Android逆向之旅---解析編譯之後的Dex檔案格式
一、前言
新的一年又開始了,大家是否還記得去年年末的時候,我們還有一件事沒有做,那就是解析Android中編譯之後的classes.dex檔案格式,我們在去年的時候已經介紹了:
如何解析編譯之後的xml檔案格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50568487
如何解析編譯之後的resource.arsc檔案格式:
http://blog.csdn.net/jiangwei0910410003/article/details/50628894
那麼我們還剩下一個檔案格式就是classes.dex了,那麼今天我們就來看看最後一個檔案格式解析,關於Android中的dex檔案的相關知識這裡就不做太多的解釋了,網上有很多資料可以參考,而且,我們在之前介紹的一篇加固apk的那篇文章中也介紹了一點dex的格式知識點:http://blog.csdn.net/jiangwei0910410003/article/details/48415225,我們按照之前的解析思路來,首先還是來一張神圖:

有了這張神圖,那麼接下來我們就可以來介紹dex的檔案結構了,首先還是來看一張大體的結構圖:

二、準備工作
我們在講解資料結構之前,我們需要先建立一個簡單的例子來幫助我們來解析,我們需要得到一個簡單的dex檔案,這裡我們不借助任何的IDE工具,就可以構造一個dex檔案出來。藉助的工具很簡單:javac,dx命令即可。
建立 java 原始檔 ,內容如下
程式碼:
public class Hello
{
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}
在當前工作路徑下 , 編譯方法如下 :
(1) 編譯成 java class 檔案
執行命令 : javac Hello.java
編譯完成後 ,目錄下生成 Hello.class 檔案 。可以使用命令 java Hello 來測試下 ,會輸出程式碼中的 “Hello, Android!” 的字串 。
(2) 編譯成 dex 檔案
編譯工具在 Android SDK 的路徑如下 ,其中 19.0.1 是Android SDK build_tools 的版本 ,請按照在本地安裝的 build_tools 版本來 。建議該路徑載入到 PATH 路徑下 ,否則引用 dx 工具時需要使用絕對路徑 :./build-tools/19.0.1/dx
執行命令 : dx --dex --output=Hello.dex Hello.class
編譯正常會生成 Hello.dex 檔案 。
3. 使用 ADB 執行測試
測試命令和輸出結果如下 :
$ adb root
$ adb push Hello.dex /sdcard/
$ adb shell
root@maguro:/ # dalvikvm -cp /sdcard/Hello.dex Hello
Hello, Android!
4. 重要說明
(1) 測試環境使用真機和 Android 虛擬機器都可以的 。核心的命令是
dalvikvm -cp /sdcard/Hello.dex Hello
-cp 是 class path 的縮寫 ,後面的 Hello 是要執行的 Class 的名稱 。網上有描述說輸入 dalvikvm --help
可以看到 dalvikvm 的幫助文件 ,但是在 Android4.4 的官方模擬器和自己的手機上測試都提示找不到
Class 路徑 ,在Android 老的版本 ( 4.3 ) 上測試還是有輸出的 。
(2) 因為命令在執行時 , dalvikvm 會在 /data/dalvik-cache/ 目錄下建立 .dex 檔案 ,因此要求 ADB 的
執行 Shell 對目錄 /data/dalvik-cache/ 有讀、寫和執行的許可權 ,否則無法達到預期效果 。
三、講解資料結構
下面我們按照這張大體的思路圖來一一講解各個資料結構
第一、頭部資訊Header結構
dex檔案裡的header。除了描述.dex檔案的檔案資訊外,還有檔案裡其它各個區域的索引。header對應成結構體型別,邏輯上的描述我用結構體header_item來理解它。先給出結構體裡面用到的資料型別ubyte和uint的解釋,然後再是結構體的描述,後面對各種結構描述的時候也是用的這種方法。
程式碼定義:
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class HeaderType {
/**
* struct header_item
{
ubyte[8] magic;
unit checksum;
ubyte[20] siganature;
uint file_size;
uint header_size;
unit endian_tag;
uint link_size;
uint link_off;
uint map_off;
uint string_ids_size;
uint string_ids_off;
uint type_ids_size;
uint type_ids_off;
uint proto_ids_size;
uint proto_ids_off;
uint method_ids_size;
uint method_ids_off;
uint class_defs_size;
uint class_defs_off;
uint data_size;
uint data_off;
}
*/
public byte[] magic = new byte[8];
public int checksum;
public byte[] siganature = new byte[20];
public int file_size;
public int header_size;
public int endian_tag;
public int link_size;
public int link_off;
public int map_off;
public int string_ids_size;
public int string_ids_off;
public int type_ids_size;
public int type_ids_off;
public int proto_ids_size;
public int proto_ids_off;
public int field_ids_size;
public int field_ids_off;
public int method_ids_size;
public int method_ids_off;
public int class_defs_size;
public int class_defs_off;
public int data_size;
public int data_off;
@Override
public String toString(){
return "magic:"+Utils.bytesToHexString(magic)+"\n"
+ "checksum:"+checksum + "\n"
+ "siganature:"+Utils.bytesToHexString(siganature) + "\n"
+ "file_size:"+file_size + "\n"
+ "header_size:"+header_size + "\n"
+ "endian_tag:"+endian_tag + "\n"
+ "link_size:"+link_size + "\n"
+ "link_off:"+Utils.bytesToHexString(Utils.int2Byte(link_off)) + "\n"
+ "map_off:"+Utils.bytesToHexString(Utils.int2Byte(map_off)) + "\n"
+ "string_ids_size:"+string_ids_size + "\n"
+ "string_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(string_ids_off)) + "\n"
+ "type_ids_size:"+type_ids_size + "\n"
+ "type_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(type_ids_off)) + "\n"
+ "proto_ids_size:"+proto_ids_size + "\n"
+ "proto_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(proto_ids_off)) + "\n"
+ "field_ids_size:"+field_ids_size + "\n"
+ "field_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(field_ids_off)) + "\n"
+ "method_ids_size:"+method_ids_size + "\n"
+ "method_ids_off:"+Utils.bytesToHexString(Utils.int2Byte(method_ids_off)) + "\n"
+ "class_defs_size:"+class_defs_size + "\n"
+ "class_defs_off:"+Utils.bytesToHexString(Utils.int2Byte(class_defs_off)) + "\n"
+ "data_size:"+data_size + "\n"
+ "data_off:"+Utils.bytesToHexString(Utils.int2Byte(data_off));
}
}
檢視Hex如下:

裡面一對一對以_size和_off為字尾的描述:data_size是以Byte為單位描述data區的大小,其餘的
_size都是描述該區裡元素的個數;_off描述相對與檔案起始位置的偏移量。其餘的6個是描述.dex檔案信
息的,各項說明如下:
(1) magic value
這 8 個 位元組一般是常量 ,為了使 .dex 檔案能夠被識別出來 ,它必須出現在 .dex 檔案的最開頭的
位置 。陣列的值可以轉換為一個字串如下 :
{ 0x64 0x65 0x78 0x0a 0x30 0x33 0x35 0x00 } = "dex\n035\0"
中間是一個 ‘\n' 符號 ,後面 035 是 Dex 檔案格式的版本 。
(2) checksum 和 signature
檔案校驗碼 ,使用alder32 演算法校驗檔案除去 maigc ,checksum 外餘下的所有檔案區域 ,用於檢
查檔案錯誤 。
signature , 使用 SHA-1 演算法 hash 除去 magic ,checksum 和 signature 外餘下的所有檔案區域 ,
用於唯一識別本檔案 。
(3) file_size
Dex 檔案的大小 。
(4) header_size
header 區域的大小 ,單位 Byte ,一般固定為 0x70 常量 。
(5) endian_tag
大小端標籤 ,標準 .dex 檔案格式為 小端 ,此項一般固定為 0x1234 5678 常量 。

