Tomcat應用報redis超時的故事
業務背景介紹
系統架構是通過分散式的方式進行部署的,登入的時候不會呼叫redis資料,假如使用者登入成功了,會跳轉到其它的專案上,並根據從redis中查到的許可權快取,像是相應的資料模組
問題排查
問題君發飆最初手段
問題一:使用者登入失敗,系統巨卡無比
問題二:Tomcat丟擲 connect timed out錯誤
2016-09-24 16:44:24,397 - [ERROR] [RedisClient]:269- java.net.SocketTimeoutException: connect timed out
redis.clients.jedis.exceptions.JedisConnectionException: java.net.SocketTimeoutException: connect timed out
at redis.clients.jedis.Connection.connect(Connection.java:134)
at redis.clients.jedis.BinaryClient.connect(BinaryClient.java:69)
at redis.clients.jedis.Connection.sendCommand(Connection.java:79)
at redis.clients.jedis.BinaryClient.exists(BinaryClient.java:99)
at redis.clients.jedis.Client.exists(Client.java:29)
at redis.clients.jedis.Jedis.exists(Jedis.java:92)
at redis.clients.jedis.ShardedJedis.exists(ShardedJedis.java:48)
at com.tools.common.redis.client.RedisClient.exists(RedisClient.java:267)
at com.group.erp.rpc.dubbo.service.impl.ActionRpcServiceImpl.getActionList(ActionRpcServiceImpl.java:23)
at com.alibaba.dubbo.common.bytecode.Wrapper1.invokeMethod(Wrapper1.java)
at com.alibaba.dubbo.rpc.proxy.javassist.JavassistProxyFactory$1.doInvoke(JavassistProxyFactory.java:46)
at com.alibaba.dubbo.rpc.proxy.AbstractProxyInvoker.invoke(AbstractProxyInvoker.java:72)
at com.alibaba.dubbo.rpc.filter.ExceptionFilter.invoke(ExceptionFilter.java:55)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.ClassLoaderFilter.invoke(ClassLoaderFilter.java:38)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.EchoFilter.invoke(EchoFilter.java:38)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.monitor.support.MonitorFilter.invoke(MonitorFilter.java:73)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.GenericFilter.invoke(GenericFilter.java:68)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.TimeoutFilter.invoke(TimeoutFilter.java:42)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.protocol.dubbo.filter.TraceFilter.invoke(TraceFilter.java:78)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.filter.ContextFilter.invoke(ContextFilter.java:60)
at com.alibaba.dubbo.rpc.protocol.ProtocolFilterWrapper$1.invoke(ProtocolFilterWrapper.java:91)
