MySQL字符集和校對規則(Collation)
閱讀目錄:MySQL的字符集和校對規則
一、字符集(Character set)
是多個字元(英文字元,漢字字元,或者其他國家語言字元)的集合,字符集種類較多,每個字符集包含的字元個數不同。
特點:
①字元編碼方式是用一個或多個位元組表示字符集中的一個字元
②每種字符集都有自己特有的編碼方式,因此同一個字元,在不同字符集的編碼方式下,會產生不同的二進位制
常見字符集:
ASCII字符集:基於羅馬字母表的一套字符集,它採用1個位元組的低7位表示字元,高位始終為0。
LATIN1字符集:相對於ASCII字符集做了擴充套件,仍然使用一個位元組表示字元,但啟用了高位,擴充套件了字符集的表示範圍。
GBK字符集:支援中文,字元有一位元組編碼和兩位元組編碼方式。
UTF8字符集:Unicode字符集的一種,是電腦科學領域裡的一項業界標準,支援了所有國家的文字字元,utf8採用1-4個位元組表示字元。
1、MySQL與字符集
只要涉及到文字的地方,就會存在字符集和編碼方式。MySQL系統變數值:

2、正確使用字符集
資料庫服務端的字符集具體要看儲存什麼字元

以上這些引數如何起作用:
1.庫、表、列字符集的由來
①建庫時,若未明確指定字符集,則採用character_set_server指定的字符集。
②建表時,若未明確指定字符集,則採用當前庫所採用的字符集。
③新增時,修改表欄位時,若未明確指定字符集,則採用當前表所採用的字符集。
2.更新、查詢涉及到得字符集變數
更新流程字符集轉換過程:character_set_client-->character_set_connection-->表字符集。
查詢流程字符集轉換過程:表字符集-->character_set_result
3.character_set_database
當前預設資料庫的字符集,比如執行use xxx後,當前資料庫變為xxx,若xxx的字符集為utf8,那麼此變數值就變為utf8(供系統設定,無需人工設定)。
3、MySQL客戶端與字符集
1.對於輸入來說:
客戶端使用的字符集必須透過character_set_client、character_set_connection體現出來:
①在客戶端對資料進行編碼(Linux:utf8、windows:gbk)
②MySQL接到SQL語句後(比如insert),發現有字元,詢問客戶端透過什麼方式對字元編碼:客戶端透過character_set_client引數告知MySQL客戶端的編碼方式(所以此引數需要正確反映客戶端對應的編碼)
③當MySQL發現客戶端的client所傳輸的字符集與自己的connection不一樣時,會將client的字符集轉換為connection的字符集
④MySQL將轉換後的編碼儲存到MySQL表的列上,在儲存的時候再判斷編碼是否與內部儲存字符集(按照優先順序判斷字符集型別)上的編碼一致,如果不一致需要再次轉換
2.對於查詢來說:
客戶端使用的字符集必須透過character_set_results來體現,伺服器詢問客戶端字符集,透過character_set_results將結果轉換為與客戶端相同的字符集傳遞給客戶端。(character_set_results預設等於character_set_client)
4、MySQL字元編碼轉換原理:
問:若character_set_client為UTF8,而character_set_database為GBK,則會出現需要進行編碼轉換的情況,字符集轉換的原理是什麼?
答:假設gbk字符集的字串“你好”,需要轉為utf8字符集儲存,實際就是對於“你好”字串中的每個漢字去utf8編碼表裡面查詢對應的二進位制,然後儲存。

