[python爬蟲] Selenium爬取新浪微博內容及使用者資訊
在進行自然語言處理、文字分類聚類、推薦系統、輿情分析等研究中,通常需要使用新浪微博的資料作為語料,這篇文章主要介紹如果使用Python和Selenium爬取自定義新浪微博語料。因為網上完整的語料比較少,而使用Selenium方法有點簡單、速度也比較慢,但方法可行,同時能夠輸入驗證碼。希望文章對你有所幫助~
原始碼下載地址:http://download.csdn.net/detail/eastmount/9501273
爬取結果
首先可以爬取使用者ID、使用者名稱、微博數、粉絲數、關注數及微博資訊。其中微博資訊包括轉發或原創、點贊數、轉發數、評論數、釋出時間、微博內容等等。如下圖所示:
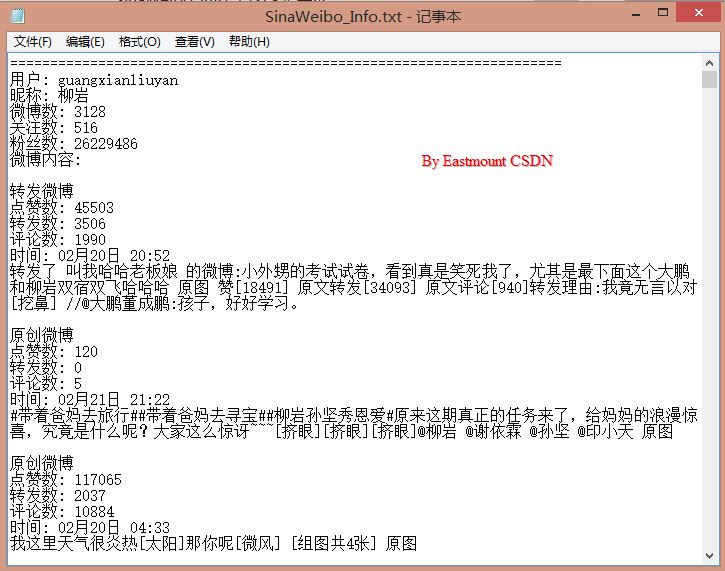
同時也可以爬取微博的眾多使用者的詳細資訊,包括基本資訊、關注人ID列表和粉絲ID列表等等。如下圖所示:

原始碼下載地址:http://download.csdn.net/detail/eastmount/9501273
爬取結果
首先可以爬取使用者ID、使用者名稱、微博數、粉絲數、關注數及微博資訊。其中微博資訊包括轉發或原創、點贊數、轉發數、評論數、釋出時間、微博內容等等。如下圖所示:
同時也可以爬取微博的眾多使用者的詳細資訊,包括基本資訊、關注人ID列表和粉絲ID列表等等。如下圖所示:
