16 17:36:27.463 [1029] >TRACE: clssgmConnectToNode: node 2 clsc (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.3.234)(PORT=37732)) - size 64 ver 1
當/etc/hosts 中定義private hostname為192.168.5.233時,css使用了另外一個網路:
[ CSSD]2009-01-16 18:59:56.411 [1029] >TRACE: clssgmPeerListener: Listening on (ADDRESS=(PROTOCOL=tcp)(DEV=12) (HOST=192.168.5.233)(PORT=50415))
Oracle例項的私有網路
Oracle例項的心跳網路使用方式的優先順序從高到低如下:
(1) 如果使用了第三方叢集的IPC,替換了對應$ORACLE_HOME/lib/libskgxnX.so檔案,那麼資料庫例項的cache fusion會使用對應的網路協議,而忽略ocr中和資料庫初始化引數中cluster_interconnects的配置,下面的例子當中就使用了VCSIPC,可以從對應的alert log中驗證:
db_name = r10g
open_cursors = 300
pga_aggregate_target = 1237319680
Fri Mar 13 14:00:35 2009
Oracle instance running with ODM: Veritas 6.0 ODM Library, Version 1.1
cluster interconnect IPC version:
VERITAS IPC 5.1.0.0 15:16:24 Feb 12 2009
IPC Vendor 86 proto 76
Version 1.0
PMON started with pid=2, OS id=4399196
DIAG started with pid=3, OS id=3936288
(2) 如果沒有使用第三方IPC,則優先使用資料庫初始化引數的cluster_interconnects配置,這個引數的格式為if1:if2:...:ifn,可以不同於crs的私有網路,需要注意的是,該引數不支援多個網路卡的故障切換;
(3) 沒有上面兩個配置,資料庫會使用oifcfg列出的心跳的網路,在對應的告警日誌中可以得到:
Interface type 1 en6 192.168.61.0 configured from OCR for use as a cluster interconnect
Interface type 1 en0 10.182.0.0 configured from OCR for use as a public interface
. . . .
Cluster communication is configured to use the following interface(s) for this instance
192.168.61.0
(4) 沒有1和2的配置,並且oifcfg也沒有配置cluster_interconnect,則資料庫會使用共有網路進行心跳資訊的傳輸,這種配置其實是配置失敗的情況,資料庫雖然能夠啟動,但急需DBA修正,在告警日誌中可以看到:
WARNING: No cluster interconnect has been specified. Depending on
the communication driver configured Oracle cluster traffic
may be directed to the public interface of this machine.
Oracle recommends that RAC clustered databases be configured
with a private interconnect for enhanced security and
performance.
對於一個已經有的系統,可以用下面幾種方法確認資料庫例項的心跳配置,包括網路卡名稱,IP地址,使用的網路協議:
(1) 最簡單的方法:可以在資料庫的後臺報警日誌中得到。具體參見上面列出的告警日誌;
(2) 使用oradebug ;
SQL> oradebug setmypid
SQL> oradebug ipc
SQL> oradebug tracefile_name
找到對應trace檔案的這一行:socket no 10 IP 10.0.0.1 UDP 49197
(3) 從資料字典中得到(V$CLUSTER_INTERCONNECTS 和 V$CONFIGURED_INTERCONNECTS),或查詢x$ksxpia
SQL> SELECT * FROM V$CLUSTER_INTERCONNECTS; ----Oracle 11g 開始支援此試圖
NAME IP_ADDRESS IS_ SOURCE
------------------------------ ---------------- --- -------------------------------
en3 192.168.2.31 NO Oracle Cluster Repository
en5 192.168.3.231 NO Oracle Cluster Repository
SQL> SELECT * FROM V$CONFIGURED_INTERCONNECTS;
NAME IP_ADDRESS IS_ SOURCE
------------------------------ ---------------- --- -------------------------------
en3 192.168.2.31 NO Oracle Cluster Repository
en5 192.168.3.231 NO Oracle Cluster Repository
en0 10.200.59.231 YES Oracle Cluster Repository
SQL> select * from x$ksxpia ;
ADDR INDX INST_ID PUB_KSXPIA PICKED_KSXPIA NAME_KSXPIA IP_KSXPIA
---------------- ---------- ---------- ---------- --------------- --------------- ----------------
00000001104AAF28 0 1 N OCR en6 192.168.61.121
00000001104AAF28 1 1 Y OCR en0 10.182.6.211
