Hadoop 之 NameNode 後設資料原理
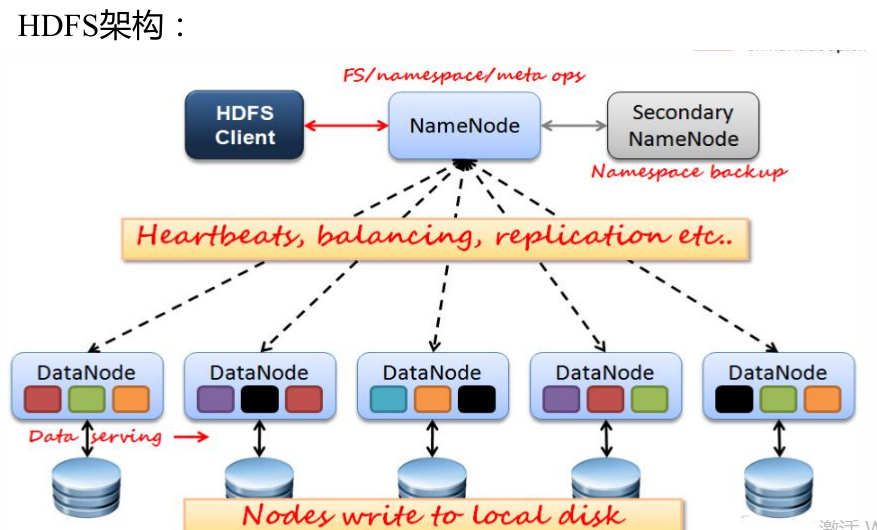
在對NameNode節點進行格式化時,呼叫了FSImage的saveFSImage()方法和FSEditLog.createEditLogFile()儲存當前的後設資料。Namenode主要維護兩個檔案,一個是fsimage,一個是editlog。
fsimage :儲存了最新的後設資料檢查點,包含了整個HDFS檔案系統的所有目錄和檔案的資訊。對於檔案來說包括了資料塊描述資訊、修改時間、訪問時間等;對於目錄來說包括修改時間、訪問許可權控制資訊(目錄所屬使用者,所在組)等。簡單的說,Fsimage就是在某一時刻,整個hdfs 的快照,就是這個時刻hdfs上所有的檔案塊和目錄,分別的狀態,位於哪些個datanode,各自的許可權,各自的副本個數等。
注意:Block的位置資訊不會儲存到fsimage,Block儲存在哪個DataNode(由DataNode啟動時上報)。
editlog :主要是在NameNode已經啟動情況下對HDFS進行的各種更新操作進行記錄,HDFS客戶端執行所有的寫操作都會被記錄到editlog中。
讀取後設資料:
啟動NameNode節點時,又要從映象和編輯日誌中讀取後設資料。
寫入後設資料:
在NameNode執行時會將記憶體中的後設資料資訊儲存到所指定的檔案,即${dfs.name.dir}/current目錄下的fsimage檔案,此外還會將另外一部分對NameNode更改的日誌資訊儲存到${dfs.name.dir}/current目錄下的edits檔案中。fsimage檔案和edits檔案可以確定NameNode節點當前的狀態,這樣在NameNode節點由於突發原因崩潰時,可以根據這兩個檔案中的內容恢復到節點崩潰前的狀態,所以對NameNode節點中記憶體後設資料的每次修改都必須儲存下來。但是如果每次都儲存到fsimage檔案中,這樣效率就特別低效,所以引入編輯日誌檔案edits,儲存對對後設資料的修改資訊,也就是fsimage檔案儲存NameNode節點中某一時刻記憶體中的後設資料(即目錄樹),edits儲存這一時刻之後的對後設資料的更改資訊。
映象的儲存:

SecondaryNameNode:主要由兩個作用,一是映象備份(不是NN的備份,但可以做備份),二是日誌與映象的定期合併。
第一步:將hdfs更新記錄寫入一個新的檔案——edits.new。
第二步:將fsimage和editlog透過http協議傳送至secondary namenode。
第三步:將fsimage與editlog合併,生成一個新的檔案——fsimage.ckpt。這步之所以要在secondary namenode中進行,是因為比較耗時,如果在namenode中進行,或導致整個系統卡頓。
第四步:將生成的fsimage.ckpt透過http協議傳送至namenode。
第五步:重新命名fsimage.ckpt為fsimage,edits.new為edits。
第六步:等待下一次checkpoint觸發SecondaryNameNode進行工作,一直這樣迴圈操作。
注:checkpoint觸發的條件可以在core-site.xml檔案中進行配置。fs.checkpoint.period表示多長時間記錄一次hdfs的映象。預設是1小時。fs.checkpoint.size表示一次記錄多大的size,預設64M。例如如下:
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.
</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
<description>The size of the current edit log (in bytes) that triggers
a periodic checkpoint even if the fs.checkpoint.period hasn't expired.
</description>
</property>
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31383567/viewspace-2143455/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- hadoop(5)--NameNode後設資料管理(2)Hadoop
- Hadoop錯誤之namenode當機的資料恢復Hadoop資料恢復
- Hadoop2之NameNode HA詳解Hadoop
- org.apache.hadoop.hdfs.server.namenode.NameNode.ApacheHadoopServer
- Smartbi:資料治理系列之後設資料管理平臺的原理
- 黑猴子的家:Hadoop之Namenode多目錄配置Hadoop
- Hadoop之HDFS及NameNode單點故障解決方案Hadoop
- Hadoop雙namenode配置搭建(HA)Hadoop
- Hadoop原理之——HDFS原理Hadoop
- Hadoop商業環境實戰-HDFS NameNode 當機後設資料一致保障及SNN機制深入研究Hadoop
- 資料治理之後設資料管理
- Windows下hadoop環境搭建之NameNode啟動報錯WindowsHadoop
- hadoop中namenode無法啟動Hadoop
- 配置hadoop HIVE後設資料儲存在mysql中HadoopHiveMySql
- Hadoop 啟動namenode節點失敗Hadoop
- 資料治理之後設資料管理實踐
- 2- hive後設資料與hadoop的關係HiveHadoop
- Hadoop框架:NameNode工作機制詳解Hadoop框架
- Hadoop Namenode 無法啟動 總結一Hadoop
- 大資料之 ZooKeeper原理及其在Hadoop和HBase中的應用大資料Hadoop
- 理“ Druid 後設資料”之亂UI
- 大資料時代之hadoop(三):hadoop資料流(生命週期)大資料Hadoop
- 大資料時代之hadoop(一):hadoop安裝大資料Hadoop
- SparkSQL:Parquet資料來源之合併後設資料SparkSQL
- 資料服務基礎能力之後設資料管理
- 分散式及高可用後設資料採集原理分散式
- Hadoop系列之HDFS 資料塊Hadoop
- Hadoop3.2.1 【 HDFS 】原始碼分析 : Standby Namenode解析Hadoop原始碼
- Hadoop中Namenode單點故障的解決方案Hadoop
- 大資料時代之hadoop(二):hadoop指令碼解析大資料Hadoop指令碼
- 大資料測試之hadoop初探大資料Hadoop
- 資料治理--後設資料
- HADOOP遇到namenode: at org.apache.hadoop.net.NetUtils.createSocketAddr錯誤HadoopApache
- Hadoop3.2.1 【 HDFS 】原始碼分析 : Secondary Namenode解析Hadoop原始碼
- 使用Atlas進行後設資料管理之Glossary
- MySQL和Oracle對比學習之資料字典後設資料MySqlOracle
- 《Hadoop權威指南》-- mapreduce原理讀後感Hadoop
- 資料庫原理-設計資料庫