Tachyon--以記憶體為核心的開源分散式儲存系統
原文:http://geek.csdn.net/news/detail/51168
Tachyon是一個以記憶體為核心的開源分散式儲存系統,也是目前發展最迅速的開源大資料專案之一。Tachyon為不同的大資料計算框架(如Apache Spark,Hadoop MapReduce, Apache Flink等)提供可靠的記憶體級的資料共享服務。此外,Tachyon還能夠整合眾多現有的儲存系統(如Amazon S3, Apache HDFS, RedHat GlusterFS, OpenStack Swift等),為使用者提供統一的、易用的、高效的資料訪問平臺。本文首先向讀者介紹Tachyon專案的誕生背景和目前發展的情況;然後詳解Tachyon系統的基本架構以及目前一些重要的功能;最後,分享一個Tachyon在百度大資料生產環境下的幾個應用案例。
1.Tachyon簡介
隨著技術的發展,記憶體的吞吐量在不斷地提高,單位容量的記憶體價格在不斷降低,這為“記憶體計算”提供可能。在大資料計算平臺領域,採用分散式記憶體計算模式的Spark驗證了這一點。Spark相比於MapReduce大大提升了大資料的計算效能,受到了業界和社群的廣泛關注。然而,還是有很多問題在計算框架層難以解決,如:不同的Spark應用或不同計算框架(Spark,MapReduce,Presto)間仍需通過基於磁碟的儲存系統(如HDFS,Amazon S3等)交換資料;當Spark計算任務崩潰,JVM快取的資料會丟失; JVM中大量快取的資料增加了Java垃圾回收的壓力。
Tachyon最初出現是為了有效地解決了上述問題,它計劃構建一個獨立的儲存層來快速共享不同計算框架的資料,實現方式上將資料置於堆外(off-heap)記憶體以避免大量垃圾回收開銷。例如,對應Spark應用而言,可以帶來以下作用:
- 不同Spark應用,甚至不同計算平臺上的應用需要資料共享時,通過Tachyon進行記憶體讀寫,避免緩慢的磁碟操作。
- 使用Tachyon進行資料快取,當Spark任務崩潰,資料仍快取在Tachyon記憶體中,任務重啟後能夠直接從Tachyon中讀取資料。
- 多個Spark應用理論上甚至可以共享同一份Tachyon快取的資料,避免記憶體資源的浪費,減輕Java垃圾回收的壓力。
圖1給出了Tachyon部署時所處的位置。Tachyon被部署在計算平臺之下和現有的儲存系統之上,能夠在不同計算框架間共享資料。同時,現有的海量資料不需要進行遷移,上層的計算作業仍能通過Tachyon訪問到底層儲存平臺上的資料。Tachyon作為一個以記憶體為中心的中間儲存層,不僅能極大地提升上層計算平臺的效能,還能充分利用不同特性的底層儲存系統,更可以有效地整合兩者的優勢。
Tachyon最初是由李浩源博士發起的源自UC Berkeley AMPLab的研究專案(該實驗室也是Mesos和Spark的發源地)。自2013年4月開源以來,Tachyon社群不斷壯大,已經成為發展速度最快的開源大資料專案之一,目前已有來自超過50個組織機構的200多人蔘與到了對Tachyon專案的貢獻中,也有超過100家公司部署了Tachyon。於此同時,Tachyon的核心建立者和開發人員創立了Tachyon Nexus公司,其中不乏UC Berkeley、CMU等博士以及Google, Palantir, Yahoo!等前員工。 2015年3月美國華爾街日報報導了Tachyon Nexus獲得矽谷著名風投Andreessen Horowitz 的750萬美元A輪投資。