登入入口
新浪微博登入常用介面:http://login.sina.com.cn/
對應主介面:http://weibo.com/
但是個人建議採用手機端微博入口:http://login.weibo.cn/login/
對應主介面:http://weibo.cn/
其原因是手機端資料相對更輕量型,同時基本資料都齊全,可能缺少些個人基本資訊,如"個人資料完成度"、"個人等級"等,同時粉絲ID和關注ID只能顯示20頁,但完全可以作為語料進行大部分的驗證。
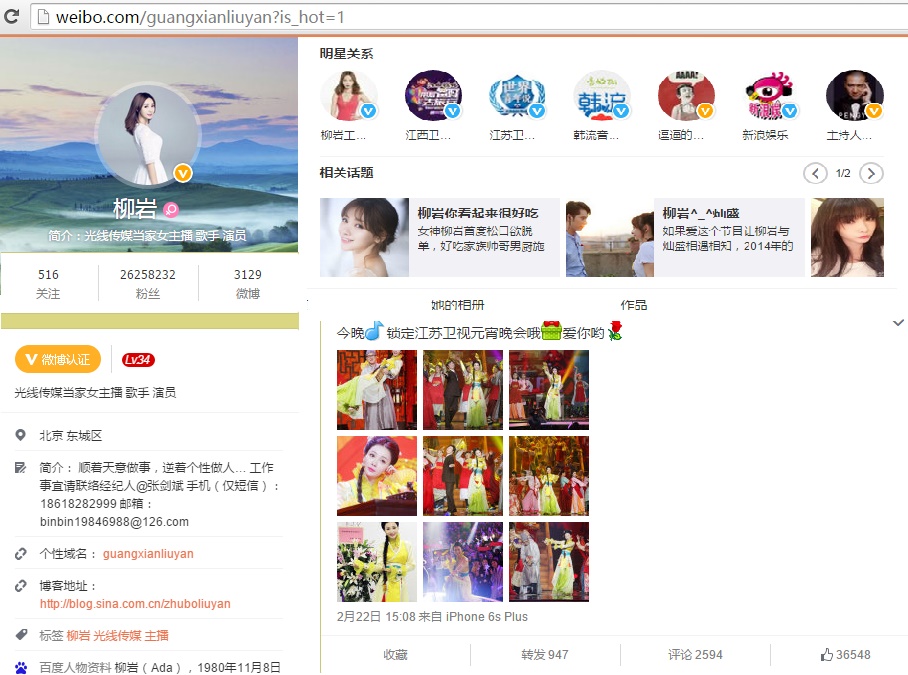
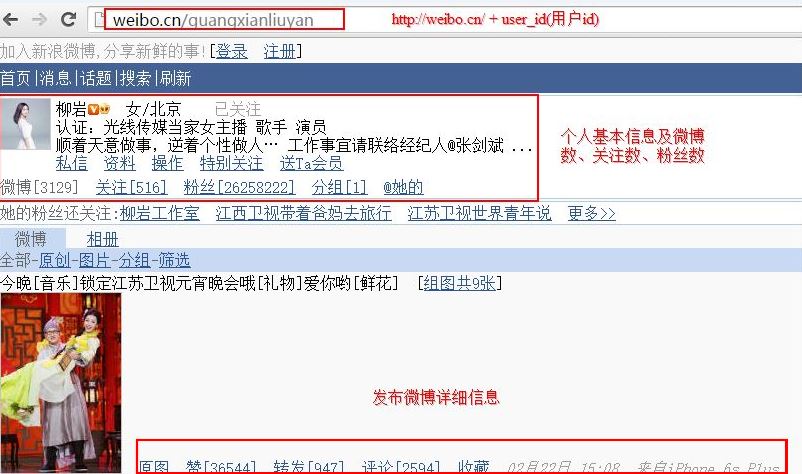
通過比較下面兩張圖,分別是PC端和手機端,可以發現內容基本一致:
完整原始碼
下面程式碼主要分為三部分:
1.LoginWeibo(username, password) 登入微博
2.VisitPersonPage(user_id) 訪問跟人網站,獲取個人資訊
3.獲取微博內容,同時http://weibo.cn/guangxianliuyan?filter=0&page=1實現翻頁
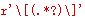 ) 如:r'\[(.*?)\]'就會自動換行 (⊙o⊙)
) 如:r'\[(.*?)\]'就會自動換行 (⊙o⊙)
登入頁面
首先,為什麼需要登入呢?
