實時計算,流資料處理系統簡介與簡單分析
實時計算,流資料處理系統簡介與簡單分析
一. 實時計算的概念
實時計算一般都是針對海量資料進行的,一般要求為秒級。
實時計算主要分為兩塊:資料的實時入庫、資料的實時計算。
主要應用的場景:
1) 資料來源是實時的不間斷的,要求使用者的響應時間也是實時的(比如對於大型網站的流式資料:網站的訪問pv/uv、使用者訪問了什麼內容、搜尋了什麼內容等,實時的資料計算和分析可以動態實時地重新整理使用者訪問資料,展示網站實時流量的變化情況,分析每天各小時的流量和使用者分佈情況)
2) 資料量大且無法或沒必要預算,但要求對使用者的響應時間是實時的。
昨天來自每個省份不同性別的訪問量分佈
昨天來自每個省份不同性別不同年齡不同職業不同名族的訪問量分佈
二. 實時計算的相關技術
主要分為三個階段(大多是日誌流):
資料的產生與收集階段、傳輸與分析處理階段、儲存對對外提供服務階段
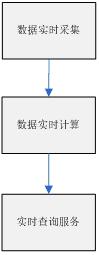
下面具體針對上面三個階段詳細介紹下
1)資料實時採集:
需求:功能上保證可以完整的收集到所有日誌資料,為實時應用提供實時資料;響應時間上要保證實時性、低延遲在1秒左右;配置簡單,部署容易;系統穩定可靠等。
目前的產品:Facebook的Scribe、LinkedIn的Kafka、Cloudera的Flume,淘寶開源的TimeTunnel、Hadoop的Chukwa等,均可以滿足每秒數百MB的日誌資料採集和傳輸需求。他們都是開源專案。
2)資料實時計算
在流資料不斷變化的運動過程中實時地進行分析,捕捉到可能對使用者有用的資訊,並把結果傳送出去。
實時計算目前的主流產品:
1. Yahoo的S4:S4是一個通用的、分散式的、可擴充套件的、分割槽容錯的、可插拔的流式系統,Yahoo開發S4系統,主要是為了解決:搜尋廣告的展現、處理使用者的點選反饋。
2. Twitter的storm:是一個分散式的、容錯的實時計算系統。可用於處理訊息和更新資料庫(流處理),在資料流上進行持續查詢,並以流的形式返回結果到客戶端(持續計算),並行化一個類似實時查詢的熱點查詢(分散式的RPC)。
3. Facebook 的Puma:facebook使用puma和HBase相結合來處理實時資料,另外facebook發表一篇利用HBase/Hadoop進行實時資料處理的論文(ApacheHadoop Goes Realtime at Facebook),通過一些實時性改造,讓批處理計算平臺也具備實時計算的能力。
關於這三個產品的具體介紹架構分析:
http://www.kuqin.com/system-analysis/20120111/317322.html
