同步阻塞迭代模型是最簡單的一種IO模型。
其核心程式碼如下:
bind(srvfd);
listen(srvfd);
for(;;){
clifd = accept(srvfd,...); //開始接受客戶端來的連線
read(clifd,buf,...); //從客戶端讀取資料
dosomthingonbuf(buf);
write(clifd,buf) //傳送資料到客戶端
}上面的程式存在如下一些弊端:- 1)如果沒有客戶端的連線請求,程式會阻塞在accept系統呼叫處,程式不能執行其他任何操作。(系統呼叫使得程式從使用者態陷入核心態,具體請參考:程式設計師的自我修養)
- 2)在與客戶端建立好一條鏈路後,通過read系統呼叫從客戶端接受資料,而客戶端合適傳送資料過來是不可控的。如果客戶端遲遲不發生資料過來,則程式同樣會阻塞在read呼叫,此時,如果另外的客戶端來嘗試連線時,都會失敗。
- 3)同樣的道理,write系統呼叫也會使得程式出現阻塞(例如:客戶端接受資料異常緩慢,導致寫緩衝區滿,資料遲遲傳送不出)。
同步阻塞迭代模型有諸多缺點。多程式併發模型在同步阻塞迭代模型的基礎上進行了一些改進,以避免是程式阻塞在read系統呼叫上。
多程式模型核心程式碼如下:
bind(srvfd);
listen(srvfd);
for(;;){
clifd = accept(srvfd,...); //開始接受客戶端來的連線
ret = fork();
switch( ret )
{
case -1 :
do_err_handler();
break;
case 0 : // 子程式
client_handler(clifd);
break ;
default : // 父程式
close(clifd);
continue ;
}
}
//======================================================
void client_handler(clifd){
read(clifd,buf,...); //從客戶端讀取資料
dosomthingonbuf(buf);
write(clifd,buf) //傳送資料到客戶端
}上述程式在accept系統呼叫時,如果沒有客戶端來建立連線,擇會阻塞在accept處。一旦某個客戶端連線建立起來,則立即開啟一個新的程式來處理與這個客戶的資料互動。避免程式阻塞在read呼叫,而影響其他客戶端的連線。3.多執行緒併發模型
在多程式併發模型中,每一個客戶端連線開啟fork一個程式,雖然linux中引入了寫實拷貝機制,大大降低了fork一個子程式的消耗,但若客戶端連線較大,則系統依然將不堪負重。通過多執行緒(或執行緒池)併發模型,可以在一定程度上改善這一問題。
在服務端的執行緒模型實現方式一般有三種:
- (1)按需生成(來一個連線生成一個執行緒)
- (2)執行緒池(預先生成很多執行緒)
- (3)Leader follower(LF)
void *thread_callback( void *args ) //執行緒回撥函式
{
int clifd = *(int *)args ;
client_handler(clifd);
}
//===============================================================
void client_handler(clifd){
read(clifd,buf,...); //從客戶端讀取資料
dosomthingonbuf(buf);
write(clifd,buf) //傳送資料到客戶端
}
//===============================================================
bind(srvfd);
listen(srvfd);
for(;;){
clifd = accept();
pthread_create(...,thread_callback,&clifd);
}服務端分為主執行緒和工作執行緒,主執行緒負責accept()連線,而工作執行緒負責處理業務邏輯和流的讀取等。因此,即使在工作執行緒阻塞的情況下,也只是阻塞線上程範圍內,對繼續接受新的客戶端連線不會有影響。
第二種實現方式,通過執行緒池的引入可以避免頻繁的建立、銷燬執行緒,能在很大程式上提升效能。但不管如何實現,多執行緒模型先天具有如下缺點:
1)穩定性相對較差。一個執行緒的崩潰會導致整個程式崩潰。
