當流量尖峰到達時,在 Linux 核心中解決網路問題

幾周前,我們開始注意位於華盛頓的追蹤API的伺服器網路流量有很大的變化。從一個相當穩定的日常模式下,我們開始看到300-400 Mbps尖峰流量,但我們的合法的流量(事件和人為更新)是不變的。
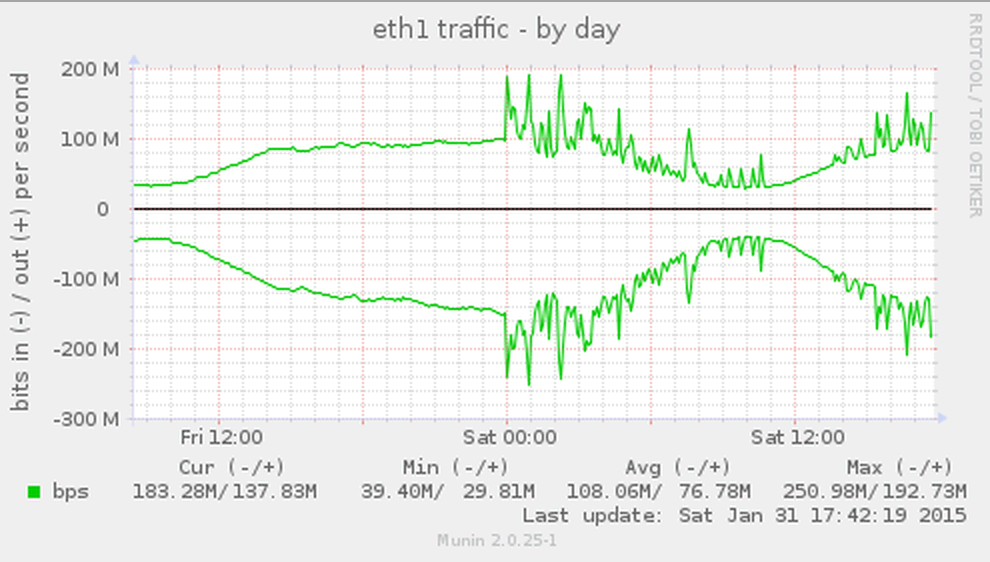
突然,我們的網路流量開始飆升像瘋了似的。
找到虛假的流量來源是當務之急,因為這些尖峰流量正觸發我們的上游路由器啟動DDOS減災模式來阻止流量。
有一些很好的內建的Linux工具幫助診斷網路問題。
-
ifconfig 會顯示你的網路介面和多少資料包透過他們
-
ethtool -S 會顯示你的資料包流的一些更詳細的資訊,象在網路卡級丟棄的資料包的數量。
-
iptables -L -v -n 將顯示你的各種防火牆規則處理資料包數。
-
netstat -s 會告訴由核心網路協議棧維護的一大堆的計數器值,例如ACK的數量,重發的數量等。
-
sysctl -a | grep net.ip 將顯示你所有kernel中網路相關的設定。
-
tcpdump 將顯示進出包的內容。
解決問題的線索是使用netstat -s命令的輸出。 不幸的是,當你檢查這個命令的輸出的時候,還很難告訴這些數字意味著什麼,應該是什麼,以及它們是如何改變的。為了檢查他們是如何變化的,我們建立了一個小程式來顯示連續執行命令的輸出,這讓我們瞭解各種計數器變化的快慢。有一行輸出看起來特別令人擔憂。
![]()
此計數器的通常速率在未受影響的伺服器上一般是 30-40 /秒,所以我們知道肯定是哪裡出問題了。計數器表明我們正拒絕大量的包,因為這些包含有無效的 TCP 時間戳。臨時的快速解決方案是用下面的命令關閉 TCP 時間戳:
sysctl -w net.ipv4.tcp_timestamps=0這立即導致了包風暴停止。但是這不是一個永久性的解決方案,因為 TCP 時間戳是用於測量往返時間和分配資料包流中的延遲包到正確位置。在高速連線的時候這將成為一個問題,TCP 序列號可能在數秒間隔內纏繞。關於 TCP 的時間戳和效能的詳細資訊,請看 RFC 1323。
在 Mixpanel,每當我們看到異常流量模式的時候,我們一般也執行 tcpdump,這樣我們能夠分析流量,然後試圖確定根本原因。我們發現大量的 TCP ACK 資料包在我們的 API 伺服器和一個特定的 IP 地址之間來回傳送。結果我們的伺服器陷入到向另一臺伺服器來來回回傳送 TCP ACK 包的無限迴圈裡面。一個主機持續地發出 TCP 時間戳,但是另一主機卻不能識別這是有效的時間戳。
這時,我們意識到我們正在處理一個只能在 Linux 核心的 TCP 協議棧才能解決問題。所以我們的 CTO求助於 linux-netdev 看看是否能找到一個解決方案。值得慶幸的是我們發現這個問題已經遇到過的,並且有一個解決方案。原來,這種型別的包風暴可以由一些硬體故障或第三方改變 TCP SEQ,ACK,或連線中的主機認為對方傳送過期的資料包所觸發。避免讓這種情況變成一個包風暴的方法是限制速度,設定 Linux 傳送重複的 ACK 資料包速度為每秒一個或兩個。這裡有一個非常好的解釋。