at com.alibaba.dubbo.rpc.protocol.dubbo.DubboProtocol$1.reply(DubboProtocol.java:108)
at com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeHandler.handleRequest(HeaderExchangeHandler.java:84)
at com.alibaba.dubbo.remoting.exchange.support.header.HeaderExchangeHandler.received(HeaderExchangeHandler.java:170)
at com.alibaba.dubbo.remoting.transport.dispather.ChannelEventRunnable.run(ChannelEventRunnable.java:78)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.net.SocketTimeoutException: connect timed out
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at redis.clients.jedis.Connection.connect(Connection.java:129)
... 34 more按照常規思路進行排查
查詢問題君之網路卡流量狀況
:sar -n DEV 1
09時00分30秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 09時00分31秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 09時00分31秒 eth1 873.74 257.58 66.75 49.75 0.00 0.00 0.00查詢問題君之CPU狀況
:top
[root@ZWCLC6X-10939 ~]# top top - 08:58:52 up 1 day, 15:05, 1 user, load average: 0.00, 0.00, 0.00 Tasks: 187 total, 1 running, 186 sleeping, 0 stopped, 0 zombie Cpu(s): 0.2%us, 0.2%sy, 0.0%ni, 98.7%id, 0.1%wa, 0.3%hi, 0.5%si, 0.0%st Mem: 16333752k total, 12914752k used, 3419000k free, 286716k buffers Swap: 1048572k total, 0k used, 1048572k free, 1013568k cached查詢問題君之記憶體狀況
:free -m
total used free shared buffers cached Mem: 15950 14612 1338 0 279 990 -/+ buffers/cache: 11342 4608 Swap: 1023 997 26這裡發現了一個問題,伺服器的記憶體資源居高不下,暫且不考慮伺服器資源的正常與否
查詢問題君之可疑程式狀況
ps -ef 顯示系統程式
這裡不方便把伺服器開啟了那些程式羅列到此處,還請見諒;最後的分析結果就是,並無異常程式
這就奇怪了,到底是哪的問題呢?繼續查詢
查詢問題君之生產環境應用
生產環境有兩個java專案都呼叫了這個伺服器的redis服務,然後找到了這兩個專案分別檢視日誌,幾乎在相同時間都丟擲了Time out的錯誤,因此斷定應該是redis單方面的問題
查詢問題君之生產環境redis服務
檢視了redis日誌,並沒有什麼報錯請求
[1008] 24 Sep 17:17:20.378 - Accepted XX.XX.XX.XX:40688
[1008] 24 Sep 17:17:20.394 - Accepted XX.XX.XX.XX:40691
[1008] 24 Sep 17:17:20.470 - Accepted XX.XX.XX.XX:40692
[1008] 24 Sep 17:17:20.470 - Accepted XX.XX.XX.XX:40693
[1008] 24 Sep 17:17:20.484 - Accepted XX.XX.XX.XX:55622
[1008] 24 Sep 17:17:20.486 - Accepted XX.XX.XX.XX:40697
[1008] 24 Sep 17:17:20.488 - Accepted XX.XX.XX.XX:55624查詢問題君之redis壓力測試
使用redis-benchmark測試了redis的壓力,也沒有什麼問題。
查詢問題君之redis慢查詢
懷疑是有慢查詢 連線數不夠用 等待了 導致超時了