為了避免心跳網路成為系統的單一故障點,簡單地我們可以使用作業系統繫結的網路卡來作為Oracle的心跳網路,以AIX為例,我們可以使用etherchannel技術,假設系統中有ent0/1/2/3四塊網路卡,我們繫結2和3作為心跳:
#mkdev -c adapter -s pseudo -t ibm_ech -a adapter_names='ent2,ent3' ## 將生成網路卡裝置ent4
#/usr/lib/methods/defif
#lsdev -Cc adapter | grep ent
#lsattr -El ent4
#ifconfig en4 inet 192.168.3.231 netmask 255.255.255.0 up
在Solaris上可以使用dladm來建立鏈路聚合:
# dladm create-aggr -d bge2 -d bge3 1
# ifconfig aggr1 plumb 192.168.3.231 netmask 255.255.255.0 up
# dladm show-aggr
# ifconfig -a
同樣在HPUX和Linux對應的技術分別叫APA和bonding。
UDP私有網路的調優
當使用UDP作為資料庫例項間cashe fusion的通訊協議時,在作業系統上需要調整相關引數,以提高UDP傳輸效率,並在較大資料時避免出現超出OS限制的錯誤:
(1) UDP資料包傳送緩衝區:大小通常設定要大於(db_block_size * db_multiblock_read_count )+4k,
(2) UDP資料包接收緩衝區:大小通常設定10倍傳送緩衝區;
(3) UDP緩衝區最大值:設定儘量大(通常大於2M)並一定要大於前兩個值;
各個平臺對應檢視和修改命令如下:
Solaris 檢視 ndd /dev/udp udp_xmit_hiwat udp_recv_hiwat udp_max_buf ;
修改 ndd -set /dev/udp udp_xmit_hiwat 262144
ndd -set /dev/udp udp_recv_hiwat 262144
ndd -set /dev/udp udp_max_buf 2621440
AIX 檢視 no -a |egrep “udp_|tcp_|sb_max”
修改 no -p -o udp_sendspace=262144
no -p -o udp_recvspace=1310720
no -p -o tcp_sendspace=262144
no -p -o tcp_recvspace=262144
no -p -o sb_max=2621440
Linux 檢視 檔案/etc/sysctl.conf
修改 sysctl -w net.core.rmem_max=2621440
sysctl -w net.core.wmem_max=2621440
sysctl -w net.core.rmem_default=262144
sysctl -w net.core.wmem_default=262144
HP-UX 不需要
HP TRU64 檢視 /sbin/sysconfig -q udp
修改: 編輯檔案/etc/sysconfigtab
inet: udp_recvspace = 65536
udp_sendspace = 65536
Windows 不需要
常見安裝、管理錯誤
1. 安裝CRS失敗,或執行root.sh報錯,可能原因:
(1) 節點間的時間不同步,解決方法:使用ntp服務
(2) Linux下啟用了預設的防火牆,導致執行root.sh報錯:
Failure at final check of Oracle CRS stack.
10
解決方法:禁用iptables ,註釋/etc/pam.d/other ;
# service iptables stop; # chkconfig iptables off.
(3) 裸裝置的許可權問題,可能因為作業系統重新啟動後許可權發生變化。(RHEL4)
解決方法: 把 chown oracle:dba /dev/raw/raw* 命令加入到/etc/rc.local中,每次開機自動執行
或者修改檔案/etc/udev/permissions.d/50-udev.permissions
第113行raw/*:root:disk:0660 改成 raw/*:oracle:dba:0660
(4) Solaris使用了包括cylinder 0的磁碟分割槽來儲存OCR或者vote disk。
解決辦法:相關分割槽不應該包括cylinder 0,可以從1開始。
(5) 使用的公網IP地址不可路由,
解決方法:新增相關閘道器
(6) 在/etc/hosts 中沒有loopback地址,即127.0.0.1 localhost
(7) 主機名含有大些字母、減號或者下劃線等特殊字元;
(8) HPUX中oracle不要使用gnu的bash,修改使用預設shell;
(9) 檢查作業系統、第三方叢集是否是oracle官方支援的,是否需要補丁,比如在AIX5.3+HACMP上安裝
Oracle 10g/11g RAC,oslevel就需要06及以上;
(10) AIX平臺,需要將共享裝置的reserve_policy (reserve_lock) 屬性修改為no_reserve(no);
(11) 所有節點看到的OCR和vote裝置的路徑名應該一致,如果不一致,可以用軟連線解決;
(12) 心跳裝置問題或者ocr/votedisk 訪問問題,unix/linux檢視有無/tmp/crsctl.*檔案,得到錯誤資訊;
(13) 在CRS舊的安裝的環境中重新安裝失敗
解決方法: dd清除ocr和vote disk,並使用下面語句清理舊的crs配置檔案
rm -rf /usr/tmp/.oracle /var/tmp/.oracle /tmp/.oracle /etc/oracle/* /var/opt/oracle/*
rm -rf /etc/init.cssd /etc/init.crs* /etc/init.evmd /etc/init.d/init.cssd /etc/init.d/init.crs
rm -rf /etc/init.d/init.crsd /etc/init.d/init.evmd /etc/rc3.d/K96init.crs /etc/rc3.d/S96init.crs
rm -rf /etc/rc.d/rc2.d/K96init.crs /etc/rc.d/rc2.d/S96init.crs
2 客戶端有時候報錯:
ORA-12545: Connect failed because target host or object does not exist
ORA-12545: 因目標主機或物件不存在, 連線失敗
解決方法:設定local_listener初始化引數
3 如果選擇節點介面出不來。
(1)HACMP環境中需要檢查oracle 使用者必須在 hagsuser組裡.