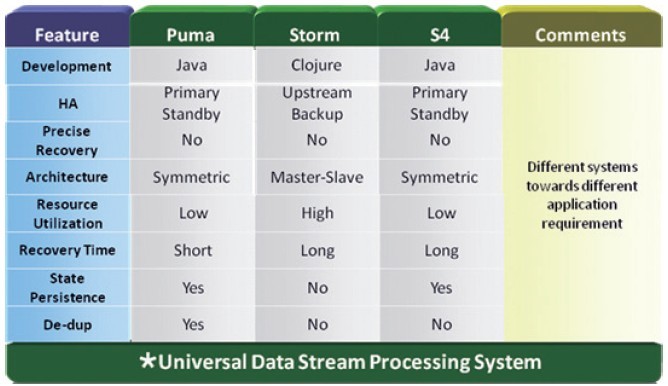
下面是s4和storm的詳細對比
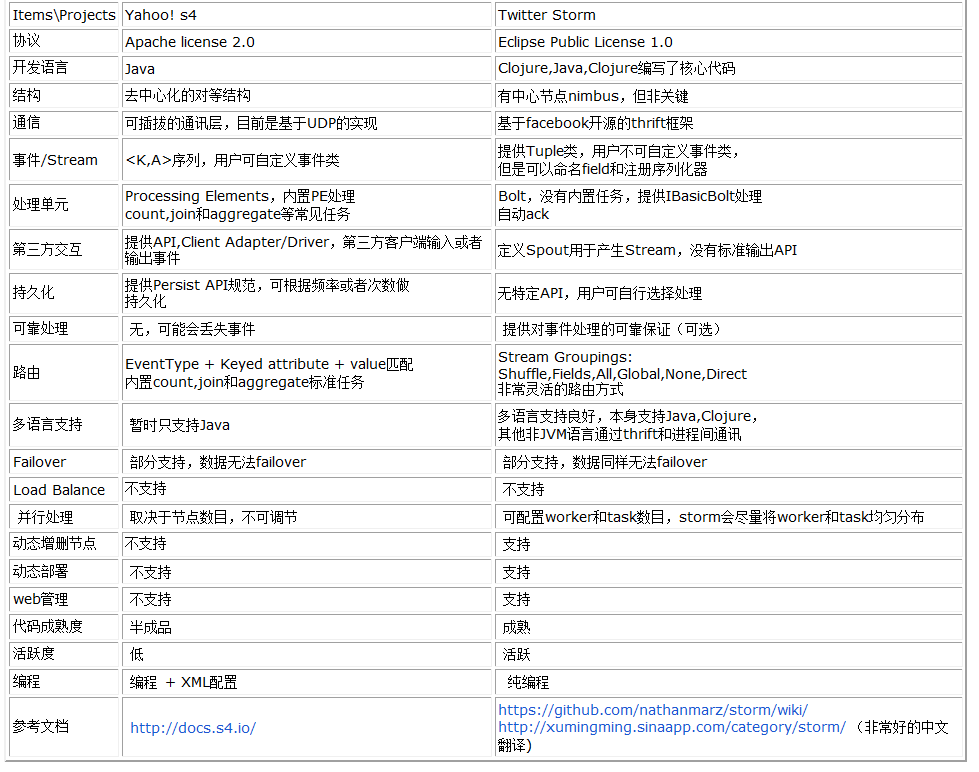
其他的產品:
早期的:IBM的StreamBase, Borealis
Hstreaming、Esper
4. 淘寶的實時計算、流式處理
1) 銀河流資料處理平臺:通用的流資料實時計算系統,以實時資料產出的低延遲、高吞吐和複用性為初衷和目標,採用actor模型構建分散式流資料計算框架(底層基於akka),功能易擴充套件、部分容錯、資料和狀態可監控。銀河具有處理實時流資料(如TimeTunnel收集的實時資料)和靜態資料(如本地檔案、HDFS檔案)的能力,能夠提供靈活的實時資料輸出,並提供自定義的資料輸出介面以便擴充套件實時計算能力。銀河目前主要是為魔方提供實時的交易、瀏覽和搜尋日誌等資料的實時計算和分析。
2) 基於storm的流式處理,統計計算、持續計算、實時訊息處理。
在淘寶,storm被廣泛用來進行實時日誌處理,出現在實時統計、實時風控、實時推薦等場景中。一般來說,我們從類kafka的metaQ或者基於hbase的timetunnel中讀取實時日誌訊息,經過一系列處理,最終將處理結果寫入到一個分散式儲存中,提供給應用程式訪問。我們每天的實時訊息量從幾百萬到幾十億不等,資料總量達到TB級。對於我們來說,storm往往會配合分散式儲存服務一起使用。在我們正在進行的個性化搜尋實時分析專案中,就使用了timetunnel + hbase + storm + ups的架構,每天處理幾十億的使用者日誌資訊,從使用者行為發生到完成分析延遲在秒級。
3) 利用Habase實現的online應用
3)實時查詢服務
全記憶體:直接提供資料讀取服務,定期dump到磁碟或資料庫進行持久化。
半記憶體:使用Redis、Memcache、MongoDB、BerkeleyDB等記憶體資料庫提供資料實時查詢服務,由這些系統進行持久化操作。
全磁碟:使用HBase等以分散式檔案系統(HDFS)為基礎的NoSQL資料庫,對於key-value引擎,關鍵是設計好key的分佈。
關於實時計算流資料分析應用舉例:
對於電子商務網站上的店鋪:
1) 實時展示一個店鋪的到訪顧客流水資訊,包括訪問時間、訪客姓名、訪客地理位置、訪客IP、訪客正在訪問的頁面等資訊;
2) 顯示某個到訪顧客的所有歷史來訪記錄,同時實時跟蹤顯示某個訪客在一個店鋪正在訪問的頁面等資訊;
3) 支援根據訪客地理位置、訪問頁面、訪問時間等多種維度下的實時查詢與分析。

下面對storm詳細介紹下:
整體架構圖
