hive命令的3中呼叫方式
hive命令的3種呼叫方式
方式1:hive –f /root/shell/hive-script.sql(適合多語句)
hive-script.sql類似於script一樣,直接寫查詢命令就行
例如:
[root@cloud4 shell]# vi hive_script3.sql
select * from t1;
select count(*) from t1;
不進入互動模式,執行一個hive script
這裡可以和靜音模式-S聯合使用,通過第三方程式呼叫,第三方程式通過hive的標準輸出獲取結果集。
$HIVE_HOME/bin/hive -S -f /home/my/hive-script.sql (不會顯示mapreduct的操作過程)
方式2:hive -e 'sql語句'(適合短語句)
直接執行sql語句
例如:
[root@cloud4 shell]# hive -e 'select * from t1'
靜音模式:
[root@cloud4 shell]# hive -S -e 'select * from t1' (用法與第一種方式的靜音模式一樣,不會顯示mapreduce的操作過程)
此處還有一亮點,用於匯出資料到linux本地目錄下
例如:
[root@cloud4 shell]# hive -e 'select * from t1' > test.txt
有點類似pig匯出分析結果一樣,都挺方便的
方式3:hive (直接使用hive互動式模式)
都挺方便的
介紹一種有意思的用法:
1.sql的語法
hive>quit; 退出hive
hive> show databases; 檢視資料庫
hive> create database test; 建立資料庫
hive> use default; 使用哪個資料庫
hive>create table t1 (key
string); 建立表
對於建立表我們可以選擇讀取檔案欄位按照什麼字元進行分割
例如:
hive>create table
t1(id ) '/wlan'
partitioned by (log_date string) 表示通過log_date進行分割槽
row format delimited fields terminated by '\t' 表示代表用‘\t’進行分割來讀取欄位
stored as textfile/sequencefile/rcfile/; 表示檔案的儲存的格式
儲存格式的參考地址:
textfile 預設格式,資料不做壓縮,磁碟開銷大,資料解析開銷大。
可結合Gzip、Bzip2使用(系統自動檢查,執行查詢時自動解壓),但使用這種方式,hive不會對資料進行切分,從而無法對資料進行並行操作。
例項:
[plain] 我在csdn收藏的有
-
> create table test1(str STRING)
-
> STORED AS TEXTFILE;
-
OK
-
Time taken: 0.786 seconds
-
#寫指令碼生成一個隨機字串檔案,匯入檔案:
-
> LOAD DATA LOCAL INPATH '/home/work/data/test.txt' INTO TABLE test1;
-
Copying data from file:/home/work/data/test.txt
-
Copying file: file:/home/work/data/test.txt
-
Loading data to table default.test1
-
OK
-
Time taken: 0.243 seconds
SequenceFile是Hadoop API提供的一種二進位制檔案支援,其具有使用方便、可分割、可壓縮的特點。
SequenceFile支援三種壓縮選擇:NONE, RECORD, BLOCK。 Record壓縮率低,一般建議使用BLOCK壓縮。
示例:
[plain] 我在csdn收藏的有
-
> create table test2(str STRING)
-
> STORED AS SEQUENCEFILE;
-
OK
-
Time taken: 5.526 seconds
-
hive> SET hive.exec.compress.output=true;
-
hive> SET io.seqfile.compression.type=BLOCK;
-
hive> INSERT OVERWRITE TABLE test2 SELECT * FROM test1;