因為新浪微博很多資料如果不登入是不能獲取或訪問的,如微博的粉絲列表、個人詳細資訊、微博下一頁等等,當你點選這些超連結時就會自動跳轉到登入介面,這是開發者對其進行的保護措施。同時,各個公司都會提供API介面讓開發者進行操作,但此處我是使用Selenium模擬瀏覽器操作進行爬取的。
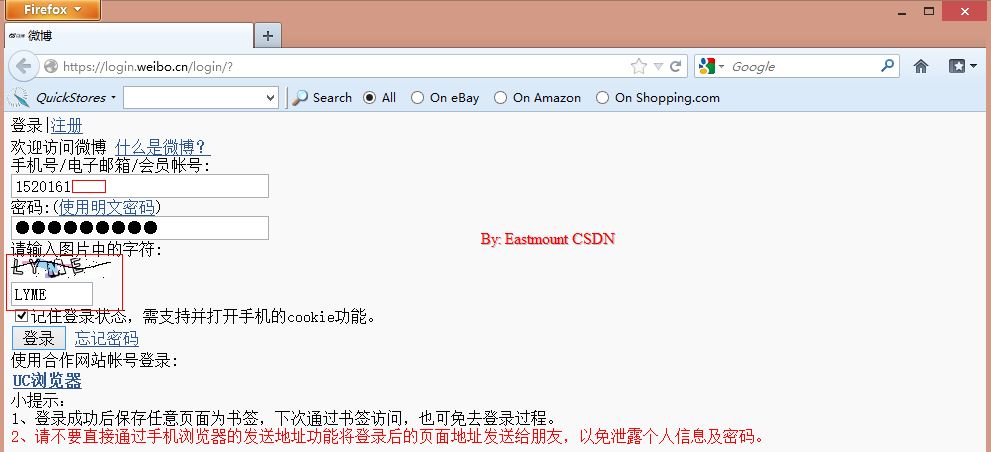
其中登入如上圖所示,函式LoginWeibo(username, password) 實現,它會自動開啟瀏覽器並輸入使用者名稱和密碼。在登入過程中由於會涉及到驗證碼,所以我採用暫停20秒,當使用者手動輸入驗證碼並且時間到後會自動點選按鈕登入。核心程式碼如下:
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #使用者名稱
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密碼
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #點選登陸
如果你登陸過程中Python報錯:
WebDriverException: Message: "Can't load the profile. Profile Dir:
猜測是Firefox版本問題,升級後出現的該問題,建議下載相對較老的版本,總體感覺只要Selenium、Python、Firefox版本一致就不會報錯,可從下面連結中安裝該版本Firefox。
下載地址:http://download.csdn.net/detail/mengh2016/7752097
那麼,登入成功後,為什麼就能訪問或跳轉到不同的頁面呢?
因為登入成功後會儲存Cookies或Session資訊,此時使用者就可以任意跳轉訪問了,否則會重新跳轉會登入介面。這裡使用Selenium的driver.get(url)實現跳轉。
獲取個人資訊
首先很多網站設計都是 URL+使用者ID 訪問個人網站,如柳巖:http://weibo.cn/guangxianliuyan
故定義一個TXT檔案列表包含,所有使用者ID資訊,依次通過讀取檔案爬取其微博資訊:
user_id = inforead.readline()
while user_id!="":
user_id = user_id.rstrip('\r\n')
VisitPersonPage(user_id) #訪問個人頁面
user_id = inforead.readline()
其中使用者ID列表在SinaWeibo_List.txt 中,如下所示:(明星)
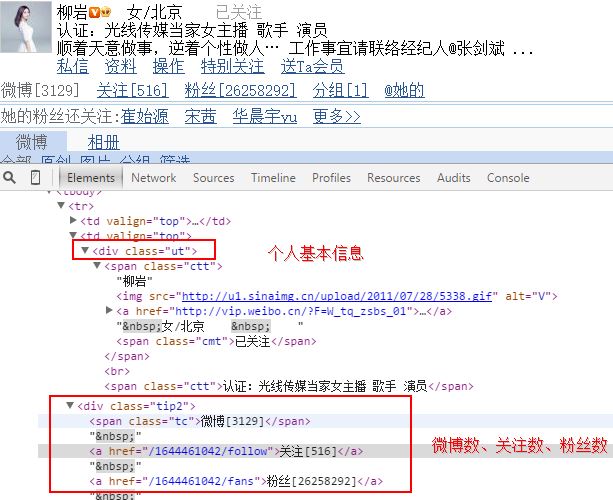
通過分析HTML原始碼,獲取節點位置,通過Selenium函式定義位置獲取資訊,然後再通過正規表示式或字串處理獲取想要的值。如獲取暱稱:
str_name = driver.find_element_by_xpath("//div[@class='ut']")
#空格分隔 獲取第一個值 "Eastmount 詳細資料 設定 新手區"
str_t = str_name.text.split(" ")
num_name = str_t[0]
print u'暱稱: ' + num_name
再如括號之間數字內容:
#微博[294] 關注[351] 粉絲[294] 分組[1] @他的
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'關注數: ' + str(num_gz)
資料URL:http://weibo.cn/1644461042/info
新浪微博登入常用介面:http://login.sina.com.cn/
對應主介面:http://weibo.com/
但是個人建議採用手機端微博入口:http://login.weibo.cn/login/
對應主介面:http://weibo.cn/
其原因是手機端資料相對更輕量型,同時基本資料都齊全,可能缺少些個人基本資訊,如"個人資料完成度"、"個人等級"等,同時粉絲ID和關注ID只能顯示20頁,但完全可以作為語料進行大部分的驗證。
通過比較下面兩張圖,分別是PC端和手機端,可以發現內容基本一致:
手機端下圖所示,其中圖片相對更小,同時內容更精簡。
完整原始碼
下面程式碼主要分為三部分:
1.LoginWeibo(username, password) 登入微博
2.VisitPersonPage(user_id) 訪問跟人網站,獲取個人資訊
3.獲取微博內容,同時http://weibo.cn/guangxianliuyan?filter=0&page=1實現翻頁
# coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博使用者的資訊
資訊:使用者ID 使用者名稱 粉絲數 關注數 微博數 微博內容
網址:http://weibo.cn/ 資料量更小 相對http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先呼叫無介面瀏覽器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全域性變數 檔案操作讀寫資訊
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陸weibo.cn 獲取新浪微博的cookie
