一個例子
高斯混合模型(Gaussian Mixed Model)指的是多個高斯分佈函式的線性組合,理論上GMM可以擬合出任意型別的分佈,通常用於解決同一集合下的資料包含多個不同的分佈的情況(或者是同一類分佈但引數不一樣,或者是不同型別的分佈,比如正態分佈和伯努利分佈)。
如圖1,圖中的點在我們看來明顯分成兩個聚類。這兩個聚類中的點分別通過兩個不同的正態分佈隨機生成而來。但是如果沒有GMM,那麼只能用一個的二維高斯分佈來描述圖1中的資料。圖1中的橢圓即為二倍標準差的正態分佈橢圓。這顯然不太合理,畢竟肉眼一看就覺得應該把它們分成兩類。
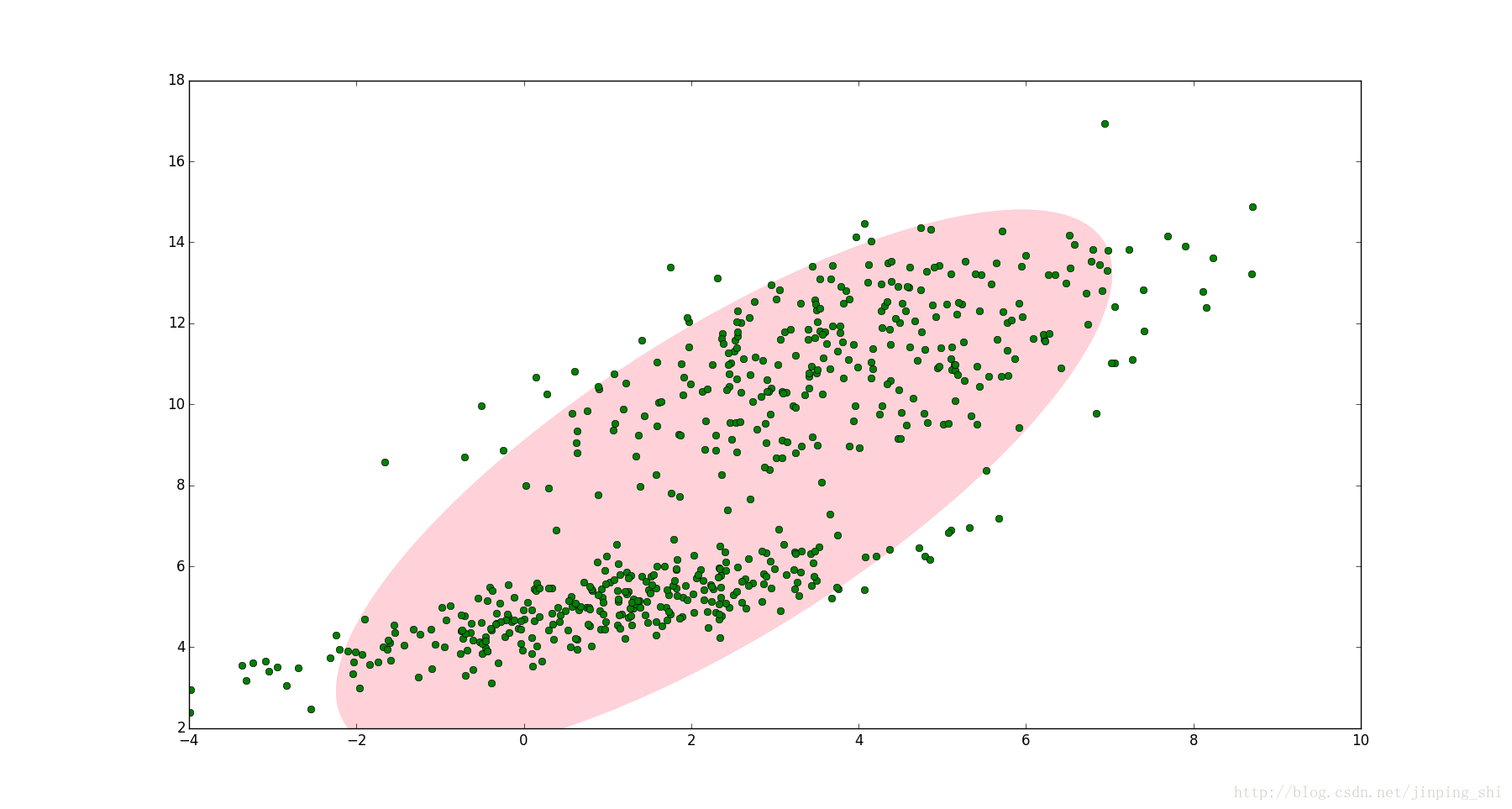
圖1
這時候就可以使用GMM了!如圖2,資料在平面上的空間分佈和圖1一樣,這時使用兩個二維高斯分佈來描述圖2中的資料,分別記為N(μ1,Σ1)和N(μ2,Σ2). 圖中的兩個橢圓分別是這兩個高斯分佈的二倍標準差橢圓。可以看到使用兩個二維高斯分佈來描述圖中的資料顯然更合理。實際上圖中的兩個聚類的中的點是通過兩個不同的正態分佈隨機生成而來。如果將兩個二維高斯分佈N(μ1,Σ1)和N(μ2,Σ2)合成一個二維的分佈,那麼就可以用合成後的分佈來描述圖2中的所有點。最直觀的方法就是對這兩個二維高斯分佈做線性組合,用線性組合後的分佈來描述整個集合中的資料。這就是高斯混合模型(GMM)。