在學術界, 國內的南京大學PASA大資料實驗室一直積極關注並參與到Tachyon專案的開發中,共向Tachyon社群貢獻了100多個PR,近300次commit,包括為Tachyon實現效能測試框架tachyon-perf,增加LFU、LRFU等多個替換策略,改進WebUI頁面,以及其他一些效能優化的工作。此外,我們還撰寫了Tachyon相關的中文部落格,以便中文讀者和使用者能夠更深入地瞭解和使用Tachyon。
在工業界,百度也把Tachyon運用到其大資料系統中, Tachyon在過去一年中穩定的支援著百度的可互動式查詢業務,令百度的互動式查詢提速30倍。在驗證了Tachyon的高效能以及可靠性後,百度在內部使用Tachyon的0.9版成功部署了1000個worker的世界最大Tachyon叢集,總共提供50TB的記憶體儲存。此叢集在百度內部已經穩定執行了一個月,也驗證的Tachyon的可擴充套件性。於此同時,百度的另外一個Tachyon部署中用Tachyon層次化資料管理了2PB資料。
2.Tachyon系統架構
這一章中我們簡介Tachyon系統的基本架構,包括Tachyon的基本元件及其功能。
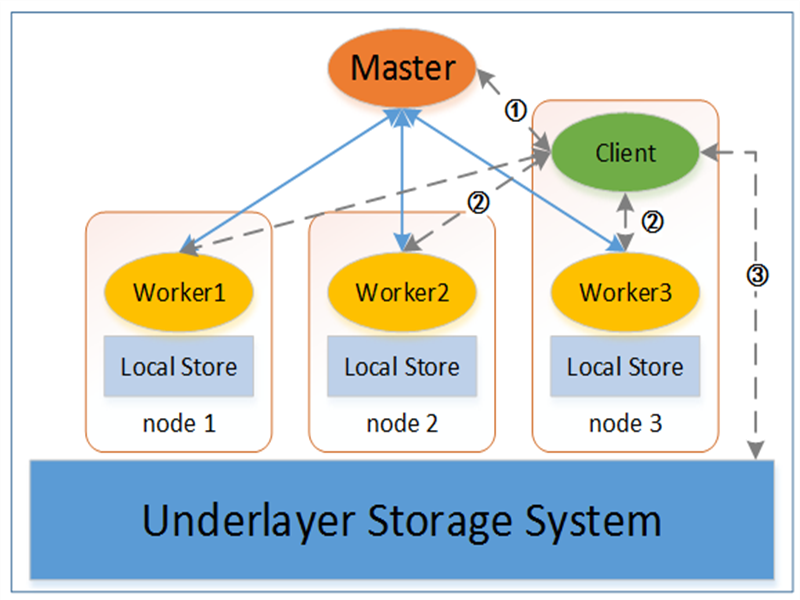
圖2是Tachyon系統的基本架構,主要包括4個基本元件:Master、Worker和Client,以及可插拔的底層儲存系統(Underlayer Storage System)。每個元件的具體功能職責如下:
-
Tachyon Master主要負責管理兩類重要資訊。第一,Tachyon Master中記錄了所有資料檔案的後設資料資訊,包括整個Tachyon名稱空間(namespace)的組織結構,所有檔案和資料塊的基本資訊等。第二,Tachyon Master監管著整個Tachyon系統的狀態,包括整個系統的儲存容量使用情況,所有Tachyon Worker的執行狀態等。
-
Tachyon Worker負責管理本地節點上的儲存資源,包括記憶體、SSD和HDD等。Tachyon中的所有資料檔案被劃分為一系列資料塊,Tachyon Worker以塊為粒度進行儲存和管理,如:為新的資料塊分配空間、將熱資料塊從SSD或HDD移至記憶體、實時或定期備份資料塊到底層儲存系統。同時,Tachyon Worker定時向Tachyon Master傳送心跳(heartbeat)以告知自身的狀態資訊。
-
Tachyon Client是上層應用訪問Tachyon資料的入口。訪問過程可以包括如下幾步:①Client向Master詢問資料檔案的基本資訊,包括檔案位置,資料塊大小等;②Client嘗試從本地Worker中讀取對應資料塊,若本地不存在Worker或者資料塊不在本地Worker中,則嘗試從遠端Worker中讀取;③若資料還未被快取到Tachyon中,則Client會從底層儲存系統中讀取對應資料。此外,Tachyon Client會向所有建立連線的Tachyon Master和Tachyon Worker定時傳送心跳以表示仍處於連線租期中,中斷連線後Tachyon Master和Tachyon Worker會回收對應Client的臨時空間。
-
底層儲存系統既可以被Tachyon用來備份資料,也可以作為Tachyon快取資料的來源,上層應用在使用Tachyon Client時也能直接訪問底層儲存系統上的資料。底層儲存系統保證了Tachyon Worker在發生故障而崩潰後不會導致資料丟失,同時也使得上層應用在遷移到Tachyon的同時不需要進行底層資料的遷移。目前Tachyon支援的底層儲存系統有HDFS,GlusterFS,Amazon S3,OpenStack Swift以及本地檔案系統,且能夠比較容易地嵌入更多的現有儲存系統。