(6) link_size和link_off
這個兩個欄位是表示連結資料的大小和偏移值
(7) map_off
map item 的偏移地址 ,該 item 屬於 data 區裡的內容 ,值要大於等於 data_off 的大小 。結構如
map_list 描述 :
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class MapList {
/**
* struct maplist
{
uint size;
map_item list [size];
}
*/
public int size;
public List<MapItem> map_item = new ArrayList<MapItem>();
}
引用位置 :header 區 。
map_list 裡先用一個 uint 描述後面有 size 個 map_item , 後續就是對應的 size 個 map_item 描述 。
map_item 結構有 4 個元素 : type 表示該 map_item 的型別 ,本節能用到的描述如下 ,詳細Dalvik
Executable Format 裡 Type Code 的定義 ;size 表示再細分此 item , 該型別的個數 ;offset 是第一個元
素的針對檔案初始位置的偏移量 ; unuse 是用對齊位元組的 ,無實際用處 。結構定義如下:
package com.wjdiankong.parsedex.struct;
public class MapItem {
/**
* struct map_item
{
ushort type;
ushort unuse;
uint size;
uint offset;
}
*/
public short type;
public short unuse;
public int size;
public int offset;
public static int getSize(){
return 2 + 2 + 4 + 4;
}
@Override
public String toString(){
return "type:"+type+",unuse:"+unuse+",size:"+size+",offset:"+offset;
}
}
每個 map_item 描述佔用 12 Byte , 整個 map_list 佔用 12 * size + 4 個位元組 。所以整個 map_list 佔用空
間為 12 * 13 + 4 = 160 = 0x00a0 , 佔用空間為 0x 0244 ~ 0x 02E3 。從檔案內容上看 ,也是從 0x 0244
到檔案結束的位置 。
地址 0x0244 的一個 uinit 的值為 0x0000 000d ,map_list - > size = 0x0d = 13 ,說明後續有 13 個
map_item 。根據 map_item 的結構描述在0x0248 ~ 0x02e3 裡的值 ,整理出這段二進位制所表示的 13 個
map_item 內容 ,匯成表格如下 :
map_list - > map_item 裡的內容 ,有部分 item 跟 header 裡面相應 item 的 offset 地址描述相同 。但
map_list 描述的更為全面些 ,又包括了 HEADER_ITEM , TYPE_LIST , STRING_DATA_ITEM 等 ,
最後還有它自己 TYPE_MAP_LIST 。
至此 , header 部分描述完畢 ,它包括描述 .dex 檔案的資訊 ,其餘各索引區和 data 區的偏移資訊 , 一個
map_list 結構 。map_list 裡除了對索引區和資料區的偏移地址又一次描述 ,也有其它諸如 HEAD_ITEM ,
DEBUG_INFO_ITEM 等資訊 。

(8) string_ids_size和string_ids_off
這兩個欄位表示dex中用到的所有的字串內容的大小和偏移值,我們需要解析完這部分,然後用一個字串池存起來,後面有其他的資料結構會用索引值來訪問字串,這個池子也是非常重要的。後面會詳細介紹string_ids的資料結構
(9) type_ids_size和type_ids_off
這兩個欄位表示dex中的型別資料結構的大小和偏移值,比如類型別,基本型別等資訊,後面會詳細介紹type_ids的資料結構
(10) proto_ids_size和type_ids_off
這兩個欄位表示dex中的後設資料資訊資料結構的大小和偏移值,描述方法的後設資料資訊,比如方法的返回型別,引數型別等資訊,後面會詳細介紹proto_ids的資料結構
(11) field_ids_size和field_ids_off
這兩個欄位表示dex中的欄位資訊資料結構的大小和偏移值,後面會詳細介紹field_ids的資料結構
(12) method_ids_size和method_ids_off
這兩個欄位表示dex中的方法資訊資料結構的大小和偏移值,後面會詳細介紹method_ids的資料結構
(13) class_defs_size和class_defs_off
這兩個欄位表示dex中的類資訊資料結構的大小和偏移值,這個資料結構是整個dex中最複雜的資料結構,他內部層次很深,包含了很多其他的資料結構,所以解析起來也很麻煩,所以後面會著重講解這個資料結構
(14) data_size和data_off
這兩個欄位表示dex中資料區域的結構資訊的大小和偏移值,這個結構中存放的是資料區域,比如我們定義的常量值等資訊。
到這裡我們就看完了dex的頭部資訊,頭部包含的資訊還是很多的,主要就兩個個部分:
1) 魔數+簽名+檔案大小等資訊
2) 後面的各個資料結構的大小和偏移值,都是成對出現的
下面我們就來開始介紹各個資料結構的資訊
第二、string_ids資料結構
string_ids 區索引了 .dex 檔案所有的字串 。 本區裡的元素格式為 string_ids_item , 可以使用結
構體如下描述 。
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class StringIdsItem {
/**
* struct string_ids_item
{
uint string_data_off;
}
*/
public int string_data_off;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(string_data_off));
}
}
string_data_off 只是一個偏移地址 ,它指向的資料結構為 string_data_item
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class StringDataItem {
/**
* struct string_data_item
{
uleb128 utf16_size;
ubyte data;
}
*/
/**
* 上述描述裡提到了 LEB128 ( little endian base 128 ) 格式 ,是基於 1 個 Byte 的一種不定長度的
編碼方式 。若第一個 Byte 的最高位為 1 ,則表示還需要下一個 Byte 來描述 ,直至最後一個 Byte 的最高
位為 0 。每個 Byte 的其餘 Bit 用來表示資料
*/
public List<Byte> utf16_size = new ArrayList<Byte>();
public byte data;
}
延展
上述描述裡提到了 LEB128 ( little endian base 128 ) 格式 ,是基於 1 個 Byte 的一種不定長度的編碼方式 。若第一個 Byte 的最高位為 1 ,則表示還需要下一個 Byte 來描述 ,直至最後一個 Byte 的最高位為 0 。每個 Byte 的其餘 Bit 用來表示資料 。這裡既然介紹了uleb128這種資料型別,就在這裡解釋一下,因為後面會經常用到這個資料型別,這個資料型別的出現其實就是為了解決一個問題,那就是減少記憶體的浪費,他就是表示int型別的數值,但是int型別四個位元組有時候在使用的時候有點浪費,所以就應運而生了,他的原理也很簡單:
圖只是指示性的用兩個位元組表示。編碼的每個位元組有效部分只有低7bits,每個位元組的最高bit用來指示是否是最後一個位元組。
非最高位元組的bit7為0
最高位元組的bit7為1
將leb128編碼的數字轉換為可讀數字的規則是:除去每個位元組的bit7,將每個位元組剩餘的7個bits拼接在一起,即為數字。
比如:
LEB128編碼的0x02b0 ---> 轉換後的數字0x0130
轉換過程:
0x02b0 => 0000 0010 1011 0000 =>去除最高位=> 000 0010 011 0000 =>按4bits重排 => 00 0001 0011 0000 => 0x130

