【伯樂線上轉註】:本文綜合自 張峻崇 寫於 2012 年末的兩篇總結(上、下)。
2012年底,末日之後,看到大家都在寫年末總結,我也忍不住想一試。工作已經3年半了,頭一次寫總結。雖然到現在仍是無名小碼農一名,但工作這些年,技術著實有不少積累。成長最大的,當然就是這篇文章標題提到的——高效能分散式計算與儲存系統的設計和研發過程,這也是我自2010年供職於國內最大的某著名網站之後,和這個系統一起成長,親眼見證和伴隨著它的發展,從一個嬰兒一樣的”Demo”程式,成長為現在可以處理千萬級日PV的強大系統,直到2012年我離開。我也順勢積累了Unix/Linux伺服器、多執行緒、I/O、海量資料處理、注重高效能與效率的C/C++程式設計等寶貴的碼農財富,當然,遺憾和不足,仍然是有許多的。
2012年,其實是自工作以來,技術積澱最多的一年。因為,在2012年,我終於學會了獨立思考,我不再像以前一樣,許許多的技術只是需要用到的時候,匆忙的google(有時候還要先匆忙的先FQ),我發現,“好記性不如爛筆頭”,古訓確實毋庸置疑,有大量的、瑣碎的技術經驗、程式設計細節、技巧,需要積澱下來,可能單條的細節與技巧,並不會對一個人的職業生涯產生什麼影響,但把它們都積聚起來,就會強大許多,很實際的,帶來的技術提升,能帶來更高的Offer。所以,2012年,我開始到部落格園寫技術部落格,和眾多園友分享我對技術的一知半解,共同進步;也終於耐下心,為自己做了一個簡單的個人主頁,雖然10年前,我就可以做出這樣的東西……;我成為了更忠實的蘋果粉,所以我嘗試去做iOS創業,雖然這和我的主要工作研究方向並不一致,當我看到自己做的demo在自己iPhone 4s上跑起來,我突然又有一了一種久違的興奮——那是每一個程式設計師,都體會過的,小小的成就感;2012年,我開始接觸和了解許多以前從來不懂的技術:Hadoop、GoogleFS、JVM、XCode、ARC……小到如何將vim打造成一個IDE……。
接下來,該進入這篇文章的正題了, 就是簡單地談談,我這兩年,主要做的東西——高效能分散式計算與儲存系統。
這個系統看名字十分牛比,所涉足的目前網際網路最領先的技術領域。具體有什麼用途? 在我之前供職的公司,它主要是作為中間層,給網站頁面提供快取服務的,並且,它對付的難題,是大資料、海量資料,相信,每一個日PV超過千萬級的網站,都必須會有類似的系統存在,如果,你曾經看過,部落格園裡的《淘寶技術發展》等類似文章,就一定不會對我接來將要提到的許多概念和術語感到陌生。對於這樣大流量,需要處理大資料的網站而言,由Web的邏輯直接呼叫管理資料儲存,是非常不科學的,實際上也是不可能的,大資料、高併發的對資料庫進行讀寫,通常資料庫都會掛掉,從而使網站也掛掉,必須要在Web和資料庫之間,通過技術手段實現一種“轉換”或“控制”,或“均衡”或“過渡”,我不知道這樣用詞是否正確,你只要明白其中的意思就好了。這樣的技術手段有許多,所實現的東東也有許多,我們用到的,就是被稱為“中間層”的一個邏輯層,在這個層,將資料庫的海量資料抓出來,做成快取,執行在伺服器的記憶體中,同理,當有新的資料到來,也先做成快取,再想辦法,持久化到資料庫中,就是這樣簡單的思路,但實現起來,從零到有,可以說難如登天,但是,任何事物,都是在曲折中,不斷髮展前進的,這是中學我們就學過的哲學理論。這個系統,就被我們稱簡為“快取系統”,它最大的好處,就是砍掉了每天上千萬次的資料庫讀寫操作,取代而之的,是讀取伺服器中提供快取服務的程式所控制的記憶體,所以你知道,這裡面節省了多少的資源申請、競爭、I/O……當然,後面你也會發現,它會帶來許多新的問題,最顯著的問題,就是資料的同步和一致性,後面我會講到。
現在,讓我們先看看, 這個系統,發展到我離開它的時候,長什麼樣子?(由於涉及到商業機密,具體的技術不能提供)

(點選可檢視大圖)
就是這樣的一張架構圖,代表著可以處理每日上千萬PV的系統,涉及到許多的技術,讓我們一個部分一個部分解讀它。