圖解字符集轉換過程:
①MySQL Server收到請求時將請求資料從character_set_client轉換為character_set_connection;
②進行內部操作前將請求資料從character_set_connection轉換為內部操作字符集
確定步驟:
--使用每個資料欄位的CHARACTER SET設定值;
--若上述值不存在,則使用對應資料表的DEFAULT CHARACTER SET設定值;
--若上述值不存在,則使用對應資料庫的DEFAULT CHARACTER SET設定值;
--若上述值不存在,則使用character_set_server設定值;
③將操作結果從內部操作字符集轉換為character_set_results。
5、字符集常見處理操作
1.檢視字符集編碼設定
mysql> show variables like '%character%';
2.設定字符集編碼
mysql> set names 'utf8';
相當於同時:
set character_set_client = utf8;
set character_set_results = utf8;
set character_set_connection = utf8;
3.修改資料庫字符集
mysql> alter database database_name character set xxx;
只修改庫的字符集,影響後續建立的表的預設定義;對於已建立的表的字符集不受影響。(一般在資料庫實現字符集即可,表和列都預設採用資料庫的字符集)
4.修改表的字符集
mysql> alter table table_name character set xxx;
只修改表的字符集,影響後續該表新增列的預設定義,已有列的字符集不受影響。
mysql> alter table table_name convert to character set xxx;
同時修改表字符集和已有列字符集,並將已有資料進行字符集編碼轉換。
5.修改列字符集
格式:
ALTER TABLE table_name MODIFY
column_name {CHAR | VARCHAR | TEXT} (column_length)
[CHARACTER SET charset_name]
[COLLATE collation_name]
mysql> alter table table_name modify col_name varchar(col_length) character set xxx;
6、字符集的正確實踐:
MySQL軟體工具本身是沒有字符集的,主要是因為工具所在的OS的字符集(Windows:gbk、Linux:utf8),所以字符集的正確實踐非常重要:
1.對於insert來說,character_set_client、character_set_connection相同,而且正確反映客戶端使用的字符集
2.對於select來說,character_set_results正確反映客戶端字符集
3.資料庫字符集取決於我們要儲存的字元型別
4.字符集轉換最多發生一次,這就要求character_set_client、character_set_connection相同
5.所有的字符集轉換都發生在資料庫端
綜述:
1、建立資料庫的時候注意字符集(gbk、utf8);
2、連線資料庫以後,無論是執行dml還是select,只要涉及到varchar、char列,就需要設定正確的字符集引數。
二、校對規則collation校對
字符集是一套符號和對應的編號
檢視資料庫支援的所有字符集(charset):
mysql> show character set;
校對規則(collation):
是在字符集內用於字元比較和排序的一套規則,比如有的規則區分大小寫,有的則無視。
mysql> create table t1(id int,name varchar(20)); #t1建表沒有指定校對規則
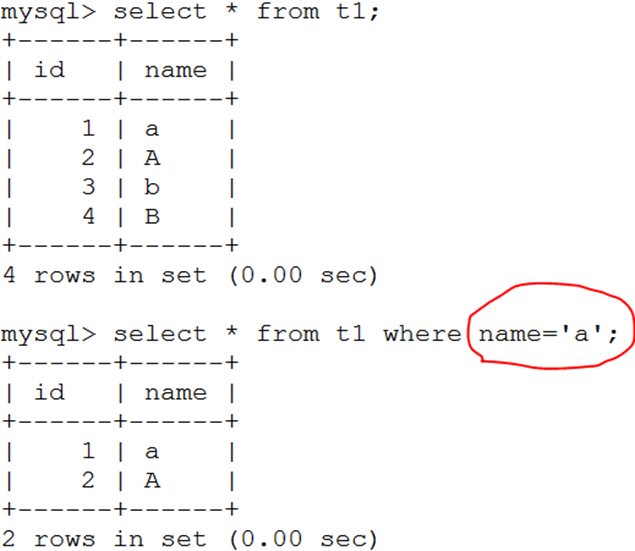
mysql> show collation; #檢視資料庫支援的所有校對規則
mysql> show variables like 'collation_%'; #檢視當前字符集和校對規則設定

校對規則特徵:
①兩個不同的字符集不能有相同的校對規則;
②每個字符集有一個預設校對規則;
③存在校對規則命名約定:以其相關的字符集名開始,中間包括一個語言名,並且以_ci(大小寫不敏感)、_cs(大小寫敏感)或_bin(二元)結束。
注意:
系統使用utf8字符集,若使用utf8_bin校對規則執行SQL查詢時區分大小寫,使用utf8_general_ci不區分大小寫(預設的utf8字符集對應的校對規則是utf8_general_ci)。
示例:
mysql> create table t2(id int,name varchar(20)) character set=gbk collate=gbk_bin; #t2建表指定校對規則(區分大小寫)