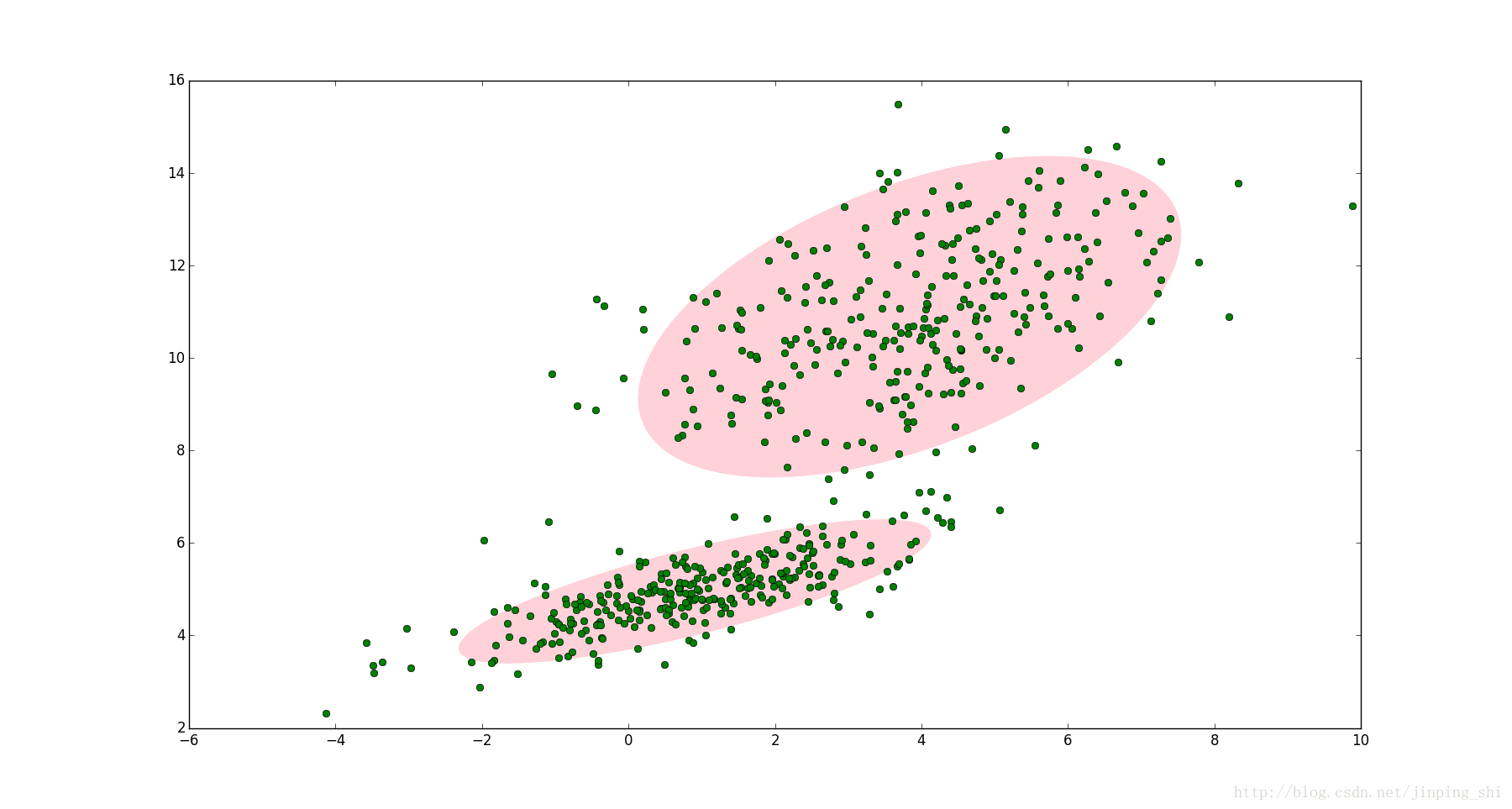
圖2
高斯混合模型(GMM)
設有隨機變數X,則混合高斯模型可以用下式表示:
p(x)=k=1∑KπkN(x∣μk,Σk)
其中N(x∣μk,Σk)稱為混合模型中的第k個分量(component)。如前面圖2中的例子,有兩個聚類,可以用兩個二維高斯分佈來表示,那麼分量數K=2. πk是混合係數(mixture coefficient),且滿足:
k=1∑Kπk=1
0≤πk≤1
實際上,可以認為πk就是每個分量N(x∣μk,Σk)的權重。
GMM的應用
GMM常用於聚類。如果要從 GMM 的分佈中隨機地取一個點的話,實際上可以分為兩步:首先隨機地在這 K 個 Component 之中選一個,每個 Component 被選中的概率實際上就是它的係數πk ,選中 Component 之後,再單獨地考慮從這個 Component 的分佈中選取一個點就可以了──這裡已經回到了普通的 Gaussian 分佈,轉化為已知的問題。