首先,從當我有一個web請求到達時,將會發生怎樣的事情說起。比如,我是一個使用者,我在這個網站登陸,我的“個人”頁面上,將會載入許許多多的東西,有許許多多的圖片、文字、訊息等,我們舉其中一個例子,我將要得到我的好友列表——friend list。通過常識可以知道,這個friend list,不是隨機的、臨時的,而肯定是一個(一組)持久化儲存於資料庫裡的資料,我們就是一個使用者請求得到他的friend list說起,來解讀這張架構圖。如果我的網站流量很小,每天不超過10萬PV,峰值可能就幾百個上千個使用者,同時請求他們的friend list,那麼,現今任何一種語言配上任何一種資料庫的搭配,只要稍做處理,都可以很好的完成這個工作——從資料庫中,讀出該使用者的friend list,然後訪回給web,如果使用者對好友列表作了任何修改,web馬上將修改內容寫入資料庫,形成新的friend list。然而,當訪問流量持續提升,達到千萬級、甚至億級PV的時候,剛才說的方法就不可行了。因為,同時可能有幾十萬甚至上百萬使用者,通過web請求從資料庫中讀(如果寫將會更糟糕)上百條萬資料,資料庫將不堪重負,形成巨大的延遲甚至掛掉。通過上面的系統,來解決這樣的問題。
現在,我們要設計和研發的上述系統,當一個web頁面提交一個獲取friend list的請求後,它首先將根據一定的規則,通過負載均衡,然後到達相應的master節點。上面我們提到的是DNS負載均衡,這得眾多負載均衡技術中的一種方法。也就是說,我有許許多多的master節點(上圖的scalabe表明,我是可擴充套件的,只要有條件,可隨意橫向擴充套件節點,以提高速度、容災、容量等指標),每個master節點的IP地址(域名)當然不一樣,通過DNS負載均衡,合理地把該請求,送到相對“空閒”的master節點伺服器。現在解釋一下master節點伺服器和slave節點伺服器的功能:slave節點,主要用於”Running services”,即,實際處理請求的快取服務程式,通常執行在slave節點上;master節點,主要用於分發通過負載均衡的請求(當然,master節點上也可以執行一些“快取服務程式”,即併發流量不高、較輔助的一些服務),找到用於處理實際請求的合適的slave節點,將該請求交給它處理,再次實現了一道“負載均衡”,同時,需要分散式計算的內容,將可能同時分發到幾個slave節點,之後再對結果進行合併返回(Map-Reduce原理)。
好了,現在我們已經知道,一個friend list請求已經通過DNS負載均衡、通過master節點進行分配,到達了相應的slave節點上。我們還知道,所說的“快取” ,正是slave節點中所執行的services程式中所管理的記憶體,提供同樣功能的service可能會有很多份,同時執行在不同slave節點上,以提供高併發和分散式計算的功能。例如,獲得friend list就是這樣的service,因為這個功能太常用了,所以,在我們的系統中,這樣的服務可能同時提供5份、10份甚至更多,那麼我這個獲取friend list的請求,究竟被分配到哪個slave節點上的service處理呢?這正是剛才提到的master節點來完成這一工作。再比如,我現在需要獲取“二度關係”的列表(關於六度人脈理論,可google),所謂“二度關係”,就是好友的好友,那麼我要取這樣的列表,即friend’s every friend list,這樣的請求,將會把取每個friend list分配(Map)到不同slave節點上去做(根據一定的規則),然後再進行合併(Reduce)(當然,熟悉演算法的同學可能已經發現,這樣去獲取請求,非常的笨拙,有沒有更好的方法呢?當然有!因為好友的好友,其實就是好友的friend list與我和好友的共同好友common friend list的“差集”,對嗎?所以我不用去取好友的每個好友的friend list,而只用取2次就可以通過計算完成請求,這又節省了多少資源呢?假如我有100個好友,1000個,10000萬個?會節省多少次計算呢?這也證明,一個良好的演算法,對改善程式效能,有多麼大的幫助!)
