CentOS7下搭建hadoop2.7.3完全分散式
這裡搭建的是3個節點的完全分散式,即1個nameNode,2個dataNode,分別如下:
CentOS-master nameNode 192.168.11.128
CentOS-node1 dataNode 192.168.11.131
CentOS-node2 dataNode 192.168..11.132
1.首先建立好一個CentOS虛擬機器,將它作為主節點我這裡起名為CentOS-master,起什麼都行,不固定要求

2.VMware中開啟虛擬機器,輸入java -version,檢查是否有JDK環境,不要用系統自帶的openJDK版本,要自己安裝的版本

3.輸入 systemctl status firewalld.service ,若如圖,防火牆處於running狀態,則執行第4和第5步,否則直接進入第6步
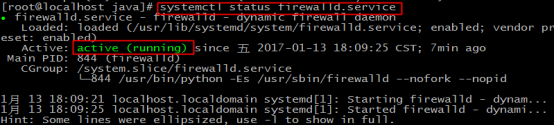
4.輸入 systemctl stop firewalld.service ,關閉防火牆

5.輸入 systemctl disable firewalld.service ,禁用防火牆

6.輸入 mkdir /usr/local/hadoop 建立一個hadoop的資料夾

7.將hadoop的tar包放到剛建立好的目錄

8.進入hadoop目錄,輸入 tar -zxvf hadoop-2.7.3.tar.gz 解壓tar包

9.輸入 vi /etc/profile ,配置環境變數

10.加入如下內容,儲存並退出
HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3/
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
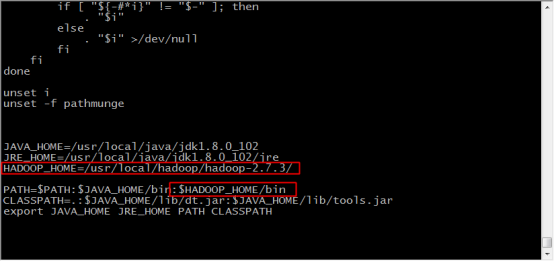
11.輸入 . /etc/profile ,使環境變數生效

12.任意目錄輸入 hado ,然後按Tab,如果自動補全為hadoop,則說明環境變數配的沒問題,否則檢查環境變數哪出錯了

13.建立3個之後要用到的資料夾,分別如下:
mkdir /usr/local/hadoop/tmp

mkdir -p /usr/local/hadoop/hdfs/name

mkdir /usr/local/hadoop/hdfs/data
14.進入hadoop解壓後的 /etc/hadoop 目錄,裡面存放的是hadoop的配置檔案,接下來要修改這裡面一些配置檔案
15.有2個.sh檔案,需要指定一下JAVA的目錄,首先輸入 vi hadoop-env.sh 修改配置檔案

16.將原有的JAVA_HOME註釋掉,根據自己的JDK安裝位置,精確配置JAVA_HOME如下,儲存並退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102/
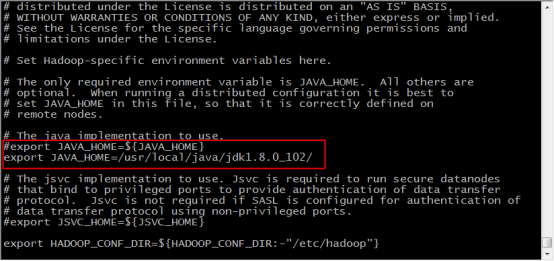
17.輸入 vi yarn-env.sh 修改配置檔案