# 該方法針對weibo.cn有效(明文形式傳輸資料) weibo.com見學弟設定POST和Header方法
# LoginWeibo(username, password) 引數使用者名稱 密碼
# 驗證碼暫停時間手動輸入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接訪問driver.get("http://weibo.cn/5824697471")會跳轉到登陸頁面 使用者id
#
# 使用者名稱<input name="mobile" size="30" value="" type="text"></input>
# 密碼 "password_4903" 中數字會變動,故採用絕對路徑方法,否則不能定位到元素
#
# 勾選記住登入狀態check預設是保留 故註釋掉該程式碼 不保留Cookie 則'expiry'=None
#**********************************************************************
#輸入使用者名稱/密碼登入
print u'準備登陸Weibo.cn網站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #使用者名稱
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密碼
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #記住登入狀態
#重點: 暫停時間輸入驗證碼
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #點選登陸
time.sleep(2)
#獲取Coockie 推薦 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #獲得cookie資訊 dict儲存
print u'輸出Cookie鍵值對資訊:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()型別list 僅包含一個元素cookie型別dict
print u'登陸成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 訪問個人頁面http://weibo.cn/5824697471並獲取資訊
# VisitPersonPage()
# 編碼常見錯誤 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'準備訪問個人網站.....'
#原創內容 http://weibo.cn/guangxianliuyan?filter=1&page=2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接獲取 使用者暱稱 微博數 關注數 粉絲數
# str_name.text是unicode編碼型別
#**************************************************************************
#使用者id
print u'個人詳細資訊'
print '**********************************************'
print u'使用者id: ' + user_id
#暱稱
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 獲取第一個值 "Eastmount 詳細資料 設定 新手區"
print u'暱稱: ' + num_name
#微博數 除個人主頁 它預設直接顯示微博數 無超連結
#Error: 'unicode' object is not callable
#一般是把字串當做函式使用了 str定義成字串 而str()函式再次使用時報錯
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正則提取"微博[0]" 但r"(\[.*?\])"總含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 關注[351] 粉絲[294] 分組[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博數: ' + str(num_wb)
#關注數
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'關注數: ' + str(num_gz)
#粉絲數
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉絲數: ' + str(num_fs)
#***************************************************************************
# No.2 檔案操作寫入資訊
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'使用者: ' + user_id + '\r\n')
infofile.write(u'暱稱: ' + num_name + '\r\n')
infofile.write(u'微博數: ' + str(num_wb) + '\r\n')
infofile.write(u'關注數: ' + str(num_gz) + '\r\n')
infofile.write(u'粉絲數: ' + str(num_fs) + '\r\n')
infofile.write(u'微博內容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 獲取微博內容
# http://weibo.cn/guangxianliuyan?filter=0&page=1
# 其中filter=0表示全部 =1表示原創
#***************************************************************************
