MySQL訂單分庫分表多維度查詢
MySQL分庫分表,一般只能按照一個維度進行查詢.
以訂單表為例, 按照使用者ID mod 64 分成 64個資料庫.
按照使用者的維度查詢很快,因為最終的查詢落在一臺伺服器上.
但是如果按照商戶的維度查詢,則代價非常高.
需要查詢全部64臺伺服器.
在分頁的情況下,更加惡化.
比如某個商戶查詢第10頁的資料(按照訂單的建立時間).需要在每臺資料庫伺服器上查詢前100條資料,程式收到 64*100 條資料,然後按照訂單的建立時間排序,擷取排名90-100號的10條記錄返回,然後拋棄其餘的6390條記錄.如果查詢的是第100頁,第1000頁,則對資料庫IO,網路,中介軟體CPU,都是不小的壓力.
分庫分表之後,為了應對多維度查詢,很多情況下會引入冗餘.
比如兩個叢集,一個按照使用者ID分庫分表,另外一個按照商戶ID分庫分表.
這樣多維度查詢的時候,各查各的.
但是有幾個問題,一樣不好解決.
比如,
每擴充套件一個維度,就需要引入一個叢集.
叢集間的資料,如何保證一致性.
冗餘佔用大量磁碟空間.
從朋友那裡看到的訂單表結構.做冗餘會佔用大量的磁碟空間.
可以試試用表代替索引的方法.
1.分庫分表
2.最終一致性
3.用表代替索引的功能
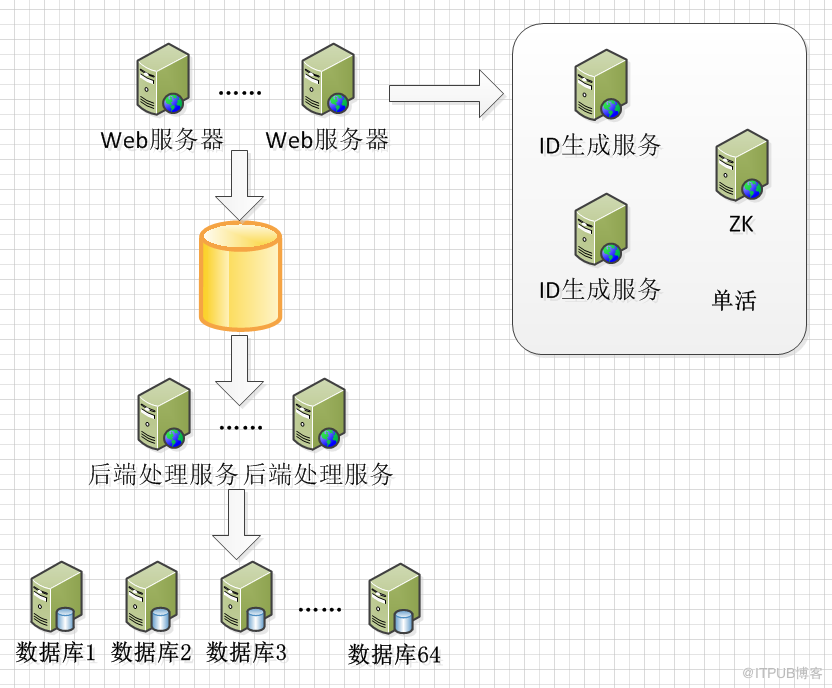
首先,還是基於分庫分表.訂單表按照使用者ID mod 64 分到不同的伺服器上(按照查詢最多的維度分)。
資料庫伺服器1 的資料庫名稱為 db_1
資料庫伺服器2 的資料庫名稱為 db_2
...
以db_1為例,建立如下表
1.訂單表
TS_ORDER_1 分割槽表,每個月一個分割槽.
2.事務表
create table tran_log_1(
tran_id bigint primary key,
param varchar(2000)
);
分割槽表,每個月一個分割槽.
3.訊息表
create table msg_log_1(
tran_id bigint,
shardKey varchar(20) not null,
primary key(tran_id,shardKey)
);
分割槽表,每個月一個分割槽.
4.維度索引表
create table shard_shop_1(
id bigint primary key auto_increment,
shopid int,
ts timestamp,
state int,
dbid int,
orderid bigint,
index(shopid,ts,state)
);
分割槽表,每個月一個分割槽.
關於使用事務表,訊息表實現分庫分表最終一致性請參考
http://blog.itpub.net/29254281/viewspace-1819422/
關於叢集主鍵生成服務請參考
http://blog.itpub.net/29254281/viewspace-1811711/
訂單建立的流程
Web伺服器接收到使用者訂單,首先透過RPC獲取一個事務ID(tran_id).