底層程式碼位於:android/dalvik/libdex/leb128.h
Java中也寫了一個工具類:
/**
* 讀取C語言中的uleb型別
* 目的是解決整型數值浪費問題
* 長度不固定,在1~5個位元組中浮動
* @param srcByte
* @param offset
* @return
*/
public static byte[] readUnsignedLeb128(byte[] srcByte, int offset){
List<Byte> byteAryList = new ArrayList<Byte>();
byte bytes = Utils.copyByte(srcByte, offset, 1)[0];
byte highBit = (byte)(bytes & 0x80);
byteAryList.add(bytes);
offset ++;
while(highBit != 0){
bytes = Utils.copyByte(srcByte, offset, 1)[0];
highBit = (byte)(bytes & 0x80);
offset ++;
byteAryList.add(bytes);
}
byte[] byteAry = new byte[byteAryList.size()];
for(int j=0;j<byteAryList.size();j++){
byteAry[j] = byteAryList.get(j);
}
return byteAry;
}還有一個方法就是解碼uleb128型別的資料:
/**
* 解碼leb128資料
* 每個位元組去除最高位,然後進行拼接,重新構造一個int型別數值,從低位開始
* @param byteAry
* @return
*/
public static int decodeUleb128(byte[] byteAry) {
int index = 0, cur;
int result = byteAry[index];
index++;
if(byteAry.length == 1){
return result;
}
if(byteAry.length == 2){
cur = byteAry[index];
index++;
result = (result & 0x7f) | ((cur & 0x7f) << 7);
return result;
}
if(byteAry.length == 3){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 14;
return result;
}
if(byteAry.length == 4){
cur = byteAry[index];
index++;
result |= (cur & 0x7f) << 21;
return result;
}
if(byteAry.length == 5){
cur = byteAry[index];
index++;
result |= cur << 28;
return result;
}
return result;
}我們通過上面的uleb128的解釋來看,其實uleb128型別就是1~5個位元組來回浮動,為什麼是5呢?因為他要表示一個4個位元組的int型別,但是每個位元組要去除最高位,那麼肯定最多隻需要5個位元組就可以表示4個位元組的int型別資料了。這裡就解釋了uleb128資料型別,下面我們迴歸正題,繼續來看string_ids資料結構
根據 string_ids_item 和 string_data_item 的描述 ,加上 header 裡提供的入口位置 string_ids_size
= 0x0e , string_ids_off = 0x70 ,我們可以整理出 string_ids 及其對應的資料如下 :

string_ids_item 和 string_data_item 裡提取出的對應資料表格 :
string 裡的各種標誌符號 ,諸如 L , V , VL , [ 等在 .dex 檔案裡有特殊的意思 。
string_ids 的終極奧義就是找到這些字串 。其實使用二進位制編輯器開啟 .dex 檔案時 ,一般工具預設翻譯成 ASCII 碼 ,總會一大片熟悉的字元白生生地很是親切, 也很是晃眼 。剛才走過的一路子分析流程 ,就是順藤摸瓜找到它們是怎麼來的。以後的一些 type-ids , method_ids 也會引用到這一片熟悉的字串。
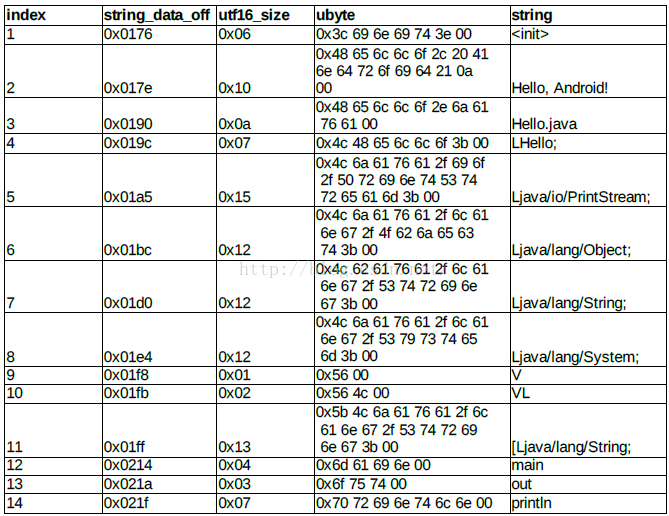
注意:我們後面的解析程式碼會看到,其實我們沒必要用那麼複雜的去解析uleb128型別,因為我們會看到這個字串和我們之前解析xml和resource.arsc格式一樣,每個字串的第一個位元組表示字串的長度,那麼我們只要知道每個字串的偏移地址就可以解析出字串的內容了,而每個字串的偏移地址是存放在string_ids_item中的。
到這裡我們就解析完了dex中所有的字串內容,我們用一個字串池來進行儲存即可。下面我們來繼續看type_ids資料結構
第三、type_ids資料結構
這個資料結構中存放的資料主要是描述dex中所有的型別,比如類型別,基本型別等資訊。type_ids 區索引了 dex 檔案裡的所有資料型別 ,包括 class 型別 ,陣列型別(array types)和基本型別(primitive types) 。 本區域裡的元素格式為 type_ids_item , 結構描述如下 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class TypeIdsItem {
/**
* struct type_ids_item
{
uint descriptor_idx;
}
*/
public int descriptor_idx;
public static int getSize(){
return 4;
}
@Override
public String toString(){
return Utils.bytesToHexString(Utils.int2Byte(descriptor_idx));
}
}
根據 header 裡 type_ids_size = 0x07 , type_ids_off = 0xa8 , 找到對應的二進位制描述區 。00000a0: 1a02
根據 type_id_item 的描述 ,整理出表格如下 。因為 type_id_item - > descriptor_idx 裡存放的是指向 string_ids 的 index 號 ,所以我們也能得到該 type 的字串描述 。這裡出現了 3 個 type descriptor :
L 表示 class 的詳細描述 ,一般以分號表示 class 描述結束 ;
V 表示 void 返回型別 ,只有在返回值的時候有效 ;
[ 表示陣列 ,[Ljava/lang/String; 可以對應到 java 語言裡的 java.lang.String[] 型別 。

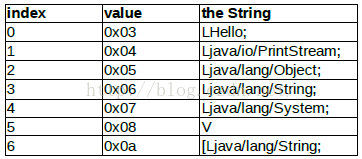
我們後面的其他資料結構也會使用到type_ids型別,所以我們這裡解析完type_ids也是需要用一個池子來存放的,後面直接用索引index來訪問即可。
第四、proto_ids資料結構
proto 的意思是 method prototype 代表 java 語言裡的一個 method 的原型 。proto_ids 裡的元素為 proto_id_item , 結構如下 。
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class ProtoIdsItem {
/**
* struct proto_id_item
{
uint shorty_idx;
uint return_type_idx;
uint parameters_off;
}
*/
public int shorty_idx;
public int return_type_idx;
public int parameters_off;
//這個不是公共欄位,而是為了儲存方法原型中的引數型別名和引數個數
public List<String> parametersList = new ArrayList<String>();
public int parameterCount;
public static int getSize(){
return 4 + 4 + 4;
}
@Override
public String toString(){
return "shorty_idx:"+shorty_idx+",return_type_idx:"+return_type_idx+",parameters_off:"+parameters_off;
}
}
return_type_idx :它的值是一個 type_ids 的 index 號 ,表示該 method 原型的返回值型別 。
parameters_off :字尾 off 是 offset , 指向 method 原型的引數列表 type_list ; 若 method 沒有引數 ,值為0 。引數列表的格式是 type_list ,結構從邏輯上如下描述 。size 表示引數的個數 ;type_idx 是對應引數的型別 ,它的值是一個 type_ids 的 index 號 ,跟 return_type_idx 是同一個品種的東西 。
package com.wjdiankong.parsedex.struct;
import java.util.ArrayList;
import java.util.List;
public class TypeList {
/**
* struct type_list
{
uint size;
ushort type_idx[size];
}
*/
public int size;//引數的個數
public List<Short> type_idx = new ArrayList<Short>();//引數的型別
}
header 裡 proto_ids_size = 0x03 , proto_ids_off = 0xc4 , 它的二進位制描述區如下 :