2)臨界資源的訪問控制,在加大程式複雜性的同時,鎖機制的引入會是嚴重降低程式的效能。效能上可能會出現“辛辛苦苦好幾年,一夜回到解放前”的情況。
4.IO多路複用模型之select/poll
多程式模型和多執行緒(執行緒池)模型每個程式/執行緒只能處理一路IO,在伺服器併發數較高的情況下,過多的程式/執行緒會使得伺服器效能下降。而通過多路IO複用,能使得一個程式同時處理多路IO,提升伺服器吞吐量。
在Linux支援epoll模型之前,都使用select/poll模型來實現IO多路複用。
以select為例,其核心程式碼如下:
bind(listenfd);
listen(listenfd);
FD_ZERO(&allset);
FD_SET(listenfd, &allset);
for(;;){
select(...);
if (FD_ISSET(listenfd, &rset)) { /*有新的客戶端連線到來*/
clifd = accept();
cliarray[] = clifd; /*儲存新的連線套接字*/
FD_SET(clifd, &allset); /*將新的描述符加入監聽陣列中*/
}
for(;;){ /*這個for迴圈用來檢查所有已經連線的客戶端是否由資料可讀寫*/
fd = cliarray[i];
if (FD_ISSET(fd , &rset))
dosomething();
}
}select IO多路複用同樣存在一些缺點,羅列如下:- 單個程式能夠監視的檔案描述符的數量存在最大限制,通常是1024,當然可以更改數量,但由於select採用輪詢的方式掃描檔案描述符,檔案描述符數量越多,效能越差;(在linux核心標頭檔案中,有這樣的定義:#define __FD_SETSIZE 1024)
- 核心 / 使用者空間記憶體拷貝問題,select需要複製大量的控制程式碼資料結構,產生巨大的開銷;
- select返回的是含有整個控制程式碼的陣列,應用程式需要遍歷整個陣列才能發現哪些控制程式碼發生了事件;
- select的觸發方式是水平觸發,應用程式如果沒有完成對一個已經就緒的檔案描述符進行IO操作,那麼之後每次select呼叫還是會將這些檔案描述符通知程式。
拿select模型為例,假設我們的伺服器需要支援100萬的併發連線,則在__FD_SETSIZE 為1024的情況下,則我們至少需要開闢1k個程式才能實現100萬的併發連線。除了程式間上下文切換的時間消耗外,從核心/使用者空間大量的無腦記憶體拷貝、陣列輪詢等,是系統難以承受的。因此,基於select模型的伺服器程式,要達到10萬級別的併發訪問,是一個很難完成的任務。
5.IO多路複用模型之epoll
epoll IO多路複用:一個看起來很美好的解決方案。 由於文章:高併發網路程式設計之epoll詳解中對epoll相關實現已經有詳細解決,這裡就直接摘錄過來。
由於epoll的實現機制與select/poll機制完全不同,上面所說的 select的缺點在epoll上不復存在。
設想一下如下場景:有100萬個客戶端同時與一個伺服器程式保持著TCP連線。而每一時刻,通常只有幾百上千個TCP連線是活躍的(事實上大部分場景都是這種情況)。如何實現這樣的高併發?
在select/poll時代,伺服器程式每次都把這100萬個連線告訴作業系統(從使用者態複製控制程式碼資料結構到核心態),讓作業系統核心去查詢這些套接字上是否有事件發生,輪詢完後,再將控制程式碼資料複製到使用者態,讓伺服器應用程式輪詢處理已發生的網路事件,這一過程資源消耗較大,因此,select/poll一般只能處理幾千的併發連線。
epoll的設計和實現與select完全不同。epoll通過在Linux核心中申請一個簡易的檔案系統(檔案系統一般用什麼資料結構實現?B+樹)。把原先的select/poll呼叫分成了3個部分:
- 1)呼叫epoll_create()建立一個epoll物件(在epoll檔案系統中為這個控制程式碼物件分配資源)
- 2)呼叫epoll_ctl向epoll物件中新增這100萬個連線的套接字
- 3)呼叫epoll_wait收集發生的事件的連線
下面來看看Linux核心具體的epoll機制實現思路。
當某一程式呼叫epoll_create方法時,Linux核心會建立一個eventpoll結構體,這個結構體中有兩個成員與epoll的使用方式密切相關。eventpoll結構體如下所示:
struct eventpoll{
....
