[CS231N課程筆記] Lecture 2. Image Classification
課程note:http://cs231n.github.io/classification/
這一節課程主要介紹以下幾個部分:影象識別的基本概念、最近鄰分類器、驗證集/交叉驗證集。
Image Classification
關於影象識別的基本概念,學過影象處理課程的同學們,基本上都知道了。
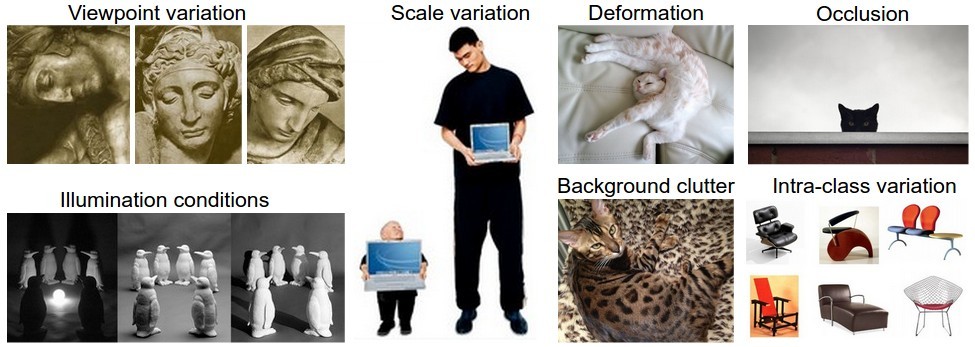
我這裡重點記錄一下,影象識別中面臨的幾個挑戰:
1. Viewpoint variation. A single instance of an object can be oriented in many ways with respect to the camera.
2. Scale variation. Visual classes often exhibit variation in their size (size in the real world, not only in terms of their extent in the image).
3. Deformation. Many objects of interest are not rigid bodies and can be deformed in extreme ways.
4. Occlusion. The objects of interest can be occluded. Sometimes only a small portion of an object (as little as few pixels) could be visible.
5. Illumination conditions. The effects of illumination are drastic on the pixel level.
6. Background clutter. The objects of interest may blend into their environment, making them hard to identify.
7. Intra-class variation. The classes of interest can often be relatively broad, such as chair. There are many different types of these objects, each with their own appearance.
Nearest Neighbor Classifier
import os
import numpy as np
import cPickle
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in xrange(num_test):
distances = np.sum(np.abs(self.Xtr.astype(int) - X[i, :].astype(int)), axis=1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
def load_CIFAR10(file_path):
file_names = os.listdir(file_path)
train_list = list()
train_data = list()
train_label = list()
for fname in file_names:
if fname.startswith('data_batch'):
full_path = os.path.join(file_path, fname)
fo = open(full_path, 'rb')
train_dict = cPickle.load(fo)
train_data.extend(train_dict['data'])
train_label.extend(train_dict['labels'])
fo.close()
if fname.startswith('test_batch'):
full_path = os.path.join(file_path, fname)
fo = open(full_path, 'rb')
test_dict = cPickle.load(fo)
test_data = test_dict['data']
test_label = test_dict['labels']
fo.close()
return np.array(train_data), np.array(train_label), test_data, np.array(test_label)
if __name__ == "__main__":
Xtr, Ytr, Xte, Yte = load_CIFAR10('/home/jeremy/Data/cifar-10-batches-py/')
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32*32*3)
Xte_rows = Xte.reshape(Xte.shape[0], 32*32*3)
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yte_predict = nn.predict(Xte_rows)
print "accuracy: %f" % (np.mean(Yte_predict==Yte))
L1 vs. L2.
It is interesting to consider differences between the two metrics. In particular, the L2 distance is much more unforgiving than the L1 distance when it comes to differences between two vectors. That is, the L2 distance prefers many medium disagreements to one big one. L1 and L2 distances (or equivalently the L1/L2 norms of the differences between a pair of images) are the most commonly used special cases of a p-norm.
Validation sets for Hyperparameter tuning
上面的演算法設計中,我們是利用Nearest Neighbor分類器中最相似的label作為結果,不過,這裡,我們其實還有一個改進方法:那就是考慮前k個最相似的結果的labels,然後利用這些labels進行投票得到最佳的結果。這是一個自然的改進方法,不過由此我們面臨了一個問題,那就是k的取值我們要怎麼設定??
其實,不僅僅是k的值需要設定,我們該選擇哪種距離度量方式(L1 or L2)也是需要我們設定的。
我們統一將這些需要設定的引數稱為: Hyperparameters
These choices are called hyperparameters and they come up very often in the design of many Machine Learning algorithms that learn from data. It’s often not obvious what values/settings one should choose.