可以看出 ,有 3 個 method 原型 ,返回值都為 void ,index = 0 的沒有引數傳入 ,index = 1 的傳入一個
String 引數 ,index=2 的傳入一個 String[] 型別的引數 。

注意:我們在這裡會看到很多idx結尾的欄位,這個一般都是索引值,所以我們要注意的是,區分這個索引值到底是對應的哪張表格,是字串池,還是型別池等資訊,這個如果弄混淆的話,那麼解析就會出現混亂了。這個後面其他資料結構都是需要注意的。
第五、field_ids資料結構
filed_ids 區裡面存放的是dex 檔案引用的所有的 field 。本區的元素格式是 field_id_item ,邏輯結構描述如
package com.wjdiankong.parsedex.struct;
public class FieldIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort type_idx;
uint name_idx;
}
*/
public short class_idx;
public short type_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",type_idx:"+type_idx+",name_idx:"+name_idx;
}
}
type_idx :表示本 field 的型別 ,它的值也是 type_ids 的一個 index 。
name_idx : 表示本 field 的名稱 ,它的值是 string_ids 的一個 index 。
header 裡 field_ids_size = 1 , field_ids_off = 0xe8 。說明本 .dex 只有一個 field ,這部分的二進位制描述如下 :

注意:這裡的欄位都是索引值,一定要區分是哪個池子的索引值,還有就是,這個資料結構我們後面也要使用到,所以需要用一個池子來儲存。
第六、 method_ids資料結構
method_ids 是索引區的最後一個條目 ,它索引了 dex 檔案裡的所有的 method.method_ids 的元素格式是 method_id_item , 結構跟 fields_ids 很相似:
package com.wjdiankong.parsedex.struct;
public class MethodIdsItem {
/**
* struct filed_id_item
{
ushort class_idx;
ushort proto_idx;
uint name_idx;
}
*/
public short class_idx;
public short proto_idx;
public int name_idx;
public static int getSize(){
return 2 + 2 + 4;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",proto_idx:"+proto_idx+",name_idx:"+name_idx;
}
}
name_idx :表示本 method 的名稱 ,它的值是 string_ids 的一個 index 。
proto_idx :描述該 method 的原型 ,指向 proto_ids 的一個 index 。
header 裡 method_ids_size = 0x04 , method_ids_off = 0xf0 。本部分的二進位制描述如下 :

對 dex 反彙編的時候 ,常用的 method 表示方法是這種形式 :
Lpackage/name/ObjectName;->MethodName(III)Z
將上述表格裡的字串再次整理下 ,method 的描述分別為 :
0:Lhello; -> <init>()V
1:LHello; -> main([Ljava/lang/String;)V
2:Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
3: Ljava/lang/Object; -> <init>()V
至此 ,索引區的內容描述完畢 ,包括 string_ids , type_ids,proto_ids , field_ids , method_ids 。每個索引區域裡存放著指向具體資料的偏移地址 (如 string_ids ) , 或者存放的資料是其它索引區域裡面的 index 號。
注意:這裡的欄位都是索引值,一定要區分是哪個池子的索引值,還有就是,這個資料結構我們後面也要使用到,所以需要用一個池子來儲存。
第八、class_defs資料結構
上面我們介紹了所有的索引區域,終於到了最後一個資料結構了,但是我們現在還不能開心,因為這個資料結構是最複雜的,所以解析下來還是很費勁的。因為他的層次太深了。
1、class_def_item
從字面意思解釋 ,class_defs 區域裡存放著 class definitions , class 的定義 。它的結構較 dex 區都要複雜些 ,因為有些資料都直接指向了data 區裡面 。
class_defs 的資料格式為 class_def_item , 結構描述如下 :
package com.wjdiankong.parsedex.struct;
public class ClassDefItem {
/**
* struct class_def_item
{
uint class_idx;
uint access_flags;
uint superclass_idx;
uint interfaces_off;
uint source_file_idx;
uint annotations_off;
uint class_data_off;
uint static_value_off;
}
*/
public int class_idx;
public int access_flags;
public int superclass_idx;
public int iterfaces_off;
public int source_file_idx;
public int annotations_off;
public int class_data_off;
public int static_value_off;
public final static int
ACC_PUBLIC = 0x00000001, // class, field, method, ic
ACC_PRIVATE = 0x00000002, // field, method, ic
ACC_PROTECTED = 0x00000004, // field, method, ic
ACC_STATIC = 0x00000008, // field, method, ic
ACC_FINAL = 0x00000010, // class, field, method, ic
ACC_SYNCHRONIZED = 0x00000020, // method (only allowed on natives)
ACC_SUPER = 0x00000020, // class (not used in Dalvik)
ACC_VOLATILE = 0x00000040, // field
ACC_BRIDGE = 0x00000040, // method (1.5)
ACC_TRANSIENT = 0x00000080, // field
ACC_VARARGS = 0x00000080, // method (1.5)
ACC_NATIVE = 0x00000100, // method
ACC_INTERFACE = 0x00000200, // class, ic
ACC_ABSTRACT = 0x00000400, // class, method, ic
ACC_STRICT = 0x00000800, // method
ACC_SYNTHETIC = 0x00001000, // field, method, ic
ACC_ANNOTATION = 0x00002000, // class, ic (1.5)
ACC_ENUM = 0x00004000, // class, field, ic (1.5)
ACC_CONSTRUCTOR = 0x00010000, // method (Dalvik only)
ACC_DECLARED_SYNCHRONIZED = 0x00020000, // method (Dalvik only)
ACC_CLASS_MASK =
(ACC_PUBLIC | ACC_FINAL | ACC_INTERFACE | ACC_ABSTRACT
| ACC_SYNTHETIC | ACC_ANNOTATION | ACC_ENUM),
ACC_INNER_CLASS_MASK =
(ACC_CLASS_MASK | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC),
ACC_FIELD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_VOLATILE | ACC_TRANSIENT | ACC_SYNTHETIC | ACC_ENUM),
ACC_METHOD_MASK =
(ACC_PUBLIC | ACC_PRIVATE | ACC_PROTECTED | ACC_STATIC | ACC_FINAL
| ACC_SYNCHRONIZED | ACC_BRIDGE | ACC_VARARGS | ACC_NATIVE
| ACC_ABSTRACT | ACC_STRICT | ACC_SYNTHETIC | ACC_CONSTRUCTOR
| ACC_DECLARED_SYNCHRONIZED);
public static int getSize(){
return 4 * 8;
}
@Override
public String toString(){
return "class_idx:"+class_idx+",access_flags:"+access_flags+",superclass_idx:"+superclass_idx+",iterfaces_off:"+iterfaces_off
+",source_file_idx:"+source_file_idx+",annotations_off:"+annotations_off+",class_data_off:"+class_data_off
+",static_value_off:"+static_value_off;
}
}
(2) access_flags: 描述 class 的訪問型別 ,諸如 public , final , static 等 。在 dex-format.html 裡 “access_flagsDefinitions” 有具體的描述 。
(3) superclass_idx:描述 supperclass 的型別 ,值的形式跟 class_idx 一樣 。
(4) interfaces_off:值為偏移地址 ,指向 class 的 interfaces , 被指向的資料結構為 type_list 。class 若沒有interfaces ,值為 0。
(5) source_file_idx:表示原始碼檔案的資訊 ,值是 string_ids 的一個 index 。若此項資訊缺失 ,此項值賦值為NO_INDEX=0xffff ffff
(6) annotions_off:值是一個偏移地址 ,指向的內容是該 class 的註釋 ,位置在 data 區,格式為annotations_direcotry_item 。若沒有此項內容 ,值為 0 。
(7) class_data_off:值是一個偏移地址 ,指向的內容是該 class 的使用到的資料 ,位置在 data 區,格式為class_data_item 。若沒有此項內容 ,值為 0 。該結構裡有很多內容 ,詳細描述該 class 的 field ,method, method 裡的執行程式碼等資訊 ,後面有一個比較大的篇幅來講述 class_data_item 。
(8) static_value_off:值是一個偏移地址 ,指向 data 區裡的一個列表 ( list ) ,格式為 encoded_array_item。若沒有此項內容 ,值為 0 。
header 裡 class_defs_size = 0x01 , class_defs_off = 0x 0110 。則此段二進位制描述為 :
其實最初被編譯的原始碼只有幾行 ,和 class_def_item 的表格對照下 ,一目瞭然 。
source file : Hello.java
public class Hello
{
element value associated strinigs
class_idx 0x00 LHello;
access_flags 0x01 ACC_PUBLIC
superclass_idx 0x02 Ljava/lang/Object;
interface_off 0x00
source_file_idx 0x02 Hello.java
annotations_off 0x00
class_data_off 0x0234
static_value_off 0x00
public static void main(String[] argc)
{
System.out.println("Hello, Android!\n");
}
}

