Flink原理與實現:記憶體管理
如今,大資料領域的開源框架(Hadoop,Spark,Storm)都使用的 JVM,當然也包括 Flink。基於 JVM 的資料分析引擎都需要面對將大量資料存到記憶體中,這就不得不面對 JVM 存在的幾個問題:
- Java 物件儲存密度低。一個只包含 boolean 屬性的物件佔用了16個位元組記憶體:物件頭佔了8個,boolean 屬性佔了1個,對齊填充佔了7個。而實際上只需要一個bit(1/8位元組)就夠了。
- Full GC 會極大地影響效能,尤其是為了處理更大資料而開了很大記憶體空間的JVM來說,GC 會達到秒級甚至分鐘級。
- OOM 問題影響穩定性。OutOfMemoryError是分散式計算框架經常會遇到的問題,當JVM中所有物件大小超過分配給JVM的記憶體大小時,就會發生OutOfMemoryError錯誤,導致JVM崩潰,分散式框架的健壯性和效能都會受到影響。
所以目前,越來越多的大資料專案開始自己管理JVM記憶體了,像 Spark、Flink、HBase,為的就是獲得像 C 一樣的效能以及避免 OOM 的發生。本文將會討論 Flink 是如何解決上面的問題的,主要內容包括記憶體管理、定製的序列化工具、快取友好的資料結構和演算法、堆外記憶體、JIT編譯優化等。
積極的記憶體管理
Flink 並不是將大量物件存在堆上,而是將物件都序列化到一個預分配的記憶體塊上,這個記憶體塊叫做 MemorySegment,它代表了一段固定長度的記憶體(預設大小為 32KB),也是 Flink 中最小的記憶體分配單元,並且提供了非常高效的讀寫方法。你可以把 MemorySegment 想象成是為 Flink 定製的 java.nio.ByteBuffer。它的底層可以是一個普通的 Java 位元組陣列(byte[]),也可以是一個申請在堆外的 ByteBuffer。每條記錄都會以序列化的形式儲存在一個或多個MemorySegment中。
Flink 中的 Worker 名叫 TaskManager,是用來執行使用者程式碼的 JVM 程式。TaskManager 的堆記憶體主要被分成了三個部分:
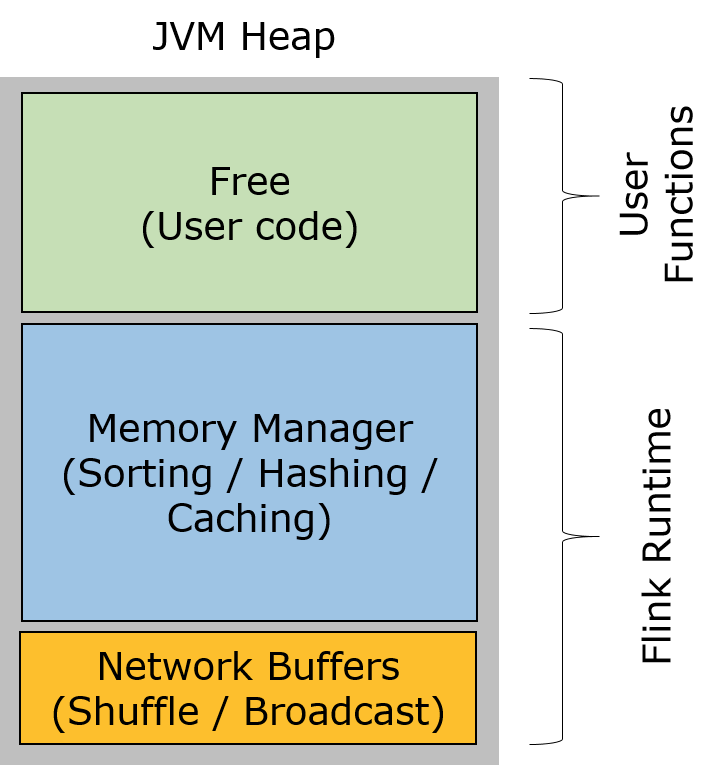
-
Network Buffers: 一定數量的32KB大小的 buffer,主要用於資料的網路傳輸。在 TaskManager 啟動的時候就會分配。預設數量是 2048 個,可以通過
taskmanager.network.numberOfBuffers來配置。(閱讀這篇文章瞭解更多Network Buffer的管理) -
Memory Manager Pool: 這是一個由
MemoryManager管理的,由眾多MemorySegment組成的超大集合。Flink 中的演算法(如 sort/shuffle/join)會向這個記憶體池申請 MemorySegment,將序列化後的資料存於其中,使用完後釋放回記憶體池。預設情況下,池子佔了堆記憶體的 70% 的大小。 - Remaining (Free) Heap: 這部分的記憶體是留給使用者程式碼以及 TaskManager 的資料結構使用的。因為這些資料結構一般都很小,所以基本上這些記憶體都是給使用者程式碼使用的。從GC的角度來看,可以把這裡看成的新生代,也就是說這裡主要都是由使用者程式碼生成的短期物件。