print '\n'
print u'獲取微博內容資訊'
num = 1
while num <= 5:
url_wb = "http://weibo.cn/" + user_id + "?filter=0&page=" + str(num)
print url_wb
driver.get(url_wb)
#info = driver.find_element_by_xpath("//div[@id='M_DiKNB0gSk']/")
info = driver.find_elements_by_xpath("//div[@class='c']")
for value in info:
print value.text
info = value.text
#跳過最後一行資料為class=c
#Error: 'NoneType' object has no attribute 'groups'
if u'設定:皮膚.圖片' not in info:
if info.startswith(u'轉發'):
print u'轉發微博'
infofile.write(u'轉發微博\r\n')
else:
print u'原創微博'
infofile.write(u'原創微博\r\n')
#獲取最後一個點贊數 因為轉發是後有個點贊數
str1 = info.split(u" 贊")[-1]
if str1:
val1 = re.match(r'\[(.*?)\]', str1).groups()[0]
print u'點贊數: ' + val1
infofile.write(u'點贊數: ' + str(val1) + '\r\n')
str2 = info.split(u" 轉發")[-1]
if str2:
val2 = re.match(r'\[(.*?)\]', str2).groups()[0]
print u'轉發數: ' + val2
infofile.write(u'轉發數: ' + str(val2) + '\r\n')
str3 = info.split(u" 評論")[-1]
if str3:
val3 = re.match(r'\[(.*?)\]', str3).groups()[0]
print u'評論數: ' + val3
infofile.write(u'評論數: ' + str(val3) + '\r\n')
str4 = info.split(u" 收藏 ")[-1]
flag = str4.find(u"來自")
print u'時間: ' + str4[:flag]
infofile.write(u'時間: ' + str4[:flag] + '\r\n')
print u'微博內容:'
print info[:info.rindex(u" 贊")] #後去最後一個贊位置
infofile.write(info[:info.rindex(u" 贊")] + '\r\n')
infofile.write('\r\n')
print '\n'
else:
print u'跳過', info, '\n'
break
else:
print u'next page...\n'
infofile.write('\r\n\r\n')
num += 1
print '\n\n'
print '**********************************************'
except Exception,e:
print "Error: ",e
finally:
print u'VisitPersonPage!\n\n'
print '**********************************************\n'
#*******************************************************************************
# 程式入口 預先呼叫
#*******************************************************************************
if __name__ == '__main__':
#定義變數
username = '1520161***' #輸入你的使用者名稱
password = '**********' #輸入你的密碼
user_id = 'guangxianliuyan' #使用者id url+id訪問個人
#操作函式
LoginWeibo(username, password) #登陸微博
#driver.add_cookie({'name':'name', 'value':'_T_WM'})
#driver.add_cookie({'name':'value', 'value':'c86fbdcd26505c256a1504b9273df8ba'})
#注意
#因為sina微博增加了驗證碼,但是你用Firefox登陸一次輸入驗證碼,再呼叫該程式即可,因為Cookies已經保證
#會直接跳轉到明星微博那部分,即: http://weibo.cn/guangxianliuyan
#在if __name__ == '__main__':引用全域性變數不需要定義 global inforead 省略即可
print 'Read file:'
user_id = inforead.readline()
while user_id!="":
user_id = user_id.rstrip('\r\n')
VisitPersonPage(user_id) #訪問個人頁面
user_id = inforead.readline()
#break
infofile.close()
inforead.close()
登入頁面
首先,為什麼需要登入呢?