將GMM用於聚類時,假設資料服從混合高斯分佈(Mixture Gaussian Distribution),那麼只要根據資料推出 GMM 的概率分佈來就可以了;然後 GMM 的 K 個 Component 實際上對應K個 cluster 。根據資料來推算概率密度通常被稱作 density estimation 。特別地,當我已知(或假定)概率密度函式的形式,而要估計其中的引數的過程被稱作『引數估計』。
例如圖2的例子,很明顯有兩個聚類,可以定義K=2. 那麼對應的GMM形式如下:
p(x)=π1N(x∣μ1,Σ1)+π2N(x∣μ2,Σ2)
上式中未知的引數有六個:(π1,μ1,Σ1;π2,μ2,Σ2). 之前提到GMM聚類時分為兩步,第一步是隨機地在這K個分量中選一個,每個分量被選中的概率即為混合係數πk. 可以設定π1=π2=0.5,表示每個分量被選中的概率是0.5,即從中抽出一個點,這個點屬於第一類的概率和第二類的概率各佔一半。但實際應用中事先指定πk的值是很笨的做法,當問題一般化後,會出現一個問題:當從圖2中的集合隨機選取一個點,怎麼知道這個點是來自N(x∣μ1,Σ1)還是N(x∣μ2,Σ2)呢?換言之怎麼根據資料自動確定π1和π2的值?這就是GMM引數估計的問題。要解決這個問題,可以使用EM演算法。通過EM演算法,我們可以迭代計算出GMM中的引數:(πk,xk,Σk).