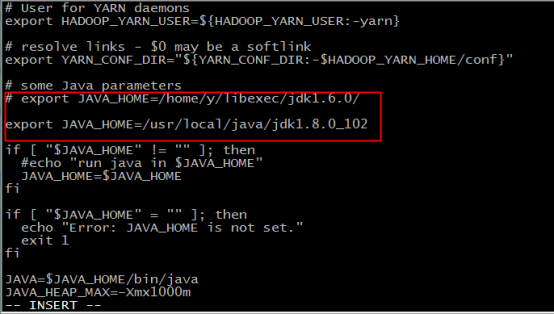
18.加入如下內容,指定JAVA_HOME,儲存並退出
export JAVA_HOME=/usr/local/java/jdk1.8.0_102
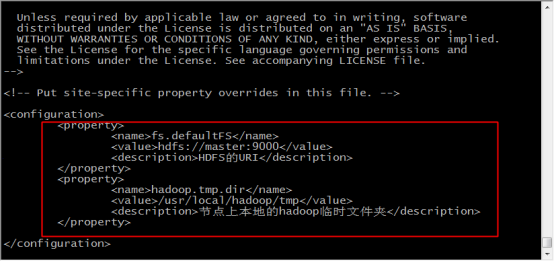
19.輸入 vi core-site.xml 修改配置檔案

20.在configuration標籤中,新增如下內容,儲存並退出,注意這裡配置的hdfs:master:9000是不能在瀏覽器訪問的
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的預設名稱</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>節點上本地的hadoop臨時資料夾</description>
</property>
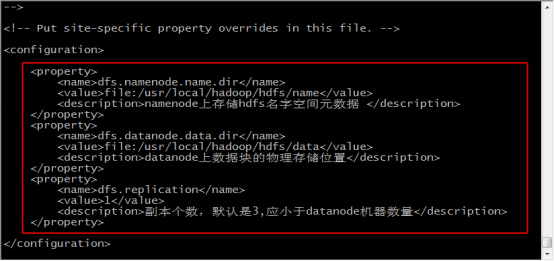
21.輸入 vi hdfs-site.xml 修改配置檔案

22.在configuration標籤中,新增如下內容,儲存並退出
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
<description>namenode上儲存hdfs名字空間後設資料 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
<description>datanode上資料塊的物理儲存位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本個數,預設是3,應小於datanode機器數量</description>
</property>
23.輸入 cp mapred-site.xml.template mapred-site.xml 將mapred-site.xml.template檔案複製到當前目錄,並重新命名為mapred-site.xml

24.輸入 vi mapred-site.xml 修改配置檔案

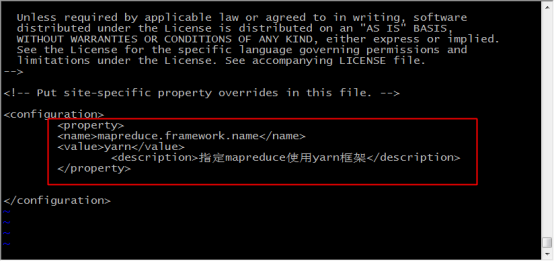
25.在configuration標籤中,新增如下內容,儲存並退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
26.輸入 vi yarn-site.xml 修改配置檔案

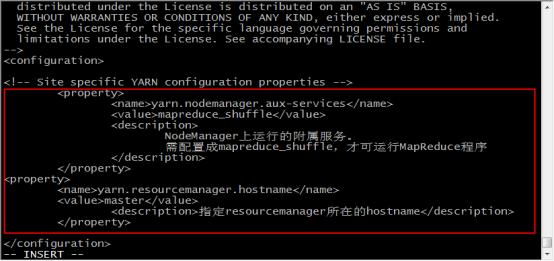
27.在configuration標籤中,新增如下內容,儲存並退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>
NodeManager上執行的附屬服務。
需配置成mapreduce_shuffle,才可執行MapReduce程式
</description>
</property>
28.輸入 vi slaves 修改配置檔案

29.將localhost刪掉,加入如下內容,即dataNode節點的主機名
node1
node2

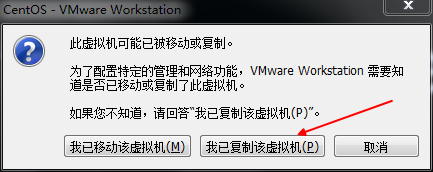
30.將虛擬機器關閉,再複製兩份虛擬機器,重新命名為如下,注意這裡一定要關閉虛擬機器,再複製