我們將接受這個補丁而且將之移植到當前正在使用的Ubuntu(Trusty)核心當中。感謝Ubuntu讓這一切變得非常簡單,重新編譯修補過的核心僅僅只需要執行下面的命令,安裝生成的.deb包並重啟系統。
# 下載核心原始碼並構建依賴
apt-get build-dep linux-image-3.13.0-45-generic
apt-get source linux-image-3.13.0-45-generic
# 應用補丁
cd linux-lts-trusty-3.13.0/
patch -p1 < Mitigate-TCP-ACK-Loops.patch
# 構建核心
fakeroot ./debian/rules clean
fakeroot ./debian/rules binary-headers binary-generic相關文章
- 在 Linux 核心中診斷網路流量異常問題Linux
- 在Linux中,如何實時監控網路流量?Linux
- linux下檢視當前網路流量Linux
- linux配置靜態路由解決網路問題Linux路由
- 在Oracle網路結構中解決連線問題Oracle
- 在Linux上安裝Oracle時DISPLAY問題解決方案LinuxOracle
- Linux配置靜態IP解決無法訪問網路問題Linux
- 網路問題導致更多的資料中心中斷
- 解決oracle網路連線問題Oracle
- LINUX 解決時間同步問題(NTP)Linux
- 解決內、外網同時訪問問題
- 在Oracle的網路結構中解決連線問題(轉)Oracle
- linux網路流量實時監控指令碼Linux指令碼
- 解決Mac無法共享網路問題Mac
- 流量卡哪個最划算?解決流量卡選擇問題
- 卷積核大小選擇、網路層數問題卷積
- 解決 Ubuntu 在啟動時凍結的問題Ubuntu
- Linux下網路流量實時監控工具大全Linux
- 深入分析網路通訊,Wireshark助你解決網路問題!
- 解決linux不能上外網的問題Linux
- Laradock 網路問題不能下載解決
- DNS解析(網路切換的問題解決)DNS
- 在Linux中,ansible可以解決哪些問題?Linux
- 從網路鏈路到跨域問題跨域
- 壓測平臺 - 使用 LVS 負載均衡解決網路流量成為瓶頸的問題負載
- 解決 go get 超時問題Go
- 暫時解決的中文問題
- ORA問題解決網站網站
- Linux網路流量安全審計Linux
- 關於網路硬體配置出現問題,無法上網問題的解決
- 解決Redmine建立&更新問題時很慢的問題
- Django在Linux上uwsgi 與nginx的問題與解決DjangoLinuxNginx
- 解決在PUTTY下Linux顯示亂碼的問題Linux
- 國外代理ip能夠解決哪些網路問題
- 四招解決無線網路訊號太弱問題
- 私域流量運營正當時,創利樹助力解決核心痛點
- 網路效能監控與流量回溯分析 - 輕鬆診斷網路問題
- 解決「問題」,不要解決問題