用事務ID mod 64 找到資料庫伺服器,
將事務ID,引數寫入tran_log 表,
然後將事務ID,引數寫入訊息佇列.
如果寫入訊息佇列成功,則提交事務.否則回滾事務.
此時就可以返回使用者介面.
後端處理服務收到訊息佇列的資訊,首先查詢tran_log 表,是否存在這個事務ID,如果不存在則不予處理.
然後將佇列的訊息,分為兩個維度分別處理,一個是使用者維度,一個是商戶維度.
作為使用者維度,
先根據使用者ID mod 64 找到最終落地的資料庫,查詢那個資料庫的訊息表msg_log,在使用者維度,是否存在這個事務ID,如果存在,則不予處理.
(select count(*) from msg_log_XX where shardKey='訂單建立:使用者維度' and tran_id=?)
如果不存在,則開啟一個事務
插入訂單表,我覺得可以用tran_id直接作為訂單的ID,
並且插入訊息表 insert msg_log_XX(tran_id,shardKey) values(?,'訂單建立:使用者維度');
提交事務,commit.
作為商戶維度,
則根據商戶ID mod 64 找到最終的資料庫,和使用者維度的資料庫,可能不是同一臺伺服器.
同樣,也是先查詢落地資料庫的訊息表,
(select count(*) from msg_log_XXX where shardKey='訂單建立:商戶維度' and tran_id=?)
如果不存在記錄,則開啟事務,
插入維度索引表,
insert into shard_shop_XXX(shopid,ts,state,dbid,orderid) values(......)
shopid,ts,state 商戶ID,訂單時間,訂單狀態都是根據訂單的原始資訊.
dbid 指的是 根據使用者維度(主維度),訂單資料所在的資料庫ID,
orderid 指的是 在使用者維度(主維度),訂單表的主鍵.
插入訊息表,insert msg_log_XX(tran_id,shardKey) values(?,'訂單建立:商戶維度');
最後提交.
這樣,作為商戶維度查詢的時候,先根據商戶的ID mod 64 找到 維度索引表,獲取該商戶的訂單資訊
select * from shard_shop_1 where shopid=? and state=2 order by ts limit 300,10;
獲取的資訊可能如下
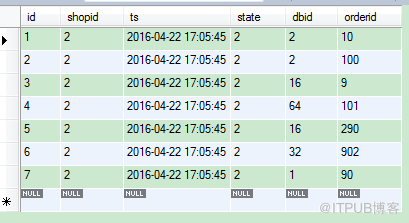
可以看到,符合條件的訂單資訊,分別來自 伺服器1,2,16,32,64
獲取了這部分資訊,就可以直接去這些伺服器上取資料,並且是主鍵查詢,速度很快.
每隔一段時間,由後臺程式,檢視 tran_log和msg_log,如果發現有缺失的資料,則進行事務補償.
擴充套件的時候,則新增維度索引表即可.
因為所有的表,都是按月的分割槽表,可以將過去的冷資料,在一個伺服器集中存放,這個例項就同時存放64個資料庫.畢竟都是冷資料,訪問量很小.
能分還要能合.比如:


以訂單表為例, 按照使用者ID mod 64 分成 64個資料庫.
按照使用者的維度查詢很快,因為最終的查詢落在一臺伺服器上.
但是如果按照商戶的維度查詢,則代價非常高.
需要查詢全部64臺伺服器.
在分頁的情況下,更加惡化.
比如某個商戶查詢第10頁的資料(按照訂單的建立時間).需要在每臺資料庫伺服器上查詢前100條資料,程式收到 64*100 條資料,然後按照訂單的建立時間排序,擷取排名90-100號的10條記錄返回,然後拋棄其餘的6390條記錄.如果查詢的是第100頁,第1000頁,則對資料庫IO,網路,中介軟體CPU,都是不小的壓力.
分庫分表之後,為了應對多維度查詢,很多情況下會引入冗餘.
比如兩個叢集,一個按照使用者ID分庫分表,另外一個按照商戶ID分庫分表.
這樣多維度查詢的時候,各查各的.
但是有幾個問題,一樣不好解決.
比如,
每擴充套件一個維度,就需要引入一個叢集.
叢集間的資料,如何保證一致性.
冗餘佔用大量磁碟空間.
從朋友那裡看到的訂單表結構.做冗餘會佔用大量的磁碟空間.