好,我們繼續。現在,我的獲取friend list的請求,已經在被某個slave節點中的負責這一功能的service程式處理,它將根據一定規則,給出兩種可能的處理方式:
1、 我這個使用者非常活躍,經常登陸網站(一定的規則,認為快取未到過期時間),且我這個slave節點自上次“重建快取”(即重新從資料庫中讀取資料,建立快取,後面會談)後,沒有發生過down機重啟行為(又一定的規則),我也沒有收到過master節點傳送過來要求更新快取(即從資料庫中比較資料並更新)的Notification(通知),或是在一定條件下我這個slave節點對它掌握的快取資料版本(版本管理系統原理,思考一下svn的工作原理)和資料庫進行了一次比較(注意,比較資料版本可認為只是一個int值,且是原子操作,這和比較整條資料是否一致在效能上有天壤之別)發現是最新的資料版本,那麼,我這個slave節點將直接返回快取資料,而沒有任何資料庫讀操作,也就是說,我這一次獲取friend list的請求,得到的是快取資料,當然,這個快取資料肯定是最新的、正確的、和資料庫中的持久化資料是一致的,後面會提到怎樣來儘量保證這一點;
2、第1點中的“一定規則”不滿足時,即我這個slave節點的快取和資料庫中的資料可能存在不一致的沒有其它辦法,我必須從資料庫中讀取資料,更新快取,然後再返回。但同時注意,slave節點中的service服務程式,將認為此使用者現在活躍,可能還會請求一些相關、類似的資料(如馬上可能進行新增好友、刪除好友等操作),所以去資料庫讀取資料的時候,將不會只讀friend list,可能與使用者有關的其它一部分資料,會被同時讀取並更新快取,如果負責這一部分資料的快取服務並不是當前的service程式,或在其它slave節點,或同時還有幾份service程式在工作,那麼slave節點將提交“更新快取”請求給master節點,通過master節點發出Notification給相關slave節點的相關service程式,從而,儘可能使每一次讀取資料庫的作用最大化,而如果稍後使用者果然進行了我們猜測的行為(可認為cache命中),結果將同第1點,直接通過快取返回資料而且保證了資料的正確和一致性。
好了,剛剛提到的都是“讀操作”,相比“寫操作”, 其資料一致性更容易保證,之後我們將講述“寫操作”的工作原理。現在,讓我們先跳過這一部分,繼續看架構圖。slave節點之後,就是實際的資料儲存了,使用了MySQL、Redis,MySQL主從之間的協同是DBA的工作,不在此篇討論,Redis主要儲存K-V鍵值對資料,比如使用者id和使用者暱稱,是最常用的K-V對之一,通過Redis進行儲存,再結合上述的工作過程,可保證這個系統的高效能。而架構圖最右下角的Hadoop與MongoDB,是可選的MySQL替代方案,其實,正是未來的主要發展方向。如果slave節點中的service服務程式與Hadoop良好結合,系統的效能將更上一層樓。順便說一句,master、slave節點都是由C++開發的。可參考陳皓的一篇文章《Why C++? 王者歸來》。
————–【分隔線】 ————–
在上篇裡,我們主要討論了,這個系統怎樣處理大資料的“讀”操作,當然還有一些細節沒有講述。下篇,我們將主要講述,“寫”操作是如何被處理的。我們都知道,如果只有“讀”,那幾乎是不用做任何資料同步的,也不會有併發安全問題,之所以,會產生這樣那樣的問題,會導致快取和資料庫的資料不一致,其實根源就在於“寫”操作的存在。下面,讓我們看一看,當系統需要寫一條資料的時候,又會發生怎樣的事情?
