機器學習——邊角料
演算法設計的一大原則
\mathrm{sophisticated\, algorithm \leq simple\, learning\, algorithm + good\, training\, data.}
sigmoid型函式
\sigma(z)=\frac1{1+\exp(-z)}
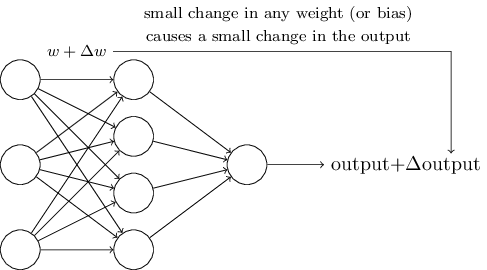
注意一點,在神經網路引入sigmoid型函式的目的是避免,對權重一個微小的改變可能對輸出帶來的顯著的改變,這一情況的發生(以此我們來進行微調)。
\sigma(\cdot)
完美地將整個實數域的值對映到(0,1)
區間(對應著概率probability?)。
何謂向量化一個函式(vectorizing a function )
也即是將函式作用於向量中的每一個元素得到的輸出再組合成一個向量。舉例說明:
a'=\sigma(wa+b)
其中
w
是一個二階權值矩陣(代表前後兩個layer中的神經元之間的權重),a
是一個向量(表示前一層每一個神經元的輸出組成的向量),b
表示上一層向下一層的偏置,\sigma(\cdot)
是sigmoid型函式。
def sigmoid(z):
return 1/(1+np.exp(-z))
# 此時sigmoid接收的是一個向量,sigmoid(z)的做法正是一種vectorize 的做法
a = sigmoid(w.dot(a)+b)
單層神經網路的增廣(augmentation)形式
z=w1x1+w2x2+…+wdxdϕ(z)={0ifz≤θ1ifz>θ \begin{equation} z=w_1x_1+w_2x_2+\ldots+w_dx_d\\ \phi(z)=\left \{ \begin{array}{l} 0\qquad if \quad z \leq \theta\\ 1\qquad if \quad z > \theta \end{array} \right. \end{equation}為了形式的簡單和統一,可將上式轉換如下形式:
z′===−θ+w1x1+w2x2+…+wdxdw0x0+w1x1+…+wdxdwTx \begin{equation} \begin{split} z'=&-\theta+w_1x_1+w_2x_2+\ldots+w_dx_d\\ =&w_0x_0+w_1x_1+\ldots+w_dx_d\\ =&w^Tx \end{split} \end{equation}也即是:
⎛⎝⎜⎜⎜⎜x1x2⋮xd⎞⎠⎟⎟⎟⎟d⇒⎛⎝⎜⎜⎜⎜⎜⎜⎜x0x1x2⋮xd⎞⎠⎟⎟⎟⎟⎟⎟⎟d+1 \begin{equation} \begin{pmatrix} x_1\\ x_2\\ \vdots\\ x_d \end{pmatrix}_d\Rightarrow \begin{pmatrix} x_0\\ x_1\\ x_2\\ \vdots\\ x_d \end{pmatrix}_{d+1} \end{equation}⎛⎝⎜⎜⎜⎜w1w2⋮wd⎞⎠⎟⎟⎟⎟d⇒⎛⎝⎜⎜⎜⎜w0w1⋮wd⎞⎠⎟⎟⎟⎟d+1 \begin{equation} \begin{pmatrix} w_1\\ w_2\\ \vdots\\ w_d \end{pmatrix}_d\Rightarrow \begin{pmatrix} w_0\\ w_1\\ \vdots\\ w_d \end{pmatrix}_{d+1} \end{equation}ϕ(z′)={0ifz′≤θ1ifz′>θ \begin{equation} \phi(z')=\left \{ \begin{array}{l} 0\qquad if \quad z'\leq\theta\\ 1\qquad if \quad z'>\theta \end{array} \right. \end{equation}轉換後的形式是原來形式的增廣形式,即分別對特徵向量
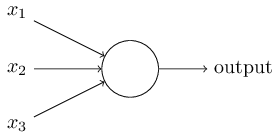
x x和權值向量做一維的增廣,w0=−θ,x0=1 w_0=-\theta, x_0=1neuron單輸出還是多輸出?