有這麼幾個命令:
./redis-cli -h 127.0.0.1 -p 6378 # 這個是連線上本機的6378的redis
auth password #如果redis設定的有密碼,使用auth進行密碼驗證
CONFIG GET slowlog-log-slower-than #(10000us,Redis中的執行單位是微秒,相當於10ms)
CONFIG GET slowlog-max-len (最多儲存128條慢日誌,應該是預設的吧?)SLOWLOG LEN #檢視redis儲存的慢查詢記錄,預設檢視128條
SLOWLOG GET # 檢視redis儲存的慢查詢記錄,預設10條
6) 1) (integer) 166
2) (integer) 1474962558
3) (integer) 55972 # 這個是慢查詢時間,微秒級別的,1秒=1000毫秒,1毫秒=1000微妙
4) 1) "SETEX"
2) "company_info_nan857920"
3) "7200"
4) "x1fx8bx00x00x00x00x00x00x00xedUKox1bUx14xbeqxc8xbb
xa1!x16x85x05xe2)axc7x8dJx12uGxcaxc2xe0Vx15)x0bx96Sxcfx8d3xc5x9ex99xcc\`x0ex0bxd4xb4ux1c`Nx9dx904xadx1bxf7x11xd5xa1 4N+Lxe2xfaxd1JHxacxf9x0bx88xcexb5gx16(Kxb6x9cxebyxd8Axb0cYKx1ex9fxf3x9dxef<xee9gxaex1fxfex89xdaTx05xbdx17x90xc2nx95x9fvGT... (1218 more從上面可以看出一個滿查詢在55毫秒左右,專案的配置檔案在10秒左右,所以不存在超時的問題
查詢問題君之redis記憶體
懷疑redis的記憶體用到上線,因此檢視了redis的配置maxmonery # 我的配置檔案沒有設定,預設是不限制記憶體
查詢問題君之redis記憶體使用狀況
#./redis-cli -h 127.0.0.1 -p 6378 # 這個是連線上本機的6378的redis
> info # 檢視redis資訊
#Server
XXXXXXXXXXXX
#Clients
XXXXXXXXXXXX
#Memory
used_memory:28507480
used_memory_human:27.19M
used_memory_rss:51208192
used_memory_peak:51844256
used_memory_peak_human:49.44M
used_memory_lua:33792
mem_fragmentation_ratio:1.80
mem_allocator:libc
#Persistence
XXXXXXXXXX
#Stats
XXXXXXXXXX
#Replication
XXXXXXXXXX
#CPU
XXXXXXXXXX
#Keyspace
XXXXXXXXXX介紹Memory的引數資訊:
檢視了redis使用記憶體很小,才使用了27.19M,排除了redis的記憶體使用情況
查詢問題君之初步定型問題
使用了speedtest-cli 命令測試了本機的網速情況
speedtest-cli命令介紹:
參考:http://www.linuxde.net/2014/01/15561.html
$ wget https://raw.github.com/sivel/speedtest-cli/master/speedtest_cli.py
$ chmod a+rx speedtest_cli.py
$ sudo mv speedtest_cli.py /usr/local/bin/speedtest-cli
$ sudo chown root:root /usr/local/bin/speedtest-cli測試結果: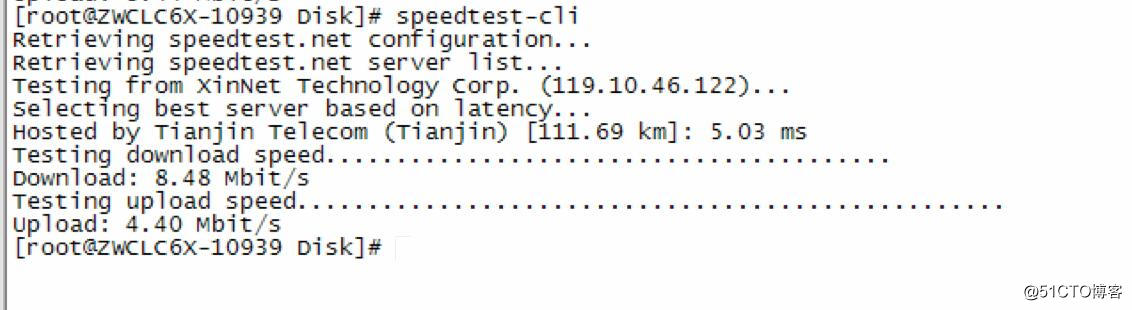
使用這個命令檢視本機網路,貌似有問題,於是那了兩臺機器之間互傳了一個較大的檔案,檢視了速度,經測試速度在5MB-6MB左右,因此排除了網路問題】
查詢問題君之資料持久化導
開始認為是持久化導致的磁碟IO飆升問題,於是更改持久化策略
先說一下持久化分為兩種方式,第一種為AOF,第二種為save的方式,格式大概為
方式一:
################################ 快照 #################################
#
# 把資料庫存到磁碟上:
#
# save <seconds> <changes>
#
# 會在指定秒數和資料變化次數之後把資料庫寫到磁碟上。
#
# 下面的例子將會進行把資料寫入磁碟的操作:
# 900秒(15分鐘)之後,且至少1次變更
# 300秒(5分鐘)之後,且至少10次變更
# 60秒之後,且至少10000次變更
#
# 注意:你要想不寫磁碟的話就把所有 "save" 設定註釋掉就行了。
#save 900 1