因為新浪微博很多資料如果不登入是不能獲取或訪問的,如微博的粉絲列表、個人詳細資訊、微博下一頁等等,當你點選這些超連結時就會自動跳轉到登入介面,這是開發者對其進行的保護措施。同時,各個公司都會提供API介面讓開發者進行操作,但此處我是使用Selenium模擬瀏覽器操作進行爬取的。
其中登入如上圖所示,函式LoginWeibo(username, password) 實現,它會自動開啟瀏覽器並輸入使用者名稱和密碼。在登入過程中由於會涉及到驗證碼,所以我採用暫停20秒,當使用者手動輸入驗證碼並且時間到後會自動點選按鈕登入。核心程式碼如下:
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #使用者名稱
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密碼
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #點選登陸
如果你登陸過程中Python報錯:
WebDriverException: Message: "Can't load the profile. Profile Dir:
猜測是Firefox版本問題,升級後出現的該問題,建議下載相對較老的版本,總體感覺只要Selenium、Python、Firefox版本一致就不會報錯,可從下面連結中安裝該版本Firefox。
下載地址:http://download.csdn.net/detail/mengh2016/7752097
那麼,登入成功後,為什麼就能訪問或跳轉到不同的頁面呢?
因為登入成功後會儲存Cookies或Session資訊,此時使用者就可以任意跳轉訪問了,否則會重新跳轉會登入介面。這裡使用Selenium的driver.get(url)實現跳轉。
獲取個人資訊
首先很多網站設計都是 URL+使用者ID 訪問個人網站,如柳巖:http://weibo.cn/guangxianliuyan
故定義一個TXT檔案列表包含,所有使用者ID資訊,依次通過讀取檔案爬取其微博資訊:
user_id = inforead.readline()
while user_id!="":
user_id = user_id.rstrip('\r\n')
VisitPersonPage(user_id) #訪問個人頁面
user_id = inforead.readline()
其中使用者ID列表在SinaWeibo_List.txt 中,如下所示:(明星)
guangxianliuyan
zhangjiani
1862829871
zmqd
houzimi
3125046087
gezhaoen
1877716733
ailleenmmm
linshenblog
superleoisme
2638613703
duiersky
ws95
wuwei1003673996
wuxin
1413971423
xiena
yangxinyu888
zhangyangguoer0418
liuyifeiofficial通過分析HTML原始碼,獲取節點位置,通過Selenium函式定義位置獲取資訊,然後再通過正規表示式或字串處理獲取想要的值。如獲取暱稱:
str_name = driver.find_element_by_xpath("//div[@class='ut']")
#空格分隔 獲取第一個值 "Eastmount 詳細資料 設定 新手區"
str_t = str_name.text.split(" ")
num_name = str_t[0]
print u'暱稱: ' + num_name
再如括號之間數字內容:
#微博[294] 關注[351] 粉絲[294] 分組[1] @他的