字符集:指符號和字元編碼的集合。
校對規則:比較字元編碼的方式。
GBK2312:主要包括簡體中文字元及常用符號,對於中文字元采用雙位元組編碼的格式,也就是說一個漢字字元在儲存佔兩個位元組。
GBK:包括有中、日、韓字元的大字符集,GB2312也是GBK的一個子集,就是說GB2312中的所有字元,GBK中全有,在這種情況下,我們也會將GBK稱為GB2312的超集,GBK也是雙位元組編碼的格式,將子集中的字元轉換成超集中儲存不會丟失資訊(出現亂碼);但反之則不一定。
UTF-8:它對於英文字符集使用一個位元組編碼,而對於多位元組符(如中文)則使用3個位元組編碼,UTF-8能夠支援大部分常見的字元,包括西、中、日、韓、法、俄等各種文字,因此意以上提到的幾種字符集都視為UTF-8的子集。
UTF-8MB4:它是UTF-8的超集,是MySQL5.5版本才引進的,其引進是為了處理像emoji這類表情字元,一個字元使用4個位元組編碼,能支援的字元最廣,但是相應占用的空間也最大。
一個字符集至少會有一個校對規則,顯示字符集的校對規則可以使用show collation 語句
mysql資料庫中字符集的校對規則都有一些共同的特點:
1.每種校對規則只能屬於一種字符集,
2.每個字符集都有一個預設的校對規則
3.校對規則的名稱也有規則,通常開頭的字元是校對規則所屬的字符集,而後是其所屬的語言,最後是校對規則型別的簡寫形式,有下列3種格式:
。_cs:全稱為case insensitive,這表示大小寫不敏感的規則
_cs:全稱為case sensitive,這表示大小寫敏感的規則
_bin :即binary,表示這是一個二元校對規則,話說二元規則也是一定是大小寫敏感規則
MySQL服務響應客戶端操作的字元的字符集和客戶端資訊處理過程:
1.客戶端發出的SQL語句,所使用的字符集由系統變數character_set_client來指定
2.MySQL服務端接收語句後,會用character_set_connection和collation_connection兩個系統變數中的設定,並且會將客戶端傳送的語句字符集由character_set_client轉到character_set_connection(除非使用者執行語句時,已經對字元列明確指定了字符集)。對於語句中指定的字串比較或排序,還需要應用collation_connection中指定的校對規則處理,而對於語句中指定的列的比較則無關collation_connection的設定了,因為物件的列表擁有自己的校對規則,他們擁有更高的優先順序
3.MySQL服務執行完語句後,會按照character_set_result系統變數設定的字符集返回結果集(或錯誤資訊)到客戶端。
可以用語句:show global variables like 'character_set_\%';檢視這些系統變數設定。
固化連線時的字符集設定:
SET NAMES和SET CHARACTER SET命令都是基於會話設定的,也就是說,僅作用於當前會話,退出登入後所做設定也就失效,如果希望設定長期有效,可以在啟動MySQL服務時,透過設定相關係統變數,達到永久生效的目的,可以到引數檔案my.ini增加一行:
[mysql]
default-character-set=gbk
這樣,只要我們使用mysql命令列工具連線伺服器後,連線的預設字符集就都會是設定好的GBK字符集。
一 什麼是字元校對規則
使用MySQL的大多數都知道字符集是一套符號和編碼,而對校驗本規則不太熟悉。校對規則是在字符集內用於比較字元的一套規則,可以控制 select 查詢時where 條件大小寫是否敏感的規則.如欄位 col 在表中的值為 'abc','ABC','AbC' 在不同的校對規則下,where col='ABC'會有不同的結果。
系統常用的字元校對規則
校對規則有如下特徵:
a 兩個不同的字符集不能有相同的校對規則。
b 每個字符集有一個預設校對規則。例如,utf8預設校對規則是utf8generalci
c 存在校對規則命名約定:它們以其相關的字符集名開始,通常包括一個語言名比如utf8,並且以ci(大小寫不敏感)、或bin(二元)結束 ,如 utf8_bin。
提示:
官方文件上說是有 cs(大小寫敏感) 但是show collation like 'utf8%'; 並沒有cs結尾的校對規則。
二 如何使用字元校對規則
MySQL 提供四種預設級別的字符集和校驗規則:伺服器級、資料庫級、表級,和連線級,一般欄位級別的不常用。
2.1 伺服器級
MySQL伺服器有一個伺服器字符集和一個伺服器校對規則,collationserver的預設字符集是在編譯mysql的時候編譯好的,比如
shell> ./configure --with-charset=utf8
或者:
shell> ./configure --with-charset=utf8 \
--with-collation=utf8generalci
如要要修改預設的字元校對規則,我們可以透過以下幾種方式:
a 在/etc/my.cnf 的[mysqld]中新增
collationserver = utf8bin
修改之後必須重啟
root@rac2 [(none)]> show variables like 'collation%';
+----------------------+-----------------+
| Variablename | Value |
+----------------------+-----------------+
| collationconnection | utf8generalci |
| collationdatabase | utf8bin |
| collationserver | utf8bin |
+----------------------+-----------------+
3 rows in set (0.00 sec)
b 透過mysqld 命令列新增 --character-set-server=utf8 --collation-server=utf8generalci
/usr/sbin/mysqld --defaults-file=/etc/my.cnf --basedir=/usr --datadir=/home/mysql/data3306/data --log-error=/home/mysql/data3306/log/master-error.log --pid-file=/home/mysql/data3306/data/rac3.pid --socket=/tmp/mysql.sock --port=3306 --character-set-server=utf8 --collation-server=utf8generalci &
注意:這篇文章描述的並不準確
https://dev.mysql.com/doc/refman/5.1/zh/charset.html#charset-column
透過
shell> mysqld --default-character-set=utf8 \
--default-collation=utf8generalci
方式啟動會報錯
140430 9:34:56 InnoDB: 1.1.8 started; log sequence number 1628178
140430 9:34:56 [ERROR] /usr/sbin/mysqld: unknown variable 'default-character-set=utf8'
140430 9:34:56 [ERROR] Aborting
伺服器級別字符集校對規則
root@rac2 [(none)]> show variables like 'collation%';
+----------------------+-----------------+
| Variablename | Value |
+----------------------+-----------------+
| collationconnection | utf8generalci |
| collationdatabase | utf8bin |
| collationserver | utf8_bin |
+----------------------+-----------------+
root@rac2 [dba]> create table t1(col varchar(5)) engine=innodb ;
Query OK, 0 rows affected (0.10 sec)
root@rac2 [dba]> insert into t1 values('abc'),('ABC'),('AbC');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
root@rac2 [dba]> select * from t1 where col='ABC';
+------+
| col |
+------+
| ABC |
+------+
1 row in set (0.01 sec)
root@rac2 [dba]> create table t2(col varchar(5)) engine=innodb default charset=utf8;
Query OK, 0 rows affected (0.11 sec)
root@rac2 [dba]> insert into t2 values('abc'),('ABC'),('AbC');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
root@rac2 [dba]> select * from t2 where col='ABC';
+------+
| col |
+------+
| abc |
| ABC |
| AbC |
+------+
3 rows in set (0.00 sec)
2.2 資料庫級別字元校對規則
每一個資料庫有一個資料庫字符集和一個資料庫校對規則。CREATE DATABASE和ALTER DATABASE語句有一個可選的子句來指定資料庫字符集和校對規則:
CREATE DATABASE dbname
[[DEFAULT] CHARACTER SET charsetname]
[[DEFAULT] COLLATE collation_name]
通常如果建立資料庫的時候不指定db的字符集和校對規則,則使用伺服器級別預設的校對規則。
如何修改資料庫級別的字元校對規則:
a 透過在建立資料庫時指定 collationdatabase 字符集。
b 透過ALTER DATABASE dbname [[DEFAULT] CHARACTER SET charsetname] [[DEFAULT] COLLATE collationname]
注意 在my.cnf 中的[mysql]或者[mysqld]中配置
collationdatabase=utf8_bin
會分別報錯:
mysql: unknown variable 'collationdatabase=utf8_bin'
140430 13:56:19 [ERROR] /usr/sbin/mysqld: unknown variable 'collation_database=utf8_bin'
140430 13:56:19 [ERROR] Aborting
例子
root@rac2 [(none)]> show variables like 'collation%';
+----------------------+-----------------+
| Variablename | Value |
+----------------------+-----------------+
| collationconnection | utf8generalci |
| collationdatabase | utf8bin |
| collationserver | utf8_bin |
+----------------------+-----------------+
3 rows in set (0.00 sec)
root@rac2 [(none)]> create database dba01;
Query OK, 1 row affected (0.00 sec)
root@rac2 [(none)]> use dba01
Database changed
root@rac2 [dba01]> CREATE TABLE t1(col varchar(5)) ;
Query OK, 0 rows affected (0.09 sec)
root@rac2 [dba01]> insert into t1 values('abc'),('ABC'),('AbC');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
root@rac2 [dba01]> select * from t1;
+------+
| col |
+------+
| abc |
| ABC |
| AbC |
+------+
3 rows in set (0.00 sec)
root@rac2 [dba01]> select * from t1 where col='abc';
+------+
| col |
+------+
| abc |
+------+
1 row in set (0.00 sec)
MySQL這樣選擇資料庫字符集和資料庫校對規則:
如果指定了CHARACTER SET X和COLLATE Y,那麼採用字符集X和校對規則Y。
如果指定了CHARACTER SET X而沒有指定COLLATE Y,那麼採用CHARACTER SET X和CHARACTER SET X的預設校對規則。否則,採用伺服器字符集和伺服器校對規則。
2.3 表級別的校對規則
每一個表有一個表字符集和一個校對規則,為指定表字符集和校對規則,CREATE TABLE 和ALTER TABLE語句有一個可選的子句:
CREATE TABLE tblname (columnlist)
[DEFAULT CHARACTER SET charsetname [COLLATE collationname]]
ALTER TABLE tblname
[DEFAULT CHARACTER SET charsetname] [COLLATE collationname]
例子:
root@rac2 [dba00]> CREATE TABLE t3(col varchar(5)) DEFAULT CHARACTER SET utf8 COLLATE utf8bin ;
Query OK, 0 rows affected (0.12 sec)
root@rac2 [dba00]> insert into t3 values('abc'),('ABC'),('AbC');
Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
root@rac2 [dba00]> select * from t3;
+------+
| col |
+------+
| abc |
| ABC |
| AbC |
+------+
3 rows in set (0.00 sec)
root@rac2 [dba00]> select * from t3 where col='abc';
+------+
| col |
+------+
| abc |
+------+
1 row in set (0.01 sec)
MySQL按照下面的方式選擇表字符集和 校對規則:
如果指定了CHARACTER SET X和COLLATE Y,那麼採用CHARACTER SET X和COLLATE Y。
如果指定了CHARACTER SET X而沒有指定COLLATE Y,那麼採用CHARACTER SET X和CHARACTER SET X的預設校對規則。
否則,採用伺服器字符集和伺服器校對規則。
如果在列定義中沒有指定列字符集和校對規則,則預設使用表字符集和校對規則。表字符集和校對規則是MySQL的擴充套件;在標準SQL中沒有。
2.4 連線字符集和校對規則詳見
文件 https://dev.mysql.com/doc/refman/5.1/zh/charset.html#charset-connection。
三 總結
資料庫查詢使用校對規則的優先順序 列>表>資料庫>伺服器,預設情況下會繼承當前字符集所對應預設的字符集校對規則,對於想要在查詢的時候區分大小寫情況而使用校對規則的話,最好建立資料庫和表的時候 就指定好期望的字元校對規則。
對於雲產品的RDS 小白客戶,顯然有些難了,需要使用文件來指引。
校對規則:在當前編碼下,字元之間的比較順序。(cs大小寫敏感,ci大小寫不敏感,bin二進位制編碼比較)
1. 檢視當前校對規則 show collation;
每個字符集都支援不定數量的校對規則,下圖為檢視結果的部分截圖:

tip : 以big5_chinese_ci為例,其中big5表示字符集,ci表示校對規則,即 “字符集_地區名_校對規則”;
校對規則是依賴字符集而存在的,在設定字符集時,可以設定當前字符集的校對規則。
如果不設定校對規則,字符集會使用預設的校對規則。
2. 檢視某種特定字符集下的校對規則 show collation like 'pattern';

3. 以 gbk 為例,比較chinese_cin和bin之間的區別:
![]()
![]()
設定新表 tb3 的校對規則為gbk_chinese_ci,而tb4的校對規則為gbk_bin;
show create table tb_name;檢視兩張表的建立資訊:


由於gbk_chinese_ci是預設校對規則,所以在tb3的建立資訊中,並不會寫出校對規則;
而tb4採用了非預設校對規則gbk_bin,右圖方框裡顯示了對應的設定。
對兩張表插入相同的三條資訊:

檢視此時,tb3 和 tb4 中的資料:


發現兩表中的資料是按照插入的順序排列的。
此時若使用排序關鍵字order by對兩表的資料進行排序,由於二者的校對規則不同,排序結果可能不同:
(order by :可以在獲得資料時,將資料按照某個欄位進行排序)


tb3是gbk_chinese_ci,不區分大小寫,所以排序結果是a、B、c ;
tb4是gbk_bin,按編碼二進位制逐位元組比較,a的ASC碼是97,B的ASC碼是 66 , c 的ASC碼是99,因此排序結果是 B、a、c ;
tip: 校對規則並不影響資料的儲存,只是影響資料的排序;
字符集影響資料的儲存。
常用的校對規則是gbk_chinese_ci。
4. 檢視當前伺服器端字符集的設定 show variables;
若要檢視character set相關的字符集設定,語句為 show variables like 'character_set%';

tip : client/connection/results是連線時所用到的編碼,
database表示當前所選擇的資料庫的字符集,用show create database db_name;檢驗:

mysql 修改表、列的字符集和校對規則
將表的所有資料轉為另外一種字符集和校對規則
To change the table default character set and all character columns (CHAR, VARCHAR, TEXT) to a new character set, use a statement like this:
ALTER TABLE tbl_name CONVERT TO CHARACTER SET charset_name [COLLATE collation_name];
The statement also changes the collation of all character columns. If you specify no COLLATE clause to indicate which collation to use, the statement uses default collation for the character set. If this collation is inappropriate for the intended table use (for example, if it would change from a case-sensitive collation to a case-insensitive collation), specify a collation explicitly.
For a column that has a data type of VARCHAR or one of the TEXT types, CONVERT TO CHARACTER SET will change the data type as necessary to ensure that the new column is long enough to store as many characters as the original column. For example, a TEXT column has two length bytes, which store the byte-length of values in the column, up to a maximum of 65,535. For a latin1 TEXT column, each character requires a single byte, so the column can store up to 65,535 characters. If the column is converted to utf8, each character might require up to three bytes, for a maximum possible length of 3 × 65,535 = 196,605 bytes. That length will not fit in a TEXT column's length bytes, so will convert the data type to MEDIUMTEXT, which is the smallest string type for which the length bytes can record a value of 196,605. Similarly, a VARCHAR column might be converted to MEDIUMTEXT.
注意:
使用convert to character set charset_name,如果轉換後的資料型別不能儲存全部資料,會發生資料型別變化。
比如text最多可以儲存65535個位元組,latin1字符集下,一個字元佔用一個位元組,所以也就是65535個字元,轉換為utf8,一個字元至多可以佔用3個位元組,所以,最壞的情況,轉換後就需要65535*3個位元組,超出text容量,Mysql會自動將資料型別轉為mediumtext
修改某列的字符集
To avoid data type changes of the type just described, do not use CONVERT TO CHARACTER SET. Instead, use MODIFY to change individual columns. For example:
ALTER TABLE t MODIFY latin1_text_col TEXT CHARACTER SET utf8;
ALTER TABLE t MODIFY latin1_varchar_col VARCHAR(M) CHARACTER SET utf8;
If you specify CONVERT TO CHARACTER SET binary, the CHAR, VARCHAR, and TEXT columns are converted to their corresponding binary string types (BINARY, VARBINARY, BLOB). This means that the columns no longer will have a character set and a subsequent CONVERT TO operation will not apply to them.
If charset_name is DEFAULT, the database character set is used.
修改某表的預設字符集和校對規則
只會對以後的列有影響,對已經建立的列,不會產生影響。
To change only the default character set for a table, use this statement:
ALTER TABLE tbl_name DEFAULT CHARACTER SET charset_name [COLLATE collation_name];參考
點選開啟連結
https://dev.mysql.com/doc/refman/5.7/en/alter-table.html
如下內容來自:
http://www.cnblogs.com/donqiang/articles/2057972.html
Liunx下修改字符集:
1.查詢MySQL的cnf檔案的位置
find / -iname '*.cnf' -print
/usr/share/mysql/my-innodb-heavy-4G.cnf
/usr/share/mysql/my-large.cnf
/usr/share/mysql/my-small.cnf
/usr/share/mysql/my-medium.cnf
/usr/share/mysql/my-huge.cnf
/usr/share/texmf/web2c/texmf.cnf
/usr/share/texmf/web2c/mktex.cnf
/usr/share/texmf/web2c/fmtutil.cnf
/usr/share/texmf/tex/xmltex/xmltexfmtutil.cnf
/usr/share/texmf/tex/jadetex/jadefmtutil.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-innodb-heavy-4G.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-large.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-small.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-medium.cnf
/usr/share/doc/MySQL-server-community-5.1.22/my-huge.cnf
2. 複製 small.cnf、my-medium.cnf、my-huge.cnf、my-innodb-heavy-4G.cnf其中的一個到/etc下,命名為my.cnf
cp /usr/share/mysql/my-medium.cnf /etc/my.cnf
3. 修改my.cnf
vi /etc/my.cnf
在[client]下新增
default-character-set=utf8
在[mysqld]下新增
default-character-set=utf8
4.重新啟動MySQL
[root@bogon ~]# /etc/rc.d/init.d/mysql restart
Shutting down MySQL [ 確定 ]
Starting MySQL. [ 確定 ]
[root@bogon ~]# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1
Server version: 5.1.22-rc-community-log MySQL Community Edition (GPL)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
5.檢視字符集設定
mysql> show variables like 'collation_%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3 rows in set (0.02 sec)
mysql> show variables like 'character_set_%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.02 sec)
mysql>
其他的一些設定方法:
修改資料庫的字符集
mysql>use mydb
mysql>alter database mydb character set utf-8;
建立資料庫指定資料庫的字符集
mysql>create database mydb character set utf-8;
