請謹慎使用sp_executesql
前一段時間,給一位朋友公司做諮詢,看到他們的很多的儲存過程都存在動態sql語句執行,sp_executesql,即使在沒有動態表名,動態欄位名的情況下仍然使用sp_executesql,這個做法是不太明智的,會存在一些效能方面的問題。
先說說什麼場景使用這個系統儲存過程吧,sp_executesql,是sql server動態執行一段可以帶有引數(內參,外參)的語句文字的系統儲存過程,傳入sp_executesql 的引數會以引數的形式傳遞,不會是以拼湊sql的形式傳遞,所以能夠在不得不拼接sql語句的情景下使用以防止sql注入。不得不拼接sql的情景包括 傳遞in內引數,動態決定表列,列名,還有就是like,為防止sql注入,也不得不拼接sql。按理來說這是一個非常好的儲存過程,但是,由於他本身的限制,會對查詢效能有很大的影響,下面我舉個例子。
使用northwind資料庫,
執行:
select * from orders where customerid = 'SAVEA';
執行:
select * from orders where customerid = 'CENTC';
這兩個語句的唯一不同就是客戶號不一樣,一個在訂單表內有31個重複值,一個沒有重複值。
然後我們們再來對比當這個語句放在了一個動態執行的sql語句內部的情況如何。
建立如下儲存過程:
 Code
Code
然後執行這個儲存過程:
exec testexecutesql 'SAVEA';
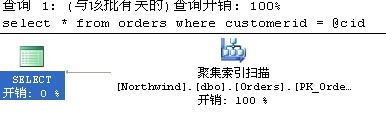
其執行計劃如下圖,是個聚集索引掃描:
(31 行受影響)
表 'Orders'。掃描計數 1,邏輯讀取 22 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
使用聚集索引掃描是個很明智的選擇,我們們可以來看看customerid上的非聚集索引的統計資訊,orders表共830行,其中客戶'SAVEA'就有31個訂單,所以優化器選擇使用聚集索引掃描而不是巢狀迴圈的book mark look up。
然後我們們再來執行一個:
exec testexecutesql 'CENTC';
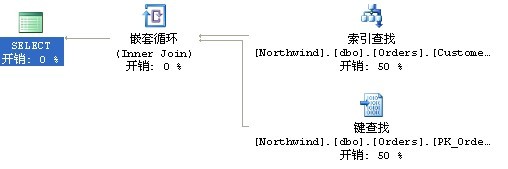
區別僅僅是傳入的customerid引數不一樣,再看看執行計劃,仍然是一樣,io也是一樣,就是返回的行數只有一行,按理來說,只返回一行,優化器應該會選擇使用非聚集索引,巢狀查詢資料,但是優化器卻沒有好好利用customerid上的統計資訊,仍然使用了聚集索引掃描,為什們?難道是索引上的統計資訊不及時嗎?不,在手動使用fullscan後的統計資訊仍然是一樣的查詢計劃,為什麼呢?
因為sp_executesql本身就是一個儲存過程,他執行動態語句的引數是不會被利用上的,所以當第一次編譯的時候產生的計劃,儲存過程testexecutesql 是無法嗅探到的,即無法去引用customerid上的統計資訊來做查詢計劃參考的,所以第一次編譯的查詢計劃是聚集索引掃描就是掃描,即使第二次執行的時候應該是查詢。
如何才能改變這一現狀呢?
可以使用提示符,recompile強制讓儲存過程在執行的時候重新編譯,來獲得最好的執行計劃,不過這也是有代價的,就是每次都需要編譯,不過相比那些被浪費掉的IO,對一些大表的效能低下的查詢計劃還是很值得的。於是,我們把儲存過程改寫如下:
都能獲得一個最優的查詢計劃。
sql server能夠支援語句級的重編譯,自動嗅探重編譯環境,閥值,使得絕大部分情況下能夠很好的利用編譯後的查詢計劃,提高資料庫整體效能。我在08年初寫過的一個ppt,是關資料庫於重編譯的,大家可以下載看看,http://img.cyzone.cn/temp/SQL SERVER 高階技巧系列之二:重編譯詳解.ppt
原文地址:http://www.cnblogs.com/perfectdesign/archive/2009/10/15/1584200.html
先說說什麼場景使用這個系統儲存過程吧,sp_executesql,是sql server動態執行一段可以帶有引數(內參,外參)的語句文字的系統儲存過程,傳入sp_executesql 的引數會以引數的形式傳遞,不會是以拼湊sql的形式傳遞,所以能夠在不得不拼接sql語句的情景下使用以防止sql注入。不得不拼接sql的情景包括 傳遞in內引數,動態決定表列,列名,還有就是like,為防止sql注入,也不得不拼接sql。按理來說這是一個非常好的儲存過程,但是,由於他本身的限制,會對查詢效能有很大的影響,下面我舉個例子。
使用northwind資料庫,
執行:
select * from orders where customerid = 'SAVEA';
執行:
select * from orders where customerid = 'CENTC';
這兩個語句的唯一不同就是客戶號不一樣,一個在訂單表內有31個重複值,一個沒有重複值。
然後我們們再來對比當這個語句放在了一個動態執行的sql語句內部的情況如何。
建立如下儲存過程:
然後執行這個儲存過程:
exec testexecutesql 'SAVEA';
其執行計劃如下圖,是個聚集索引掃描:
(31 行受影響)
表 'Orders'。掃描計數 1,邏輯讀取 22 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
使用聚集索引掃描是個很明智的選擇,我們們可以來看看customerid上的非聚集索引的統計資訊,orders表共830行,其中客戶'SAVEA'就有31個訂單,所以優化器選擇使用聚集索引掃描而不是巢狀迴圈的book mark look up。
然後我們們再來執行一個:
exec testexecutesql 'CENTC';
區別僅僅是傳入的customerid引數不一樣,再看看執行計劃,仍然是一樣,io也是一樣,就是返回的行數只有一行,按理來說,只返回一行,優化器應該會選擇使用非聚集索引,巢狀查詢資料,但是優化器卻沒有好好利用customerid上的統計資訊,仍然使用了聚集索引掃描,為什們?難道是索引上的統計資訊不及時嗎?不,在手動使用fullscan後的統計資訊仍然是一樣的查詢計劃,為什麼呢?