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'關注數: ' + str(num_gz)
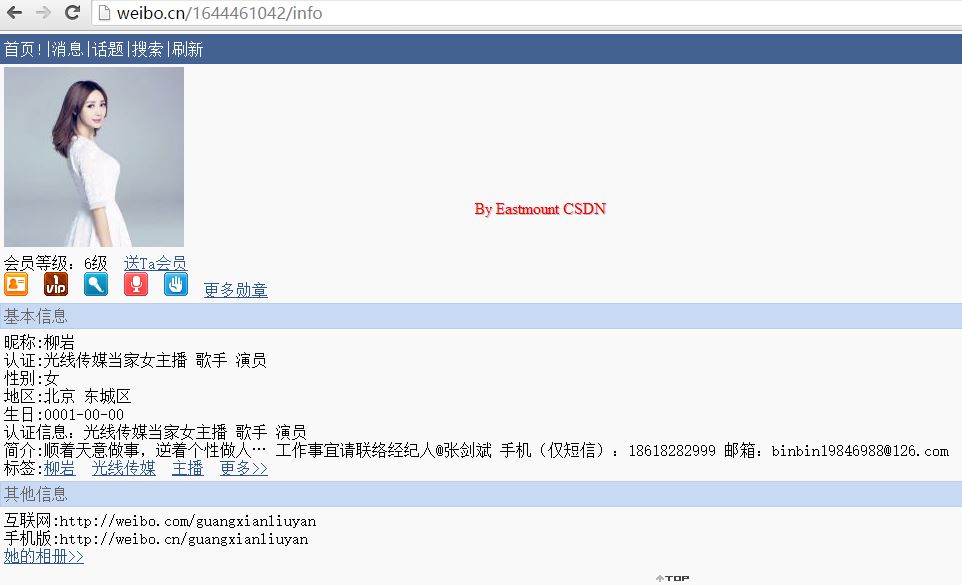
資料URL:http://weibo.cn/1644461042/info
關注URL:http://weibo.cn/1644461042/follow
粉絲URL:http://weibo.cn/1644461042/fans
但是手機端只能顯示20頁粉絲列表和關注列表。
點選"資料"可以獲取個人詳細資訊、點選"關注[516]"可以獲取關注列表,如果需要建立不同使用者之間的關注網,個人建議通過關注表而不是粉絲表,因為關注表覆蓋明星更大,而粉絲太多,構建的圖太稀疏。個人資訊如下圖所示:
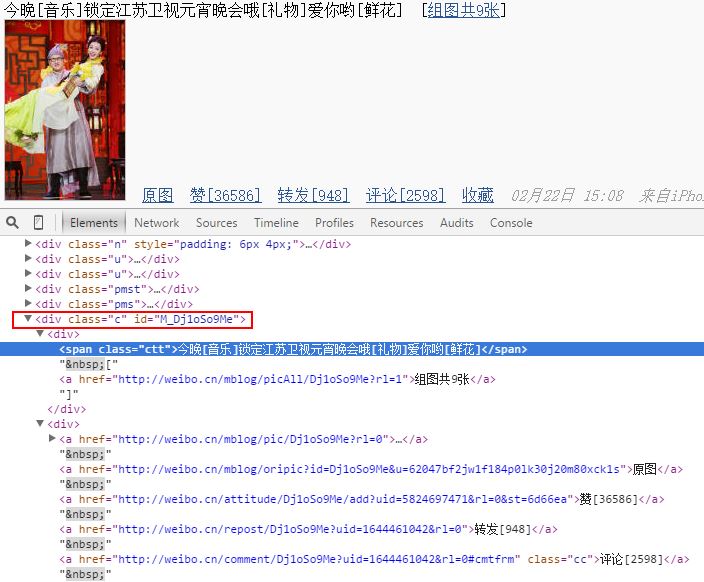
獲取微博
微博URL:http://weibo.cn/guangxianliuyan?filter=0&page=1
通過分析如下URL連結,可以發現Page=n 表示訪問第n頁微博,從而實現跳轉。filter=1表示原創,可以分析它對應的開頭幾個型別。再通過函式獲取內容:
info = driver.find_elements_by_xpath("//div[@class='c']")
然後如果釋出的微博以"轉發了..."開頭表示轉發的微博,否則為原創微博,程式碼:
info.startswith(u'轉發')
同時獲取微博點贊數、轉發數、時間等,其中因為轉發會包括點贊數,故獲取最後一個"贊[xxx]",然後通過正規表示式i獲取括號之間內容。
str1 = info.split(u" 贊")[-1]
if str1:
val1 = re.match(, str1).groups()[0]
print u'點贊數: ' + val1
infofile.write(u'點贊數: ' + str(val1) + '\r\n')
微博都是以class='c'節點,故獲取是有這類值,再進行字串處理即可。
PS:最後希望文章對你有所幫助!其實方法很簡單,希望你能理解這種思想,如何分析HTML原始碼及DOM樹結構,然後動態獲取自己需要的資訊。
(By:Eastmount 2016-02-23 深夜5點半 http://blog.csdn.net/eastmount/ )
粉絲URL:http://weibo.cn/1644461042/fans
但是手機端只能顯示20頁粉絲列表和關注列表。
點選"資料"可以獲取個人詳細資訊、點選"關注[516]"可以獲取關注列表,如果需要建立不同使用者之間的關注網,個人建議通過關注表而不是粉絲表,因為關注表覆蓋明星更大,而粉絲太多,構建的圖太稀疏。個人資訊如下圖所示:
獲取微博
微博URL:http://weibo.cn/guangxianliuyan?filter=0&page=1
通過分析如下URL連結,可以發現Page=n 表示訪問第n頁微博,從而實現跳轉。filter=1表示原創,可以分析它對應的開頭幾個型別。再通過函式獲取內容:
info = driver.find_elements_by_xpath("//div[@class='c']")
然後如果釋出的微博以"轉發了..."開頭表示轉發的微博,否則為原創微博,程式碼:
info.startswith(u'轉發')
同時獲取微博點贊數、轉發數、時間等,其中因為轉發會包括點贊數,故獲取最後一個"贊[xxx]",然後通過正規表示式i獲取括號之間內容。
str1 = info.split(u" 贊")[-1]
if str1:
val1 = re.match(