透過配置檔案修改:
修改/var/lib/mysql/mydb/db.opt
default-character-set=latin1
default-collation=latin1_swedish_ci
為
default-character-set=utf8
default-collation=utf8_general_ci
重起MySQL:
[root@bogon ~]# /etc/rc.d/init.d/mysql restart
透過MySQL命令列修改:
mysql> set character_set_client=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_connection=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_database=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_results=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_server=utf8;
Query OK, 0 rows affected (0.00 sec)
mysql> set character_set_system=utf8;
Query OK, 0 rows affected (0.01 sec)
mysql> set collation_connection=utf8;
Query OK, 0 rows affected (0.01 sec)
mysql> set collation_database=utf8;
Query OK, 0 rows affected (0.01 sec)
mysql> set collation_server=utf8;
Query OK, 0 rows affected (0.01 sec)
檢視:
mysql> show variables like 'character_set_%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.03 sec)
mysql> show variables like 'collation_%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3 rows in set (0.04 sec)
-------------------------------------------------------------------------
【知識性文章轉載】
MYSQL 字符集問題
MySQL的字符集支援(Character Set Support)有兩個方面:
字符集(Character set)和排序方式(Collation)。
對於字符集的支援細化到四個層次:
伺服器(server),資料庫(database),資料表(table)和連線(connection)。
1.MySQL預設字符集
MySQL對於字符集的指定可以細化到一個資料庫,一張表,一列,應該用什麼字符集。
但是,傳統的程式在建立資料庫和資料表時並沒有使用那麼複雜的配置,它們用的是預設的配置,那麼,預設的配置從何而來呢? (1)編譯MySQL 時,指定了一個預設的字符集,這個字符集是 latin1;
(2)安裝MySQL 時,可以在配置檔案 (my.ini) 中指定一個預設的的字符集,如果沒指定,這個值繼承自編譯時指定的;
(3)啟動mysqld 時,可以在命令列引數中指定一個預設的的字符集,如果沒指定,這個值繼承自配置檔案中的配置,此時 character_set_server 被設定為這個預設的字符集;
(4)當建立一個新的資料庫時,除非明確指定,這個資料庫的字符集被預設設定為character_set_server;
(5)當選定了一個資料庫時,character_set_database 被設定為這個資料庫預設的字符集;
(6)在這個資料庫裡建立一張表時,表預設的字符集被設定為 character_set_database,也就是這個資料庫預設的字符集;
(7)當在表內設定一欄時,除非明確指定,否則此欄預設的字符集就是表預設的字符集;
簡單的總結一下,如果什麼地方都不修改,那麼所有的資料庫的所有表的所有欄位的都用
latin1 儲存,不過我們如果安裝 MySQL,一般都會選擇多語言支援,也就是說,安裝程式會自動在配置檔案中把
default_character_set 設定為 UTF-8,這保證了預設情況下,所有的資料庫的所有表的所有欄位的都用 UTF-8 儲存。
2.檢視預設字符集(預設情況下,mysql的字符集是latin1(ISO_8859_1)
通常,檢視系統的字符集和排序方式的設定可以透過下面的兩條命令:
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | latin1 |
| character_set_connection | latin1 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | latin1 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
mysql> SHOW VARIABLES LIKE 'collation_%';
+----------------------+-----------------+
| Variable_name | Value |
+----------------------+-----------------+
| collation_connection | utf8_general_ci |
| collation_database | utf8_general_ci |
| collation_server | utf8_general_ci |
+----------------------+-----------------+
3.修改預設字符集
(1) 最簡單的修改方法,就是修改mysql的my.ini檔案中的字符集鍵值,
如 default-character-set = utf8
character_set_server = utf8
修改完後,重啟mysql的服務,service mysql restart
使用 mysql> SHOW VARIABLES LIKE 'character%';檢視,發現資料庫編碼均已改成utf8
+--------------------------+---------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | D:"mysql-5.0.37"share"charsets" |
+--------------------------+---------------------------------+
(2) 還有一種修改字符集的方法,就是使用mysql的命令
mysql> SET character_set_client = utf8 ;
MySQL中涉及的幾個字符集
character-set-server/default-character-set:伺服器字符集,預設情況下所採用的。
character-set-database:資料庫字符集。
character-set-table:資料庫表字符集。
優先順序依次增加。所以一般情況下只需要設定character-set-server,而在建立資料庫和表時不特別指定字符集,這樣統一採用character-set-server字符集。
character-set-client:客戶端的字符集。客戶端預設字符集。當客戶端向伺服器傳送請求時,請求以該字符集進行編碼。
character-set-results:結果字符集。伺服器向客戶端返回結果或者資訊時,結果以該字符集進行編碼。
在客戶端,如果沒有定義character-set-results,則採用character-set-client字符集作為預設的字符集。所以只需要設定character-set-client字符集。
要處理中文,則可以將character-set-server和character-set-client均設定為GB2312,如果要同時處理多國語言,則設定為UTF8。
關於MySQL的中文問題
解決亂碼的方法是,在執行SQL語句之前,將MySQL以下三個系統引數設定為與伺服器字符集character-set-server相同的字符集。
character_set_client:客戶端的字符集。
character_set_results:結果字符集。
character_set_connection:連線字符集。
設定這三個系統引數透過向MySQL傳送語句:set names gb2312
關於GBK、GB2312、UTF8
UTF- 8:Unicode Transformation Format-8bit,允許含BOM,但通常不含BOM。是用以解決國際上字元的一種多位元組編碼,它對英文使用8位(即一個位元組),中文使用24為(三個位元組)來編碼。UTF-8包含全世界所有國家需要用到的字元,是國際編碼,通用性強。UTF-8編碼的文字可以在各國支援UTF8字符集的瀏覽器上顯示。如,如果是UTF8編碼,則在外國人的英文IE上也能顯示中文,他們無需下載IE的中文語言支援包。
GBK是國家標準GB2312基礎上擴容後相容GB2312的標準。GBK的文字編碼是用雙位元組來表示的,即不論中、英文字元均使用雙位元組來表示,為了區分中文,將其最高位都設定成1。GBK包含全部中文字元,是國家編碼,通用性比UTF8差,不過UTF8佔用的資料庫比GBD大。
GBK、GB2312等與UTF8之間都必須透過Unicode編碼才能相互轉換:
GBK、GB2312--Unicode--UTF8
UTF8--Unicode--GBK、GB2312
對於一個網站、論壇來說,如果英文字元較多,則建議使用UTF-8節省空間。不過現在很多論壇的外掛一般只支援GBK。
