基礎知識
一張資料表中具有百萬級的資料時,如何精確且快速的拿出其中某一條或多條記錄成為了人們思考的問題。
InnoDB儲存引擎的出現讓這個問題得到了很好的解決,InnoDB儲存引擎是以索引來進行資料的組織,而索引在MySQL中也被稱之為鍵,因此UNIQUE KEY,PRIMARY KEY約束欄位會作為索引欄位。
當沒有明確指出PRIMAY KEY時,InnoDB儲存引擎會自動的建立一個6位元組的隱藏主鍵用於組織資料,但是由於該主鍵是隱藏的所以對查詢沒有任何幫助。
索引相當於一本大字典的目錄,有了目錄來找想要的內容就快很多,否則就只能進行一頁一頁的遍歷查詢
查詢過程
索引的查詢過程是依照B+樹演算法進行查詢的,而每一張資料表都會有一個且只能有一個與之對應的樹

只有最下面一層節點中儲存一整行記錄
第二層及第一層中黃色部分為指標
如圖所示,如果要查詢資料項29,那麼首先會把磁碟塊1由磁碟載入到記憶體,此時發生一次IO,在記憶體中用二分查詢確定29在17和35之間,鎖定磁碟塊1的P2指標,記憶體時間因為非常短(相比磁碟的IO)可以忽略不計,通過磁碟塊1的P2指標的磁碟地址把磁碟塊3由磁碟載入到記憶體,發生第二次IO,29在26和30之間,鎖定磁碟塊3的P2指標,通過指標載入磁碟塊8到記憶體,發生第三次IO,同時記憶體中做二分查詢找到29,結束查詢,總計三次IO。真實的情況是,3層的B+樹可以表示上百萬的資料,如果上百萬的資料查詢只需要三次IO,效能提高將是巨大的,如果沒有索引,每個資料項都要發生一次IO,那麼總共需要百萬次的IO,顯然成本非常非常高。
索引分類
索引分為聚集索引與輔助索引
聚集索引
聚集索引是會直接按照B+樹進行查詢,由於B+樹的底層葉子節點是一整行記錄,所以聚集索引能夠十分快速的拿到一整行記錄。
值得注意的是,一張資料表中只能有一個聚集索引。
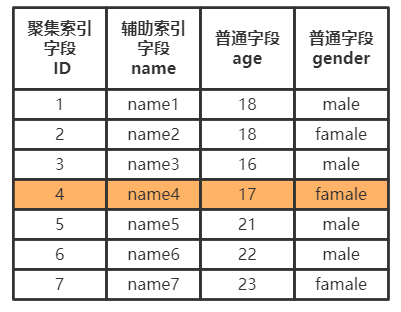
輔助索引
輔助索引的樹最底層的葉子節點並不會儲存一整行記錄,而是隻儲存單列索引的資料,並且還儲存了聚集索引的資訊。
通過輔助索引進行查詢時,先拿到自身索引欄位的資料,再通過聚集索引拿到整行記錄,也就是說輔助索引拿一整行記錄而言需要最少兩次查詢。
而一張資料表中可以有多個輔助索引。
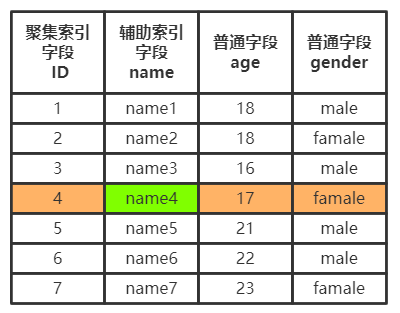
建立索引
索引型別
| 索引名 | 型別 |
|---|---|
| INDEX(field) | 普通索引,只加速查詢,無約束條件 |
| PRIMARY KEY(field) | 主鍵索引,加速查詢,非空且唯一約束 |
| UNIQUE(field) | 唯一索引,加速查詢,唯一約束 |
| INDEX(field1,field2) | 聯合普通索引 |
| PRIMARY KEY(field1,field2) | 聯合主鍵索引 |
| UNIQUE(field1,field2) | 聯合唯一索引 |
| FULLTEXT(field) | 全文索引 |
| SPATIAL(field) | 空間索引 |


舉個例子來說,比如你在為某商場做一個會員卡的系統。 這個系統有一個會員表 有下列欄位: 會員編號 INT 會員姓名 VARCHAR(10) 會員身份證號碼 VARCHAR(18) 會員電話 VARCHAR(10) 會員住址 VARCHAR(50) 會員備註資訊 TEXT 那麼這個 會員編號,作為主鍵,使用 PRIMARY 會員姓名 如果要建索引的話,那麼就是普通的 INDEX 會員身份證號碼 如果要建索引的話,那麼可以選擇 UNIQUE (唯一的,不允許重複) # 除此之外還有全文索引,即FULLTEXT 會員備註資訊如果需要建索引的話,可以選擇全文搜尋。 用於搜尋很長一篇文章的時候,效果最好。 用在比較短的文字,如果就一兩行字的,普通的 INDEX 也可以。 但其實對於全文搜尋,我們並不會使用MySQL自帶的該索引,而是會選擇第三方軟體如Sphinx,專門來做全文搜尋。 # 其他的如空間索引SPATIAL,瞭解即可,幾乎不用 各個索引的應用場景
語法介紹
索引應當再建立表時就進行建立,如果表中已有大量資料,再進行建立索引會花費大量的時間。
-- 方法一:建立表時
CREATE TABLE 表名 (
欄位名1 資料型別 [完整性約束條件…],
欄位名2 資料型別 [完整性約束條件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (欄位名[(長度)] [ASC |DESC])
);
-- 方法二:CREATE在已存在的表上建立索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (欄位名[(長度)] [ASC |DESC]) ;
-- 方法三:ALTER TABLE在已存在的表上建立索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (欄位名[(長度)] [ASC |DESC]) ;
-- 刪除索引:DROP INDEX 索引名 ON 表名字;
功能測試
-- 準備表,注意此時表沒有設定任何型別的索引
create table s1(
id int,
number varchar(20)
);
-- 建立儲存過程,實現批量插入記錄
delimiter $$ -- 宣告儲存過程的結束符號為$$
create procedure auto_insert1()
BEGIN
declare i int default 1; -- 宣告定義變數
while(i < 1000000) do
insert into s1 values
(i,concat('第', i, '條記錄'));
set i = i + 1;
end while;
END $$ -- 儲存過程建立完畢
delimiter ;
-- 呼叫儲存過程,自動插入一百萬條資料
call auto_insert1();
在無索引的情況下,查詢id為567891的這條記錄,耗時0.03s
mysql> select * from s1 where id = 567891;
+--------+--------------------+
| id | number |
+--------+--------------------+
| 567891 | 第567891條記錄 |
+--------+--------------------+
1 row in set (0.33 sec) 接下來為id欄位建立主鍵索引後再進行查詢,耗時為0.00s
mysql> ALTER TABLE s1 MODIFY id int PRIMARY KEY;
Query OK, 0 rows affected (4.76 sec) -- 建立索引花費寺廟
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from s1 where id = 567891;
+--------+--------------------+
| id | number |
+--------+--------------------+
| 567891 | 第567891條記錄 |
+--------+--------------------+
1 row in set (0.00 sec) 再次查詢則快了很多