You might be tempted to suggest that we should try out many different values and see what works best. That is a fine idea and that’s indeed what we will do, but this must be done very carefully. In particular, we cannot use the test set for the purpose of tweaking hyperparameters. Whenever you’re designing Machine Learning algorithms, you should think of the test set as a very precious resource that should ideally never be touched until one time at the very end.
if you only use the test set once at end, it remains a good proxy for measuring the generalization of your classifier (we will see much more discussion surrounding generalization later in the class).
Evaluate on the test set only a single time, at the very end.
雖然我們不能使用Test set,但是我們可以使用一個替代的fake test dataset,那就是Validation set。這個Validation set由原始的Train set
的一小部分組成:
Original Train set = Train set + Validation set
In practice. In practice, people prefer to avoid cross-validation in favor of having a single validation split, since cross-validation can be computationally expensive. The splits people tend to use is between 50%-90% of the training data for training and rest for validation. However, this depends on multiple factors: For example if the number of hyperparameters is large you may prefer to use bigger validation splits. If the number of examples in the validation set is small (perhaps only a few hundred or so), it is safer to use cross-validation. Typical number of folds you can see in practice would be 3-fold, 5-fold or 10-fold cross-validation.
Summary
In summary:
- We introduced the problem of Image Classification, in which we are given a set of images that are all labeled with a single category. We are then asked to predict these categories for a novel set of test images and measure the accuracy of the predictions.
- We introduced a simple classifier called the Nearest Neighbor classifier. We saw that there are multiple hyper-parameters (such as value of k, or the type of distance used to compare examples) that are associated with this classifier and that there was no obvious way of choosing them.
- We saw that the correct way to set these hyperparameters is to split your training data into two: a training set and a fake test set, which we call validation set. We try different hyperparameter values and keep the values that lead to the best performance on the validation set.
- If the lack of training data is a concern, we discussed a procedure called cross-validation, which can help reduce noise in estimating which hyperparameters work best.
Once the best hyperparameters are found, we fix them and perform a single evaluation on the actual test set. - We saw that Nearest Neighbor can get us about 40% accuracy on CIFAR-10. It is simple to implement but requires us to store the entire training set and it is expensive to evaluate on a test image.
- Finally, we saw that the use of L1 or L2 distances on raw pixel values is not adequate since the distances correlate more strongly with backgrounds and color distributions of images than with their semantic content.
相關文章
- 史丹佛CS231n課程筆記純乾貨2筆記
- 史丹佛CS231n課程筆記純乾貨1筆記
- CS231n winter 2016 學習筆記lecture 1筆記
- image-classification-dataset
- 軒田機器學習基石課程學習筆記11 — Linear Models for Classification機器學習筆記
- 機器學習課程筆記機器學習筆記
- python課程筆記Python筆記
- 會計學課程筆記筆記
- 王道C短期課程筆記筆記
- 物聯網課程筆記筆記
- lua課程學習筆記筆記
- 達內課程學習筆記筆記
- 萬物互聯課程筆記筆記
- Stanford機器學習課程筆記——SVM機器學習筆記
- UI設計課程筆記(三)UI筆記
- [Triton課程筆記] 2.2.3 BLS續筆記
- 網站SEO課程筆記整理版!網站筆記
- 遨遊Unix–APUE課程筆記【1】筆記
- 資料庫課程作業筆記資料庫筆記
- Python基礎課程筆記5Python筆記
- Andrew ng 深度學習課程筆記深度學習筆記
- 遨遊Unix — APUE課程筆記【2】筆記
- 龍哥盟-PMP-課程筆記-四-筆記
- 龍哥盟-PMP-課程筆記-三-筆記
- 龍哥盟-PMP-課程筆記-十九-筆記
- 北航OS課程筆記--一、緒論筆記
- 北航OS課程筆記--六、磁碟管理筆記
- 計算機網路 - 課程筆記計算機網路筆記
- 北航OS課程筆記--三、記憶體管理筆記記憶體
- 網站SEO課程筆記整理版(2)網站筆記
- 谷歌機器學習課程筆記(4)——降低損失谷歌機器學習筆記
- 《資料庫系統原理》課程筆記資料庫筆記
- data cleaning(資料清洗) 課程筆記筆記
- 3月24日廣州DBA課程筆記筆記
- 北航軟院人工智慧課程筆記人工智慧筆記
- MIT6S081課程筆記MIT筆記
- 北航OS課程筆記--四、程序管理筆記
- 北航OS課程筆記--五、裝置管理筆記