31.將3臺虛擬機器都開啟,後兩臺複製的虛擬機器開啟時,都選擇“我已複製該虛擬機器”
32.在master機器上,輸入 vi /etc/hostname,將localhost改為master,儲存並退出
33.在node1機器上,輸入 vi /etc/hostname,將localhost改為node1,儲存並退出
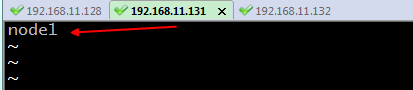
34.在node2機器上,輸入 vi /etc/hostname,將localhost改為node2,儲存並退出
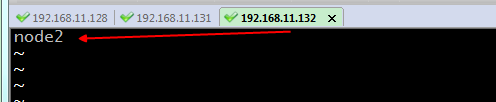
35.在三臺機器分別輸入 vi /etc/hosts 修改檔案,其作用是將一些常用的網址域名與其對應的IP地址建立一個關聯,當使用者在訪問網址時,系統會首先自動從Hosts檔案中尋找對應的IP地址
36.三個檔案中都加入如下內容,儲存並退出,注意這裡要根據自己實際IP和節點主機名進行更改,IP和主機名中間要有一個空格
192.168.11.128 master
192.168.11.131 node1
192.168.11.132 node2
37.在master機器上輸入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 建立一個無密碼的公鑰,-t是型別的意思,dsa是生成的金鑰型別,-P是密碼,’’表示無密碼,-f後是秘鑰生成後儲存的位置

38.在master機器上輸入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 將公鑰id_dsa.pub新增進keys,這樣就可以實現無密登陸ssh

39.在master機器上輸入 ssh master 測試免密碼登陸

如果有詢問,則輸入 yes ,回車

40.在node1主機上執行 mkdir ~/.ssh
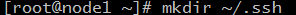
41.在node2主機上執行 mkdir ~/.ssh
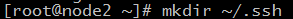
42.在master機器上輸入 scp ~/.ssh/authorized_keys root@node1:~/.ssh/authorized_keys 將主節點的公鑰資訊匯入node1節點,匯入時要輸入一下node1機器的登陸密碼

43.在master機器上輸入 scp ~/.ssh/authorized_keys root@node2:~/.ssh/authorized_keys 將主節點的公鑰資訊匯入node2節點,匯入時要輸入一下node2機器的登陸密碼

44.在三臺機器上分別執行 chmod 600 ~/.ssh/authorized_keys 賦予金鑰檔案許可權

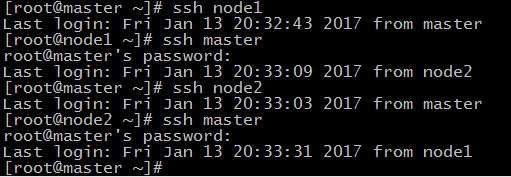
45.在master節點上分別輸入 ssh node1 和 ssh node2 測試是否配置ssh成功
46.如果node節點還沒有hadoop,則master機器上分別輸入如下命令將hadoop複製
scp -r /usr/local/hadoop/ root@node1:/usr/local/
scp -r /usr/local/hadoop/ root@node2:/usr/local/
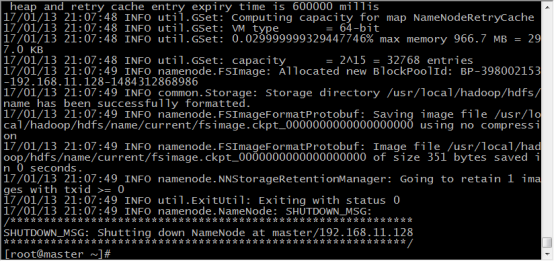
47.在master機器上,任意目錄輸入 hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之後就不用再格式化,如果改一些配置檔案了,可能還需要再次格式化