(2)如果是hacmp5.4,需要打Oracle補丁6718715;
(3)可以使用叢集配置檔案cluster CONFIGURATION FILE ,內容模板如下:
MyCluster
rac01 rac01-priv rac01-vip
rac02 rac02-priv rac02-vip
rac03 rac03-priv rac03-vip
rac04 rac04-priv rac04-vip
4. AIX上資料庫啟動報錯
ora-27504 IPC error creating OSD context
ora-27300 OS system dependent operation:sendmsg failed with status:59
ora-27301 OS failure message:Message too long
ora-27302 failure occurred at:sskgxpsnd1
原因:沒有設定網路引數udp_recvspace/udp_sendspace
5. Windows平臺,ORA-600 [kccsbck_first]
解決方法:關閉Media Sense(媒體感知)
6. 系統迴圈重啟:
可能是CRS導致,如果因為crs,首先設定 crsctl disable crs 來禁止oracle crs的自動啟動。
檢視OS、crsd和cssd的對應日誌,看/tmp/下是否有crs檔案 (ls -lrt /tmp/crsctl*),確定crs失敗原因。
7. 第二個節點的資料例項無法mount,掛起或者報錯,
原因1:使用了vendor clusterware ,libskgxn2.so檔案連結錯誤,
解決方法:比較兩個節點的ORACLE_HOME/lib/libskgxn2和CRS_HOME/lib/libskgxn2*都是否相同,
如果不同需要重新link
原因2:任何平臺Oracle 9i,沒有設定網路引數udp引數
導致udp_sendspace或者udp_recvspace小於 db_block_size * db_file_multiblock_read_count
解決方法:設定對應引數,如AIX上設定udp_recvspace = 65536 udp_sendspace = 65536
原因3:AIX/HACMP/Oracle9i,在hacmp中定義了service IP
解決方法:在初始化引數中定義cluster_interconnects
原因4:任何平臺,設定了錯誤的cluster_interconnects
解決方法:檢查並糾正此引數,
8. 建庫時不能識別裸裝置;
原因1:Oracle,10.2.0.3 ,很多平臺(比如aix和linux)有rawutl相關bug,
解決辦法:還原10.2.0.1中的rawutl工具,該程式在 $ORACLE_HOME/bin目錄中。
原因2:Oracle9i,AIX平臺,需要設定環境變數export PGSD_SUBSYS=grpsvcs
9. evm資源自動報錯oac_init:2: Could not connect to server, clsc retcode = 9
解決方法:關閉 “UDP ICMP rejections”
/etc/rc.d/init.d/iptables stop ;chkconfig iptables off
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/7656893/viewspace-590663/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 詳細講述Oracle RAC入門和提高Oracle
- Oracle RAC入門和進步Oracle
- Oracle調優(入門及提高篇)Oracle
- Oracle RAC 基本概念及入門Oracle
- vuex 2 入門與提高Vue
- 《C#入門與提高》 (轉)C#
- 轉:Oracle RAC學習筆記:基本概念及入門Oracle筆記
- 《C#入門與提高》(一) (轉)C#
- SAP OData 開發教程 - 從入門到提高(包含 SEGW, RAP 和 CDP)
- 管理ORACLE RAC GUARD——RAC GUARD概念和管理Oracle
- ORACLE RAC GUARD操作——RAC GUARD概念和管理Oracle
- Oracle入門——起動和關閉詳解Oracle
- oracle入門之1 rac下啟動關閉與更改歸檔模式Oracle模式
- ORACLE RAC GUARD故障排除——RAC GUARD概念和管理Oracle
- 定製ORACLE RAC GUARD——RAC GUARD概念和管理Oracle
- 使用ORACLE RAC GUARD命令——RAC GUARD概念和管理Oracle
- ORACLE RAC GUARD架構——RAC GUARD概念和管理Oracle架構
- oracle入門之1 rac下啟動關閉與更改歸檔模式 (zt)Oracle模式
- 18Oracle入門Oracle
- 2、oracle入門心得Oracle
- ORACLE PL/SQ入門Oracle
- Oracle的入門心得Oracle
- ORACLE RAC GUARD配置引數——RAC GUARD概念和管理Oracle
- Docker 實戰教程之從入門到提高 (五)Docker
- Docker 實戰教程之從入門到提高 (六)Docker
- Docker 實戰教程之從入門到提高 (七)Docker
- Docker 實戰教程之從入門到提高(二)Docker
- Docker 實戰教程之從入門到提高(三)Docker
- Docker 實戰教程之從入門到提高 (四)Docker
- Docker 實戰教程之從入門到提高 (八)Docker
- Docker 實戰教程之從入門到提高(一)Docker
- Oracle RAC修改IP和VIP地址Oracle
- 為ORACLE RAC GUARD配置網路——RAC GUARD概念和管理Oracle
- [轉載] Oracle EBS 入門Oracle
- Oracle入門心得(2)(轉)Oracle
- Oracle RMAN快速入門指南Oracle
- ORACLE物化檢視入門Oracle
- oracle基礎入門(轉)Oracle