- create table TS_ORDER
- (
- ORDER_ID NUMBER(8) not null,
- SN VARCHAR2(50),
- MEMBER_ID NUMBER(8),
- STATUS NUMBER(2),
- PAY_STATUS NUMBER(2),
- SHIP_STATUS NUMBER(2),
- SHIPPING_ID NUMBER(8),
- SHIPPING_TYPE VARCHAR2(255),
- SHIPPING_AREA VARCHAR2(255),
- PAYMENT_ID NUMBER(8),
- PAYMENT_NAME VARCHAR2(50),
- PAYMENT_TYPE VARCHAR2(50),
- PAYMONEY NUMBER(20,2),
- CREATE_TIME NUMBER(20) not null,
- SHIP_NAME VARCHAR2(255),
- SHIP_ADDR VARCHAR2(255),
- SHIP_ZIP VARCHAR2(20),
- SHIP_EMAIL VARCHAR2(50),
- SHIP_MOBILE VARCHAR2(50),
- SHIP_TEL VARCHAR2(50),
- SHIP_DAY VARCHAR2(255),
- SHIP_TIME VARCHAR2(255),
- IS_PROTECT VARCHAR2(1),
- PROTECT_PRICE NUMBER(20,2),
- GOODS_AMOUNT NUMBER(20,2),
- SHIPPING_AMOUNT NUMBER(20,2),
- ORDER_AMOUNT NUMBER(20,2),
- WEIGHT NUMBER(20,2),
- GOODS_NUM NUMBER(8),
- GAINEDPOINT NUMBER(11) default 0,
- CONSUMEPOINT NUMBER(11) default 0,
- DISABLED VARCHAR2(1),
- DISCOUNT NUMBER(20,2),
- IMPORTED NUMBER(2) default 0,
- PIMPORTED NUMBER(2) default 0,
- COMPLETE_TIME NUMBER(11) default 0,
- CANCEL_REASON VARCHAR2(255),
- SIGNING_TIME NUMBER(11),
- THE_SIGN VARCHAR2(255),
- ALLOCATION_TIME NUMBER(11),
- SHIP_PROVINCEID NUMBER(11),
- SHIP_CITYID NUMBER(11),
- SHIP_REGIONID NUMBER(11),
- SALE_CMPL NUMBER(2),
- SALE_CMPL_TIME NUMBER(11),
- DEPOTID NUMBER(11),
- ADMIN_REMARK VARCHAR2(1000),
- COMPANY_CODE VARCHAR2(32),
- PARENT_SN VARCHAR2(50),
- REMARK VARCHAR2(100),
- GOODS CLOB,
- ORIGINAL_AMOUNT NUMBER(20,2),
- IS_ONLINE CHAR(1),
- IS_COMMENTED CHAR(1) default 0,
- ORDER_FLAG CHAR(1) default 1
- )
可以試試用表代替索引的方法.
1.分庫分表
2.最終一致性
3.用表代替索引的功能
首先,還是基於分庫分表.訂單表按照使用者ID mod 64 分到不同的伺服器上(按照查詢最多的維度分)。
資料庫伺服器1 的資料庫名稱為 db_1
資料庫伺服器2 的資料庫名稱為 db_2
...
以db_1為例,建立如下表
1.訂單表
TS_ORDER_1 分割槽表,每個月一個分割槽.
2.事務表
create table tran_log_1(
tran_id bigint primary key,
param varchar(2000)
);
分割槽表,每個月一個分割槽.
3.訊息表
create table msg_log_1(
tran_id bigint,
shardKey varchar(20) not null,
primary key(tran_id,shardKey)
);
分割槽表,每個月一個分割槽.
4.維度索引表
create table shard_shop_1(
id bigint primary key auto_increment,
shopid int,
ts timestamp,
state int,
dbid int,
orderid bigint,
index(shopid,ts,state)
);
分割槽表,每個月一個分割槽.
關於使用事務表,訊息表實現分庫分表最終一致性請參考
http://blog.itpub.net/29254281/viewspace-1819422/
關於叢集主鍵生成服務請參考
http://blog.itpub.net/29254281/viewspace-1811711/
訂單建立的流程
Web伺服器接收到使用者訂單,首先透過RPC獲取一個事務ID(tran_id).
用事務ID mod 64 找到資料庫伺服器,
將事務ID,引數寫入tran_log 表,
然後將事務ID,引數寫入訊息佇列.
如果寫入訊息佇列成功,則提交事務.否則回滾事務.
此時就可以返回使用者介面.
後端處理服務收到訊息佇列的資訊,首先查詢tran_log 表,是否存在這個事務ID,如果不存在則不予處理.
然後將佇列的訊息,分為兩個維度分別處理,一個是使用者維度,一個是商戶維度.