, str1).groups()[0]print u'點贊數: ' + val1
infofile.write(u'點贊數: ' + str(val1) + '\r\n')
微博都是以class='c'節點,故獲取是有這類值,再進行字串處理即可。
PS:最後希望文章對你有所幫助!其實方法很簡單,希望你能理解這種思想,如何分析HTML原始碼及DOM樹結構,然後動態獲取自己需要的資訊。
(By:Eastmount 2016-02-23 深夜5點半 http://blog.csdn.net/eastmount/ )
相關文章
- JB的Python之旅-爬蟲篇-新浪微博內容爬取Python爬蟲
- Python實現微博爬蟲,爬取新浪微博Python爬蟲
- Python網路爬蟲2 - 爬取新浪微博使用者圖片Python爬蟲
- 爬蟲實戰(一):爬取微博使用者資訊爬蟲
- [python爬蟲] Selenium爬取內容並儲存至MySQL資料庫Python爬蟲MySql資料庫
- PHP 爬蟲爬取社群文章內容PHP爬蟲
- 【Python爬蟲實戰】使用Selenium爬取QQ音樂歌曲及評論資訊Python爬蟲
- scrapy定製爬蟲-爬取javascript內容爬蟲JavaScript
- [python爬蟲] BeautifulSoup和Selenium簡單爬取知網資訊測試Python爬蟲
- python爬蟲——爬取大學排名資訊Python爬蟲
- python 爬蟲如何爬取動態生成的網頁內容Python爬蟲網頁
- Python爬蟲爬取B站up主所有動態內容Python爬蟲
- python爬蟲--爬取鏈家租房資訊Python爬蟲
- 爬蟲實戰(三):微博使用者資訊分析爬蟲
- Python爬蟲爬取淘寶,京東商品資訊Python爬蟲
- 小白學 Python 爬蟲(25):爬取股票資訊Python爬蟲
- 分散式爬蟲之知乎使用者資訊爬取分散式爬蟲
- ScienceDirect內容爬蟲爬蟲
- Python爬蟲學習筆記(1)爬取知乎使用者資訊Python爬蟲筆記
- 爬蟲實戰(二):Selenium 模擬登入並爬取資訊爬蟲
- 爬蟲Selenium+PhantomJS爬取動態網站圖片資訊(Python)爬蟲JS網站Python
- [python爬蟲] BeautifulSoup和Selenium對比爬取豆瓣Top250電影資訊Python爬蟲
- Scrapy框架的使用之Scrapy爬取新浪微博框架
- Python爬蟲實戰:爬取淘寶的商品資訊Python爬蟲
- Java爬蟲-爬取疫苗批次資訊Java爬蟲
- Python 超簡單爬取新浪微博資料 (高階版)Python
- Python爬蟲之路-selenium在爬蟲中的使用Python爬蟲
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- [python 爬蟲]第一個Python爬蟲,爬取某個新浪部落格所有文章並儲存為doc文件Python爬蟲
- 簡單的爬蟲:爬取網站內容正文與圖片爬蟲網站
- 蘇寧易購網址爬蟲爬取商品資訊及圖片爬蟲
- [Python3]selenium爬取淘寶商品資訊Python
- python爬蟲58同城(多個資訊一次爬取)Python爬蟲
- python爬蟲爬取csdn部落格專家所有部落格內容Python爬蟲
- Python 爬蟲進階篇-利用beautifulsoup庫爬取網頁文章內容實戰演示Python爬蟲網頁
- 【Python學習】爬蟲爬蟲爬蟲爬蟲~Python爬蟲
- python實現微博個人主頁的資訊爬取Python
- python 爬蟲 爬取 learnku 精華文章Python爬蟲