GMM引數估計過程
GMM的貝葉斯理解
在介紹GMM引數估計之前,先改寫GMM的形式,改寫之後的GMM模型可以方便地使用EM估計引數。GMM的原始形式如下:
p(x)=k=1∑KπkN(x∣μk,Σk)(1)
前面提到πk可以看成是第k類被選中的概率。我們引入一個新的K維隨機變數z. zk(1≤k≤K)只能取0或1兩個值;zk=1表示第k類被選中的概率,即:p(zk=1)=πk;如果zk=0表示第k類沒有被選中的概率。更數學化一點,zk要滿足以下兩個條件:
zk∈{0,1}
K∑zk=1
例如圖2中的例子,有兩類,則z的維數是2. 如果從第一類中取出一個點,則z=(1,0);,如果從第二類中取出一個點,則z=(0,1).
zk=1的概率就是πk,假設zk之間是獨立同分布的(iid),我們可以寫出z的聯合概率分佈形式,就是連乘:
p(z)=p(z1)p(z2)...p(zK)=k=1∏Kπkzk(2)
因為zk只能取0或1,且z中只能有一個zk為1而其它zj(j̸=k)全為0,所以上式是成立的。
圖2中的資料可以分為兩類,顯然,每一類中的資料都是服從正態分佈的。這個敘述可以用條件概率來表示:
p(x∣zk=1)=N(x∣μk,Σk)
即第k類中的資料服從正態分佈。進而上式有可以寫成如下形式:
p(x∣z)=k=1∏KN(x∣μk,Σk)zk(3)
上面分別給出了p(z)和p(x∣z)的形式,根據條件概率公式,可以求出p(x)的形式:
p(x)=z∑p(z)p(x∣z)=z∑(k=1∏KπkzkN(x∣μk,Σk)zk)=k=1∑KπkN(x∣μk,Σk)(4)
(注:上式第二個等號,對z求和,實際上就是∑k=1K。又因為對某個k,只要i̸=k,則有zi=0,所以zk=0的項為1,可省略,最終得到第三個等號)
可以看到GMM模型的(1)式與(4)式有一樣的形式,且(4)式中引入了一個新的變數z,通常稱為隱含變數(latent variable)。對於圖2中的資料,『隱含』的意義是:我們知道資料可以分成兩類,但是隨機抽取一個資料點,我們不知道這個資料點屬於第一類還是第二類,它的歸屬我們觀察不到,因此引入一個隱含變數z來描述這個現象。
注意到在貝葉斯的思想下,p(z)是先驗概率, p(x∣z)是似然概率,很自然我們會想到求出後驗概率p(z∣x):
γ(zk)=p(zk=1∣x)=p(x,zk=1)p(zk=1)p(x∣zk=1)=∑j=1Kp(zj=1)p(x∣zj=1)p(zk=1)p(x∣zk=1)=∑j=1KπjN(x∣μj,Σj)πkN(x∣μk,Σk)(5)
(第2行,貝葉斯定理。關於這一行的分母,很多人有疑問,應該是p(x,zk=1)還是p(x),按照正常寫法,應該是p(x)。但是為了強調zk的取值,有的書會寫成p(x,zk=1),比如李航的《統計學習方法》,這裡就約定p(x)與p(x,zk=1)是等同的)
(第3行,全概率公式)
(最後一個等號,結合(3)(4))
上式中我們定義符號γ(zk)來表示來表示第k個分量的後驗概率。在貝葉斯的觀點下,πk可視為zk=1的先驗概率。
上述內容改寫了GMM的形式,並引入了隱含變數z和已知x後的的後驗概率γ(zk),這樣做是為了方便使用EM演算法來估計GMM的引數。
EM演算法估計GMM引數
EM演算法(Expectation-Maximization algorithm)分兩步,第一步先求出要估計引數的粗略值,第二步使用第一步的值最大化似然函式。因此要先求出GMM的似然函式。
假設x={x1,x2,...,xN},對於圖2,x是圖中所有點(每個點有在二維平面上有兩個座標,是二維向量,因此x1,x2等都用粗體表示)。GMM的概率模型如(1)式所示。GMM模型中有三個引數需要估計,分別是π,μ和Σ. 將(1)式稍微改寫一下:
p(x∣π,μ,Σ)=k=1∑KπkN(x∣μk,Σk)(6)
