簡單ORACLE分割槽表、分割槽索引
本文轉自CSDN部落格http://blog.csdn.net/xieyuooo/archive/2010/03/31/5437126.aspx
ORACLE對於分割槽表方式其實就是將表分段儲存,一般普通表格是一個段儲存,而分割槽表會分成多個段,所以查詢資料過程都是先定位根據查詢條件定位分割槽範圍,即資料在那個分割槽或那幾個內部,然後在分割槽內部去查詢資料,一個分割槽一般保證四十多萬條資料就比較正常了,但是分割槽表並非亂建立,而其維護性也相對較為複雜一點,而索引的建立也是有點講究的,這些以下儘量闡述詳細即可。
1、型別說明:
range分割槽方式,也算是最常用的分割槽方式,其透過某欄位或幾個欄位的組合的值,從小到大,按照指定的範圍說明進行分割槽,我們在INSERT資料的時候就會儲存到指定的分割槽中。
List分割槽方式,一般是在range基礎上做的二級分割槽較多,是一種列舉方式進行分割槽,一般講某些地區、狀態或指定規則的編碼等進行劃分。
Hash分割槽方式,它沒有固定的規則,由ORACLE管理,只需要將值INSERT進去,ORACLE會自動去根據一套HASH演算法去劃分分割槽,只需要告訴ORACLE要分幾個區即可。
分割槽可以進行兩兩組合,ORACLE 11G以前兩兩組合都必須以range作為一級分割槽的開頭,ORACLE目前最多支援2級別分割槽,但這個級別已經夠我們使用了。
我這隻以最簡單的分割槽方式建立分割槽來說明問題,就拿range分割槽來說明問題吧(基本建立語句如下):
CREATE TABLE TABLE_PARTITION(
COL1 NUMBER,
COL2 VARCHAR2(10)
)
partition by range(COL1)(
partition TAB_PARTOTION_01 values less than (450000),
partition TAB_PARTOTION_02 values less than (900000),
partition TAB_PARTOTION_03 values less than (1350000),
partition TAB_PARTOTION_04 values less than (1800000),
partition TAB_PARTOTION_OTHER values less THAN (MAXVALUE)
);
這個分割槽表建立了四個定長分割槽,理想情況下,儲存450000條資料,擴充套件分割槽是超過這個數額的分割槽,當發現擴充套件分割槽有資料的時候,可以進行將擴充套件分割槽做SPLIT操作,這個後面說明,這裡先說一下一些常用的分割槽表查詢功能,我們先插入一些資料進去。
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(1,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(23,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(449000,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(450000,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(1350000,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(900000,'資料測試');
INSERT INTO TABLE_PARTITION(COL1,COL2)
VALUES(1800000-1,'資料測試');
COMMIT;
為了檢測哪些分割槽中有哪些資料分別按照分割槽去查詢資料(應用開發中基本不會用到,因為不會把分割槽寫死)
SQL> SELECT * FROM TABLE_PARTITION partition(TAB_PARTOTION_01);
COL1 COL2
---------- ---------------
1 資料測試
23 資料測試
449000 資料測試
說明第一個分割槽有:1、23、44900這些資料,也就是插入時,ORACLE是自己去找分割槽的,其實分割槽這種子表管理自己也可以透過程式去完成,ORACLE給你提供了一套,就可以自己去完成了。其餘的資料就自己查了,都是一個道理。
2、分割槽應用:
一般一張表超過2G的大小,ORACLE是推薦使用分割槽表的,分割槽一般都需要建立索引,說到分割槽索引,就可以分為:全域性索引、分割槽索引,即:global索引和local索引,前者為預設情況下在分割槽表上建立索引時的索引方式,並不對索引進行分割槽(索引也是表結構,索引大了也需要分割槽,關於索引以後專門寫點)而全域性索引可修飾為分割槽索引,但是和local索引有所區別,前者的分割槽方式完全按照自定義方式去建立,和表結構完全無關,所以對於分割槽表的全域性索引有以下兩幅網上常用的圖解:
2.1、對於分割槽表的不分割槽索引(這個有點繞,不過就是表分割槽,但其索引不分割槽):
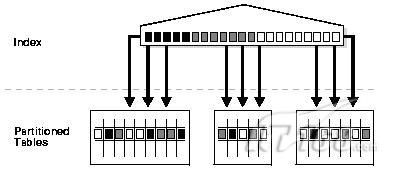
建立語法(直接建立即可):
CREATE INDEX
2.2、對於分割槽表的分割槽索引:
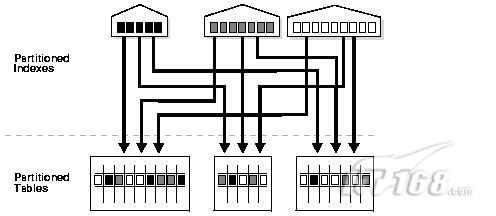
建立語法為:
CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1)
GLOBAL PARTITION BY RANGE(COL1)(
PARTITION IDX_P1 values less than (1000000),
PARTITION IDX_P2 values less than (2000000),
PARTITION IDX_P3 values less than (MAXVALUE)
);
2.3、LOCAL索引結構:
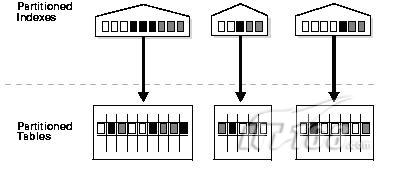
建立語法為:
CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1) LOCAL;
也可按照分割槽表的的分割槽結構給與一一定義,索引的分割槽將得到重新命名。
分割槽上的點陣圖索引只能為LOCAL索引,不能為GLOBAL全域性索引。
2.4、對比索引方式:
一般使用LOCAL索引較為方便,而且維護代價較低,並且LOCAL索引是在分割槽的基礎上去建立索引,類似於在一個子表內部去建立索引,這樣開銷主要是區分分割槽上,很規範的管理起來,在OLAP系統中應用很廣泛;而相對的GLOBAL索引是全域性型別的索引,根據實際情況可以調整分割槽的類別,而並非按照分割槽結構一一定義,相對維護代價較高一些,在OLTP環境用得相對較多,這裡所謂OLTP和OLAP也是相對的,不是特殊的專案,沒有絕對的劃分概念,在應用過程中依據實際情況而定,來提高整體的執行效能。
3、常用檢視:
1、查詢當前使用者下有哪些是分割槽表:
SELECT * FROM USER_PART_TABLES;
2、查詢當前使用者下有哪些分割槽索引:
SELECT * FROM USER_PART_INDEXES;
3、查詢當前使用者下分割槽索引的分割槽資訊:
SELECT * FROM USER_IND_PARTITIONS T
WHERE T.INDEX_NAME=?
4、查詢當前使用者下分割槽表的分割槽資訊:
SELECT * FROM USER_TAB_PARTITIONS T
WHERE T.TABLE_NAME=?;
5、查詢某分割槽下的資料量:
SELECT COUNT(*) FROM TABLE_PARTITION PARTITION(TAB_PARTOTION_01);
6、查詢索引、表上在那些列上建立了分割槽:
SELECT * FROM USER_PART_KEY_COLUMNS;
7、查詢某使用者下二級分割槽的資訊(只有建立了二級分割槽才有資料):
SELECT * FROM USER_TAB_SUBPARTITIONS;
4、維護操作:
4.1、刪除分割槽
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03;
如果是全域性索引,因為全域性索引的分割槽結構和表可以不一致,若不一致的情況下,會導致整個全域性索引失效,在刪除分割槽的時候,語句修改為:
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03 UPDATE GLOBAL INDEXES;
4.2、分割槽合併(從中間刪除掉一個分割槽,或者兩個分割槽需要合併後減少分割槽數量)
合併分割槽和刪除中間的RANGE有點像,但是合併分割槽是不會刪除資料的,對於LIST、HASH分割槽也是和RANGE分割槽不一樣的,其語法為:
ALTER TABLE TABLE_PARTITION MERGE PARTITIONS TAB_PARTOTION_01,TAB_PARTOTION_02 INTO PARTITION MERGED_PARTITION;
4.3、分隔分割槽(一般分割槽從擴充套件分割槽從分隔)
ALTER TABLE TABLE_PARTITION SPLIT PARTITION TAB_PARTOTION_OTHERE AT(2500000)
INTO (PARTITION TAB_PARTOTION_05,PARTITION TAB_PARTOTION_OTHERE);
