【面向程式碼】學習 Deep Learning(二)Deep Belief Nets(DBNs)
==========================================================================================
最近一直在看Deep Learning,各類部落格、論文看得不少
但是說實話,這樣做有些疏於實現,一來呢自己的電腦也不是很好,二來呢我目前也沒能力自己去寫一個toolbox
只是跟著Andrew Ng的UFLDL tutorial 寫了些已有框架的程式碼(這部分的程式碼見github)
後來發現了一個matlab的Deep Learning的toolbox,發現其程式碼很簡單,感覺比較適合用來學習演算法
再一個就是matlab的實現可以省略掉很多資料結構的程式碼,使演算法思路非常清晰
所以我想在解讀這個toolbox的程式碼的同時來鞏固自己學到的,同時也為下一步的實踐打好基礎
(本文只是從程式碼的角度解讀演算法,具體的演算法理論步驟還是需要去看paper的
我會在文中給出一些相關的paper的名字,本文旨在梳理一下演算法過程,不會深究演算法原理和公式)
==========================================================================================
使用的程式碼:DeepLearnToolbox ,下載地址:點選開啟,感謝該toolbox的作者
==========================================================================================
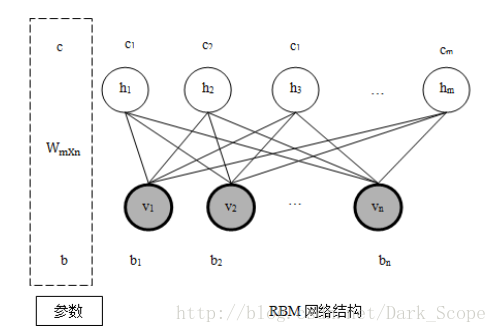
今天介紹DBN的內容,其中關鍵部分都是(Restricted Boltzmann Machines, RBM)的步驟,所以先放一張rbm的結構,幫助理解
==========================================================================================
照例,我們首先來看一個完整的DBN的例子程式:
這是\tests\test_example_DBN.m 中的ex2
//train dbn
dbn.sizes = [100 100];
opts.numepochs = 1;
opts.batchsize = 100;
opts.momentum = 0;
opts.alpha = 1;
dbn =dbnsetup(dbn, train_x, opts); //here!!!
dbn = dbntrain(dbn, train_x, opts); //here!!!
//unfold dbn to nn
nn = dbnunfoldtonn(dbn, 10); //here!!!
nn.activation_function = 'sigm';
//train nn
opts.numepochs = 1;
opts.batchsize = 100;
nn = nntrain(nn, train_x, train_y, opts);
[er, bad] = nntest(nn, test_x, test_y);
assert(er < 0.10, 'Too big error');
最後fine tuning的時候用了(一)裡看過的nntrain和nntest,參見(一)
\DBN\dbnsetup.m
這個實在沒什麼好說的,
同樣,W,b,c是引數,vW,vb,vc是更新時用到的與momentum的變數,見到程式碼時再說
for u = 1 : numel(dbn.sizes) - 1
dbn.rbm{u}.alpha = opts.alpha;
dbn.rbm{u}.momentum = opts.momentum;
dbn.rbm{u}.W = zeros(dbn.sizes(u + 1), dbn.sizes(u));
dbn.rbm{u}.vW = zeros(dbn.sizes(u + 1), dbn.sizes(u));
dbn.rbm{u}.b = zeros(dbn.sizes(u), 1);
dbn.rbm{u}.vb = zeros(dbn.sizes(u), 1);
dbn.rbm{u}.c = zeros(dbn.sizes(u + 1), 1);
dbn.rbm{u}.vc = zeros(dbn.sizes(u + 1), 1);
end\DBN\dbntrain.m
function dbn = dbntrain(dbn, x, opts)
n = numel(dbn.rbm);
//對每一層的rbm進行訓練
dbn.rbm{1} = rbmtrain(dbn.rbm{1}, x, opts);
for i = 2 : n
x = rbmup(dbn.rbm{i - 1}, x);
dbn.rbm{i} = rbmtrain(dbn.rbm{i}, x, opts);
end
end
\DBN\rbmtrain.m

for i = 1 : opts.numepochs //迭代次數
kk = randperm(m);
err = 0;
for l = 1 : numbatches
batch = x(kk((l - 1) * opts.batchsize + 1 : l * opts.batchsize), :);
v1 = batch;
h1 = sigmrnd(repmat(rbm.c', opts.batchsize, 1) + v1 * rbm.W'); //gibbs sampling的過程
v2 = sigmrnd(repmat(rbm.b', opts.batchsize, 1) + h1 * rbm.W);
h2 = sigm(repmat(rbm.c', opts.batchsize, 1) + v2 * rbm.W');
//Contrastive Divergence 的過程
//這和《Learning Deep Architectures for AI》裡面寫cd-1的那段pseudo code是一樣的
c1 = h1' * v1;
c2 = h2' * v2;