48.格式化完成
49.在master機器上,進入hadoop的sbin目錄,輸入 ./start-all.sh 啟動hadoop
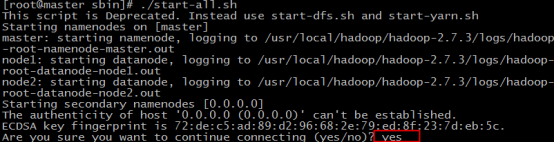
50.輸入yes,回車
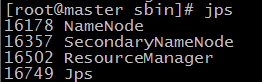
51.輸入 jps 檢視當前java的程式,該命令是JDK1.5開始有的,作用是列出當前java程式的PID和Java主類名,nameNode節點除了JPS,還有3個程式,啟動成功
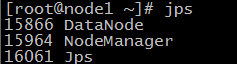
52.在node1機器和node2機器上分別輸入 jps 檢視程式如下,說明配置成功
53.在瀏覽器訪問nameNode節點的8088埠和50070埠可以檢視hadoop的執行狀況
54.在master機器上,進入hadoop的sbin目錄,輸入 ./stop-all.sh 關閉hadoop
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31383567/viewspace-2144196/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Zookeeper — 本地完全分散式 搭建分散式
- Hbase完全分散式的搭建分散式
- hadoop完全分散式環境搭建Hadoop分散式
- Hadoop hdfs完全分散式搭建教程Hadoop分散式
- Hadoop3.x完全分散式搭建(詳細)Hadoop分散式
- Centos7搭建hadoop3.3.4分散式叢集CentOSHadoop分散式
- Hadoop完全分散式叢集配置Hadoop分散式
- 分散式配置nacos搭建踩坑指南(下)分散式
- centos7 hadoop3.2.0分散式叢集搭建步驟CentOSHadoop分散式
- CentOS7 hadoop3.3.1安裝(單機分散式、偽分散式、分散式)CentOSHadoop分散式
- CentOS7下搭建JumpServerCentOSServer
- Storm-1.2.2完全分散式安裝ORM分散式
- Hadoop框架:叢集模式下分散式環境搭建Hadoop框架模式分散式
- centOS 7-Hadoop3.3.0完全分散式部署CentOSHadoop分散式
- Hadoop--HDFS完全分散式(簡單版)Hadoop分散式
- [分散式][Redis]Redis分散式框架搭建與整合分散式Redis框架
- Centos7下GlusterFS分散式儲存叢集環境部署記錄CentOS分散式
- 完全分散式模式hadoop叢集安裝與配置分散式模式Hadoop
- Hadoop3.0完全分散式叢集安裝部署Hadoop分散式
- HDFS分散式叢集搭建分散式
- hadoop分散式叢集搭建Hadoop分散式
- HA分散式叢集搭建分散式
- 虛擬機器裝Hadoop叢集完全分散式虛擬機Hadoop分散式
- Centos7下使用Ceph-deploy快速部署Ceph分散式儲存-操作記錄CentOS分散式
- Hadoop環境搭建(二)分散式Hadoop分散式
- Hbase偽分散式環境搭建分散式
- Hadoop分散式叢集搭建_1Hadoop分散式
- Centos7下搭建Laravel環境(非docker)CentOSLaravelDocker
- 分散式:分散式系統下的唯一序列分散式
- java實現分散式專案搭建Java分散式
- Centos7下搭建FTP檔案伺服器CentOSFTP伺服器
- 騰訊雲centos7下搭建fastDFS+nginxCentOSASTNginx
- Seata搭建與分散式事務入門分散式
- 基於Spring Cloud搭建分散式配置中心SpringCloud分散式
- Cassandra安裝及分散式叢集搭建分散式
- 冰河開源了全網首個完全開源的分散式全域性有序序列號(分散式ID)框架!!分散式框架
- centos7 wiki搭建CentOS
- 使用docker搭建ELK分散式日誌同步方案Docker分散式
- hadoop叢集搭建——單節點(偽分散式)Hadoop分散式