注意:Memory Manager Pool 主要在Batch模式下使用。在Steaming模式下,該池子不會預分配記憶體,也不會向該池子請求記憶體塊。也就是說該部分的記憶體都是可以給使用者程式碼使用的。不過社群是打算在 Streaming 模式下也能將該池子利用起來。
Flink 採用類似 DBMS 的 sort 和 join 演算法,直接操作二進位制資料,從而使序列化/反序列化帶來的開銷達到最小。所以 Flink 的內部實現更像 C/C++ 而非 Java。如果需要處理的資料超出了記憶體限制,則會將部分資料儲存到硬碟上。如果要操作多塊MemorySegment就像操作一塊大的連續記憶體一樣,Flink會使用邏輯檢視(AbstractPagedInputView)來方便操作。下圖描述了 Flink 如何儲存序列化後的資料到記憶體塊中,以及在需要的時候如何將資料儲存到磁碟上。
從上面我們能夠得出 Flink 積極的記憶體管理以及直接操作二進位制資料有以下幾點好處:
-
減少GC壓力。顯而易見,因為所有常駐型資料都以二進位制的形式存在 Flink 的
MemoryManager中,這些MemorySegment一直呆在老年代而不會被GC回收。其他的資料物件基本上是由使用者程式碼生成的短生命週期物件,這部分物件可以被 Minor GC 快速回收。只要使用者不去建立大量類似快取的常駐型物件,那麼老年代的大小是不會變的,Major GC也就永遠不會發生。從而有效地降低了垃圾回收的壓力。另外,這裡的記憶體塊還可以是堆外記憶體,這可以使得 JVM 記憶體更小,從而加速垃圾回收。 -
避免了OOM。所有的執行時資料結構和演算法只能通過記憶體池申請記憶體,保證了其使用的記憶體大小是固定的,不會因為執行時資料結構和演算法而發生OOM。在記憶體吃緊的情況下,演算法(sort/join等)會高效地將一大批記憶體塊寫到磁碟,之後再讀回來。因此,
OutOfMemoryErrors可以有效地被避免。 - 節省記憶體空間。Java 物件在儲存上有很多額外的消耗(如上一節所談)。如果只儲存實際資料的二進位制內容,就可以避免這部分消耗。
- 高效的二進位制操作 & 快取友好的計算。二進位制資料以定義好的格式儲存,可以高效地比較與操作。另外,該二進位制形式可以把相關的值,以及hash值,鍵值和指標等相鄰地放進記憶體中。這使得資料結構可以對快取記憶體更友好,可以從 L1/L2/L3 快取獲得效能的提升(下文會詳細解釋)。
為 Flink 量身定製的序列化框架
目前 Java 生態圈提供了眾多的序列化框架:Java serialization, Kryo, Apache Avro 等等。但是 Flink 實現了自己的序列化框架。因為在 Flink 中處理的資料流通常是同一型別,由於資料集物件的型別固定,對於資料集可以只儲存一份物件Schema資訊,節省大量的儲存空間。同時,對於固定大小的型別,也可通過固定的偏移位置存取。當我們需要訪問某個物件成員變數的時候,通過定製的序列化工具,並不需要反序列化整個Java物件,而是可以直接通過偏移量,只是反序列化特定的物件成員變數。如果物件的成員變數較多時,能夠大大減少Java物件的建立開銷,以及記憶體資料的拷貝大小。