#save 300 10
#save 60 10000方式二:
############################## 純累加模式 ###############################
# 預設情況下,Redis是非同步的把資料匯出到磁碟上。這種情況下,當Redis掛掉的時候,最新的資料就丟了。
# 如果不希望丟掉任何一條資料的話就該用純累加模式:一旦開啟這個模式,Redis會把每次寫入的資料在接收後都寫入 appendonly.aof 檔案。
# 每次啟動時Redis都會把這個檔案的資料讀入記憶體裡。
#
# 注意,非同步匯出的資料庫檔案和純累加檔案可以並存(你得把上面所有"save"設定都註釋掉,關掉匯出機制)。
# 如果純累加模式開啟了,那麼Redis會在啟動時載入日誌檔案而忽略匯出的 dump.rdb 檔案。
#
# 重要:檢視 BGREWRITEAOF 來了解當累加日誌檔案太大了之後,怎麼在後臺重新處理這個日誌檔案。
appendonly yes
# 純累加檔名字(預設:"appendonly.aof")
# appendfilename appendonly.aof
appendfilename "appendonly.aof"
# fsync() 請求作業系統馬上把資料寫到磁碟上,不要再等了。
# 有些作業系統會真的把資料馬上刷到磁碟上;有些則要磨蹭一下,但是會盡快去做。
#
# Redis支援三種不同的模式:
#
# no:不要立刻刷,只有在作業系統需要刷的時候再刷。比較快。
# always:每次寫操作都立刻寫入到aof檔案。慢,但是最安全。
# everysec:每秒寫一次。折衷方案。
#
# 預設的 "everysec" 通常來說能在速度和資料安全性之間取得比較好的平衡。
# 如果你真的理解了這個意味著什麼,那麼設定"no"可以獲得更好的效能表現(如果丟資料的話,則只能拿到一個不是很新的快照);
# 或者相反的,你選擇 "always" 來犧牲速度確保資料安全、完整。
#
# 如果拿不準,就用 "everysec"
# appendfsync always
appendfsync everysec
# appendfsync no
# 如果AOF的同步策略設定成 "always" 或者 "everysec",那麼後臺的儲存程式(後臺儲存或寫入AOF日誌)會產生很多磁碟I/O開銷。
# 某些Linux的配置下會使Redis因為 fsync() 而阻塞很久。
# 注意,目前對這個情況還沒有完美修正,甚至不同執行緒的 fsync() 會阻塞我們的 write(2) 請求。
#
# 為了緩解這個問題,可以用下面這個選項。它可以在 BGSAVE 或 BGREWRITEAOF 處理時阻止 fsync()。
#
# 這就意味著如果有子程式在進行儲存操作,那麼Redis就處於"不可同步"的狀態。
# 這實際上是說,在最差的情況下可能會丟掉30秒鐘的日誌資料。(預設Linux設定)
#
# 如果你有延遲的問題那就把這個設為 "yes",否則就保持 "no",這是儲存持久資料的最安全的方式。
no-appendfsync-on-rewrite yes
# 自動重寫AOF檔案
#
# 如果AOF日誌檔案大到指定百分比,Redis能夠通過 BGREWRITEAOF 自動重寫AOF日誌檔案。
#
# 工作原理:Redis記住上次重寫時AOF日誌的大小(或者重啟後沒有寫操作的話,那就直接用此時的AOF檔案),
# 基準尺寸和當前尺寸做比較。如果當前尺寸超過指定比例,就會觸發重寫操作。
#
# 你還需要指定被重寫日誌的最小尺寸,這樣避免了達到約定百分比但尺寸仍然很小的情況還要重寫。
#
# 指定百分比為0會禁用AOF自動重寫特性。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
# lua
lua-time-limit 5000注掉了從的持久化,主注掉save模式,開啟AOF模式,可是io高的問題依舊沒有解決,於是乎就有了下文
查詢問題君之磁碟IO狀況
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 59.00 574.00 99.00 21272.00 1272.00 33.50 6.02 9.01 1.34 89.90
sda 0.00 0.00 0.00 3.00 0.00 24.00 8.00 0.00 0.00 0.00 0.00
dm-0 0.00 0.00 568.00 158.00 21080.00 1272.00 30.79 6.04 8.38 1.24 89.90看到這個介面,好像找到了點頭緒,伺服器的磁碟IO較高,但是小編這裡也提出了疑問,redis的資料全部存放到了sdb銀盤上,而且redis的程式也都是在sdb上面,那為什麼伺服器的sda的
IO資源佔用如此之高呢?
