這是Andrew Ng深度學習專項課程第三門課《構建機器學習專案》的第二節筆記。
1. Carrying out error analysis
對已經建立的機器學習模型進行錯誤分析(error analysis)十分必要,而且有針對性地、正確地進行error analysis更加重要。
舉個例子,貓類識別問題,已經建立的模型的錯誤率為10%。為了提高正確率,我們發現該模型會將一些狗類圖片錯誤分類成貓。一種常規解決辦法是擴大狗類樣本,增強模型對夠類(負樣本)的訓練。但是,這一過程可能會花費幾個月的時間,耗費這麼大的時間成本到底是否值得呢?也就是說擴大狗類樣本,重新訓練模型,對提高模型準確率到底有多大作用?這時候我們就需要進行error analysis,幫助我們做出判斷。
方法很簡單,我們可以從分類錯誤的樣本中統計出狗類的樣本數量。根據狗類樣本所佔的比重,判斷這一問題的重要性。假如狗類樣本所佔比重僅為5%,即時我們花費幾個月的時間擴大狗類樣本,提升模型對其識別率,改進後的模型錯誤率最多隻會降低到9.5%。相比之前的10%,並沒有顯著改善。我們把這種效能限制稱為ceiling on performance。相反,假如錯誤樣本中狗類所佔比重為50%,那麼改進後的模型錯誤率有望降低到5%,效能改善很大。因此,值得去花費更多的時間擴大狗類樣本。
這種error analysis雖然簡單,但是能夠避免花費大量的時間精力去做一些對提高模型效能收效甚微的工作,讓我們專注解決影響模型正確率的主要問題,十分必要。
這種error analysis可以同時評估多個影響模型效能的因素,透過各自在錯誤樣本中所佔的比例來判斷其重要性。例如,貓類識別模型中,可能有以下幾個影響因素:
- Fix pictures of dogs being recognized as cats<p>
-
Fix great cats(lions, panthers, etc…) being misrecognized
-
Improve performance on blurry images
通常來說,比例越大,影響越大,越應該花費時間和精力著重解決這一問題。這種error analysis讓我們改進模型更加有針對性,從而提高效率。
2. Cleaning up incorrectly labeled data
監督式學習中,訓練樣本有時候會出現輸出y標註錯誤的情況,即incorrectly labeled examples。如果這些label標錯的情況是隨機性的(random errors),DL演算法對其包容性是比較強的,即健壯性好,一般可以直接忽略,無需修復。然而,如果是系統錯誤(systematic errors),這將對DL演算法造成影響,降低模型效能。
剛才說的是訓練樣本中出現incorrectly labeled data,如果是dev/test sets中出現incorrectly labeled data,該怎麼辦呢?
方法很簡單,利用上節內容介紹的error analysis,統計dev sets中所有分類錯誤的樣本中incorrectly labeled data所佔的比例。根據該比例的大小,決定是否需要修正所有incorrectly labeled data,還是可以忽略。舉例說明,若:
- Overall dev set error: 10%<p>
-
Errors due incorrect labels: 0.6%
-
Errors due to other causes: 9.4%
上面資料表明Errors due incorrect labels所佔的比例僅為0.6%,佔dev set error的6%,而其它型別錯誤佔dev set error的94%。因此,這種情況下,可以忽略incorrectly labeled data。
如果最佳化DL演算法後,出現下面這種情況:
- Overall dev set error: 2%<p>
-
Errors due incorrect labels: 0.6%
-
Errors due to other causes: 1.4%
上面資料表明Errors due incorrect labels所佔的比例依然為0.6%,但是卻佔dev set error的30%,而其它型別錯誤佔dev set error的70%。因此,這種情況下,incorrectly labeled data不可忽略,需要手動修正。
我們知道,dev set的主要作用是在不同演算法之間進行比較,選擇錯誤率最小的演算法模型。但是,如果有incorrectly labeled data的存在,當不同演算法錯誤率比較接近的時候,我們無法僅僅根據Overall dev set error準確指出哪個演算法模型更好,必須修正incorrectly labeled data。
關於修正incorrect dev/test set data,有幾條建議:
- Apply same process to your dev and test sets to make sure they continue to come from the same distribution<p>
-
Consider examining examples your algorithm got right as well as ones it got wrong
-
Train and dev/test data may now come from slightly different distributions
3. Build your first system quickly then iterate
對於如何構建一個機器學習應用模型,Andrew給出的建議是先快速構建第一個簡單模型,然後再反覆迭代最佳化。
- Set up dev/test set and metric<p>
-
Build initial system quickly
-
Use Bias/Variance analysis & Error analysis to prioritize next steps
4. Training and testing on different distribution
當train set與dev/test set不來自同一個分佈的時候,我們應該如何解決這一問題,構建準確的機器學習模型呢?