Flink支援任意的Java或是Scala型別。Flink 在資料型別上有很大的進步,不需要實現一個特定的介面(像Hadoop中的org.apache.hadoop.io.Writable),Flink 能夠自動識別資料型別。Flink 通過 Java Reflection 框架分析基於 Java 的 Flink 程式 UDF (User Define Function)的返回型別的型別資訊,通過 Scala Compiler 分析基於 Scala 的 Flink 程式 UDF 的返回型別的型別資訊。型別資訊由 TypeInformation 類表示,TypeInformation 支援以下幾種型別:
-
BasicTypeInfo: 任意Java 基本型別(裝箱的)或 String 型別。 -
BasicArrayTypeInfo: 任意Java基本型別陣列(裝箱的)或 String 陣列。 -
WritableTypeInfo: 任意 Hadoop Writable 介面的實現類。 -
TupleTypeInfo: 任意的 Flink Tuple 型別(支援Tuple1 to Tuple25)。Flink tuples 是固定長度固定型別的Java Tuple實現。 -
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。 -
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java物件的所有成員變數,要麼是 public 修飾符定義,要麼有 getter/setter 方法。 -
GenericTypeInfo: 任意無法匹配之前幾種型別的類。
前六種資料型別基本上可以滿足絕大部分的Flink程式,針對前六種型別資料集,Flink皆可以自動生成對應的TypeSerializer,能非常高效地對資料集進行序列化和反序列化。對於最後一種資料型別,Flink會使用Kryo進行序列化和反序列化。每個TypeInformation中,都包含了serializer,型別會自動通過serializer進行序列化,然後用Java Unsafe介面寫入MemorySegments。對於可以用作key的資料型別,Flink還同時自動生成TypeComparator,用來輔助直接對序列化後的二進位制資料進行compare、hash等操作。對於 Tuple、CaseClass、POJO 等組合型別,其TypeSerializer和TypeComparator也是組合的,序列化和比較時會委託給對應的serializers和comparators。如下圖展示 一個內嵌型的Tuple3 物件的序列化過程。
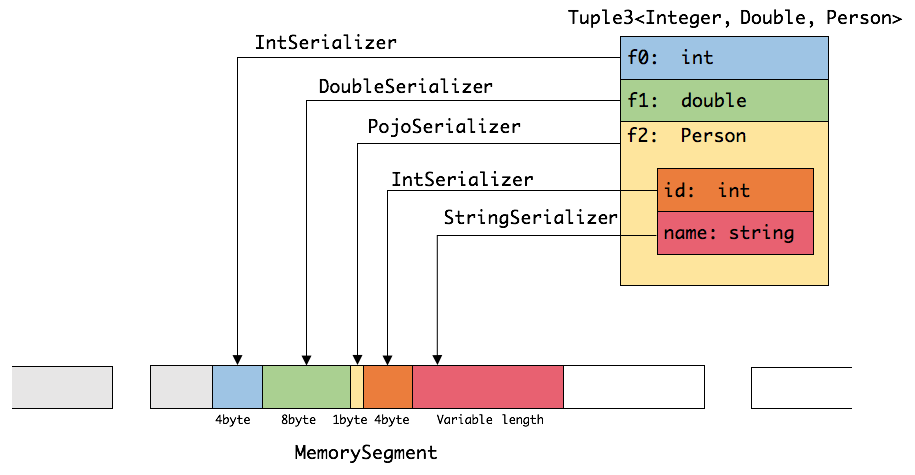
可以看出這種序列化方式儲存密度是相當緊湊的。其中 int 佔4位元組,double 佔8位元組,POJO多個一個位元組的header,PojoSerializer只負責將header序列化進去,並委託每個欄位對應的serializer對欄位進行序列化。