順藤摸瓜>>>就從高IO的線索查詢問題根源:
檢查是什麼程式佔用瞭如此高系統盤IO?
iotopiotop執行命令結果,發現一個佔用資源特別高的程式
檢查發現,這個程式存在的作用是,當系統的實體記憶體耗盡時候,系統會啟用此程式,以來呼叫swap分割槽。
這下有點明白其中的道道了,問題原因大概如下: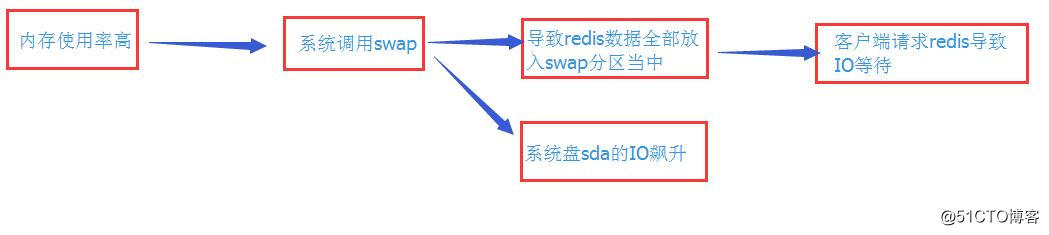
檢查都有那些系統應用佔用了swap分割槽,編寫指令碼:
#!/bin/bash
###############################################################################
# 日期 : 2016-09-27
# 作者 : sean
# Email : linux_no1@126.com
# 版本 : 1.0
# 指令碼功能 : 列出正在佔用swap的程式。
###############################################################################
echo -e "PID Swap Proc_Name"
for pid in `ls -l /proc | grep ^d | awk `{ print $9 }`| grep -v [^0-9]`
# /proc目錄下所有以數字為名的目錄(程式名是數字才是程式,其他如sys,net等存放的是其他資訊)
do
if [ $pid -eq 1 ];then continue;fi # Do not check init process
# 讓程式釋放swap的方法只有一個:就是重啟該程式。或者等其自動釋放。
# 如果程式會自動釋放,那麼我們就不會寫指令碼來找他了,找他都是因為他沒有自動釋放。
# 所以我們要列出佔用swap並需要重啟的程式,但是init這個程式是系統裡所有程式的祖先程式
# 重啟init程式意味著重啟系統,這是萬萬不可以的,所以就不必檢測他了,以免對系統造成影響。
grep -q "Swap" /proc/$pid/smaps 2>/dev/null #檢查是否佔用swap分割槽
if [ $? -eq 0 ];then
swap=$(awk `/Swap/{ sum+=$2;} END{ print sum }` /proc/$pid/smaps) #統計佔用的swap分割槽的大小 單位是KB
proc_name=$(ps aux | grep -w "$pid" | awk `!/grep/{ for(i=11;i<=NF;i++){ printf("%s ",$i); }}`) #取出程式的名字
if [ $swap -gt 0 ];then #判斷是否佔用swap,只有佔用才會輸出
echo -e "$pid ${swap} $proc_name"
fi
fi
done | sort -k2 -n | awk -F` ` `{
if($2<1024)
printf("%-10s %15sKB %s
",$1,$2,$3);
else if($2<1048576)
printf("%-10s %15.2fMB %s
",$1,$2/1024,$3);
else
printf("%-10s %15.2fGB %s
",$1,$2/1048576,$3);
}`執行結果,發現
redis的程式全部存放在了swap分割槽中,果然是這樣。
修改核心引數,合理分配記憶體使用
A.釋放實體記憶體,並且叫新應用獲取實體記憶體。
參考地址:http://www.cnblogs.com/minideas/p/3796505.html
1.在釋放記憶體之前,檢查可用記憶體多少
free -m
輸出結果略
2.手動釋放記憶體
echo 1 > /proc/sys/vm/drop_caches
3.釋放完成後,檢查可用記憶體是否進行了釋放
free -m
輸出結果略
經過上述的三個命令,發現記憶體確實進行了釋放。
4.重啟redis服務
5.檢查swap分割槽使用
重啟了redis發現記憶體走的依舊是swap分割槽,實體記憶體還有很多可用記憶體,但是系統為什麼分給應用swap分割槽呢?
