一、圖表欺騙
圖表通常用來增強需要文字和資料的說服力,通過視覺化的圖表更容易讓受眾接受資訊。但圖表有時候會表現的不是資料的本質:
1.圖表拉伸
如果沒有特殊用途,通常圖表的長(橫軸)與高(縱軸)的比例為1:1到1:2之間,如果在這個範圍之外,資料現實的結果會過於異常。比如:
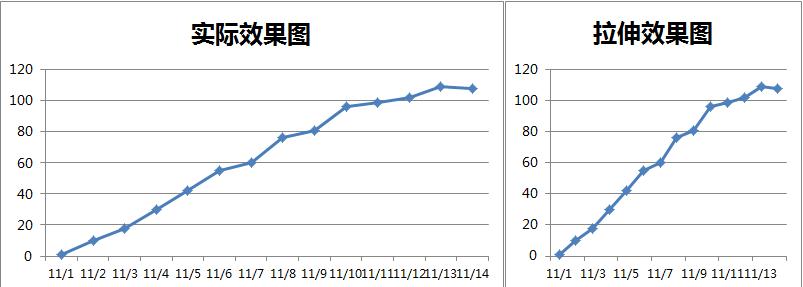
2.座標軸特殊處理
在很多場合下,如果兩列資料的取值範圍差異性過大,通常在顯示時會取對數,這時原來柱狀圖間的巨大差異會被故意縮小。通常,嚴謹的分析師在講解之前會進行告知。比如:
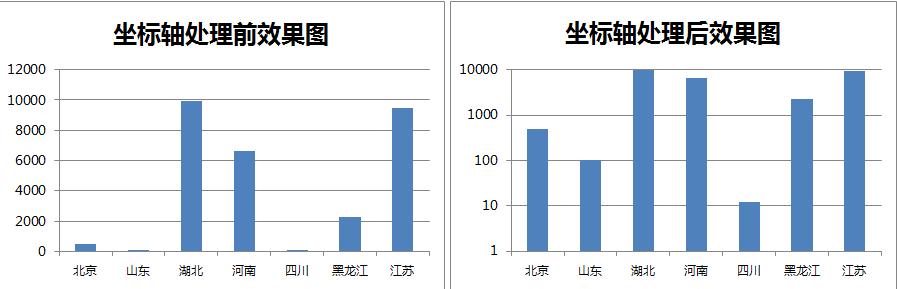
3.資料標準化
資料標準化也是一個讓資料落在相同區間內常用的方法,常用Z標準化或0-1標準化,如果不提前告知,可能會誤以為兩列資料取值異常接近,不符合實際業務場景,比如:
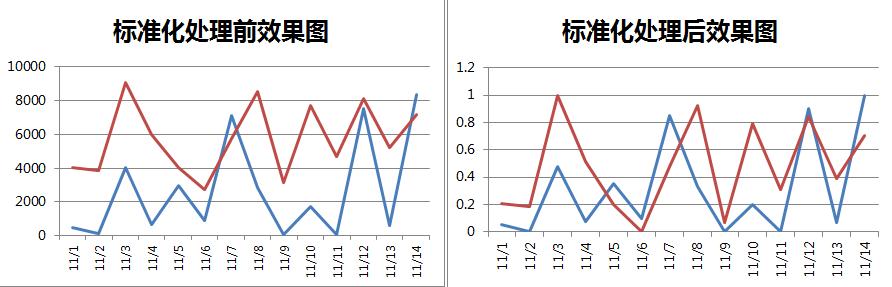
隱祕層次:★★☆☆☆
破解方法:詢問分析師的圖表各個含義,瞭解基本圖表檢視常識。
二、資料處理欺騙
資料處理中的欺騙方法通常包括抽樣方法欺騙、樣本量不同、異常值處理欺騙等。
1.抽樣方法欺騙
整體樣本的維度,粒度和取數邏輯相同的情況下,不用的樣本抽樣規則會使資料看來更符合或不符合“預期”。比如在做使用者挽回中,假如做的兩次活動的抽樣樣本分別是最近6個月未購物和最近6個月未購物但有登陸行為的使用者,不用做什麼測試,基本上可以確定後者的挽回效果更佳。要識破這個“騙局”只需要詢問資料取樣方法即可,需要細到具體的SQL邏輯。
2.樣本量不同
嚴格來說樣本量不同並不一定是故意欺騙,實踐中確實存在這種情況。(遇到這種情況可以用欠抽樣和過抽樣進行樣本平衡)樣本量不同分為兩種情況:
樣本量數量不同。比如要做效果差異對比,第一步是做效果比對,假如兩個資料樣本量分別是幾千和幾萬的級別,可比性就很小。尤其是對於樣本分佈不均的情況下,資料結果可信度低。
樣本主體不同。這是非常嚴重的資料引導錯誤,通常存在於為了達到某種結果而故意選擇對結果有利的樣本。比如做品類推廣,一部分使用者推廣渠道為廣告,另一部分是CPS可以遇見相同費用下後者的效果必然更好。
相同樣本不同的客觀環境。比如做站內使用者體驗分析,除了用隨機A/B測試以外,其他所有測試方法都沒有完全相同的客觀環境,因此即使選的是相同樣本,不同時間由於使用者,網站本身等影響,可信度較低。
3.異常值處理欺騙
通常面對樣本時需要做整體資料觀察,以確認樣本數量、均值、極值、方差、標準差以及資料範圍等。其中的極值很可能是異常值,此時如何處理異常值會直接影響資料結果。比如某天的銷售資料中,可能存在異常下單或行單,導致品類銷售額和轉化率異常高。如果忽視該情況,結論就是利好的,但實際並非如此。通常我們會把異常值拿出來,單獨做文字說明,甚至會說明沒有異常值下的真實情況。
隱祕層次:★★★☆☆
破解方法:在跟資料分析師溝通中,多詢問他們在資料選取規則,處理方法上的方法,如果他們吞吞吐吐或答不上來,那很有可能是故意為之。同時,業務人員也要增強基本資料意識,不能被這種不可見的底層錯誤欺騙。
三、 意識上的欺騙
這種欺騙是等級最高也是最嚴重的欺騙和錯誤,通常存在於資料分析師在做資料之前就已經下結論,分析過程中只選取有利於證明其論斷的方法和材料,因此會在從資料選擇,處理,資料表現等各個方面進行事實上的扭曲,是嚴重的誤導行為!資料分析師需要有中立的立場,客觀的態度,任何有立場的分析師的結論都會失之偏頗。
隱祕層次:★★★★★
破解方法:在跟該分析師溝通中,檢視其是否有明顯立場或態度,如果有,那麼該警惕;然後通過上面的方法逐一驗證。
綜上,當你遇到以下資料情形,就需要警惕資料的真實性了:
資料包告從來不註明資料出處,資料時間,資料取樣規則,資料取得方法等。現在市場上很多報告都屬於這一類。
資料包告在做市場調查中說明全樣本共1000,其中北京可能只有100,基於這100個樣本出來的結論顯然不可信。事實上很多市場研究報告就是這樣出來的。
資料包告中存在明顯的觀點,對於事物的分析只講其優勢或劣勢,不全面也不客觀。現在很多網際網路分析師就是屬於這類,大家注意辨別。
評論(1)