2、 class_def_item => class_data_item
class_data_off 指向 data 區裡的 class_data_item 結構 ,class_data_item 裡存放著本 class 使用到的各種資料 ,下面是 class_data_item 的邏輯結構 :
package com.wjdiankong.parsedex.struct;
public class ClassDataItem {
/**
* uleb128 unsigned little-endian base 128
struct class_data_item
{
uleb128 static_fields_size;
uleb128 instance_fields_size;
uleb128 direct_methods_size;
uleb128 virtual_methods_size;
encoded_field static_fields [ static_fields_size ];
encoded_field instance_fields [ instance_fields_size ];
encoded_method direct_methods [ direct_method_size ];
encoded_method virtual_methods [ virtual_methods_size ];
}
*/
//uleb128只用來編碼32位的整型數
public int static_fields_size;
public int instance_fields_size;
public int direct_methods_size;
public int virtual_methods_size;
public EncodedField[] static_fields;
public EncodedField[] instance_fields;
public EncodedMethod[] direct_methods;
public EncodedMethod[] virtual_methods;
@Override
public String toString(){
return "static_fields_size:"+static_fields_size+",instance_fields_size:"
+instance_fields_size+",direct_methods_size:"+direct_methods_size+",virtual_methods_size:"+virtual_methods_size
+"\n"+getFieldsAndMethods();
}
private String getFieldsAndMethods(){
StringBuilder sb = new StringBuilder();
sb.append("static_fields:\n");
for(int i=0;i<static_fields.length;i++){
sb.append(static_fields[i]+"\n");
}
sb.append("instance_fields:\n");
for(int i=0;i<instance_fields.length;i++){
sb.append(instance_fields[i]+"\n");
}
sb.append("direct_methods:\n");
for(int i=0;i<direct_methods.length;i++){
sb.append(direct_methods[i]+"\n");
}
sb.append("virtual_methods:\n");
for(int i=0;i<virtual_methods.length;i++){
sb.append(virtual_methods[i]+"\n");
}
return sb.toString();
}
}
encoded_field 的結構如下 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedField {
/**
* struct encoded_field
{
uleb128 filed_idx_diff; // index into filed_ids for ID of this filed
uleb128 access_flags; // access flags like public, static etc.
}
*/
public byte[] filed_idx_diff;
public byte[] access_flags;
@Override
public String toString(){
return "field_idx_diff:"+Utils.bytesToHexString(filed_idx_diff) + ",access_flags:"+Utils.bytesToHexString(filed_idx_diff);
}
}
encoded_method 的結構如下 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class EncodedMethod {
/**
* struct encoded_method
{
uleb128 method_idx_diff;
uleb128 access_flags;
uleb128 code_off;
}
*/
public byte[] method_idx_diff;
public byte[] access_flags;
public byte[] code_off;
@Override
public String toString(){
return "method_idx_diff:"+Utils.bytesToHexString(method_idx_diff)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(method_idx_diff)))
+",access_flags:"+Utils.bytesToHexString(access_flags)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(access_flags)))
+",code_off:"+Utils.bytesToHexString(code_off)+","+Utils.bytesToHexString(Utils.int2Byte(Utils.decodeUleb128(code_off)));
}
}
(2) access_flags:訪問許可權 , 比如 public、private、static、final 等 。
(3) code_off:一個指向 data 區的偏移地址 ,目標是本 method 的程式碼實現 。被指向的結構是
code_item ,有近 10 項元素 ,後面再詳細解釋 。
class_def_item -- > class_data_off = 0x 0234 。

名稱為 LHello; 的 class 裡只有 2 個 directive methods 。 directive_methods 裡的值都是 uleb128 的原始二
進位制值 。按照 directive_methods 的格式 encoded_method 再整理一次這 2 個 method 描述 ,得到結果如下
表格所描述 :