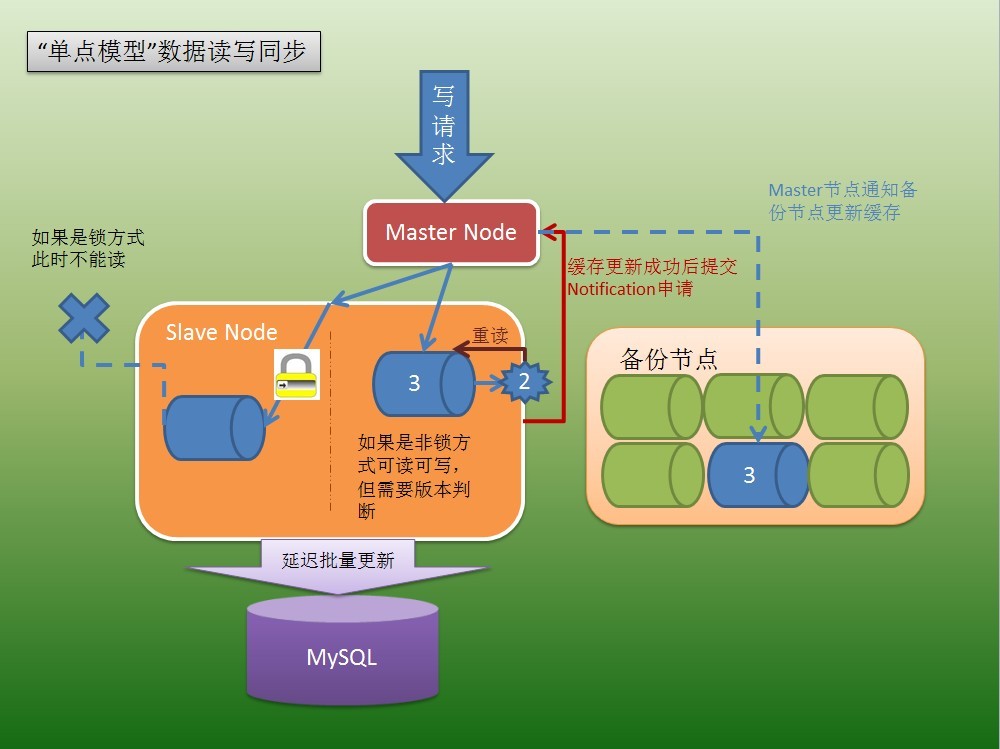
同樣,我們還是以friend list為例。現在,我登陸了這個網站,獲取了friend list之後,我新增了一個好友,那麼,我的friend list必定要做修改和更新(當然,新增好友這一個動作肯定不會只有修改更新friend list這一個請求,但我們以此為例,其它請求也是類似處理),那麼,這個要求修改和更新friend list的請求,和獲取friend list請求類似,在被slave節點中的服務程式處理之前,也是先通過DNS負載均衡,被分配到合適的master節點,再由master節點,分配到合適的相對空閒的負責這一功能的slave點上。現在假設,前面我們已經講過,獲取friend list這樣的請求,非常常用,所以,提供這一供能的服務程式將會有多份,比如,有10份,服務程式編號為0~9,同時執行在10個(也可能僅執行在1個~9個slave節點上!)slave節點上,具體分配請求的時候,選擇哪一個slave節點和哪一份服務程式呢?這當然有許多種規則去影響分配策略,我們就舉一個最簡單的例子,採用使用者id對10取模,得到0~9的結果,即是所選擇的服務程式編號,假設我的使用者id尾號為9,那麼我這個請求,只會被分配到編號為9的服務程式去處理(當然,所有使用者id尾號為9的都是如此),編號為9的服務程式,也只負責為資料庫中使用者id尾號為9的那些資料做快取,而使用者id尾號為0~8的快取則由其它服務程式來處理。如果所需的請求是以剛才這種方式工作的,那麼現在我要求修改和更新friend list的這個請求,將只會被分配到服務程式編號為9的程式來處理,我們稱之為“單點模型”(也就是說,同一條資料只會有一份可用快取,備份節點上的的不算),你可能已經猜到了,還會有“多點模型”——即同時有好幾個服務程式都會負責同樣的快取資料,這是更復雜的情況,我們稍後再討論。
(點選可檢視大圖)
現在,我們接著說“單點模型” 。這個修改和更新friend list的請求到了編號為9的服務程式中後,如何被處理呢?快取肯定先要被處理,之後才考慮快取去和資料庫同步一致,這大家都知道(否則還要這個系統幹嘛?)大家還知道,只要涉及到併發的讀寫,就肯定存在併發衝突和安全問題,這又如何解決呢?我們有兩種方式,來進行讀寫同步。
1、 第一種方式,就是傳統的,加鎖方式——通過加鎖,可以有效地保證快取中資料的同步和正確,但缺點也非常明顯,當服務程式中同時存在讀寫操作的執行緒時,將會存在嚴重的鎖競爭,進而重新形成效能瓶頸。好在,通常使用這種方式處理的業務需求,都經過上述的一些負載均衡、分流措施之後,鎖的粒度不會太大,還是上述例子,我最多也就鎖住了所有使用者id尾號為9的這部分快取資料更新,其它90%的使用者則不受影響。再具體些,鎖住的快取資料可以更小,甚至僅鎖住我這個使用者的快取資料,那麼,鎖產生的效能瓶頸影響就會更小了(為什麼鎖的粒度不可能小到總是直接鎖住每個使用者的快取資料呢?答案很簡單,你不可能有那麼多的鎖同時在工作,資料庫也不可能為每個使用者建一張表),即鎖的粒度是需要平衡和調整的。好,現在繼續,我要求修改和更新friend list的請求,已經被服務程式中的寫程式在處理,它將會申請獲得對這部分快取資料的鎖,然後進行寫操作,之後釋放鎖,傳統的鎖工作流程。在這期間,讀操作將被阻塞等待,可想而知,如果鎖的粒度很大,將有多少讀操作處於阻塞等待狀態,那麼該系統的高效能就無從談起了。