在實際部署時, Tachyon Master通常部署在單個主節點上(Tachyon也支援多個節點上部署Tachyon Master,並通過使用ZooKeeper來防止單點故障);將Tachyon Worker部署在多個從節點;Tachyon Client和應用相關,可以位於任何一個節點上。
3.Tachyon的特色功能
本節我們簡介Tachyon面向上層應用的特色功能。
3.1 支援多種部署方式
作為大資料系統中的儲存層,Tachyon為使用者提供了不同的啟動模式、對資源管理框架的支援、以及目標執行環境,能夠部署多種大資料平臺環境中:
- 啟動模式:以正常模式啟動單個Tachyon Master;以高階容錯模式啟動多個Tachyon Master,並使用ZooKeeper進行管理;
- 資源管理框架:以Standalone方式直接執行在作業系統之上;執行在Apache Mesos之上;執行在Apache Hadoop Yarn之上;
- 目標執行環境:部署在本地叢集環境中;部署在Virtual Box虛擬機器中;部署在容器(如Docker)中;部署在Amazon EC2雲平臺上(Tachyon社群正在開發支援Tachyon部署在阿里雲OSS上)
使用者可以自由選擇不同的啟動模式、資源管理框架和目標執行環境,Tachyon為多種組合都提供了相應的啟動指令碼,能夠很方便地將Tachyon部署在使用者的環境中。
3.2 層次化儲存
Tachyon的層次化儲存充分利用了每個Tachyon Worker上的本地儲存資源,將Tachyon中的資料塊按不同熱度存放在了不同的儲存層中。目前Tachyon所使用的本地儲存資源包括MEM(Memory,記憶體)、SSD(Solid State Drives,固態硬碟)和HDD(Hard Disk Drives,磁碟)。在Tachyon Worker中,每一類儲存資源被視作一層(Storage Tier),每一層又可以由多個目錄(Storage Directory)組成,並且使用者可以設定每個儲存目錄的容量。
在讀寫Tachyon資料時,分配器(Allocator)負責為新的資料塊選擇目標儲存目錄,替換器(Evictor)負責將冷資料從記憶體剔至SSD和HDD,同時將熱資料從SSD和HDD提升至記憶體中。目前分配器所使用的分配策略包括Greedy、MaxFree和RoundRobin。替換器所使用的替換策略包括Greedy、LRU/PartialLRU、LRFU。額外地,Tachyon還為使用者提供了Pin功能,支援使用者將所需要的資料始終存放在記憶體中。關於如何配置Tachyon層次化儲存,可以進一步參考Tachyon官方文件。
3.3 靈活的讀寫機制
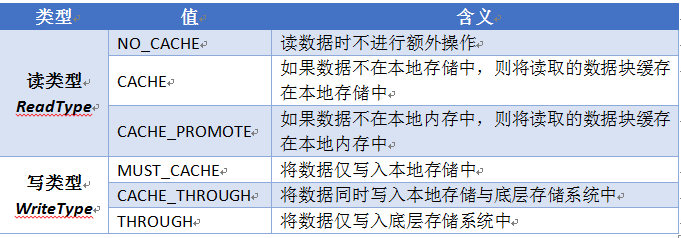
為了充分利用多層次的儲存資源和底層儲存系統,Tachyon為使用者提供了不同的讀寫型別(ReadType/WriteType)API,用於靈活控制讀寫資料時的行為方式,不同的讀寫型別及其含義如表1所示。
除了上述的讀寫型別外,Tachyon還提供了另一套控制方式:TachyonStorageType和UnderStorageType,用於分別控制在Tachyon儲存和底層儲存系統上的讀寫行為,具體取值及其含義如表2所示。實際上,這種控制方式是Tachyon-0.8之後新增的,控制粒度更細,功能也更多,因此推薦使用者採用這種方式控制讀寫行為。