因為sp_executesql本身就是一個儲存過程,他執行動態語句的引數是不會被利用上的,所以當第一次編譯的時候產生的計劃,儲存過程testexecutesql 是無法嗅探到的,即無法去引用customerid上的統計資訊來做查詢計劃參考的,所以第一次編譯的查詢計劃是聚集索引掃描就是掃描,即使第二次執行的時候應該是查詢。
如何才能改變這一現狀呢?
可以使用提示符,recompile強制讓儲存過程在執行的時候重新編譯,來獲得最好的執行計劃,不過這也是有代價的,就是每次都需要編譯,不過相比那些被浪費掉的IO,對一些大表的效能低下的查詢計劃還是很值得的。於是,我們把儲存過程改寫如下:
<!--
Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->USE [Northwind]
GO
/****** 物件: StoredProcedure [dbo].[testexecutesql] 指令碼日期: 10/15/2009 20:09:45 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [dbo].[testexecutesql](@customerid nchar(5))
as
begin
exec sp_executesql N'select * from orders where customerid = @cid option(recompile) ',
N'@cid as nchar(5)',@cid = @customerid ;
end
這樣再次執行exec testexecutesql 'CENTC'; exec
testexecutesql 'SAVEA';Code highlighting produced by Actipro CodeHighlighter (freeware)
http://www.CodeHighlighter.com/
-->USE [Northwind]
GO
/****** 物件: StoredProcedure [dbo].[testexecutesql] 指令碼日期: 10/15/2009 20:09:45 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
ALTER proc [dbo].[testexecutesql](@customerid nchar(5))
as
begin
exec sp_executesql N'select * from orders where customerid = @cid option(recompile) ',
N'@cid as nchar(5)',@cid = @customerid ;
end
都能獲得一個最優的查詢計劃。
sql server能夠支援語句級的重編譯,自動嗅探重編譯環境,閥值,使得絕大部分情況下能夠很好的利用編譯後的查詢計劃,提高資料庫整體效能。我在08年初寫過的一個ppt,是關資料庫於重編譯的,大家可以下載看看,http://img.cyzone.cn/temp/SQL SERVER 高階技巧系列之二:重編譯詳解.ppt
原文地址:http://www.cnblogs.com/perfectdesign/archive/2009/10/15/1584200.html
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/16436858/viewspace-616723/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 技術人,請謹慎跳槽!
- 【Lambda、SteamAPI】謹慎使用流API
- AIX系統謹慎使用reboot命令AIboot
- oracle中要謹慎使用update交叉更新!Oracle
- java流操作要謹慎Java
- Linux需要謹慎使用的幾個命令Linux
- 為什麼要謹慎使用Linux find命令?Linux
- 大型專案開發:謹慎使用智慧指標指標
- JAVA基礎:謹慎使用Date和Time類(轉)Java
- 謹慎處理 Service Worker 的更新
- UNIX下VG遷移(謹慎) - 轉
- 升級oracle一定要謹慎Oracle
- AIX強制關機需要謹慎AI
- 高峰期謹慎編譯業務物件編譯物件
- 新程式語言選擇需謹慎
- 搞程式有風險 修bug需謹慎
- 安全機構建議奧巴馬政府謹慎使用開源軟體
- 微軟今日徹底放棄Windows XP 繼續使用需謹慎微軟Windows
- 【SQL*Plus】在SQL*Plus中謹慎使用Ctrl+S快捷鍵SQL
- 學生網貸請謹慎:網際網路金融信用風險隱患難除
- 第55條:謹慎地進行優化優化
- 【警鐘】謹慎刪除歸檔日誌
- DBA要謹慎關閉資料庫(轉)資料庫
- 蘋果AirPods耳機補買一隻599元 謹慎使用蘋果AI
- STL程式設計實踐一:謹慎使用下標運算子 (轉)程式設計
- API介面公司要考察的核心,讓你謹慎合作API
- 你的應用有漏洞嗎?使用第三方依賴需謹慎
- 直播平臺開發難嗎?自己開發須謹慎
- 網付智慧數字經營系統,代理需謹慎
- 外媒:Apple Watch不如傳統手錶 投資需謹慎APP
- 從Go、Swift出發:語言的選擇需謹慎GoSwift
- 休學創業需謹慎,一場遊戲一場夢?創業遊戲
- C#:謹慎 DateTime.Now 帶來的危險C#
- 入手需謹慎 二手iPhone編輯教你如何買iPhone
- 謹慎做資料庫技術的標準化(轉)資料庫
- 喜提JDK的BUG一枚!多執行緒的情況下請謹慎使用這個類的stream遍歷。JDK執行緒
- sp_executesqlSQL
- 在SQL Server中謹慎匯入匯出大容量資料SQLServer