Flink 的型別系統可以很輕鬆地擴充套件出自定義的TypeInformation、Serializer以及Comparator,來提升資料型別在序列化和比較時的效能。
Flink 如何直接操作二進位制資料
Flink 提供瞭如 group、sort、join 等操作,這些操作都需要訪問海量資料。這裡,我們以sort為例,這是一個在 Flink 中使用非常頻繁的操作。
首先,Flink 會從 MemoryManager 中申請一批 MemorySegment,我們把這批 MemorySegment 稱作 sort buffer,用來存放排序的資料。
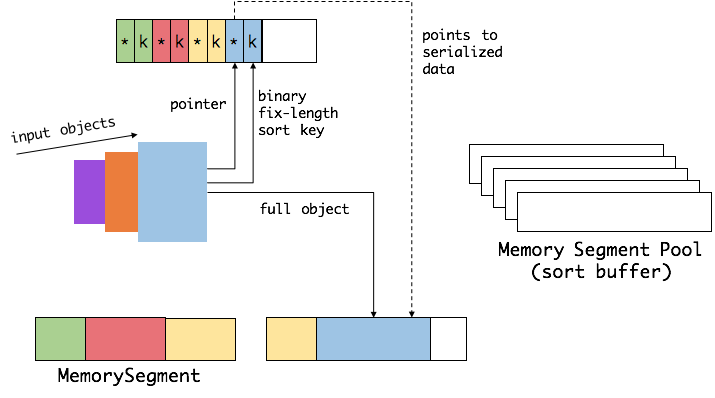
我們會把 sort buffer 分成兩塊區域。一個區域是用來存放所有物件完整的二進位制資料。另一個區域用來存放指向完整二進位制資料的指標以及定長的序列化後的key(key+pointer)。如果需要序列化的key是個變長型別,如String,則會取其字首序列化。如上圖所示,當一個物件要加到 sort buffer 中時,它的二進位制資料會被加到第一個區域,指標(可能還有key)會被加到第二個區域。
將實際的資料和指標加定長key分開存放有兩個目的。第一,交換定長塊(key+pointer)更高效,不用交換真實的資料也不用移動其他key和pointer。第二,這樣做是快取友好的,因為key都是連續儲存在記憶體中的,可以大大減少 cache miss(後面會詳細解釋)。
排序的關鍵是比大小和交換。Flink 中,會先用 key 比大小,這樣就可以直接用二進位制的key比較而不需要反序列化出整個物件。因為key是定長的,所以如果key相同(或者沒有提供二進位制key),那就必須將真實的二進位制資料反序列化出來,然後再做比較。之後,只需要交換key+pointer就可以達到排序的效果,真實的資料不用移動。
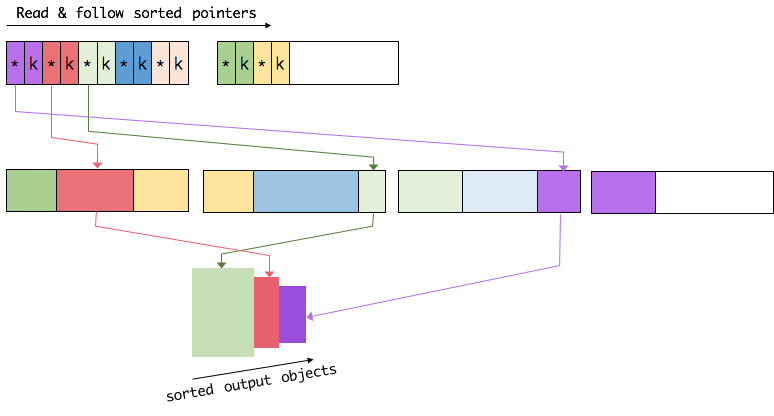
最後,訪問排序後的資料,可以沿著排好序的key+pointer區域順序訪問,通過pointer找到對應的真實資料,並寫到記憶體或外部(更多細節可以看這篇文章 Joins in Flink)。
快取友好的資料結構和演算法
隨著磁碟IO和網路IO越來越快,CPU逐漸成為了大資料領域的瓶頸。從 L1/L2/L3 快取讀取資料的速度比從主記憶體讀取資料的速度快好幾個量級。通過效能分析可以發現,CPU時間中的很大一部分都是浪費在等待資料從主記憶體過來上。如果這些資料可以從 L1/L2/L3 快取過來,那麼這些等待時間可以極大地降低,並且所有的演算法會因此而受益。
在上面討論中我們談到的,Flink 通過定製的序列化框架將演算法中需要操作的資料(如sort中的key)連續儲存,而完整資料儲存在其他地方。因為對於完整的資料來說,key+pointer更容易裝進快取,這大大提高了快取命中率,從而提高了基礎演算法的效率。這對於上層應用是完全透明的,可以充分享受快取友好帶來的效能提升。
走向堆外記憶體
Flink 基於堆記憶體的記憶體管理機制已經可以解決很多JVM現存問題了,為什麼還要引入堆外記憶體?