以貓類識別為例,train set來自於網路下載(webpages),圖片比較清晰;dev/test set來自使用者手機拍攝(mobile app),圖片比較模糊。假如train set的大小為200000,而dev/test set的大小為10000,顯然train set要遠遠大於dev/test set。

雖然dev/test set質量不高,但是模型最終主要應用在對這些模糊的照片的處理上。面對train set與dev/test set分佈不同的情況,有兩種解決方法。
第一種方法是將train set和dev/test set完全混合,然後在隨機選擇一部分作為train set,另一部分作為dev/test set。例如,混合210000例樣本,然後隨機選擇205000例樣本作為train set,2500例作為dev set,2500例作為test set。這種做法的優點是實現train set和dev/test set分佈一致,缺點是dev/test set中webpages圖片所佔的比重比mobile app圖片大得多。例如dev set包含2500例樣本,大約有2381例來自webpages,只有119例來自mobile app。這樣,dev set的演算法模型對比驗證,仍然主要由webpages決定,實際應用的mobile app圖片所佔比重很小,達不到驗證效果。因此,這種方法並不是很好。
第二種方法是將原來的train set和一部分dev/test set組合當成train set,剩下的dev/test set分別作為dev set和test set。例如,200000例webpages圖片和5000例mobile app圖片組合成train set,剩下的2500例mobile app圖片作為dev set,2500例mobile app圖片作為test set。其關鍵在於dev/test set全部來自於mobile app。這樣保證了驗證集最接近實際應用場合。這種方法較為常用,而且效能表現比較好。
5. Bias and Variance with mismatched data distributions
我們之前介紹過,根據human-level error、training error和dev error的相對值可以判定是否出現了bias或者variance。但是,需要注意的一點是,如果train set和dev/test set來源於不同分佈,則無法直接根據相對值大小來判斷。例如某個模型human-level error為0%,training error為1%,dev error為10%。根據我們之前的理解,顯然該模型出現了variance。但是,training error與dev error之間的差值9%可能來自演算法本身(variance),也可能來自於樣本分佈不同。比如dev set都是很模糊的圖片樣本,本身就難以識別,跟演算法模型關係不大。因此不能簡單認為出現了variance。
在可能伴有train set與dev/test set分佈不一致的情況下,定位是否出現variance的方法是設定train-dev set。Andrew給train-dev set的定義是:“Same distribution as training set, but not used for training.”也就是說,從原來的train set中分割出一部分作為train-dev set,train-dev set不作為訓練模型使用,而是與dev set一樣用於驗證。
這樣,我們就有training error、training-dev error和dev error三種error。其中,training error與training-dev error的差值反映了variance;training-dev error與dev error的差值反映了data mismatch problem,即樣本分佈不一致。
舉例說明,如果training error為1%,training-dev error為9%,dev error為10%,則variance問題比較突出。如果training error為1%,training-dev error為1.5%,dev error為10%,則data mismatch problem比較突出。透過引入train-dev set,能夠比較準確地定位出現了variance還是data mismatch。