3.4 檔案系統層的Lineage容錯機制
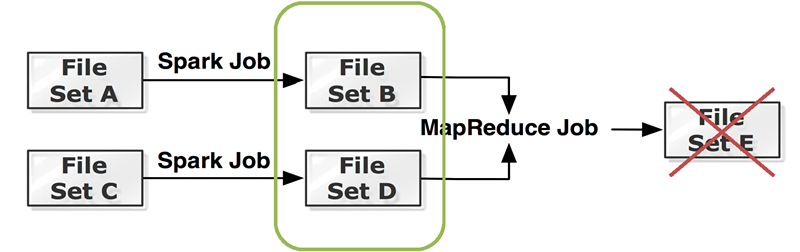
在Tachyon中,Lineage表示了兩個或多個檔案之間的世系關係,即輸出檔案集B是由輸入檔案集A通過怎樣的操作得到的。有了Lineage資訊後,在檔案資料意外丟失時,Tachyon就會啟動重計算作業,根據現有的檔案重新執行同樣的操作,以恢復丟失的資料。圖3給出了一個Lineage示例,檔案集A通過一個Spark作業生成檔案集B;檔案集C通過另一個Spark作業生成檔案集D;B和D作為同一個MapReduce作業的輸入,輸出為檔案集E。那麼,如果檔案集E意外丟失,並且沒有備份,那麼Tachyon就會重新啟動對應的MapReduce作業,再次生成E。
3.5 統一名稱空間
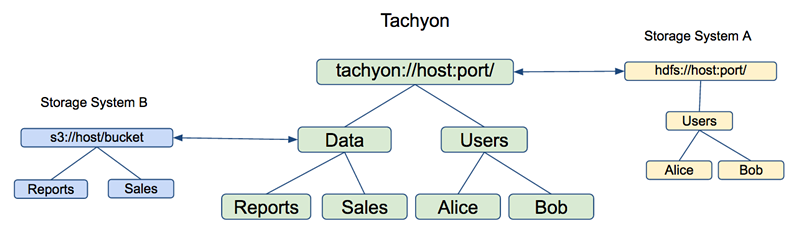
對於Tachyon的使用者而言,通過Tachyon提供的介面所訪問到的是Tachyon檔案系統的名稱空間。當使用者需要訪問Tachyon以外的檔案和資料時,Tachyon提供了Mount介面,能夠將外部儲存系統的檔案或目錄掛載到Tachyon的名稱空間中。這樣使用者就能夠在統一的Tachyon名稱空間中,使用相同或者自定義的路徑,訪問其他儲存系統上的檔案和資料。
3.6 HDFS相容介面
在Tachyon出現之前,諸如Hadoop MapReduce以及Apache Spark的應用大多使用HDFS、Amazon S3等儲存檔案。Tachyon為這些應用提供了一套HDFS相容的介面(確切地說,是相容了org.apache.hadoop.fs.FileSystem的介面),使用者可以在不改動應用原始碼的情況下,通過以下3個步驟,將目標檔案系統更改為Tachyon:
1.將對應版本Tachyon Client的jar包新增至執行環境的CLASSPATH中;
2.新增Hadoop配置項<“fs.tachyon.impl”, “tachyon.hadoop.TFS”>;
3.將原先的”hdfs://ip:port/file/X”路徑更改為”tachyon://ip:port/file/X”。
通常,使用者可以結合使用“HDFS相容介面”和“統一名稱空間”這兩個特性,將原先的大資料應用直接執行在Tachyon之上,而不需要進行任何程式碼和資料的遷移。
3.7 豐富的命令列式工具
Tachyon自帶了一個名為 “tfs”的命令列工具,能夠讓使用者以命令列的方式與Tachyon互動,而不需要編寫原始碼來檢視、新建、刪除Tachyon檔案。例如:

“tfs”工具提供的全部命令使用方式詳見Tachyon官方文件。
3.8 方便管理的WebUI
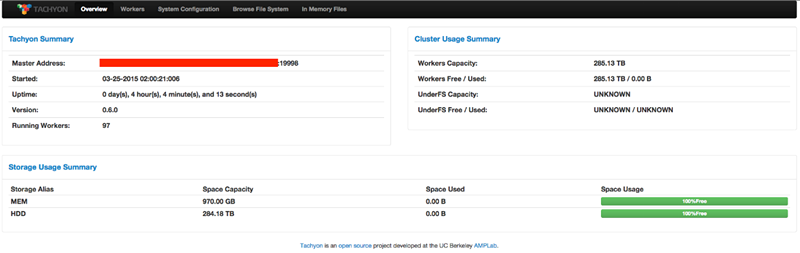
除了“tfs”工具外,Tachyon還在Tachyon Master和每個Tachyon Worker節點上啟動了一個網頁管理頁面,使用者可以通過瀏覽器開啟對應的WebUI(預設為http://:19999和http://:30000)。WebUI上列舉了整個Tachyon系統的基本資訊、所有Tachyon Worker的執行狀態、以及當前Tachyon系統的配置資訊。同時,使用者可以直接在WebUI上瀏覽整個Tachyon檔案系統、預覽檔案內容、甚至下載具體的某個檔案。
3.9 實時指標監控系統