4.4、建立新的分割槽(分割槽資料若不能提供範圍,則插入時會報錯,需要增加分割槽來擴大範圍)
一般有擴充套件分割槽的是都是用分隔的方式,若上述建立表時沒有建立TAB_PARTOTION_OTHER分割槽時,在插入資料較大時(按照上述建立規則,超過1800000就應該建立新的分割槽來儲存),就可以建立新的分割槽,如:
為了試驗,我們將擴充套件分割槽先刪除掉再建立新的分割槽(因為ORACLE要求,分割槽的資料不允許重疊,即按照分割槽欄位同樣的資料不能同時儲存在不同的分割槽中):
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_OTHER;
ALTER TABLE TABLE_PARTITION ADD PARTITION TAB_PARTOTION_06 VALUES LESS THAN(2500000);
在分割槽下建立新的子分割槽大致如下(RANGE分割槽,若為LIST或HASH分割槽,將建立方式修改為對應的方式即可):
ALTER TABLE
4.5、修改分割槽名稱(修改相關的屬性資訊)
ALTER TABLE TABLE_PARTITION RENAME PARTITION MERGED_PARTITION TO MERGED_PARTITION02;
4.6、交換分割槽(快速交換資料,其實是交換段名稱指標)
首先建立一個交換表,和原表結構相同,如果有資料,必須符合所交換對應分割槽的條件:
CREATE TABLE TABLE_PARTITION_2
AS SELECT * FROM TABLE_PARTITION WHERE 1=2;
然後將第一個分割槽的資料交換出去:
ALTER TABLE TABLE_PARTITION EXCHANGE PARTITION TAB_PARTOTION_01
WITH TABLE TABLE_PARTITION_2 INCLUDING INDEXES;
此時會發現第一個分割槽的資料和表TABLE_PARTITION_2做了瞬間交換,比TRUNCATE還要快,因為這個過程沒有進行資料轉存,只是段名稱的修改過程,和實際的資料量沒有關係。
如果是子分割槽也可以與外部的表進行交換,只需要將關鍵字修改為:SUBPARTITION 即可。
4.7、清空分割槽資料
ALTER TABLE
ALTER TABLE
9、磁碟碎片壓縮
對分割槽表的某分割槽進行磁碟壓縮,當對分割槽內部資料進行了大量的UPDATE、DELETE操作後,一定時間需要進行磁碟壓縮,否則在查詢時,若透過FULL SCAN掃描資料,將會把空塊也會掃描到,對錶進行磁碟壓縮需要進行行遷移操作,所以首先需要操作:
ALTER TABLE
對分割槽表的某分割槽壓縮語法為:
10、分割槽表重新分析以及索引重新分析
對錶進行壓縮後,需要對錶和索引進行重新分析,對錶進行重新分析,一般有兩種方式:
在ORACLE 10G以前,使用:
BEGIN
dbms_stats.gather_table_stats(USER,UPPER('
END;
ORACLE 10G後,可以使用:
ANALYZE TABLE
索引重新分析,將上述兩種方式分別修改一下,如第一種可以使用:gather_index_stats,而第二種修改為:ANALYZE INDEX即可,不過一般比較常用的是重新編譯:
對於分割槽表並進行了索引分割槽的情況,需要對每個分割槽的索引進行重新編譯,這裡以LOCAL索引為例子(其每個索引的分割槽和表分割槽結構相同,預設分割槽名稱和表分割槽名稱相同):
ALTER INDEX
對於全域性索引,根據全域性索引鎖定義的分割槽名稱修改即可,若沒有分割槽,和普通單表索引重新編譯方式相同:
ALTER INDEX
11、關聯物件重新編譯
上述對錶、索引進行重新編譯,尤其對錶進行了壓縮後會產生行遷移,這個過程可能會導致一些檢視、過程物件的失效,此時要將其重新編譯一次。
12、擴充套件:HASH分割槽中,如果建立了新的分割槽,可以將其進行重新HASH分佈:
ALTER TABLE
5、迴歸總結:何時建分割槽,分割槽類別,索引,如何對應SQL
1、建立時機
上述已經說明,2G以上的表,ORACLE推薦建立分割槽。
分割槽的方式根據實際情況而定,才能提高整體效能。
分割槽的欄位一定要是經常用以提取資料的欄位,否則會在提取過程中導致遍歷多個分割槽,這樣比沒有分割槽還要慢。
分割槽欄位要選擇合適,資料較為均勻分佈到各個分割槽,不要太多也不要太少,而且根據分割槽欄位可以很快定位到分割槽範圍。
一般情況下,儘量然業務操作在同一個分割槽內部完成。
2、分割槽類別
分割槽主要有RANGE、LIST、HASH;
RANGE透過值的範圍分割槽,也是最常用的分割槽,這種分割槽注意在一種變長數字字串中,很多人會導致認為是數字型別,而按照數字區分割槽,這樣會分佈十分不均勻的現象發生。