總結一下human-level error、training error、training-dev error、dev error以及test error之間的差值關係和反映的問題:

一般情況下,human-level error、training error、training-dev error、dev error以及test error的數值是遞增的,但是也會出現dev error和test error下降的情況。這主要可能是因為訓練樣本比驗證/測試樣本更加複雜,難以訓練。
6. Addressing data mismatch
關於如何解決train set與dev/test set樣本分佈不一致的問題,有兩條建議:
- Carry out manual error analysis to try to understand difference between training dev/test sets<p>
-
Make training data more similar; or collect more data similar to dev/test sets
為了讓train set與dev/test set類似,我們可以使用人工資料合成的方法(artificial data synthesis)。例如說話人識別問題,實際應用場合(dev/test set)是包含背景噪聲的,而訓練樣本train set很可能沒有背景噪聲。為了讓train set與dev/test set分佈一致,我們可以在train set上人工新增背景噪聲,合成類似實際場景的聲音。這樣會讓模型訓練的效果更準確。但是,需要注意的是,我們不能給每段語音都增加同一段背景噪聲,這樣會出現對背景噪音的過擬合,效果不佳。這就是人工資料合成需要注意的地方。
7. Transfer learning
深度學習非常強大的一個功能之一就是有時候你可以將已經訓練好的模型的一部分知識(網路結構)直接應用到另一個類似模型中去。比如我們已經訓練好一個貓類識別的神經網路模型,那麼我們可以直接把該模型中的一部分網路結構應用到使用X光片預測疾病的模型中去。這種學習方法被稱為遷移學習(Transfer Learning)。
如果我們已經有一個訓練好的神經網路,用來做影像識別。現在,我們想要構建另外一個透過X光片進行診斷的模型。遷移學習的做法是無需重新構建新的模型,而是利用之前的神經網路模型,只改變樣本輸入、輸出以及輸出層的權重係數W^{[L]},\ b^{[L]}。也就是說對新的樣本(X,Y),重新訓練輸出層權重係數W^{[L]},\ b^{[L]},而其它層所有的權重係數W^{[l]},\ b^{[l]}保持不變。
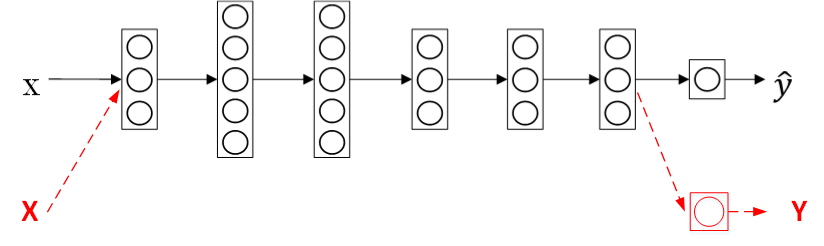
遷移學習,重新訓練權重係數,如果需要構建新模型的樣本數量較少,那麼可以像剛才所說的,只訓練輸出層的權重係數W^{[L]},\ b^{[L]},保持其它層所有的權重係數W^{[l]},\ b^{[l]}不變。這種做法相對來說比較簡單。如果樣本數量足夠多,那麼也可以只保留網路結構,重新訓練所有層的權重係數。這種做法使得模型更加精確,因為畢竟樣本對模型的影響最大。選擇哪種方法通常由資料量決定。
順便提一下,如果重新訓練所有權重係數,初始W^{[l]},\ b^{[l]}由之前的模型訓練得到,這一過程稱為pre-training。之後,不斷除錯、最佳化W^{[l]},\ b^{[l]}的過程稱為fine-tuning。pre-training和fine-tuning分別對應上圖中的黑色箭頭和紅色箭頭。
遷移學習之所以能這麼做的原因是,神經網路淺層部分能夠檢測出許多圖片固有特徵,例如影像邊緣、曲線等。使用之前訓練好的神經網路部分結果有助於我們更快更準確地提取X光片特徵。二者處理的都是圖片,而圖片處理是有相同的地方,第一個訓練好的神經網路已經幫我們實現如何提取圖片有用特徵了。 因此,即便是即將訓練的第二個神經網路樣本數目少,仍然可以根據第一個神經網路結構和權重係數得到健壯性好的模型。
遷移學習可以保留原神經網路的一部分,再新增新的網路層。具體問題,具體分析,可以去掉輸出層後再增加額外一些神經層。
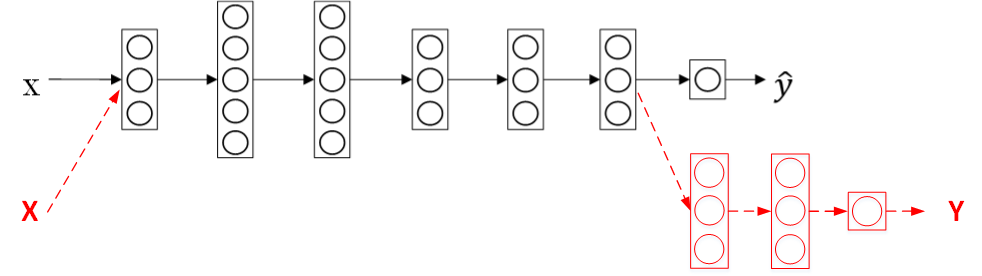
總體來說,遷移學習的應用場合主要包括三點:
- Task A and B have the same input x.<p>
-
You have a lot more data for Task A than Task B.