/*紅黑樹的根節點,這顆樹中儲存著所有新增到epoll中的需要監控的事件*/
struct rb_root rbr;
/*雙連結串列中則存放著將要通過epoll_wait返回給使用者的滿足條件的事件*/
struct list_head rdlist;
....
};每一個epoll物件都有一個獨立的eventpoll結構體,用於存放通過epoll_ctl方法向epoll物件中新增進來的事件。這些事件都會掛載在紅黑樹中,如此,重複新增的事件就可以通過紅黑樹而高效的識別出來(紅黑樹的插入時間效率是lgn,其中n為樹的高度)。而所有新增到epoll中的事件都會與裝置(網路卡)驅動程式建立回撥關係,也就是說,當相應的事件發生時會呼叫這個回撥方法。這個回撥方法在核心中叫ep_poll_callback,它會將發生的事件新增到rdlist雙連結串列中。
在epoll中,對於每一個事件,都會建立一個epitem結構體,如下所示:
struct epitem{
struct rb_node rbn;//紅黑樹節點
struct list_head rdllink;//雙向連結串列節點
struct epoll_filefd ffd; //事件控制程式碼資訊
struct eventpoll *ep; //指向其所屬的eventpoll物件
struct epoll_event event; //期待發生的事件型別
}當呼叫epoll_wait檢查是否有事件發生時,只需要檢查eventpoll物件中的rdlist雙連結串列中是否有epitem元素即可。如果rdlist不為空,則把發生的事件複製到使用者態,同時將事件數量返回給使用者。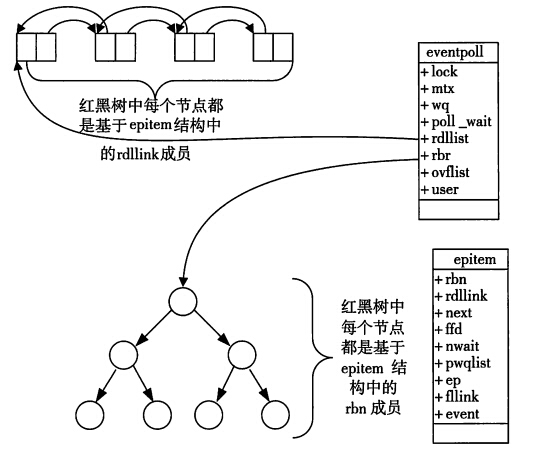
epoll資料結構示意圖
從上面的講解可知:通過紅黑樹和雙連結串列資料結構,並結合回撥機制,造就了epoll的高效。
OK,講解完了Epoll的機理,我們便能很容易掌握epoll的用法了。一句話描述就是:三步曲。
第一步:epoll_create()系統呼叫。此呼叫返回一個控制程式碼,之後所有的使用都依靠這個控制程式碼來標識。
第二步:epoll_ctl()系統呼叫。通過此呼叫向epoll物件中新增、刪除、修改感興趣的事件,返回0標識成功,返回-1表示失敗。
第三部:epoll_wait()系統呼叫。通過此呼叫收集收集在epoll監控中已經發生的事件。
最後,附上一個epoll程式設計例項。(此程式碼作者為sparkliang)
//
// a simple echo server using epoll in linux
//
// 2009-11-05
// 2013-03-22:修改了幾個問題,1是/n格式問題,2是去掉了原始碼不小心加上的ET模式;
// 本來只是簡單的示意程式,決定還是加上 recv/send時的buffer偏移
// by sparkling
//
#include <sys/socket.h>
#include <sys/epoll.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
#include <iostream>
using namespace std;
#define MAX_EVENTS 500
struct myevent_s
{
int fd;
void (*call_back)(int fd, int events, void *arg);
int events;
void *arg;
int status; // 1: in epoll wait list, 0 not in
char buff[128]; // recv data buffer
int len, s_offset;
long last_active; // last active time
};
// set event
void EventSet(myevent_s *ev, int fd, void (*call_back)(int, int, void*), void *arg)
{
ev->fd = fd;
ev->call_back = call_back;
ev->events = 0;
ev->arg = arg;
ev->status = 0;
bzero(ev->buff, sizeof(ev->buff));
ev->s_offset = 0;
ev->len = 0;
ev->last_active = time(NULL);
}
// add/mod an event to epoll
void EventAdd(int epollFd, int events, myevent_s *ev)
{
struct epoll_event epv = {0, {0}};
int op;
epv.data.ptr = ev;
epv.events = ev->events = events;
if(ev->status == 1){
op = EPOLL_CTL_MOD;
}
else{
op = EPOLL_CTL_ADD;
ev->status = 1;
}
if(epoll_ctl(epollFd, op, ev->fd, &epv) < 0)
printf("Event Add failed[fd=%d], evnets[%d]\n", ev->fd, events);
else