GB2312是GBK的子集,GBK是GB18030的子集
GBK是包括中日韓字元的大字符集合
如果是中文的網站 推薦GB2312 GBK有時還是有點問題
為了避免所有亂碼問題,應該採用UTF-8,將來要支援國際化也非常方便
UTF-8可以看作是大字符集,它包含了大部分文字的編碼。
使用UTF-8的一個好處是其他地區的使用者(如香港臺灣)無需安裝簡體中文支援就能正常觀看你的文字而不會出現亂碼。
gb2312是簡體中文的碼
gbk支援簡體中文及繁體中文
big5支援繁體中文
utf-8支援幾乎所有字元
首先分析亂碼的情況
1.寫入資料庫時作為亂碼寫入
2.查詢結果以亂碼返回
究竟在發生亂碼時是哪一種情況呢?
我們先在mysql 命令列下輸入
show variables like '%char%';
檢視mysql 字符集設定情況:
mysql> show variables like '%char%';
+--------------------------+----------------------------------------+
| Variable_name | Value |
+--------------------------+----------------------------------------+
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | gbk |
| character_set_filesystem | binary |
| character_set_results | gbk |
| character_set_server | gbk |
| character_set_system | utf8 |
| character_sets_dir | /usr/local/mysql/share/mysql/charsets/ |
+--------------------------+----------------------------------------+
在查詢結果中可以看到mysql 資料庫系統中客戶端、資料庫連線、資料庫、檔案系統、查詢
結果、伺服器、系統的字符集設定
在這裡,檔案系統字符集是固定的,系統、伺服器的字符集在安裝時確定,與亂碼問題無關
亂碼的問題與客戶端、資料庫連線、資料庫、查詢結果的字符集設定有關
*注:客戶端是看訪問mysql 資料庫的方式,透過命令列訪問,命令列視窗就是客戶端,通
過JDBC 等連線訪問,程式就是客戶端
我們在向mysql 寫入中文資料時,在客戶端、資料庫連線、寫入資料庫時分別要進行編碼轉
換
在執行查詢時,在返回結果、資料庫連線、客戶端分別進行編碼轉換
現在我們應該清楚,亂碼發生在資料庫、客戶端、查詢結果以及資料庫連線這其中一個或多
個環節
接下來我們來解決這個問題
在登入資料庫時,我們用mysql --default-character-set=字符集-u root -p 進行連線,這時我們
再用show variables like '%char%';命令檢視字符集設定情況,可以發現客戶端、資料庫連線、
查詢結果的字符集已經設定成登入時選擇的字符集了
如果是已經登入了,可以使用set names 字符集;命令來實現上述效果,等同於下面的命令:
set character_set_client = 字符集
set character_set_connection = 字符集
set character_set_results = 字符集
如果碰到上述命令無效時,也可採用一種最簡單最徹底的方法:
一、Windows
1、中止MySQL服務
2、在MySQL的安裝目錄下找到my.ini,如果沒有就把my-medium.ini複製為一個my.ini即可
3、開啟my.ini以後,在[client]和[mysqld]下面均加上default-character-set=utf8,儲存並關閉
4、啟動MySQL服務
要徹底解決編碼問題,必須使
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | gbk |
| character_set_results | gbk |
| character_set_server | gbk |
| character_set_system | utf8
這些編碼相一致,都統一。
如果是透過JDBC 連線資料庫,可以這樣寫URL:
URL=jdbc:mysql://localhost:3306/abs?useUnicode=true&characterEncoding=字符集
JSP 頁面等終端也要設定相應的字符集
資料庫的字符集可以修改mysql 的啟動配置來指定字符集,也可以在create database 時加上
default character set 字符集來強制設定database 的字符集
透過這樣的設定,整個資料寫入讀出流程中都統一了字符集,就不會出現亂碼了
為什麼從命令列直接寫入中文不設定也不會出現亂碼?
可以明確的是從命令列下,客戶端、資料庫連線、查詢結果的字符集設定沒有變化
輸入的中文經過一系列轉碼又轉回初始的字符集,我們檢視到的當然不是亂碼
但這並不代表中文在資料庫裡被正確作為中文字元儲存
舉例來說,現在有一個utf8 編碼資料庫,客戶端連線使用GBK 編碼,connection 使用預設
的ISO8859-1(也就是mysql 中的latin1),我們在客戶端傳送“中文”這個字串,客戶端
將傳送一串GBK 格式的二進位制碼給connection 層,connection 層以ISO8859-1 格式將這段
二進位制碼傳送給資料庫,資料庫將這段編碼以utf8 格式儲存下來,我們將這個欄位以utf8
格式讀取出來,肯定是得到亂碼,也就是說中文資料在寫入資料庫時是以亂碼形式儲存的,
在同一個客戶端進行查詢操作時,做了一套和寫入時相反的操作,錯誤的utf8 格式二進位制
碼又被轉換成正確的GBK 碼並正確顯示出來。
mysql 修改表的預設字符集和修改表欄位的預設字符集
之前設計資料庫的時候,所有的字符集都是設定的utf-8,後來發現儲存iPhone自帶的表情的時候會失敗,所以想改為utf-8mb4的,又不想一個欄位一個欄位得改,找了以下資料:
修改表的預設字符集:
ALTER TABLE table_name DEFAULT CHARACTER SET character_name;
修改表欄位的預設字符集:
ALTER TABLE table_name CHANGE field field field_type CHARACTER SET character_name [other_attribute]
修改表的預設字符集和所有列的字符集:
ALTER TABLE table_name CONVERT TO CHARACTER SET character_name
注意:my.cnf中必須加上character-set-server=utf8mb4屬性,才可以正常使用,只改資料庫、表和欄位的字符集不行。
資料來源:http://my.oschina.net/u/147332/blog/222116
About Me
.............................................................................................................................................
● 本文整理自網路,若有侵權請聯絡小麥苗刪除
● 本文在itpub(http://blog.itpub.net/26736162/abstract/1/)、部落格園(http://www.cnblogs.com/lhrbest)和個人微信公眾號(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文部落格園地址:http://www.cnblogs.com/lhrbest
● 本文pdf版、個人簡介及小麥苗雲盤地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 資料庫筆試面試題庫及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● DBA寶典今日頭條號地址:
.............................................................................................................................................
● QQ群號:230161599(滿)、618766405
● 微信群:可加我微信,我拉大家進群,非誠勿擾
● 聯絡我請加QQ好友(646634621),註明新增緣由
● 於 2017-09-01 09:00 ~ 2017-09-30 22:00 在魔都完成
● 文章內容來源於小麥苗的學習筆記,部分整理自網路,若有侵權或不當之處還請諒解
● 版權所有,歡迎分享本文,轉載請保留出處
.............................................................................................................................................
● 小麥苗的微店:
● 小麥苗出版的資料庫類叢書:http://blog.itpub.net/26736162/viewspace-2142121/
.............................................................................................................................................
使用微信客戶端掃描下面的二維碼來關注小麥苗的微信公眾號(xiaomaimiaolhr)及QQ群(DBA寶典),學習最實用的資料庫技術。