method 一個是 <init> , 一個是 main , 這裡我們需要用我們在string_ids那塊介紹到的一個方法就是解碼uleb125型別的方法得到正確的value值。
3、class_def_item => class_data_item => code_item
到這裡 ,邏輯的描述有點深入了 。我自己都有點分析不過來 ,先理一下是怎麼走到這一步的 ,code_item
在 dex 裡處於一個什麼位置 。
(1) 一個 .dex 檔案被分成了 9 個區 ,詳細見 “1. dex 整個檔案的佈局 ” 。其中有一個索引區叫做
class_defs , 索引了 .dex 裡面用到的 class ,以及對這個 class 的描述 。
(2) class_defs 區 , 這裡面其實是class_def_item 結構 。這個結構裡描述了 LHello; 的各種資訊 ,諸如名稱 ,superclass , access flag, interface 等 。class_def_item 裡有一個元素 class_data_off , 指向data 區裡的一個 class_data_item 結構 ,用來描述 class 使用到的各種資料 。自此以後的結構都歸於 data區了 。
(3) class_data_item 結構 ,裡描述值著 class 裡使用到的 static field , instance field , direct_method ,和 virtual_method 的數目和描述 。例子 Hello.dex 裡 ,只有 2 個 direct_method , 其餘的 field 和method 的數目都為 0 。描述 direct_method 的結構叫做 encoded_method ,是用來詳細描述某個 method的 。
(4) encoded_method 結構 ,描述某個 method 的 method 型別 , access flags 和一個指向 code_item的偏移地址 ,裡面存放的是該 method 的具體實現 。
(5) code_item , 一層又一層 ,盜夢空間啊!簡要的說 ,code_item 結構裡描述著某個 method 的具體實現 。它的結構如下描述 :
package com.wjdiankong.parsedex.struct;
import com.wjdiankong.parsedex.Utils;
public class CodeItem {
/**
* struct code_item
{
ushort registers_size;
ushort ins_size;
ushort outs_size;
ushort tries_size;
uint debug_info_off;
uint insns_size;
ushort insns [ insns_size ];
ushort paddding; // optional
try_item tries [ tyies_size ]; // optional
encoded_catch_handler_list handlers; // optional
}
*/
public short registers_size;
public short ins_size;
public short outs_size;
public short tries_size;
public int debug_info_off;
public int insns_size;
public short[] insns;
@Override
public String toString(){
return "regsize:"+registers_size+",ins_size:"+ins_size
+",outs_size:"+outs_size+",tries_size:"+tries_size+",debug_info_off:"+debug_info_off
+",insns_size:"+insns_size + "\ninsns:"+getInsnsStr();
}
private String getInsnsStr(){
StringBuilder sb = new StringBuilder();
for(int i=0;i<insns.length;i++){
sb.append(Utils.bytesToHexString(Utils.short2Byte(insns[i]))+",");
}
return sb.toString();
}
}
(1) registers_size:本段程式碼使用到的暫存器數目。
(2) ins_size:method傳入引數的數目 。
(3) outs_size: 本段程式碼呼叫其它method 時需要的引數個數 。
(4) tries_size: try_item 結構的個數 。
(5) debug_off:偏移地址 ,指向本段程式碼的 debug 資訊存放位置 ,是一個 debug_info_item 結構。
(6) insns_size:指令列表的大小 ,以 16-bit 為單位 。 insns 是 instructions 的縮寫 。
(7) padding:值為 0 ,用於對齊位元組 。
(8) tries 和 handlers:用於處理 java 中的 exception , 常見的語法有 try catch 。
4、 分析 main method 的執行程式碼並與 smali 反編譯的結果比較
在 8.2 節裡有 2 個 method , 因為 main 裡的執行程式碼是自己寫的 ,分析它會熟悉很多 。偏移地址是
directive_method [1] -> code_off = 0x0148 ,二進位制描述如下 :
insns 陣列裡的 8 個二進位制原始資料 , 對這些資料的解析 ,需要對照官網的文件 《Dalvik VM Instruction
Format》和《Bytecode for Dalvik VM》。
分析思路整理如下
(1) 《Dalvik VM Instruction Format》 裡操作符 op 都是位於首個 16bit 資料的低 8 bit ,起始的是 op =0x62。
(2) 在 《Bytecode for Dalvik VM》 裡找到對應的 Syntax 和 format 。
syntax = sget_object
format = 0x21c 。
(3) 在《Dalvik VM Instruction Format》裡查詢 21c , 得知 op = 0x62 的指令佔據 2 個 16 bit 資料 ,格式是 AA|op BBBB ,解釋為 op vAA, type@BBBB 。因此這 8 組 16 bit 資料裡 ,前 2 個是一組 。對比資料得 AA=0x00, BBBB = 0x0000。
(4)返回《Bytecode for Dalvik VM》裡查閱對 sget_object 的解釋, AA 的值表示 Value Register ,即0 號暫存器; BBBB 表示 static field 的 index ,就是之前分析的field_ids 區裡 Index = 0 指向的那個東西 ,當時的 fields_ids 的分析結果如下 :
對 field 常用的表述是
包含 field 的型別 -> field 名稱 :field 型別 。
此次指向的就是 Ljava/lang/System; -> out:Ljava/io/printStream;
(5) 綜上 ,前 2 個 16 bit 資料 0x 0062 0000 , 解釋為
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
其餘的 6 個 16 bit 資料分析思路跟這個一樣 ,依次整理如下 :
0x011a 0x0001: const-string v1, “Hello, Android!”


0x206e 0x0002 0x0010:
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
0x000e: return-void
(6) 最後再整理下 main method , 用容易理解的方式表示出來就是 。
ACC_PUBLIC ACC_STATIC LHello;->main([Ljava/lang/String;)V
{
sget_object v0, Ljava/lang/System; -> out:Ljava/io/printStream;
const-string v1,Hello, Android!
invoke-virtual {v0, v1}, Ljava/io/PrintStream; -> println(Ljava/lang/String;)V
return-void
}
看起來很像 smali 格式語言 ,不妨使用 smali 反編譯下 Hello.dex , 看看 smali 生成的程式碼跟方才推匯出
來的有什麼差異 。
.method public static main([Ljava/lang/String;)V
.registers 3
.prologue
.line 5
sget-object v0, Ljava/lang/System;->out:Ljava/io/PrintStream;
const-string v1, "Hello, Android!\n"
index 0
class_idx 0x04
type_idx 0x01
name_idx 0x0c
class string Ljava/lang/System;
type string Ljava/io/PrintStream;
name string out
invoke-virtual {v0, v1}, Ljava/io/PrintStream;->println(Ljava/lang/String;)V
.line 6
return-void
從內容上看 ,二者形式上有些差異 ,但表述的是同一個 method 。這說明剛才的分析走的路子是沒有跑偏
的 。另外一個 method 是 <init> , 若是分析的話 ,思路和流程跟 main 一樣 。走到這裡,心裡很踏實了。
四、解析程式碼
上面我們解析完了所有的資料結構區域,下面就來看看具體的解析程式碼,由於篇幅的原因,這裡就不貼出全部的程式碼了,只貼出核心的程式碼:
1、解析頭部資訊:
public static void praseDexHeader(byte[] byteSrc){
HeaderType headerType = new HeaderType();
//解析魔數
byte[] magic = Utils.copyByte(byteSrc, 0, 8);
headerType.magic = magic;
//解析checksum
byte[] checksumByte = Utils.copyByte(byteSrc, 8, 4);
headerType.checksum = Utils.byte2int(checksumByte);
//解析siganature
byte[] siganature = Utils.copyByte(byteSrc, 12, 20);
headerType.siganature = siganature;
//解析file_size
byte[] fileSizeByte = Utils.copyByte(byteSrc, 32, 4);
headerType.file_size = Utils.byte2int(fileSizeByte);
//解析header_size
byte[] headerSizeByte = Utils.copyByte(byteSrc, 36, 4);
headerType.header_size = Utils.byte2int(headerSizeByte);
//解析endian_tag
byte[] endianTagByte = Utils.copyByte(byteSrc, 40, 4);
headerType.endian_tag = Utils.byte2int(endianTagByte);
//解析link_size
byte[] linkSizeByte = Utils.copyByte(byteSrc, 44, 4);
headerType.link_size = Utils.byte2int(linkSizeByte);
//解析link_off
byte[] linkOffByte = Utils.copyByte(byteSrc, 48, 4);
headerType.link_off = Utils.byte2int(linkOffByte);
//解析map_off
byte[] mapOffByte = Utils.copyByte(byteSrc, 52, 4);
headerType.map_off = Utils.byte2int(mapOffByte);
//解析string_ids_size
byte[] stringIdsSizeByte = Utils.copyByte(byteSrc, 56, 4);
headerType.string_ids_size = Utils.byte2int(stringIdsSizeByte);
//解析string_ids_off
byte[] stringIdsOffByte = Utils.copyByte(byteSrc, 60, 4);
headerType.string_ids_off = Utils.byte2int(stringIdsOffByte);
//解析type_ids_size
byte[] typeIdsSizeByte = Utils.copyByte(byteSrc, 64, 4);
headerType.type_ids_size = Utils.byte2int(typeIdsSizeByte);
//解析type_ids_off
byte[] typeIdsOffByte = Utils.copyByte(byteSrc, 68, 4);
headerType.type_ids_off = Utils.byte2int(typeIdsOffByte);
//解析proto_ids_size
byte[] protoIdsSizeByte = Utils.copyByte(byteSrc, 72, 4);
headerType.proto_ids_size = Utils.byte2int(protoIdsSizeByte);
//解析proto_ids_off
byte[] protoIdsOffByte = Utils.copyByte(byteSrc, 76, 4);
headerType.proto_ids_off = Utils.byte2int(protoIdsOffByte);
//解析field_ids_size
byte[] fieldIdsSizeByte = Utils.copyByte(byteSrc, 80, 4);
headerType.field_ids_size = Utils.byte2int(fieldIdsSizeByte);
//解析field_ids_off
byte[] fieldIdsOffByte = Utils.copyByte(byteSrc, 84, 4);
headerType.field_ids_off = Utils.byte2int(fieldIdsOffByte);
//解析method_ids_size
byte[] methodIdsSizeByte = Utils.copyByte(byteSrc, 88, 4);
headerType.method_ids_size = Utils.byte2int(methodIdsSizeByte);
//解析method_ids_off
byte[] methodIdsOffByte = Utils.copyByte(byteSrc, 92, 4);
headerType.method_ids_off = Utils.byte2int(methodIdsOffByte);
//解析class_defs_size
byte[] classDefsSizeByte = Utils.copyByte(byteSrc, 96, 4);
headerType.class_defs_size = Utils.byte2int(classDefsSizeByte);
//解析class_defs_off
byte[] classDefsOffByte = Utils.copyByte(byteSrc, 100, 4);
headerType.class_defs_off = Utils.byte2int(classDefsOffByte);
//解析data_size
byte[] dataSizeByte = Utils.copyByte(byteSrc, 104, 4);
headerType.data_size = Utils.byte2int(dataSizeByte);
//解析data_off
byte[] dataOffByte = Utils.copyByte(byteSrc, 108, 4);
headerType.data_off = Utils.byte2int(dataOffByte);
System.out.println("header:"+headerType);
stringIdOffset = headerType.header_size;//header之後就是string ids
stringIdsSize = headerType.string_ids_size;
stringIdsOffset = headerType.string_ids_off;
typeIdsSize = headerType.type_ids_size;
typeIdsOffset = headerType.type_ids_off;
fieldIdsSize = headerType.field_ids_size;
fieldIdsOffset = headerType.field_ids_off;
protoIdsSize = headerType.proto_ids_size;
protoIdsOffset = headerType.proto_ids_off;
methodIdsSize = headerType.method_ids_size;
methodIdsOffset = headerType.method_ids_off;
classIdsSize = headerType.class_defs_size;
classIdsOffset = headerType.class_defs_off;
mapListOffset = headerType.map_off;
}解析結果:

2、解析string_ids索引區
/************************解析字串********************************/
public static void parseStringIds(byte[] srcByte){
int idSize = StringIdsItem.getSize();
int countIds = stringIdsSize;
for(int i=0;i<countIds;i++){
stringIdsList.add(parseStringIdsItem(Utils.copyByte(srcByte, stringIdsOffset+i*idSize, idSize)));
}
System.out.println("string size:"+stringIdsList.size());
}
public static void parseStringList(byte[] srcByte){
//第一個位元組還是字串的長度
for(StringIdsItem item : stringIdsList){
String str = getString(srcByte, item.string_data_off);
System.out.println("str:"+str);
stringList.add(str);
}
}解析結果:

3、解析type_ids索引區
/***************************解析型別******************************/
public static void parseTypeIds(byte[] srcByte){
int idSize = TypeIdsItem.getSize();
int countIds = typeIdsSize;
for(int i=0;i<countIds;i++){
typeIdsList.add(parseTypeIdsItem(Utils.copyByte(srcByte, typeIdsOffset+i*idSize, idSize)));
}
//這裡的descriptor_idx就是解析之後的字串中的索引值
for(TypeIdsItem item : typeIdsList){
System.out.println("typeStr:"+stringList.get(item.descriptor_idx));
}
}解析結果:

4、解析proto_ids索引區
/***************************解析Proto***************************/
public static void parseProtoIds(byte[] srcByte){
int idSize = ProtoIdsItem.getSize();
int countIds = protoIdsSize;
for(int i=0;i<countIds;i++){
protoIdsList.add(parseProtoIdsItem(Utils.copyByte(srcByte, protoIdsOffset+i*idSize, idSize)));
}
for(ProtoIdsItem item : protoIdsList){
System.out.println("proto:"+stringList.get(item.shorty_idx)+","+stringList.get(item.return_type_idx));
//有的方法沒有引數,這個值就是0
if(item.parameters_off != 0){
item = parseParameterTypeList(srcByte, item.parameters_off, item);
}
}
}
//解析方法的所有引數型別
private static ProtoIdsItem parseParameterTypeList(byte[] srcByte, int startOff, ProtoIdsItem item){
//解析size和size大小的List中的內容
byte[] sizeByte = Utils.copyByte(srcByte, startOff, 4);
int size = Utils.byte2int(sizeByte);
List<String> parametersList = new ArrayList<String>();
List<Short> typeList = new ArrayList<Short>(size);
for(int i=0;i<size;i++){
byte[] typeByte = Utils.copyByte(srcByte, startOff+4+2*i, 2);
typeList.add(Utils.byte2Short(typeByte));
}
System.out.println("param count:"+size);
for(int i=0;i<typeList.size();i++){
System.out.println("type:"+stringList.get(typeList.get(i)));
int index = typeIdsList.get(typeList.get(i)).descriptor_idx;
parametersList.add(stringList.get(index));
}
item.parameterCount = size;
item.parametersList = parametersList;
return item;
}解析結果:

5、解析field_ids索引區
/***************************解析欄位****************************/
public static void parseFieldIds(byte[] srcByte){
int idSize = FieldIdsItem.getSize();
int countIds = fieldIdsSize;
for(int i=0;i<countIds;i++){
fieldIdsList.add(parseFieldIdsItem(Utils.copyByte(srcByte, fieldIdsOffset+i*idSize, idSize)));
}
for(FieldIdsItem item : fieldIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int typeIndex = typeIdsList.get(item.type_idx).descriptor_idx;
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",type:"+stringList.get(typeIndex));
}
}解析結果:
6、解析method_ids索引區
/***************************解析方法*****************************/
public static void parseMethodIds(byte[] srcByte){
int idSize = MethodIdsItem.getSize();
int countIds = methodIdsSize;
for(int i=0;i<countIds;i++){
methodIdsList.add(parseMethodIdsItem(Utils.copyByte(srcByte, methodIdsOffset+i*idSize, idSize)));
}
for(MethodIdsItem item : methodIdsList){
int classIndex = typeIdsList.get(item.class_idx).descriptor_idx;
int returnIndex = protoIdsList.get(item.proto_idx).return_type_idx;
String returnTypeStr = stringList.get(typeIdsList.get(returnIndex).descriptor_idx);
int shortIndex = protoIdsList.get(item.proto_idx).shorty_idx;
String shortStr = stringList.get(shortIndex);
List<String> paramList = protoIdsList.get(item.proto_idx).parametersList;
StringBuilder parameters = new StringBuilder();
parameters.append(returnTypeStr+"(");
for(String str : paramList){
parameters.append(str+",");
}
parameters.append(")"+shortStr);
System.out.println("class:"+stringList.get(classIndex)+",name:"+stringList.get(item.name_idx)+",proto:"+parameters);
}
}
7、解析class_def區域
/****************************解析類*****************************/
public static void parseClassIds(byte[] srcByte){
System.out.println("classIdsOffset:"+Utils.bytesToHexString(Utils.int2Byte(classIdsOffset)));
System.out.println("classIds:"+classIdsSize);
int idSize = ClassDefItem.getSize();
int countIds = classIdsSize;
for(int i=0;i<countIds;i++){
classIdsList.add(parseClassDefItem(Utils.copyByte(srcByte, classIdsOffset+i*idSize, idSize)));
}
for(ClassDefItem item : classIdsList){
System.out.println("item:"+item);
int classIdx = item.class_idx;
TypeIdsItem typeItem = typeIdsList.get(classIdx);
System.out.println("classIdx:"+stringList.get(typeItem.descriptor_idx));
int superClassIdx = item.superclass_idx;
TypeIdsItem superTypeItem = typeIdsList.get(superClassIdx);
System.out.println("superitem:"+stringList.get(superTypeItem.descriptor_idx));
int sourceIdx = item.source_file_idx;
String sourceFile = stringList.get(sourceIdx);
System.out.println("sourceFile:"+sourceFile);
classDataMap.put(sourceFile, item);
}
}
這裡我們看到解析結果我們可能有點看不懂,其實這裡我是沒有在繼續解讀下去了,為什麼,因為我們通過class_def的資料結構解析可以看到,我們需要藉助《Bytecode for Dalvik VM》這個來進行查閱具體的指令,然後翻譯成具體的指令程式碼,關於這個指令表可以參考這裡:http://www.netmite.com/android/mydroid/dalvik/docs/dalvik-bytecode.html,所以具體解析並不複雜,所以這裡就不在詳細解析了,具體的解析思路,可以參考class_def的資料結構解析那一塊的內容,上面又說道。