printf("Event Add OK[fd=%d], op=%d, evnets[%0X]\n", ev->fd, op, events);
}
// delete an event from epoll
void EventDel(int epollFd, myevent_s *ev)
{
struct epoll_event epv = {0, {0}};
if(ev->status != 1) return;
epv.data.ptr = ev;
ev->status = 0;
epoll_ctl(epollFd, EPOLL_CTL_DEL, ev->fd, &epv);
}
int g_epollFd;
myevent_s g_Events[MAX_EVENTS+1]; // g_Events[MAX_EVENTS] is used by listen fd
void RecvData(int fd, int events, void *arg);
void SendData(int fd, int events, void *arg);
// accept new connections from clients
void AcceptConn(int fd, int events, void *arg)
{
struct sockaddr_in sin;
socklen_t len = sizeof(struct sockaddr_in);
int nfd, i;
// accept
if((nfd = accept(fd, (struct sockaddr*)&sin, &len)) == -1)
{
if(errno != EAGAIN && errno != EINTR)
{
}
printf("%s: accept, %d", __func__, errno);
return;
}
do
{
for(i = 0; i < MAX_EVENTS; i++)
{
if(g_Events[i].status == 0)
{
break;
}
}
if(i == MAX_EVENTS)
{
printf("%s:max connection limit[%d].", __func__, MAX_EVENTS);
break;
}
// set nonblocking
int iret = 0;
if((iret = fcntl(nfd, F_SETFL, O_NONBLOCK)) < 0)
{
printf("%s: fcntl nonblocking failed:%d", __func__, iret);
break;
}
// add a read event for receive data
EventSet(&g_Events[i], nfd, RecvData, &g_Events[i]);
EventAdd(g_epollFd, EPOLLIN, &g_Events[i]);
}while(0);
printf("new conn[%s:%d][time:%d], pos[%d]\n", inet_ntoa(sin.sin_addr),
ntohs(sin.sin_port), g_Events[i].last_active, i);
}
// receive data
void RecvData(int fd, int events, void *arg)
{
struct myevent_s *ev = (struct myevent_s*)arg;
int len;
// receive data
len = recv(fd, ev->buff+ev->len, sizeof(ev->buff)-1-ev->len, 0);
EventDel(g_epollFd, ev);
if(len > 0)
{
ev->len += len;
ev->buff[len] = '\0';
printf("C[%d]:%s\n", fd, ev->buff);
// change to send event
EventSet(ev, fd, SendData, ev);
EventAdd(g_epollFd, EPOLLOUT, ev);
}
else if(len == 0)
{
close(ev->fd);
printf("[fd=%d] pos[%d], closed gracefully.\n", fd, ev-g_Events);
}
else
{
close(ev->fd);
printf("recv[fd=%d] error[%d]:%s\n", fd, errno, strerror(errno));
}
}
// send data
void SendData(int fd, int events, void *arg)
{
struct myevent_s *ev = (struct myevent_s*)arg;
int len;
// send data
len = send(fd, ev->buff + ev->s_offset, ev->len - ev->s_offset, 0);
if(len > 0)
{
printf("send[fd=%d], [%d<->%d]%s\n", fd, len, ev->len, ev->buff);
ev->s_offset += len;
if(ev->s_offset == ev->len)
{
// change to receive event