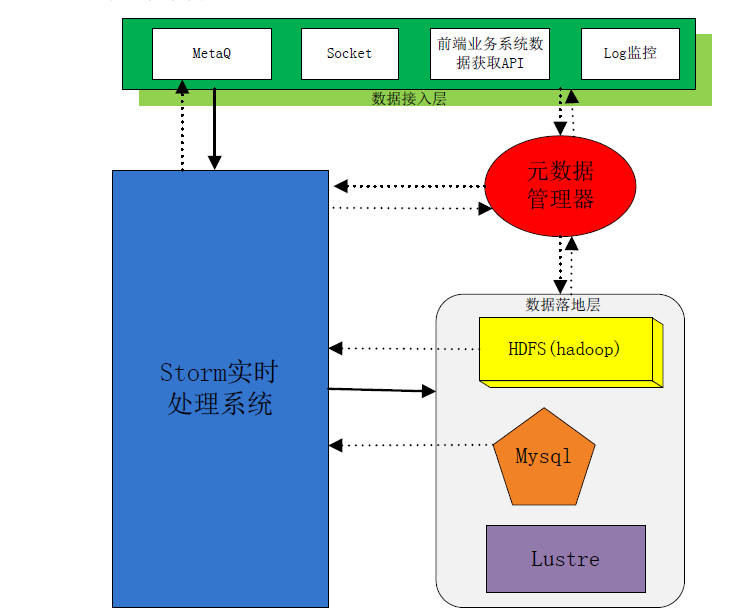
架構說明:
整個資料處理流程包括四部分
第二部分是最重要的storm 實時處理部分,資料從接入層接入,經過實時處理後傳入資料落地層;
第三部分為資料落地層,該部分指定了資料的落地方式;
第四部分後設資料管理器。
資料接入層:
該部分有多種資料收集方式,包括使用訊息佇列(MetaQ),直接通過網路Socket傳輸資料,前端業務系統專有資料採集API,對Log問價定時監控。(注:有時候我們的資料來源是已經儲存下來的log檔案,那Spout就必須監控Log檔案的變化,及時將變化部分的資料提取寫入Storm中,這很難做到完全實時性。)
Storm實時處理層
首先我們通過一個 storm 和hadoop的對比來了解storm中的基本概念。
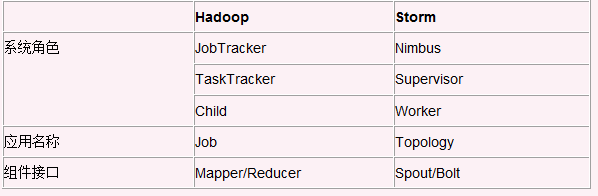
(Storm關注的是資料多次處理一次寫入,而hadoop關注的是資料一次寫入,多次處理使用(查詢)。Storm系統執行起來後是持續不斷的,而hadoop往往只是在業務需要時呼叫資料。兩者關注及應用的方向不一樣。)
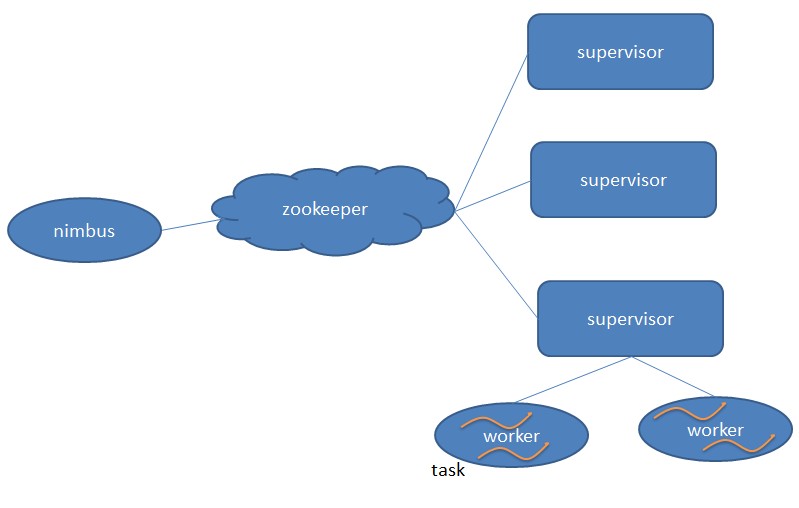
1. Nimbus:負責資源分配和任務排程。
2. Supervisor:負責接受nimbus分配的任務,啟動和停止屬於自己管理的worker程式。
3. Worker:執行具體處理元件邏輯的程式。
4. Task:worker中每一個spout/bolt的執行緒稱為一個task. 在storm0.8之後,task不再與物理執行緒對應,同一個spout/bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
{kind=link}
{kind=link}
具體業務需求:條件過濾、中間值計算、求topN、推薦系統、分散式RPC、熱度統計
資料落地層:
MetaQ
如圖架構所示,Storm與MetaQ是有一條虛線相連的,部分資料在經過實時處理之後需要寫入MetaQ之中,因為後端業務系統需要從MetaQ中獲取資料。這嚴格來說不算是資料落地,因為資料沒有實實在在寫入磁碟中持久化。
Mysql
資料量不是非常大的情況下可以使用Mysql作為資料落地的儲存物件。Mysql對資料後續處理也是比較方便的,且網路上對Mysql的操作也是比較多的,在開發上代價比較小,適合中小量資料儲存。
HDFS
HDFS及基於Hadoop的分散式檔案系統。許多日誌分析系統都是基於HDFS搭建出來的,所以開發Storm與HDFS的資料落地介面將很有必要。例如將大批量資料實時處理之後存入Hive中,提供給後端業務系統進行處理,例如日誌分析,資料探勘等等。