對於高階使用者和系統管理人員,Tachyon提供了一套實時指標監控系統,實時地記錄和管理了Tachyon中一些重要的統計資訊,包括儲存容量使用情況、現有Tachyon檔案數、對檔案的操作次數、現有的資料塊數、對資料塊的操作次數、總共讀寫的位元組數等。根據使用者的配置,這些指標能夠以多種方式進行輸出:標準控制檯輸出、以CSV格式儲存為檔案、輸出到JMX控制檯、輸出到Graphite伺服器以及輸出到Tachyon的WebUI。
3.10支援Linux FUSE
Tachyon-FUSE是Tachyon最新開發版的新特性,由Tachyon Nexus和IBM共同主導開發。在Linux系統中,FUSE(Filesystem in Userspace,使用者空間檔案系統)模組使得使用者能將其他檔案系統掛載到本地檔案系統的某一目錄下,然後以統一的方式進行訪問。Tachyon-FUSE的出現使得使用者同樣可以將Tachyon檔案系統掛載到本地檔案系統中。通過Tachyon-FUSE,使用者/應用可以使用訪問本地檔案系統的方式來訪問Tachyon。這更加方便了使用者對Tachyon的管理和使用,以及現有基於FUSE介面的應用通過Tachyon進行記憶體加速或者資料共享。
4.Tachyon在百度大資料平臺的應用案例
在百度,我們從2014年底開始關注Tachyon。當時我們使用Spark SQL進行大資料分析工作,由於Spark是個基於記憶體的計算平臺,我們預計絕大部分的資料查詢應該在幾秒或者十幾秒完成以達到互動查詢的體驗。然而,我們卻發現實際查詢幾乎都需要上百秒才能完成,其原因在於我們的計算資源與資料倉儲可能並不在同一個資料中心。 在這種情況下,我們每一次資料查詢都可能需要從遠端的資料中心讀取資料,由於資料中心間的網路頻寬以及延時的問題,導致每次查詢都需要較長的時間(>100秒)才能完成。更糟糕的是,很多查詢的重複性或相似性很高,同樣的資料很可能會被查詢多次,如果每次都從遠端的資料中心讀取,必然造成資源浪費。
為了解決這個問題,在一年前我們藉助Tachyon管理遠端及本地資料讀取和排程,儘量避免跨資料中心讀資料。 當Tachyon被部署到Spark所在的資料中心後,每次資料冷查詢時,我們還是從遠端資料倉儲拉資料,但是當資料再次被查詢時, Spark將直接從同一資料中心的Tachyon中讀取資料, 從而提高查詢效能。在我們的環境和應用中實驗表明:如果是從非本機的Tachyon讀取資料的話,耗時降到10到15秒,比原來的效能提高了10倍; 最好的情況下,如果從本機的Tachyon讀資料,查詢僅需5秒,比原來的效能提高了30倍, 效果很明顯。除了效能的提高,更難能可貴的是Tachyon執行穩定,在過去一年中很好的支援著百度的互動式查詢業務, 而且社群在每一版迭代更新中都不斷提供更多的功能以及不斷提高系統的穩定性,讓業界對Tachyon系統更有信心。
在過去一個月,百度在為大規模使用Tachyon做準備,驗證Tachyon的可擴充套件性。我們使用Tachyon的最新版成功部署了1000個worker的Tachyon叢集,在本文完成時這應該是世界最大的Tachyon叢集。此叢集總共提供超過50TB的記憶體儲存,在百度內部已經穩定執行了一個月,現在有不同的百度業務在上面試執行以及壓力測試。在百度的圖搜變現業務上,我們與社群合作在Tachyon上搭建了一個高效能的Key/Value儲存,提供線上圖片服務。同時由於圖片直接存在Tachyon裡,我們的線下計算可以直接從Tachyon中讀取圖片。 這使得我們將線上以及線下系統整合成一個系統,既簡化了開發流程,也節省了儲存資源,達到了事半功倍的效果。本文篇幅有限,期待在後期給大家詳細介紹百度是1000 worker的Tachyon 叢集的實用案例,包括如何使用Tachyon整合線上線下的儲存資源等。