答案是單輸出(single output)
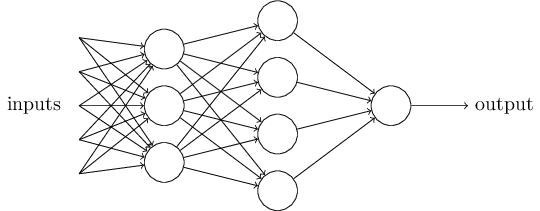
通常我們看到的關於多層感知機(perceptron)網路的圖示如上圖。然而,這樣的圖有一種“迷惑性的”一點是,對於每一個神經元節點(neuron)而言,它們都是多輸入和單輸出,雖然從一個神經元出來的箭頭指向下一層的每一個節點,其實輸出的每一個值都是相等的,這樣做只是出於一個直觀的需要。人工神經元從perceptron到sigmoid neuron
引入sigmoid neuron(
S型神經元)的目的是避免對權值(w1,…,wd w_1,\ldots, w_d)或者偏置(bias,w0 w_0)的小幅修改可能對最終的輸出造成的比較大的變化,比如分類問題中,將-1判斷為1,手寫識別例子中將8錯分為9。
z=wTxσ(z)=11+e−z \begin{split} &z=w^Tx\\ &\sigma(z)=\frac{1}{1+e^{-z}} \end{split}
σ(⋅) \sigma(\cdot)實現了原始輸入(−∞,∞) (-\infty, \,\infty)向(0,1) (0, \,1)的對映(map),實現了一種值域的收縮,也可實現降低輸入(weigts、bias)的小幅修改對輸出可能造成的影響,如此我們可放心地調整引數,實現更優的結果,而不會出現,因輸入的變化可能造成的結果的跳變。
相關文章
- css圓角矩形邊框CSS
- button設定邊寬和圓角
- css設定四角邊框CSS
- CSS3邊框與圓角CSSS3
- 機器學習實戰-邊學邊讀python程式碼(5)機器學習Python
- 機器學習實戰-邊學邊讀python程式碼(4)機器學習Python
- 如何實現css漸變圓角邊框CSS
- Flutter 彩邊圓角 Container 的實現FlutterAI
- 13 - CSS3 - 邊框圓角 - 鐘錶CSSS3
- unocss如何簡寫特定的邊角半徑CSS
- 【三角函式】已知直角三角形的斜邊長度和一個銳角角度,求另外兩條直角邊的長度函式
- 《Java效能優化權威指南》的邊邊角(2)——理解JVM-系統鎖Java優化JVM
- Winform窗體圓角以及描邊完美解決方案ORM
- 巧用 CSS 實現炫彩三角邊框動畫CSS動畫
- 帶圓角的虛線邊框?CSS 不在話下CSS
- QLC只是邊角料?宏旺半導體盤點那些對QLC固態硬碟的誤解硬碟
- 《Java效能優化權威指南》的邊邊角(3)——生存代和記憶體洩漏Java優化記憶體
- 利用元素邊框巧妙的畫三角形
- 訊號、系統與訊號處理邊角雜談
- 邊玩邊學!互動式視覺化圖解!快收藏這18個機器學習和資料科學網站!⛵視覺化圖解機器學習資料科學網站
- 直播平臺原始碼,自定義設定 View 四個角的圓角 以及邊框的設定原始碼View
- JS邊角料: NodeJS+AutoJS+WebSocket+TamperMonkey實現區域網多端文字互傳NodeJSWeb
- 【火爐煉AI】機器學習048-Harris檢測影像角點AI機器學習
- 《Java效能優化權威指南》的邊邊角(5)——被我們搬運的豆瓣讀書筆記Java優化筆記
- 《Java效能優化權威指南》的邊邊角(1)——如果你發現日誌中只有Full GCJava優化GC
- PCB 板邊倒圓角的實現方法(基本演算法一)演算法
- 視訊直播原始碼,css實現圖片對角邊框線原始碼CSS
- 用CSS實現三角形和平行四邊形CSS
- 用 CSS 實現三角形與平行四邊形CSS
- Android學習之 圓角邊框的幾種實現方式Android
- 常見機器學習用例TOP 7,在你身邊無處不在機器學習
- 直播app系統原始碼,Flutter MaterialButton 實現圓角邊框按鈕APP原始碼Flutter
- CSS-邊距2-實現一個三角形CSS
- border-image實現與圓角漸變邊框例項頁面
- 低程式碼是如何幫助500強企業,解決數字化轉型邊角料問題的?
- 機器學習-資料清洗機器學習
- 機器學習 大資料機器學習大資料
- 我愛機器學習--機器學習方向資料彙總機器學習