專案下載地址:http://download.csdn.net/detail/jiangwei0910410003/9432263
注意:
我們到這裡算是解析完了dex檔案了,但是我現在要告訴大家,其實Android中有一個工具可以為我們做這個事,不知道大家還記得我們之前介紹解析AndroidManifest.xml和resource.arsc檔案格式的時候,也是一樣的,直接用aapt命令就可以檢視了,這裡也是一樣的,只是這個工具是:dexdump
這個命令也是在AndroidSdk目錄下的build-tools下面,這裡我們可以將列印的結果重定向到demo.txt檔案中

那麼我們上面做的解析工作是不是就沒有用了呢?當然不是,我們在後面會說道我們解析dex格式有很多用途的。
五、技術總結和概述
到這裡我們就解析完了dex檔案的所有東東,講解的內容有點多,在這裡就來總結一下:
第一、學習到的技術
1、我們學習到了如何不是用任何的IDE工具,就可以構造一個dex檔案出來,主要藉助於java和dx命令。同時,我們也學會了一個可以執行dex檔案的命令:dalvikvm;不過這個命令需要root許可權。
2、我們瞭解到了Android中的DVM指令,如何翻譯指令程式碼。
3、學習了一個資料型別:uleb128,如何將uleb128型別和int型別進行轉化。
第二、未解決的問題
我們在整個解析的過程中會發現,我們這裡只是用一個非常簡單的dex來做案例解析,所以解析起來也很容易,但是我們實際的過程中,不會這麼簡單的,一個類可能實現多個介面,內部類,註解等資訊的時候,解析起來肯定還要複雜,那麼我們這篇文章主要的目的是介紹一下dex的檔案格式,目的不是說去解決實際中專案的問題,所以後面在解析複雜的dex的時候,我們也只能遇到什麼問題就去解決一下。
第三、我們解析dex的目的是啥?
我們開始的時候,並沒有介紹說解析dex幹啥?那麼現在可以說,解析完dex之後我們有很多事都可以做了。
1、我們可以檢測一個apk中是否包含了指定系統的api(當然這些api沒有被混淆),同樣也可以檢測這個apk是否包含了廣告,以前我們可以通過解析AndroidManifest.xml檔案中的service,activity,receiver,meta等資訊來判斷,因為現在的廣告sdk都需要新增這些東西,如果我們可以解析dex的話,那麼我們可以得到他的所有字串內容,就是string_ids池,這樣就可以判斷呼叫了哪些api。那麼就可以判斷這個apk的一些行為了,當然這裡還有一個問題,假如dex加密了我們就蛋疼了。好吧,那就牽涉出第二件事了。
2、我們在之前說過如何對apk進行加固,其實就是加密apk/dex檔案內容,那麼這時候我們必須要了解dex的檔案結構資訊,因為我們先加密dex,然後在動態載入dex進行解密即可。
3、我們可以更好的逆向工作,其實說到這裡,我們看看apktool原始碼也知道,他內部的反編譯原理就是這些,只是他會將指令翻譯成smail程式碼,這個網上是有相對應的jar包api的,所以我們知道了dex的資料結構,那麼原理肯定就知道了,同樣還有一個dex2jar工具原理也是類似的。
六、總結
到這裡我們就介紹完了dex檔案格式的解析工作,至此我們也解析完了Android中編譯之後的所有檔案格式,我之所以介紹這幾篇文章,一來是更好的瞭解Android中生成apk的流程,其次是我們能更好的的解決反編譯過程中遇到的問題,我們需要去解決。這篇文章解析起來還是很費勁的,累死了,也是2016年第一篇文章,謝謝大家的支援~~。記得點贊呀~~
相關文章
- Android逆向之旅---解析編譯之後的AndroidManifest檔案格式Android編譯
- Android逆向之旅---解析編譯之後的Resource.arsc檔案格式Android編譯
- Android逆向之旅---SO(ELF)檔案格式詳解Android
- iOS逆向之五 MACH O檔案解析iOSMac
- 淺談 Android Dex 檔案Android
- Android逆向之旅---Android應用的安全的攻防之戰Android
- 使用Reflector和Filedisassembler逆向編譯反編譯.cs.dll檔案程式碼編譯
- iOS逆向之旅(基礎篇) — Macho檔案iOSMac
- Go語言專案編譯之後找不到配置檔案Go編譯
- VirtualView Android實現詳解(一)—— 檔案格式與模板編譯ViewAndroid編譯
- Android之XML檔案解析AndroidXML
- 安卓逆向之Luac解密反編譯安卓解密編譯
- BVH檔案格式解析
- Android-ffmpeg編譯so檔案Android編譯
- Qt的.pro檔案格式解析QT
- 文字檔案的編碼格式
- DEX檔案解析--7、類及其類資料解析(完結篇)
- Reflector反編譯.NET檔案後修復編譯
- java class 檔案格式解析Java
- class與dex檔案
- Android 突破 DEX 檔案的 64K 方法數限制Android
- Android逆向之旅---反編譯利器Apktool和Jadx原始碼分析以及錯誤糾正Android編譯APK原始碼
- 如何修改檔案的編碼格式
- Android逆向之旅--免Root實現微信訊息同步原理解析Android
- Reflector反編譯.NET檔案後修復【轉】編譯
- MP4檔案格式解析
- Java解析ELF檔案:ELF檔案格式規範Java
- iOS逆向之旅(基礎篇) — 彙編(五) — 彙編下的BlockiOSBloC
- Android.mk各種檔案編譯彙總Android編譯
- 檔案上傳之解析漏洞編輯器安全
- Android小知識-如何載入外部dex檔案中的類Android
- PE檔案格式詳細解析(一)
- C語言編譯器開發之旅(二):解析器C語言編譯
- gcc編譯cpp檔案GC編譯
- 延遲載入 Dex 檔案
- maven編專案編譯後在target下的zip檔案損壞無法開啟Maven編譯
- iOS逆向之旅(基礎篇) — 彙編(四) — 彙編下的函式iOS函式
- iOS逆向之旅(基礎篇) — 彙編(二) — 彙編下的 IF語句iOS