5.結語
作為一個以記憶體為中心、統一的分散式儲存系統,Tachyon極大地增強了大資料生態中儲存層的功能。雖然Tachyon專案相對還比較年輕,但已經很成熟穩定,並且已經在學術界以及工業界取得了成功。隨著整個計算機產業的發展,記憶體變的越來越便宜,在計算叢集中可使用的記憶體容量會不斷增長,我們相信Tachyon也必將會在大資料平臺中發揮越來越重要的作用。
現在Tachyon專案發展迅速,更多的功能也在逐步得到完善,應用前景也頗為廣闊。Tachyon正不斷地在支援更多的底層儲存系統(特別地,社群中已經有人正在實施支援阿里雲OSS儲存系統以及百度開放雲平臺,這對國內的使用者和開發者來說是個很好的機會);同時Tachyon也在實現安全性相關的支援,以充分滿足業界生成環境的需要;更進一步地,Tachyon目前更多地被視為檔案系統,而作為一個統一儲存系統,Tachyon也將支援更多的資料結構,以滿足不同計算框架的需要。在本文完成時Tachyon已經準備釋出下一版,有興趣的讀者們可以多關注Tachyon,到社群裡進行技術討論以及功能開發。
相關文章
- 騰訊重磅開源分散式NoSQL儲存系統DCache分散式SQL
- 基於Raft的分散式MySQL Binlog儲存系統開源Raft分散式MySql
- IPFS分散式儲存挖礦系統開發軟體技術分散式
- Bayou複製分散式儲存系統分散式
- IPFS分散式儲存挖礦技術系統開發分散式
- 雲端儲存及其分散式檔案系統分散式
- 提升Raft以加速分散式鍵值儲存Raft分散式
- 分散式儲存轉崗記分散式
- 分散式儲存系統可靠性:系統量化估算分散式
- GlusterFS分散式儲存系統中更換故障Brick的操作記錄分散式
- Disque:Redis之父新開源的分散式記憶體作業佇列Redis分散式記憶體佇列
- 浪潮儲存:以全快閃記憶體儲加速數字轉型記憶體
- 分散式儲存系統可靠性如何估算?分散式
- 分散式系統中資料儲存方案實踐分散式
- 不同體系分散式儲存技術的技術特性分散式
- InnoDB儲存引擎——記憶體儲存引擎記憶體
- 分散式儲存與傳統網路儲存系統相比有哪些區別分散式
- 分散式儲存系統的最佳實踐:系統發展路徑分散式
- 高效能分散式記憶體佇列系統beanstalkd(轉)分散式記憶體佇列Bean
- [技術思考]分散式儲存系統的雪崩效應分散式
- 必須掌握的分散式檔案儲存系統—HDFS分散式
- 分散式系統中的資料儲存方案實踐分散式
- 基於一致性雜湊的分散式記憶體鍵值儲存——CHKV分散式記憶體
- 360開源的類Redis儲存系統:PikaRedis
- 記憶體中的資料儲存記憶體
- 日誌: 分散式系統的核心分散式
- 分散式系統的核心問題分散式
- 分散式系統技術:儲存之資料庫分散式資料庫
- 杉巖PACS影像系統分散式儲存架構分散式架構
- 分散式kv儲存系統之Etcd叢集分散式
- 分散式 Key-Value 儲存系統:Cassandra 入門分散式
- Zipkin開源分散式跟蹤系統分散式
- Linux核心記憶體管子系統分析Linux記憶體
- 【大資料】BigTable分散式資料儲存系統分散式資料庫 | 複習筆記大資料分散式資料庫筆記
- 分散式塊儲存系統Ursa的設計與實現分散式
- GlusterFS分散式儲存學習筆記分散式筆記
- 儲存學習之開源儲存軟體
- Redis 分散式儲存Redis分散式