- 啟動超大記憶體(上百GB)的JVM需要很長時間,GC停留時間也會很長(分鐘級)。使用堆外記憶體的話,可以極大地減小堆記憶體(只需要分配Remaining Heap那一塊),使得 TaskManager 擴充套件到上百GB記憶體不是問題。
- 高效的 IO 操作。堆外記憶體在寫磁碟或網路傳輸時是 zero-copy,而堆記憶體的話,至少需要 copy 一次。
- 堆外記憶體是程式間共享的。也就是說,即使JVM程式崩潰也不會丟失資料。這可以用來做故障恢復(Flink暫時沒有利用起這個,不過未來很可能會去做)。
但是強大的東西總是會有其負面的一面,不然為何大家不都用堆外記憶體呢。
- 堆記憶體的使用、監控、除錯都要簡單很多。堆外記憶體意味著更復雜更麻煩。
- Flink 有時需要分配短生命週期的
MemorySegment,這個申請在堆上會更廉價。 - 有些操作在堆記憶體上會快一點點。
Flink用通過ByteBuffer.allocateDirect(numBytes)來申請堆外記憶體,用 sun.misc.Unsafe 來操作堆外記憶體。
基於 Flink 優秀的設計,實現堆外記憶體是很方便的。Flink 將原來的 MemorySegment 變成了抽象類,並生成了兩個子類。HeapMemorySegment 和 HybridMemorySegment。從字面意思上也很容易理解,前者是用來分配堆記憶體的,後者是用來分配堆外記憶體和堆記憶體的。是的,你沒有看錯,後者既可以分配堆外記憶體又可以分配堆記憶體。為什麼要這樣設計呢?
首先假設HybridMemorySegment只提供分配堆外記憶體。在上述堆外記憶體的不足中的第二點談到,Flink 有時需要分配短生命週期的 buffer,這些buffer用HeapMemorySegment會更高效。那麼當使用堆外記憶體時,為了也滿足堆記憶體的需求,我們需要同時載入兩個子類。這就涉及到了 JIT 編譯優化的問題。因為以前 MemorySegment 是一個單獨的 final 類,沒有子類。JIT 編譯時,所有要呼叫的方法都是確定的,所有的方法呼叫都可以被去虛化(de-virtualized)和內聯(inlined),這可以極大地提高效能(MemroySegment的使用相當頻繁)。然而如果同時載入兩個子類,那麼 JIT 編譯器就只能在真正執行到的時候才知道是哪個子類,這樣就無法提前做優化。實際測試的效能差距在 2.7 被左右。
Flink 使用了兩種方案:
方案1:只能有一種 MemorySegment 實現被載入
程式碼中所有的短生命週期和長生命週期的MemorySegment都例項化其中一個子類,另一個子類根本沒有例項化過(使用工廠模式來控制)。那麼執行一段時間後,JIT 會意識到所有呼叫的方法都是確定的,然後會做優化。
方案2:提供一種實現能同時處理堆記憶體和堆外記憶體
這就是 HybridMemorySegment 了,能同時處理堆與堆外記憶體,這樣就不需要子類了。這裡 Flink 優雅地實現了一份程式碼能同時操作堆和堆外記憶體。這主要歸功於 sun.misc.Unsafe提供的一系列方法,如getLong方法:
sun.misc.Unsafe.getLong(Object reference, long offset)- 如果reference不為空,則會取該物件的地址,加上後面的offset,從相對地址處取出8位元組並得到 long。這對應了堆記憶體的場景。
- 如果reference為空,則offset就是要操作的絕對地址,從該地址處取出資料。這對應了堆外記憶體的場景。
這裡我們看下 MemorySegment 及其子類的實現。
public abstract class MemorySegment {
// 堆記憶體引用
protected final byte[] heapMemory;
// 堆外記憶體地址
protected long address;
//堆記憶體的初始化
MemorySegment(byte[] buffer, Object owner) {
//一些先驗檢查
...