小麥苗的微信公眾號 小麥苗的DBA寶典QQ群1 小麥苗的DBA寶典QQ群2 小麥苗的微店
.............................................................................................................................................






來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/26736162/viewspace-2144469/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- MySQL字符集和校對規則(character set & collation)MySql
- mysql的字符集校對規則MySql
- 【勝通】mysql連線通道中的字符集和校驗規則MySql
- 【MySQL】資料庫字元校對規則MySql資料庫字元
- 【勝通 】mysql字符集與校驗規則的設定MySql
- 塗抹MySQL--第6章 開源運動與開源軟體MySQL - 6.1字符集和校對規則MySql
- 從根上理解 MySQL 的字符集和比較規則MySql
- TiDB 6.0 新特性解讀 | Collation 規則TiDB
- TiDB 6.0 新特性解讀丨 Collation 規則TiDB
- 關於mysql字符集及排序規則設定MySql排序
- 《Oracle MySQL程式設計自學與面試指南》05:字符集和校對集OracleMySql程式設計面試
- MySQL 字符集與亂碼與collation設定的問題?MySql
- SQLServer的排序規則(字符集編碼)SQLServer排序
- 前端Vue中常用rules校驗規則前端Vue
- 校驗檔案的搜尋規則
- 正整數表單校驗規則
- 資料庫建庫時字符集和排序規則的選擇資料庫排序
- 對線面試官:Mysql組合索引的生效規則面試MySql索引
- 2021-2-18:請你說說MySQL的字符集與排序規則對開發有哪些影響?MySql排序
- Angular8 form 表單對隱藏元素取消表單校驗規則AngularORM
- laravel 校驗規則 Rule::in 等對中文字元不友好的問題Laravel字元
- MySQL中的排序規則MySql排序
- 【MySQL】批次修改排序規則MySql排序
- mysql字符集和字元排序MySql字元排序
- Mysql-基本的規則與規範MySql
- MYSQL collation 選好還能換嗎MySql
- SpringBoot專案校驗規則優化Spring Boot優化
- sentinel流控規則校驗之原始碼分析原始碼
- Vue中form表單常用rules校驗規則VueORM
- springMVC:校驗框架:多規則校驗,巢狀校驗,分組校驗;ssm整合技術SpringMVC框架巢狀SSM
- MySQL鎖(四)行鎖的加鎖規則和案例MySql
- element-ui自定義表單校驗規則及常用表單校驗UI
- 管理規則和基於規則的轉換——流
- 使用jakarta.validation自定義校驗規則
- MySQL觸發器的使用規則MySql觸發器
- MySQL索引選擇及規則整理MySql索引
- 對於同步的規則定義
- Makefile基本規則和原理