2、有沒有更好的方法呢?當然有,這就是無鎖的工作方式。首先,我們的網站,是一個讀操作遠大於寫操作的網站(如果需求相反,可能處理的方式也就相反了),也就是說,大多數時候,讀操作不應該被寫操作阻塞,應優先保證讀操作,如果產生了寫操作,再想辦法使讀操作“更新”一次,進而使得讀寫同步。這樣的工作方式,其實很像版本管理工具,如svn的工作原理:即,每個人,都可以讀,不會因為有人在進行寫,使得讀被阻塞;當我讀到資料後,由於有人寫,可能已經不是最新的資料了,svn在你嘗試提交寫的時候,進行判斷,如果版本不一致,則重新讀,合併,再寫。我們的系統也是按類似的方式工作的:即每個執行緒,都可以讀,但讀之前先比較一下版本號,然後讀快取資料,讀完之後準備返回給Web時,再次比較版本號,如果發現版本已經被更新(當然你讀的資料頂多是“老”資料,但不至於是錯誤的資料,Why?還是參考svn,這是”Copy and Write”原理,即我寫的那一份資料,是copy出來寫的,寫完再copy回去,不會在你讀出的那一份上寫),則必須重新讀,直到讀到的快取資料版本號是最新的。前面已經說過,比較和更新版本號,可認為是原子操作(比如,利用CAS操作可以很好的完成這一點,關於CAS操作,可以google到一大堆東西),所以,整個處理流程就實現了無鎖化,這樣,在大資料高併發的時候,沒有鎖瓶頸產生。然而,你可能已經發現其中的一些問題,最顯著的問題,就是可能多讀不止一次資料,如果讀的資料較多較大,又要產生效能瓶頸了(苦!沒有辦法),並且可能產生延遲,造成差的使用者體驗。那麼,又如何來解決這些問題呢?其實,我們是根據實際的業務需求來做權衡的,如果,所要求的請求,允許一定的延遲存在,實時性要求不是最高,比如,我看我好友發的動態,這樣的快取資料,並不要求實時性非常高,稍稍有延遲是允許的,你可以想象一下,如果你的好友發了一個狀態,你完全沒有必要,其實也不可能在他點選“釋出”之後,你的動態就得到了更新,其實只要在一小段時間內(比如10秒?)你的動態更新了,看到了他新發布了狀態,就足夠了。假設是這樣的請求,且如果我採用第1種加鎖的方式所產生的效能瓶頸更大,那麼,將採用這種無鎖的工作方式,即當讀寫有衝突時候,讀操作重新讀所產生的開銷或延遲,是可以忍受的。比較幸運的是,同時有多個讀寫執行緒操作同一條快取資料導致多次的重讀行為,其實並不是總是發生,也就是說,我們系統的大資料併發,主要在多個程式執行緒同時讀不同條的資料這一業務需求上,這也很容易理解,每個使用者登陸,都是讀他們各自的friend list(不同條資料,且在不同的slave節點上),只不過,這些請求是併發的(如果不進行分散式處理會沖垮伺服器或資料庫),但是並不總是會,許多使用者都要同時讀某一條friend list同時我還在更新該條friend list導致多次無效的重讀行為。
我們繼續上面的friend list。現在,我的friend list已經在快取中被修改和更新了。無論是採用方式1還是方式2進行,在這期間,如果恰好有其它執行緒來讀我的friend list,那麼總之會受到影響,如果是方式1,該請求將等待寫完畢;而如果是方式2,該請求將讀2次(也可能更多,但實在不常見)。這樣的處理方式,應該不是最好的,但前面已經說過了,我們的系統,主要解決:大流量高併發地讀寫多條資料,而不是一條。接下來,該考慮和資料庫同步的事情了。