this.heapMemory = buffer;
this.address = BYTE_ARRAY_BASE_OFFSET;
...
}
//堆外記憶體的初始化
MemorySegment(long offHeapAddress, int size, Object owner) {
//一些先驗檢查
...
this.heapMemory = null;
this.address = offHeapAddress;
...
}
public final long getLong(int index) {
final long pos = address + index;
if (index >= 0 && pos <= addressLimit - 8) {
// 這是我們關注的地方,使用 Unsafe 來操作 on-heap & off-heap
return UNSAFE.getLong(heapMemory, pos);
}
else if (address > addressLimit) {
throw new IllegalStateException("segment has been freed");
}
else {
// index is in fact invalid
throw new IndexOutOfBoundsException();
}
}
...
}
public final class HeapMemorySegment extends MemorySegment {
// 指向heapMemory的額外引用,用來如陣列越界的檢查
private byte[] memory;
// 只能初始化堆記憶體
HeapMemorySegment(byte[] memory, Object owner) {
super(Objects.requireNonNull(memory), owner);
this.memory = memory;
}
...
}
public final class HybridMemorySegment extends MemorySegment {
private final ByteBuffer offHeapBuffer;
// 堆外記憶體初始化
HybridMemorySegment(ByteBuffer buffer, Object owner) {
super(checkBufferAndGetAddress(buffer), buffer.capacity(), owner);
this.offHeapBuffer = buffer;
}
// 堆記憶體初始化
HybridMemorySegment(byte[] buffer, Object owner) {
super(buffer, owner);
this.offHeapBuffer = null;
}
...
}可以發現,HybridMemorySegment 中的很多方法其實都下沉到了父類去實現。包括堆內堆外記憶體的初始化。MemorySegment 中的 getXXX/putXXX 方法都是呼叫了 unsafe 方法,可以說MemorySegment已經具有了些 Hybrid 的意思了。HeapMemorySegment只呼叫了父類的MemorySegment(byte[] buffer, Object owner)方法,也就只能申請堆記憶體。另外,閱讀程式碼你會發現,許多方法(大量的 getXXX/putXXX)都被標記成了 final,兩個子類也是 final 型別,為的也是優化 JIT 編譯器,會提醒 JIT 這個方法是可以被去虛化和內聯的。
對於堆外記憶體,使用 HybridMemorySegment 能同時用來代表堆和堆外記憶體。這樣只需要一個類就能代表長生命週期的堆外記憶體和短生命週期的堆記憶體。既然HybridMemorySegment已經這麼全能,為什麼還要方案1呢?因為我們需要工廠模式來保證只有一個子類被載入(為了更高的效能),而且HeapMemorySegment比heap模式的HybridMemorySegment要快。
下方是一些效能測試資料,更詳細的資料請參考這篇文章。
| Segment | Time |
|---|---|
| HeapMemorySegment, exclusive | 1,441 msecs |
| HeapMemorySegment, mixed | 3,841 msecs |
| HybridMemorySegment, heap, exclusive | 1,626 msecs |
| HybridMemorySegment, off-heap, exclusive | 1,628 msecs |