LIST是列舉方式進行分割槽,一般作為二級分割槽而存在(當然也可以自己分割槽,ORACLE 11G後在分割槽上也可以作為主分割槽而存在),在RANGE基礎上,若資料需要繼續分割槽,並且在RANGE基礎上資料量較為固定,只是較大,可以按照一定規則進一步分割槽。
HASH只指定分割槽個數,分割槽細節由ORACLE完成,增加HASH分割槽可以重新分佈資料。
注意:分割槽欄位不能使用函式轉換後在分割槽,如,將某數字字串欄位,先TO_NUMER(COL_NAME)後分割槽。
3、索引類別
大致分:GLOBAL索引和LOCAL索引,錢和可以分:GLOBAL不分割槽索引,和GLOBAL分割槽索引。
GLOBAL不分割槽索引一般不太推薦,因為是用一顆大的索引樹來對映一個表,這個過程,這樣速度不見得比不分割槽快。
GLOBAL分割槽索引,查詢資料若透過要透過索引,是先定位了索引內部的分割槽,然後在這個分割槽索引中找到ROWID,然後回表提取資料。
LOCAL索引是和分割槽的個數逐個對應的,可以說先定位分割槽表的分割槽也可以說先定位索引的分割槽,因為他們是一一對應的,找到對應分割槽後,分割槽內部索引資料集合。
4、對應應用
分割槽表、索引、分割槽索引,要利用其效能優勢,最基本就是要提取資料時,要透過它首先將資料的範圍縮小到一個即使做全盤掃描也不會太慢的情況。
所以SQL一定要有分割槽上的這個欄位的一個WHERE條件,將資料迅速定位到分割槽內部,而且儘量定位到一個分割槽裡面(這個和建立分割槽的規則有關係)。
建立分割槽本身不提要效能,要用好才可提高效能,在必要的RAC叢集中,若存在多分割槽提取資料,適當採用並行提取可以提高提取的速度。
對於索引部分,這裡也只提到分割槽索引的建立方式以及常見索引的維護方式,對於索引原理理解後會更容易認識到提取資料時的技巧。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/24778843/viewspace-692994/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Oracle分割槽表及分割槽索引Oracle索引
- 深入學習Oracle分割槽表及分割槽索引Oracle索引
- 全面認識oracle分割槽表及分割槽索引Oracle索引
- Oracle分割槽表基礎運維-06分割槽表索引Oracle運維索引
- Oracle帶區域性分割槽索引的分割槽表刪除舊分割槽新增新分割槽Oracle索引
- rebuild分割槽表分割槽索引的方法Rebuild索引
- 分割槽表及分割槽索引建立示例索引
- 全面學習分割槽表及分割槽索引(13)--分隔表分割槽索引
- 【學習筆記】分割槽表和分割槽索引——管理索引分割槽(四)筆記索引
- 全面學習分割槽表及分割槽索引(10)--交換分割槽索引
- 全面學習分割槽表及分割槽索引(9)--刪除表分割槽索引
- 全面學習分割槽表及分割槽索引(11)--合併表分割槽索引
- 全面學習分割槽表及分割槽索引(12)--修改list表分割槽索引
- 學習筆記】分割槽表和分割槽索引——新增表分割槽(二)筆記索引
- 全面學習分割槽表及分割槽索引(17)--其它索引分割槽管理操作索引
- Oracle索引分割槽Oracle索引
- oracle分割槽表和分割槽表exchangeOracle
- 分割槽表分割槽索引查詢效率探究索引
- 全面學習分割槽表及分割槽索引(16)--增加和刪除索引分割槽索引
- Oracle分割槽表全域性索引新增分割槽時不會失效Oracle索引
- oracle分割槽表和非分割槽表exchangeOracle
- 全面學習分割槽表及分割槽索引(1)索引
- 深入學習分割槽表及分割槽索引(1)索引
- 分割槽表、分割槽索引和全域性索引部分總結索引
- 全面學習分割槽表及分割槽索引(8)--增加和收縮表分割槽索引
- 【學習筆記】分割槽表和分割槽索引——分割槽表的其他管理(三)筆記索引
- Oracle分割槽之五:建立分割槽索引總結Oracle索引
- oracle分割槽partition及分割槽索引partition index(一)Oracle索引Index
- oracle分割槽索引(二)Oracle索引
- oracle分割槽索引(一)Oracle索引
- 全面學習分割槽表及分割槽索引(15)--修改表分割槽屬性和模板索引
- Oracle 表分割槽Oracle
- oracle分割槽表Oracle
- oracle表分割槽Oracle
- Oracle 分割槽表Oracle
- [oracle] expdp 匯出分割槽表的分割槽Oracle
- oracle 針對普通表的索引分割槽及10g新增hash 索引分割槽Oracle索引
- 【三思筆記】 全面學習Oracle分割槽表及分割槽索引筆記Oracle索引