Python3爬蟲之爬取某一路徑的所有html檔案
要離線下載易百教程網站中的所有關於Python的教程,需要將Python教程的首頁作為種子url:http://www.yiibai.com/python/,然後按照廣度優先(廣度優先,使用佇列;深度優先,使用棧),依次爬取每一篇關於Python的文章。為了防止同一個連結重複爬取,使用集合來限制同一個連結只處理一次。
使用正規表示式提取網頁原始碼裡邊的文章標題和文章url,獲取到了文章的url,使用Python根據url生成html檔案十分容易。
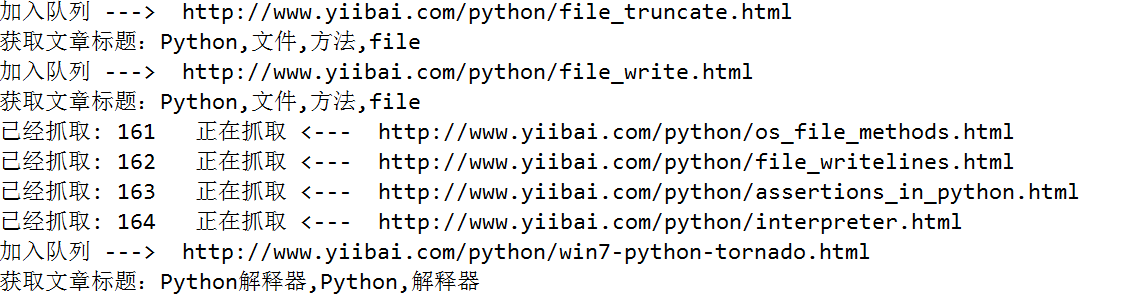
使用正規表示式提取網頁原始碼裡邊的文章標題和文章url,獲取到了文章的url,使用Python根據url生成html檔案十分容易。
import re
import urllib.request
import urllib
from collections import deque
# 儲存檔案的字尾
SUFFIX='.html'
# 提取文章標題的正規表示式
REX_TITLE=r'<title>(.*?)</title>'
# 提取所需連結的正規表示式
REX_URL=r'/python/(.+?).html'
# 種子url,從這個url開始爬取
BASE_URL='http://www.yiibai.com/python/'
# 將獲取到的文字儲存為html檔案
def saveHtml(file_name,file_content):
# 注意windows檔案命名的禁用符,比如 /
with open (file_name.replace('/','_')+SUFFIX,"wb") as f:
# 寫檔案用bytes而不是str,所以要轉碼
f.write(bytes(file_content, encoding = "utf8"))
# 獲取文章標題
def getTitle(file_content):
linkre = re.search(REX_TITLE,file_content)
if(linkre):
print('獲取文章標題:'+linkre.group(1))
return linkre.group(1)
# 爬蟲用到的兩個資料結構,佇列和集合
queue = deque()
visited = set()
# 初始化種子連結
queue.append(BASE_URL)
count = 0
while queue:
url = queue.popleft() # 隊首元素出隊
visited |= {url} # 標記為已訪問
print('已經抓取: ' + str(count) + ' 正在抓取 <--- ' + url)
count += 1
urlop = urllib.request.urlopen(url)
# 只處理html連結
if 'html' not in urlop.getheader('Content-Type'):
continue
# 避免程式異常中止
try:
data = urlop.read().decode('utf-8')
title=getTitle(data);
# 儲存檔案
saveHtml(title,data)
except:
continue
# 正規表示式提取頁面中所有連結, 並判斷是否已經訪問過, 然後加入待爬佇列
linkre = re.compile(REX_URL)
for sub_link in linkre.findall(data):
sub_url=BASE_URL+sub_link+SUFFIX;
# 已經訪問過,不再處理
if sub_url in visited:
pass
else:
# 設定已訪問
visited |= {sub_url}
# 加入佇列
queue.append(sub_url)
print('加入佇列 ---> ' + sub_url)

相關文章
- 網路爬蟲——專案實戰(爬取糗事百科所有文章)爬蟲
- 爬蟲之股票定向爬取爬蟲
- Python3 大型網路爬蟲實戰 — 給 scrapy 爬蟲專案設定為防反爬Python爬蟲
- 在scrapy框架下建立爬蟲專案,建立爬蟲檔案,執行爬蟲檔案框架爬蟲
- Python3 大型網路爬蟲實戰 002 --- scrapy 爬蟲專案的建立及爬蟲的建立 --- 例項:爬取百度標題和CSDN部落格Python爬蟲
- 【0基礎學爬蟲】爬蟲基礎之檔案儲存爬蟲
- python3網路爬蟲開發實戰_Python3 爬蟲實戰Python爬蟲
- 《Python3網路爬蟲開發實戰》教程||爬蟲教程Python爬蟲
- 爬蟲學習之基於Scrapy的網路爬蟲爬蟲
- [Python3網路爬蟲開發實戰] 分散式爬蟲原理Python爬蟲分散式
- 【爬蟲】利用Python爬蟲爬取小麥苗itpub部落格的所有文章的連線地址(1)爬蟲Python
- Python爬蟲入門教程 50-100 Python3爬蟲爬取VIP視訊-Python爬蟲6操作Python爬蟲
- python網路爬蟲--爬取淘寶聯盟Python爬蟲
- Java 爬蟲專案實戰之爬蟲簡介Java爬蟲
- python爬蟲練習之爬取豆瓣讀書所有標籤下的書籍資訊Python爬蟲
- 網路爬蟲專案爬蟲
- Python爬蟲-獲得某一連結下的所有超連結Python爬蟲
- python爬蟲爬取csdn部落格專家所有部落格內容Python爬蟲
- Python爬蟲爬取B站up主所有動態內容Python爬蟲
- 爬蟲爬取微信小程式爬蟲微信小程式
- Python3網路爬蟲(十一):爬蟲黑科技之讓你的爬蟲程式更像人類使用者的行為(代理IP池等)Python爬蟲
- 反爬蟲之字型反爬蟲爬蟲
- 爬蟲:HTTP請求與HTML解析(爬取某乎網站)爬蟲HTTPHTML網站
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- 用PYTHON爬蟲簡單爬取網路小說Python爬蟲
- 網路爬蟲——爬取糗事百科笑料段子爬蟲
- 提高爬蟲爬取效率的辦法爬蟲
- Python3爬蟲利器之ChromeDriver的安裝Python爬蟲Chrome
- 分散式爬蟲之知乎使用者資訊爬取分散式爬蟲
- Python使用多程式提高網路爬蟲的爬取速度Python爬蟲
- 網路爬蟲——爬蟲實戰(一)爬蟲
- [網路爬蟲] Jsoup : HTML 解析工具爬蟲JSHTML
- 精通Scrapy網路爬蟲【一】第一個爬蟲專案爬蟲
- 網路爬蟲之關於爬蟲 http 代理的常見使用方式爬蟲HTTP
- python3網路爬蟲開發實戰_Python 3開發網路爬蟲(一)Python爬蟲
- 網路爬蟲專案蒐集爬蟲
- Java爬蟲批量爬取圖片Java爬蟲
- 如何合理控制爬蟲爬取速度?爬蟲