| HybridMemorySegment, heap, mixed | 3,848 msecs |
| HybridMemorySegment, off-heap, mixed | 3,847 msecs |
總結
本文主要總結了 Flink 面對 JVM 存在的問題,而在記憶體管理的道路上越走越深。從自己管理記憶體,到序列化框架,再到堆外記憶體。其實縱觀大資料生態圈,其實會發現各個開源專案都有同樣的趨勢。比如最近炒的很火熱的 Spark Tungsten 專案,與 Flink 在記憶體管理上的思想是及其相似的。
參考資料
- [Off-heap Memory in Apache Flink and the curious JIT compiler
](https://flink.apache.org/news/2015/09/16/off-heap-memory.html) - [Juggling with Bits and Bytes
](https://flink.apache.org/news/2015/05/11/Juggling-with-Bits-and-Bytes.html) - [Peeking into Apache Flink`s Engine Room
](https://flink.apache.org/news/2015/03/13/peeking-into-Apache-Flinks-Engine-Room.html) - Flink: Memory Management
- [Big Data Performance Engineering
](http://www.bigsynapse.com/addressing-big-data-performance) - sun.misc.misc.Unsafe usage for C style memory management
- sun.misc.misc.Unsafe usage for C style memory management – How to do it.
- Memory usage of Java objects: general guide
- 脫離JVM? Hadoop生態圈的掙扎與演化
相關文章
- Flink記憶體管理記憶體
- 記憶體管理Release和Retain實現原理記憶體AI
- iOS記憶體管理的那些事兒-原理及實現iOS記憶體
- Flink原理與實現:SessionWindowSession
- C++ 多型的實現原理與記憶體模型C++多型記憶體模型
- 記憶體管理篇——實體記憶體的管理記憶體
- Java 8 記憶體管理原理解析及記憶體故障排查實踐Java記憶體
- Go:記憶體管理與記憶體清理Go記憶體
- Objective-C 記憶體管理之alloc/retain/release/dealloc實現原理Object記憶體AI
- C++記憶體管理:簡易記憶體池的實現C++記憶體
- flink記憶體模型詳解與案例記憶體模型
- 記憶體管理兩部曲之實體記憶體管理記憶體
- Java記憶體管理原理及記憶體區域詳解Java記憶體
- Flink原理與實現:Window機制
- 資料庫實現原理#6(共享記憶體)資料庫記憶體
- Flink 的記憶體管理是如何做的?記憶體
- 記憶體管理 記憶體管理概述記憶體
- 作業系統記憶體管理-原理作業系統記憶體
- Flink Window基本概念與實現原理
- 記憶體管理與檢測記憶體
- 自動共享記憶體管理 自動記憶體管理 手工記憶體管理記憶體
- linux記憶體管理(一)實體記憶體的組織和記憶體分配Linux記憶體
- oracle記憶體結構與管理Oracle記憶體
- 讀Flink原始碼談設計:有效管理記憶體之道原始碼記憶體
- 記憶體自動管理與手動管理記憶體
- 有管理共享記憶體設計方法的具體實現記憶體
- 【記憶體管理】記憶體佈局記憶體
- 記憶體定址原理記憶體
- iOS底層原理(一):OC物件實際佔用記憶體與開闢記憶體關係iOS物件記憶體
- [Virtualization]ESXi體系結構與記憶體管理(二)控制記憶體分配記憶體
- [Virtualization]ESXi體系結構與記憶體管理(三)控制記憶體分配記憶體
- AntDB記憶體管理之記憶體上下文之記憶體上下文機制是怎麼實現的記憶體
- 記憶體管理記憶體
- hugepages優化記憶體原理與優點優化記憶體
- flink中的記憶體劃分記憶體
- JVM原理講解和調優,記憶體管理和垃圾回收,記憶體調優JVM記憶體
- CORBA物件生命週期之實現和記憶體管理ORB物件記憶體
- PHP 垃圾回收與記憶體管理指引PHP記憶體