恩,剛才說了那麼多,你有沒有發現,經過我修改和更新friend list後,快取中的資料和資料庫不一致了呢?顯然,資料庫中的資料,已經過期了,需要對其更新。現在,slave節點中的編號為9的服務程式,更新完了自己的快取資料後(修改更新我的friend list),將“嘗試”向資料庫更新。注意,用詞“嘗試”表明該請求不一定會被馬上得到滿足。其實,服務程式對資料庫的更新,是批量進行的,可認為是一個TaskContainer(任務容器),每間隔一段時間,或得到一定的任務數量,則成批地向資料庫進行更新操作,而不是每過來一個請求,更新快取後就更新一次資料庫(你現在知道了這樣做又節省了多少次資料庫操作!)。那麼,為什麼可以這樣做呢?因為,我們已經有了快取,快取就是我們的保障,在“單點模型”下,快取更新後,任何讀快取的操作,都只會讀到該快取,不需要經過資料庫,參看上篇中提到過此問題。所以,資料庫的寫更新操作,可以“聚集”,可以一定延遲之後,再進行處理。你會發現,既然如此,我就可以對這些操作進行合併、優化,比如,兩個寫請求都是操作同一張表,那麼可以合併成一條,沒錯,這其實已經涉及到SQL優化的領域了。當然,你也會發現,現在快取中的新資料還沒有進行持久化,如果在這個時間點,slave節點機器down掉了,那麼,這部分資料就丟失了!所以,這個延遲時間並不會太長,通常10秒已經足夠了。即,每10秒,整理一下我這個服務程式中已經更新快取未更新DB的請求,然後統一處理,如果更杞人憂天(雖然考慮資料安全性決不能說是杞人憂天,但你要明白,其實任何實時伺服器發生down行為總是會有資料丟失的,只是或多或少),則延遲間隔可以更短一些,則DB壓力更大一些,再次需要進行實際的考量和權衡。至此,我的friend list修改和更新請求,就全部完成了,雖然,可能在幾十秒之前,就已經在頁面上看到了變化(通過快取返回的資料)。
那麼,讀和寫都已經講述了,還有其它問題嗎?問題還不少。剛才討論的,都是“單點模型”。

(點選可檢視大圖)
即,每一條資料庫中的資料,都只有一份快取資料與之對應。然而,實際上,“多點模型”是必須存在的,而且是更強大的處理方式,也帶來同步和一致性的更多難題,即每一條資料,可能有多份快取與之對應。即多個slave節點上的服務程式中,都有一份對應DB中相同資料的快取,這個時候,又將如何同步呢?我們解決的方式,叫做“最終一致性”原則,關於最終一致性模型,又可以google到一大堆,特別要提出的是GoogleFS的多點一致性同步,就是通過“最終一致性”來解決的,通俗的講,就是同一條資料,同一時刻,只能被一個節點修改。假設,我現在的業務,是“多點模型”,比如,我的friend list,是多點模型,有多份快取(雖然實際並不是這樣的),那麼,我對friend list的修改和更新,將只會修改我被分配到的slave節點服務程式中的快取,其它服務程式或slave節點的快取,以及資料庫,將必須被同步更新,這是如何做到的呢?這又要用到上篇曾提到的Notification(通知服務),這個模組雖然沒有在架構圖中出現,卻是這個系統中最核心的一種服務(當然,它也是多份的,呵呵),即,當一條資料是多點模型時,當某一個服務程式對其進行修改和更新後,將通過向master節點提交Notificaion並通知其它服務程式或其它slave節點,告知他們的快取已經過期,需要進行更新,這個更新,可能由所進行修改更新的服務程式,傳送快取資料給其它程式或節點,也由可能等待DB更新之後,由其它節點從DB進行更新,從而間接保證多點一致性。等等,剛才不是說,通常10秒才批量更新DB嗎?那是因為在單點模型下,這樣做是合理的,但在多點模型下,雖然也是批理對資料庫進行更新,但這樣的延遲通常非常小,可認為即時對資料庫進行批量更新,然後,通過Notification通知所有有這一條資料的節點,更新他們的快取。由此可見,多點模型,所可能產生的問題是不少的。那麼,為什麼要用多點模型呢?假設我有這樣的業務:大資料高併發的讀某一條資料,非常非常多的讀,但寫很少,比如一張XX門的熱門圖片,有很多很多的請求來自不同的使用者都需要這個條資料的快取,多點模型即是完美的選擇。我許多slave節點上都有它的快取,而很少更新,則可最大限度的享用到多點模型帶來的效能提升。