Lustre
Lustre作為資料落地的應用場景是,資料量很大,且處理後目的是作為歸檔處理。這種情形,Lustre能夠為資料提供一個比較大(相當大)的資料目錄,用於資料歸檔儲存。
後設資料管理器
後設資料管理器的設計目的是,整個系統需要一個統一協調的元件,指導前端業務系統的資料寫入,通知實時處理部分資料型別及其他資料描述,及指導資料如何落地。後設資料管理器貫通整個系統,是比較重要的組成部分。後設資料設計可以使用mysql儲存後設資料資訊,結合快取機制開源軟體設計而成。
相關文章
- 實時流處理框架Apache Flink簡介框架Apache
- 《Storm實時資料處理》一1.1 簡介ORM
- 事件流處理 (ESP) 與 Kafka 簡介事件Kafka
- Hadoop大資料分散式處理系統簡介Hadoop大資料分散式
- [翻譯]Kafka Streams簡介: 讓流處理變得更簡單Kafka
- 日誌和實時流計算處理
- 簡單批處理內部命令簡介
- Java的簡單理解(22)---處理流Java
- 平行計算與Neon簡介
- 簡單實現批處理
- 計算機控制技術課程簡介與資料計算機
- ACCESS 在資料表中實現簡單計算
- 街面環衛演算法影片分析伺服器流動商販實時影片流分析邊緣計算技術簡介演算法伺服器
- 設計模式實踐---策略+簡單工廠對大量計算公式的處理設計模式公式
- js dom元素事件處理簡單介紹JS事件
- 簡單的資料表統計
- Oracle實時資料整合工具簡介SBOracle
- redux簡單實現與分析Redux
- 實時計算 Flink> 產品簡介——最新動態
- iOS中獲取當前時間與簡單的處理iOS
- JavaScript簡單計算器程式碼分析JavaScript
- java 如何簡單快速處理 xml 中的資料JavaXML
- 實時計算無線資料分析
- SQL Server 2008事件處理系統簡介LSSQLServer事件
- 雲端計算情報局預告|告別 Kafka Streams,讓輕量級流處理更加簡單Kafka
- 簡單的字串處理字串
- 簡單的文字處理
- 串的簡單處理
- 伺服器系統簡單分析伺服器
- 瀑布流簡單實現
- Scrapy架構及資料流圖簡介架構
- 快速部署DBus體驗實時資料流計算
- 簡單介紹Python中異常處理用法Python
- javascript事件處理函式繫結簡單介紹JavaScript事件函式
- EXCEL的重生!處理百萬行資料竟如此簡單Excel
- java 如何簡單快速處理 json 中的資料JavaJSON
- DB2--資料庫管理系統簡介DB2資料庫
- POP簡單介紹與使用實踐