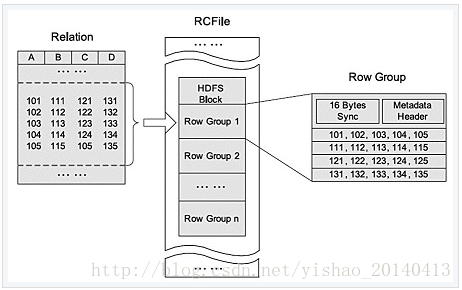
例項:
[plain] 我在csdn收藏的有
-
> create table test3(str STRING)
-
> STORED AS RCFILE;
-
OK
-
Time taken: 0.184 seconds
-
> INSERT OVERWRITE TABLE test3 SELECT * FROM test1;
總結:
相比textfile和SequenceFile,rcfile由於列式儲存方式,資料載入時效能消耗較大,但是具有較好的壓縮比和查詢響應。資料倉儲的特點是一次寫入、多次讀取,因此,整體來看,rcfile相比其餘兩種格式具有較明顯的優勢。
hive>show tables; 檢視該資料庫中的所有表
hive>show tables ‘*t*’; //支援模糊查詢
hive>show partitions t1; //檢視錶有哪些分割槽
hive>drop table t1 ; 刪除表hive不支援修改表中資料,但是可以修改表結構,而不影響資料
有local的速度明顯比沒有local慢:
hive>load data inpath '/root/inner_table.dat' into table t1; 移動hdfs中資料到t1表中
hive>load data local inpath '/root/inner_table.dat' into table t1; 上傳本地資料到hdfs中
hive> !ls; 查詢當前linux資料夾下的檔案hive> dfs -ls /; 查詢當前hdfs檔案系統下 '/'目錄下的檔案
希望通過共享自己的筆記,來找到一群和我一樣願意分享筆記和心得的朋友,讓大家一起進步
我的QQ:529815144,外號:小頭
相關文章
- Hive shell 命令Hive
- exe呼叫DLL的方式
- [Hive]呼叫本地模式,避免使用MapReduceHive模式
- 數倉工具—Hive的其他語言呼叫(15)Hive
- api呼叫方式API
- 一種WebService的呼叫方式Web
- 一起學Hive——使用MSCK命令修復Hive分割槽Hive
- 函式的呼叫方式和引數函式
- JS的五種函式呼叫方式JS函式
- es請求方式呼叫
- Hive學習之常用互動命令Hive
- MySQL入門--如何呼叫命令列命令MySql命令列
- php 直接呼叫svn命令PHP
- 以 Laravel 的方式呼叫 ai 客戶端LaravelAI客戶端
- PHP 以 SOAP 方式呼叫介面PHP
- Python呼叫C/C++方式PythonC++
- Hive --------- hive 的優化Hive優化
- Linux中source命令的使用方式Linux
- 3 種使用 PostgreSQL 命令的方式SQL
- linux中xargs命令的使用方式Linux
- 命令列下Git呼叫IDEA的diff功能命令列GitIdea
- pycharm怎麼呼叫命令列PyCharm命令列
- 微服務之間的呼叫方式哪種最佳?微服務
- 說說Java非同步呼叫的幾種方式Java非同步
- 函式呼叫的三種方式 __cdecl、__stdcall、__fastcall函式AST
- 呼叫java介面的方式有哪些?Java
- react+dva+antd介面呼叫方式React
- 兩條命令搞定 ChatGPT API 的呼叫問題ChatGPTAPI
- SAP ABAP Function Module 的動態呼叫方式使用方式介紹試讀版Function
- C#方法呼叫追溯:選擇正確的方式,輕鬆找到呼叫者C#
- oc與swift檔案的相互呼叫方式——橋接Swift橋接
- SAP Commerce Cloud 裡的 Site API 呼叫方式講解CloudAPI
- Springboot呼叫Oracle儲存過程的幾種方式Spring BootOracle儲存過程
- @PathVariable @RequestParam @RequestBody @ModelAttribute的區別及RestTemplate呼叫方式REST
- CloudFoundry命令列和Kubernetes命令列的Restful API消費方式Cloud命令列RESTAPI
- 0459-如何使用SQuirreL通過JDBC連線CDH的Hive(方式一)UIJDBCHive
- Hive常用命令,快鍵和關鍵詞Hive
- 淺談非同步呼叫幾種方式非同步
- Hive-常見調優方式 && 兩個面試sqlHive面試SQL