-
Low level features from A could be helpful for learning B.
8. Multi-task learning
顧名思義,多工學習(multi-task learning)就是構建神經網路同時執行多個任務。這跟二元分類或者多元分類都不同,多工學習類似將多個神經網路融合在一起,用一個網路模型來實現多種分類效果。如果有C個,那麼輸出y的維度是(C,1)。例如汽車自動駕駛中,需要實現的多工為行人、車輛、交通標誌和訊號燈。如果檢測出汽車和交通標誌,則y為:
y= \left[ \begin{matrix} 0\ 1\ 1\ 0 \end{matrix} \right]
多工學習模型的cost function為:
\frac1m\sum_{i=1}^m\sum_{j=1}^cL(\hat y_j^{(i)},y_j^{(i)})
其中,j表示任務下標,總有c個任務。對應的loss function為:
L(\hat y_j^{(i)},y_j^{(i)})=-y_j^{(i)}log\ \hat y_j^{(i)}-(1-y_j^{(i)})log\ (1-\hat y_j^{(i)})
值得一提的是,Multi-task learning與Softmax regression的區別在於Softmax regression是single label的,即輸出向量y只有一個元素為1;而Multi-task learning是multiple labels的,即輸出向量y可以有多個元素為1。
多工學習是使用單個神經網路模型來實現多個任務。實際上,也可以分別構建多個神經網路來實現。但是,如果各個任務之間是相似問題(例如都是圖片類別檢測),則可以使用多工學習模型。另外,多工學習中,可能存在訓練樣本Y某些label空白的情況,這並不影響多工模型的訓練。
總體來說,多工學習的應用場合主要包括三點:
- Training on a set of tasks that could benefit from having shared lower-level features.<p>
-
Usually: Amount of data you have for each task is quite similar.
-
Can train a big enough neural network to do well on all the tasks.
順便提一下,遷移學習和多工學習在實際應用中,遷移學習使用得更多一些。
9. What is end-to-end deep learning
端到端(end-to-end)深度學習就是將所有不同階段的資料處理系統或學習系統模組組合在一起,用一個單一的神經網路模型來實現所有的功能。它將所有模組混合在一起,只關心輸入和輸出。
以語音識別為例,傳統的演算法流程和end-to-end模型的區別如下:
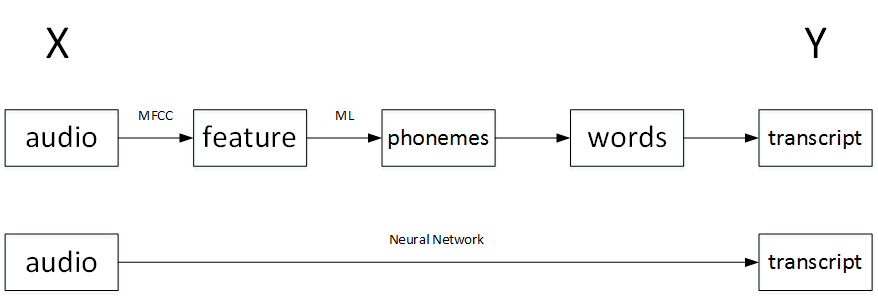
如果訓練樣本足夠大,神經網路模型足夠複雜,那麼end-to-end模型效能比傳統機器學習分塊模型更好。實際上,end-to-end讓神經網路模型內部去自我訓練模型特徵,自我調節,增加了模型整體契合度。
10. Whether to use end-to-end deep learning
end-to-end深度學習有優點也有缺點。
優點:
- Let the data speak<p>
-
Less hand-designing of components needed
缺點:
- May need large amount of data<p>
-
Excludes potentially useful hand-designed
更多AI資源請關注公眾號:AI有道(ID:redstonewill)