//關於momentum,請參看Hinton的《A Practical Guide to Training Restricted Boltzmann Machines》
//它的作用是記錄下以前的更新方向,並與現在的方向結合下,跟有可能加快學習的速度
rbm.vW = rbm.momentum * rbm.vW + rbm.alpha * (c1 - c2) / opts.batchsize;
rbm.vb = rbm.momentum * rbm.vb + rbm.alpha * sum(v1 - v2)' / opts.batchsize;
rbm.vc = rbm.momentum * rbm.vc + rbm.alpha * sum(h1 - h2)' / opts.batchsize;
//更新值
rbm.W = rbm.W + rbm.vW;
rbm.b = rbm.b + rbm.vb;
rbm.c = rbm.c + rbm.vc;
err = err + sum(sum((v1 - v2) .^ 2)) / opts.batchsize;
end
end\DBN\dbnunfoldtonn.m
function nn = dbnunfoldtonn(dbn, outputsize)
%DBNUNFOLDTONN Unfolds a DBN to a NN
% outputsize是你的目標輸出label,比如在MINST就是10,DBN只負責學習feature
% 或者說初始化Weight,是一個unsupervised learning,最後的supervised還得靠NN
if(exist('outputsize','var'))
size = [dbn.sizes outputsize];
else
size = [dbn.sizes];
end
nn = nnsetup(size);
%把每一層展開後的Weight拿去初始化NN的Weight
%注意dbn.rbm{i}.c拿去初始化了bias項的值
for i = 1 : numel(dbn.rbm)
nn.W{i} = [dbn.rbm{i}.c dbn.rbm{i}.W];
end
end
最後fine tuning就再訓練一下NN就可以了
總結
相關文章
- 【面向程式碼】學習 Deep Learning(四) Stacked Auto-Encoders(SAE)
- 【面向程式碼】學習 Deep Learning(三)Convolution Neural Network(CNN)CNN
- 深度學習 DEEP LEARNING 學習筆記(二)深度學習筆記
- 深度學習(Deep Learning)深度學習
- 《DEEP LEARNING·深度學習》深度學習
- 深度學習 DEEP LEARNING 學習筆記(一)深度學習筆記
- 深度學習(Deep Learning)優缺點深度學習
- 機器學習(Machine Learning)&深度學習(Deep Learning)資料機器學習Mac深度學習
- Deep Learning(深度學習)學習筆記整理系列深度學習筆記
- 顯示卡不是你學習 Deep Learning 的藉口
- 貝葉斯深度學習(bayesian deep learning)深度學習
- Deep Reinforcement Learning 深度增強學習資源
- Deep Learning with Differential Privacy
- 深度學習模型調優方法(Deep Learning學習記錄)深度學習模型
- Deep Learning(深度學習)學習筆記整理系列之(一)深度學習筆記
- 《深度學習》PDF Deep Learning: Adaptive Computation and Machine Learning series深度學習APTMac
- Searching with Deep Learning 深度學習的搜尋應用深度學習
- 文章學習29“Crafting a Toolchain for Image Restoration by Deep Reinforcement Learning”RaftAIREST
- 【深度學習】大牛的《深度學習》筆記,Deep Learning速成教程深度學習筆記
- Neural Networks and Deep Learning(神經網路與深度學習) - 學習筆記神經網路深度學習筆記
- 強化學習(九)Deep Q-Learning進階之Nature DQN強化學習
- 林軒田機器學習技法課程學習筆記13 — Deep Learning機器學習筆記
- Join Query Optimization with Deep Reinforcement Learning AlgorithmsGo
- [Deep Learning] 神經網路基礎神經網路
- Deep Learning 優化方法總結優化
- deep learning深度學習之學習筆記基於吳恩達coursera課程深度學習筆記吳恩達
- 剛剛,阿里開源首個深度學習框架 X-Deep Learning!阿里深度學習框架
- Deep learning:五十一(CNN的反向求導及練習)CNN求導
- 深度互學習-Deep Mutual Learning:三人行必有我師
- 林倞:Beyond Supervised Deep Learning--後深度學習時代的挑戰深度學習
- Ranked List Loss for Deep Metric Learning | 論文分享
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | TENSORSPyTorch
- Deep Transfer Learning綜述閱讀筆記筆記
- Udacity Deep Learning課程作業(一)
- Deep learning 資料彙總--持續更新
- COMP9444 Neural Networks and Deep Learning
- 「Wide & Deep Learning for Recommender Systems」- 論文摘要IDE
- DEEP LEARNING WITH PYTORCH: A 60 MINUTE BLITZ | NEURAL NETWORKSPyTorch