還有一些問題,不得不說一下。就是down機和定期快取更新的問題。先說當機,很顯然,快取是slave節點中的服務程式的記憶體,一旦節點當機,快取就丟失了,這時就需要前面我提到過的“重建快取”,這通常是由master節點發出的,master節點負責監控各個slave節點(當然也可以是其它master節點)的執行狀況,如果發現某個slave節點當機(沒有了“心跳”,如果你瞭解一些Hadoop,你會發現它也是這樣工作的),則在slave節點重新執行之後(可能進行了重啟),master節點將通知該slave節點,重建其所負責的資料的快取,從哪重建,當然是從資料庫了,這需要一定的時間(在我們擁有百萬使用者之後,重建一個slave節點所負責的資料的快取通常需要幾分鐘),那麼,從當機到slave節點重建快取完畢這一段時間,服務由誰提供呢?顯然備份節點就出馬了。其實在單點模型下,如果考慮了備份節點,則其實所有的請求都是多點模型。只不過備份節點並不是總是會更新它的快取,而是定期,或收到Notification時,才會進行更新。master節點在發現某個slave節點當機後,可以馬上指向含有同樣資料的備份節點,保證快取服務不中斷。那麼,備份節點的快取資料是否是最新的呢?有可能不是。雖然,通常每次對資料庫完成批量更新後,都會通知備份節點,去更新這些快取,但還是有可能存在不一致的情況。所以,備份節點的工作方式,是特別的,即對於每次請求的快取都採用Pull(拉)方式,如何Pull?前面提到的版本管理系統再次出馬,即每次讀之前,先比較版本,再讀,寫也是一樣的。所以,備份節點的效能,並不會很高,而且,通常需要同時負責幾個slave節點的資料的備份,所以,存在被沖垮的可能性,還需要slave節點儘快恢復,然後把服務工作重新還給它。
再說定期快取更新的問題。通常,所有的slave節點,都會被部署在夜深人靜的某個時候(如02:00~06:00),使用者很少的時候,定期進行快取更新,以儘可能保證資料的同步和一致性,且第二天上午,大量請求到達時,基本都能從快取返回最新資料。而備份節點,則可能每30分鐘,就進行一次快取更新。咦?前面你不是說,備份節點上每次讀都要Pull,比較版本並更新快取,才會返回嗎?是的,那為什麼還要定期更新呢?答案非常簡單,因為如果大部分快取都是最新的資料,只比較版本而沒有實際的更新操作,所消耗的效能很小很小,所以定期更新,在發生slave節點當機轉由備份節點工作的時候,有很大的幫助。
最後,再說一下Push(推送)方式,即,每次有資料改動,都強制去更新所有快取。這種方式很消耗效能,但更能保證實時性。而通常我們使用的,都是Pull(拉)方式,即無論是定期更新快取,還是收到Notification(雖然收通知是被“推”了一把)後更新快取,其實都是拉,把新的資料拉過來,就好了。在實際的系統中,兩種方式都有,還是那句話,看需求,再決定處理方式。
好了,終於寫完了這篇總結,看到上篇釋出後,得到了許許多多園友的鼓勵和支援,在此一併感謝!相信也有不少園友,已經看到了這個系統的許多不足和瓶頸,確實,它並不是一個完美的系統,還需要不斷進化。我寫出這篇文章,也是希望和大家多多交流,共同進步。馬上就是2013年了,希望自己能有更好的發展,也希望所有的朋友,都能更上一層樓!
(全文完,Jone Zhang,張峻崇,2012.12.28)