EventDel(g_epollFd, ev);
EventSet(ev, fd, RecvData, ev);
EventAdd(g_epollFd, EPOLLIN, ev);
}
}
else
{
close(ev->fd);
EventDel(g_epollFd, ev);
printf("send[fd=%d] error[%d]\n", fd, errno);
}
}
void InitListenSocket(int epollFd, short port)
{
int listenFd = socket(AF_INET, SOCK_STREAM, 0);
fcntl(listenFd, F_SETFL, O_NONBLOCK); // set non-blocking
printf("server listen fd=%d\n", listenFd);
EventSet(&g_Events[MAX_EVENTS], listenFd, AcceptConn, &g_Events[MAX_EVENTS]);
// add listen socket
EventAdd(epollFd, EPOLLIN, &g_Events[MAX_EVENTS]);
// bind & listen
sockaddr_in sin;
bzero(&sin, sizeof(sin));
sin.sin_family = AF_INET;
sin.sin_addr.s_addr = INADDR_ANY;
sin.sin_port = htons(port);
bind(listenFd, (const sockaddr*)&sin, sizeof(sin));
listen(listenFd, 5);
}
int main(int argc, char **argv)
{
unsigned short port = 12345; // default port
if(argc == 2){
port = atoi(argv[1]);
}
// create epoll
g_epollFd = epoll_create(MAX_EVENTS);
if(g_epollFd <= 0) printf("create epoll failed.%d\n", g_epollFd);
// create & bind listen socket, and add to epoll, set non-blocking
InitListenSocket(g_epollFd, port);
// event loop
struct epoll_event events[MAX_EVENTS];
printf("server running:port[%d]\n", port);
int checkPos = 0;
while(1){
// a simple timeout check here, every time 100, better to use a mini-heap, and add timer event
long now = time(NULL);
for(int i = 0; i < 100; i++, checkPos++) // doesn't check listen fd
{
if(checkPos == MAX_EVENTS) checkPos = 0; // recycle
if(g_Events[checkPos].status != 1) continue;
long duration = now - g_Events[checkPos].last_active;
if(duration >= 60) // 60s timeout
{
close(g_Events[checkPos].fd);
printf("[fd=%d] timeout[%d--%d].\n", g_Events[checkPos].fd, g_Events[checkPos].last_active, now);
EventDel(g_epollFd, &g_Events[checkPos]);
}
}
// wait for events to happen
int fds = epoll_wait(g_epollFd, events, MAX_EVENTS, 1000);
if(fds < 0){
printf("epoll_wait error, exit\n");
break;
}
for(int i = 0; i < fds; i++){
myevent_s *ev = (struct myevent_s*)events[i].data.ptr;
if((events[i].events&EPOLLIN)&&(ev->events&EPOLLIN)) // read event
{
ev->call_back(ev->fd, events[i].events, ev->arg);
}
if((events[i].events&EPOLLOUT)&&(ev->events&EPOLLOUT)) // write event
{
ev->call_back(ev->fd, events[i].events, ev->arg);
}
}
}
// free resource
return 0;
}作者:快課網——Jay13參考:《深入理解Nginx》
來自:快課網
相關閱讀
評論(1)