B.修改系統核心引數,叫所有的應用盡量使用實體記憶體,避免使用swap分割槽。
參考地址:http://davidbj.blog.51cto.com/4159484/1172879/
仔細看,實體記憶體還有將近1GB沒有使用。但是swap已經開始被使用。懷疑是不是swappiness檔案的值沒有更改。
說明:在centos裡面,swappiness的值的大小對如何使用swap分割槽是有著很大的聯絡的。swappiness=0的時候表示最大限度使用實體記憶體,然後才是 swap空間,swappiness=100的時候表示積極的使用swap分割槽,並且把記憶體上的資料及時的搬運到swap空間裡面。兩個極端,對於Centos的預設設定,這個值等於60,建議修改為10。具體這樣做:
sysctl vm.swappiness=10
但是這只是臨時的修改,如果系統重啟會恢復預設的值60,所有還需要做下一步:
echo vm.swappiness=10 >> /etc/sysctl.conf
這樣就可以了。最後重新載入swap虛擬記憶體:
swapoff -a //關閉虛擬記憶體
swapon -a //開啟虛擬記憶體 但是上面操作後,重啟了redis應用,系統依舊分給了redis swap分割槽。
C. 最後重啟伺服器,並再次啟動redis服務,最後問題得到了解決。swap分割槽為0了
相關文章
- websphere 應用超時問題的解決Web
- Redis乾貨|解鎖Redis 時間序列資料的應用Redis
- 應用連線超時排查DB MySQLMySql
- Tomcat的應用範圍Tomcat
- tomcat 啟動dangdang的spring配置超時TomcatSpring
- 磁碟、mysql、redis、hana 的故事!MySqlRedis
- 我又和redis超時槓上了Redis
- redis主從超時檢測Redis
- redis應用Redis
- apr在tomcat中的應用Tomcat
- redis的應用場景Redis
- Redis持久化背後的故事Redis持久化
- 【Azure Redis】部署在AKS中的應用連線Redis時候出現Unable to connect to Redis serverRedisServer
- Redis連線超時排查實錄Redis
- TOMCAT和JAVA應用TomcatJava
- Redis 應用-GeoRedis
- Redis 應用-限流Redis
- Redis詳解以及Redis的應用場景Redis
- Redis之Lua的應用(四)Redis
- redis的incr和hash應用Redis
- Dr Windows報導:德國版Win10應用商店移除超17.4萬應用WindowsWin10
- 技術乾貨 | 解鎖Redis 時間序列資料的應用Redis
- Redis_RDB持久化之寫時複製技術的應用Redis持久化
- Redis作者談Redis應用場景Redis
- Redis 高階應用Redis
- SAP Fiori應用發生超時錯誤的一個可能原因
- tomcat部署web應用的4種方法TomcatWeb
- tomcat啟動超時以及啟動之後開啟網頁報404錯誤的解決方法Tomcat網頁
- redis在nodejs中的應用RedisNodeJS
- redis在python中的應用RedisPython
- 【詳解】Tomcat是如何監控並刪除超時Session的?TomcatSession
- python redis 分散式鎖 自動超時PythonRedis分散式
- 應用與tomcat上問題Tomcat
- Redis 應用-非同步訊息佇列與延時佇列Redis非同步佇列
- 使用者故事地圖實際應用地圖
- tomcat連線池配置,解決資料庫超時Tomcat資料庫
- Redis 應用-點陣圖Redis
- Redis 應用-分散式鎖Redis分散式