在現代web應用開發中,資料扮演著越來越重要的角色:通過資料我們能夠知道系統哪些地方有待改進,從而迭代開發重新上線,
隨後再次通過資料我們來評估新的迭代開發是否滿足了我們的預期目標,從而形成了一個資料驅動開發的業務閉環。這個閉環之所以
能夠工作,其原因就是我們能夠蒐集到web應用使用資料,從而能夠對這些資料進行分析。
本文就對web行為資料蒐集做一個簡單探討。
下面的內容摘自: http://www.admin10000.com/document/1089.html
文章確實不錯。
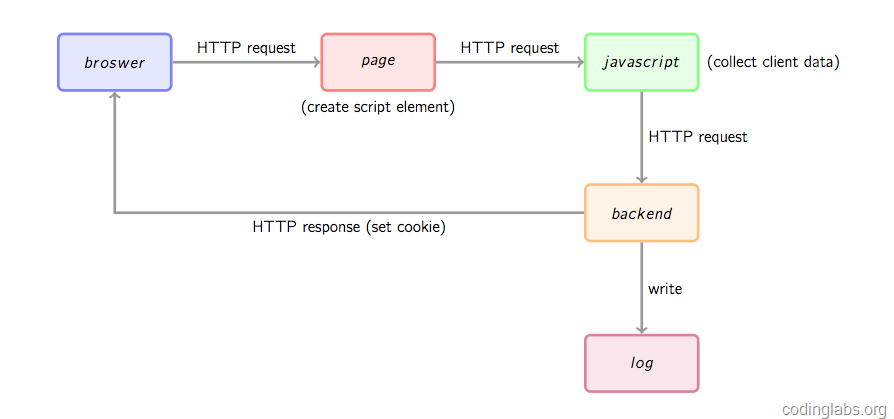
上圖是一個類似百度統計,GA工作時網站統計資料收集的基本流程圖,介紹如下:
1.瀏覽器向被統計頁面發起http請求開啟頁面;
2.開啟頁面時,頁面中的GA埋點js片段就會被執行,而這段程式碼一般來說就是執行一小段js,動態建立一個script標籤,並且將其src指向google或者baidu的單獨的js檔案,而這個js檔案本身才是真正的資料收集指令碼;
3.將上述動態script標籤插入到頁面dom中,隨後該頁面就向baidu/google請求那個js檔案,該檔案下載後立即執行,該檔案往往通過蒐集比如作業系統,螢幕尺寸,瀏覽器名稱等資訊,隨後這個js就會向後端請求訪問;
4.但是由於javascript的跨域訪問限制,往往在上述3.的步驟中並不會直接通過ajax呼叫後端服務,而使用了一個小的tip:將收集到的客戶端資料放在url引數中,去向後端請求返回偽裝1x1px image的後端指令碼;
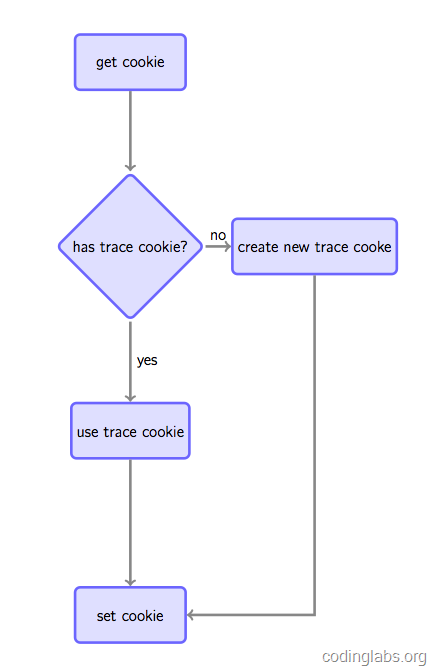
5.後端指令碼獲取上面的引數,插入資料庫中,同時要檢視是否已經在客戶瀏覽器中種下cookie(用於標識使用者唯一ID),如果有種過,則依然使用它,如果沒有,則新建立一個UIDCookie,並且在返回image響應中以set-cookie頭關鍵字返回到客戶端瀏覽器,這樣瀏覽器就建立或者更新自己的cookie,從而對baidu/google使用者跟蹤打下堅實的基礎:(現代需求方廣告平臺DSP就依賴這些cookie及)