為了估計這三個引數,需要分別求解出這三個引數的最大似然函式。先求解μk的最大似然函式。樣本符合iid,(6)式所有樣本連乘得到最大似然函式,對(6)式取對數得到對數似然函式,然後再對μk求導並令導數為0即得到最大似然函式。
0=−n=1∑N∑jπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)Σk(xn−μk)(7)
注意到上式中分數的一項的形式正好是(5)式後驗概率的形式。兩邊同乘Σk−1,重新整理可以得到:
μk=Nk1n=1∑Nγ(znk)xn(8)
其中:
Nk=n=1∑Nγ(znk)(9)
(8)式和(9)式中,N表示點的數量。γ(znk)表示點n(xn)屬於聚類k的後驗概率。則Nk可以表示屬於第k個聚類的點的數量。那麼μk表示所有點的加權平均,每個點的權值是∑n=1Nγ(znk),跟第k個聚類有關。
同理求Σk的最大似然函式,可以得到:
Σk=Nk1n=1∑Nγ(znk)(xn−μk)(xn−μk)T(10)
最後剩下πk的最大似然函式。注意到πk有限制條件∑k=1Kπk=1,因此我們需要加入拉格朗日運算元:
lnp(x∣π,μ,Σ)+λ(k=1∑Kπk−1)
求上式關於πk的最大似然函式,得到:
0=n=1∑N∑jπjN(xn∣μj,Σj)N(xn∣μk,Σk)+λ(11)
上式兩邊同乘πk,我們可以做如下推導:
0=n=1∑N∑jπjN(xn∣μj,Σj)πkN(xn∣μk,Σk)+λπk(11.1)
結合公式(5)、(9),可以將上式改寫成:
0=Nk+λπk(11.2)
注意到∑k=1Kπk=1,上式兩邊同時對k求和。此外Nk表示屬於第個聚類的點的數量(公式(9))。對Nk,從k=1到k=K求和後,就是所有點的數量N:
0=k=1∑KNk+λk=1∑Kπk(11.3)
0=N+λ(11.4)
從而可得到λ=−N,帶入(11.2),進而可以得到πk更簡潔的表示式:
πk=NNk(12)
EM演算法估計GMM引數即最大化(8),(10)和(12)。需要用到(5),(8),(10)和(12)四個公式。我們先指定π,μ和Σ的初始值,帶入(5)中計算出γ(znk),然後再將γ(znk)帶入(8),(10)和(12),求得πk,μk和Σk;接著用求得的πk,μk和Σk再帶入(5)得到新的γ(znk),再將更新後的γ(znk)帶入(8),(10)和(12),如此往復,直到演算法收斂。
EM演算法
- 定義分量數目K,對每個分量k設定πk,μk和Σk的初始值,然後計算(6)式的對數似然函式。
- E step
根據當前的πk、μk、Σk計算後驗概率γ(znk)
γ(znk)=∑j=1KπjN(xn∣μj,Σj)πkN(xn∣μn,Σn)
- M step
根據E step中計算的γ(znk)再計算新的πk、μk、Σk
μknewΣknewπknew=Nk1n=1∑Nγ(znk)xn=Nk1n=1∑Nγ(znk)(xn−μknew)(xn−μknew)T=NNk
其中:
Nk=n=1∑Nγ(znk)
- 計算(6)式的對數似然函式
lnp(x∣π,μ,Σ)=n=1∑Nln{k=1∑KπkN(xk∣μk,Σk)}
- 檢查引數是否收斂或對數似然函式是否收斂,若不收斂,則返回第2步。
Reference
- 漫談 Clustering (3): Gaussian Mixture Model
- Draw Gaussian distribution ellipse
- Pang-Ning Tan 等, 資料探勘導論(英文版), 機械工業出版社, 2010
- Christopher M. Bishop etc., Pattern Recognition and Machine Learning, Springer, 2006
- 李航, 統計學習方法, 清華大學出版社, 2012