作為使用者維度,
先根據使用者ID mod 64 找到最終落地的資料庫,查詢那個資料庫的訊息表msg_log,在使用者維度,是否存在這個事務ID,如果存在,則不予處理.
(select count(*) from msg_log_XX where shardKey='訂單建立:使用者維度' and tran_id=?)
如果不存在,則開啟一個事務
插入訂單表,我覺得可以用tran_id直接作為訂單的ID,
並且插入訊息表 insert msg_log_XX(tran_id,shardKey) values(?,'訂單建立:使用者維度');
提交事務,commit.
作為商戶維度,
則根據商戶ID mod 64 找到最終的資料庫,和使用者維度的資料庫,可能不是同一臺伺服器.
同樣,也是先查詢落地資料庫的訊息表,
(select count(*) from msg_log_XXX where shardKey='訂單建立:商戶維度' and tran_id=?)
如果不存在記錄,則開啟事務,
插入維度索引表,
insert into shard_shop_XXX(shopid,ts,state,dbid,orderid) values(......)
shopid,ts,state 商戶ID,訂單時間,訂單狀態都是根據訂單的原始資訊.
dbid 指的是 根據使用者維度(主維度),訂單資料所在的資料庫ID,
orderid 指的是 在使用者維度(主維度),訂單表的主鍵.
插入訊息表,insert msg_log_XX(tran_id,shardKey) values(?,'訂單建立:商戶維度');
最後提交.
這樣,作為商戶維度查詢的時候,先根據商戶的ID mod 64 找到 維度索引表,獲取該商戶的訂單資訊
select * from shard_shop_1 where shopid=? and state=2 order by ts limit 300,10;
獲取的資訊可能如下
可以看到,符合條件的訂單資訊,分別來自 伺服器1,2,16,32,64
獲取了這部分資訊,就可以直接去這些伺服器上取資料,並且是主鍵查詢,速度很快.
每隔一段時間,由後臺程式,檢視 tran_log和msg_log,如果發現有缺失的資料,則進行事務補償.
擴充套件的時候,則新增維度索引表即可.
因為所有的表,都是按月的分割槽表,可以將過去的冷資料,在一個伺服器集中存放,這個例項就同時存放64個資料庫.畢竟都是冷資料,訪問量很小.
能分還要能合.比如:
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/29254281/viewspace-2086198/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 分庫分表後的分頁查詢
- SQL 單表多條記錄分組查詢分頁程式碼SQL
- 10億級別訂單的分庫分表方案
- MySQL分庫分表MySql
- [Mysql]分庫分表MySql
- 億萬級分庫分表後如何進行跨表分頁查詢
- 百億級資料 分庫分表 後怎麼分頁查詢?
- Mysql分庫分表方案MySql
- 【Mysql】OneProxy分庫分表MySql
- MySQL運維9-Mycat分庫分表之列舉分片MySql運維
- 資料庫全表查詢之-分頁查詢優化資料庫優化
- MySQL單表查詢MySql
- MySQL 單表查詢MySql
- MySQL的分頁查詢MySql
- MySQL 多表查詢分頁MySql
- MySQL運維12-Mycat分庫分表之按天分片MySql運維
- 多對多關係自行維護單項關聯數量,加快分頁查詢
- 徹底搞清MySQL分庫分表(垂直分庫,垂直分表,水平分庫,水平分表)MySql
- [Mysql 查詢語句]——分組查詢group byMySql
- 3.1 MYSQL分庫分表實踐MySql
- MySQL分庫分表的原則MySql
- MySQL全面瓦解28:分庫分表MySql
- MySQL運維11-Mycat分庫分表之應用指定分片MySql運維
- MySQL分頁查詢優化MySql優化
- Java資料庫分表與多執行緒查詢結果彙總Java資料庫執行緒
- Linux MySQL分庫分表之MycatLinuxMySql
- MySql分表、分庫、分片和分割槽MySql
- MySQL分庫分表總結參考MySql
- Mysql-基本練習(09-刪除單表記錄、查詢指定列資料、列的別名、簡單單表條件查詢、簡單分組查詢)MySql
- 資料庫分類統計、分組查詢資料庫
- mysql三表連線查詢以及百分數排序MySql排序
- MySQL——優化巢狀查詢和分頁查詢MySql優化巢狀
- mysql-分組查詢-子查詢-連線查詢-組合查詢MySql
- Oracle和MySQL分組查詢GROUP BYOracleMySql
- MYSQL效能最佳化分享(分庫分表)MySql
- MySQL 分庫分表方案,總結太全了。。MySql
- 分庫分表系列:分庫分表的前世今生
- MySql、SqlServer、Oracle 三種資料庫查詢分頁方式MySqlServerOracle資料庫