Android逆向之旅---解析編譯之後的AndroidManifest檔案格式
一、前言
今天又是週六了,閒來無事,只能寫文章了呀,今天我們繼續來看逆向的相關知識,我們今天來介紹一下Android中的AndroidManifest檔案格式的內容,有的同學可能好奇了,AndroidManifest檔案格式有啥好說的呢?不會是介紹那些標籤和屬性是怎麼用的吧?那肯定不會,介紹那些知識有點無聊了,而且和我們的逆向也沒關係,我們今天要介紹的是Android中編譯之後的AndroidManifest檔案的格式,首先來腦補一個知識點,Android中的Apk程式其實就是一個壓縮包,我們可以用壓縮軟體進行解壓的:

二、技術介紹
我們可以看到這裡有三個檔案我們後續都會做詳細的解讀的:AndroidManifest.xml,classes.dex,resources.arsc
其實說到這裡只要反編譯過apk的同學都知道一個工具apktool,那麼其實他的工作原理就是解析這三個檔案格式,因為本身Android在編譯成apk之後,這個檔案有自己的格式,用普通文字格式開啟的話是亂碼的,看不懂的,所以需要解析他們成我們能看懂的東東,所以從這篇文章開始,陸續介紹這三個檔案的格式解析,這樣我們在後面反編譯apk的時候,遇到錯誤能夠精確的定位到問題。
今天我們先來看一下AndroidManifest.xml格式:

如果我們這裡顯示全是16進位制的內容,所以我們需要解析,就像我之前解析so檔案一樣:
http://blog.csdn.net/jiangwei0910410003/article/details/49336613
任何一個檔案都一定有他自己的格式,既然編譯成apk之後,變成這樣了,那麼google就是給AndroidManifest定義了一種檔案格式,我們只需要知道這種格式的話,就可以詳細的解析出來檔案了:
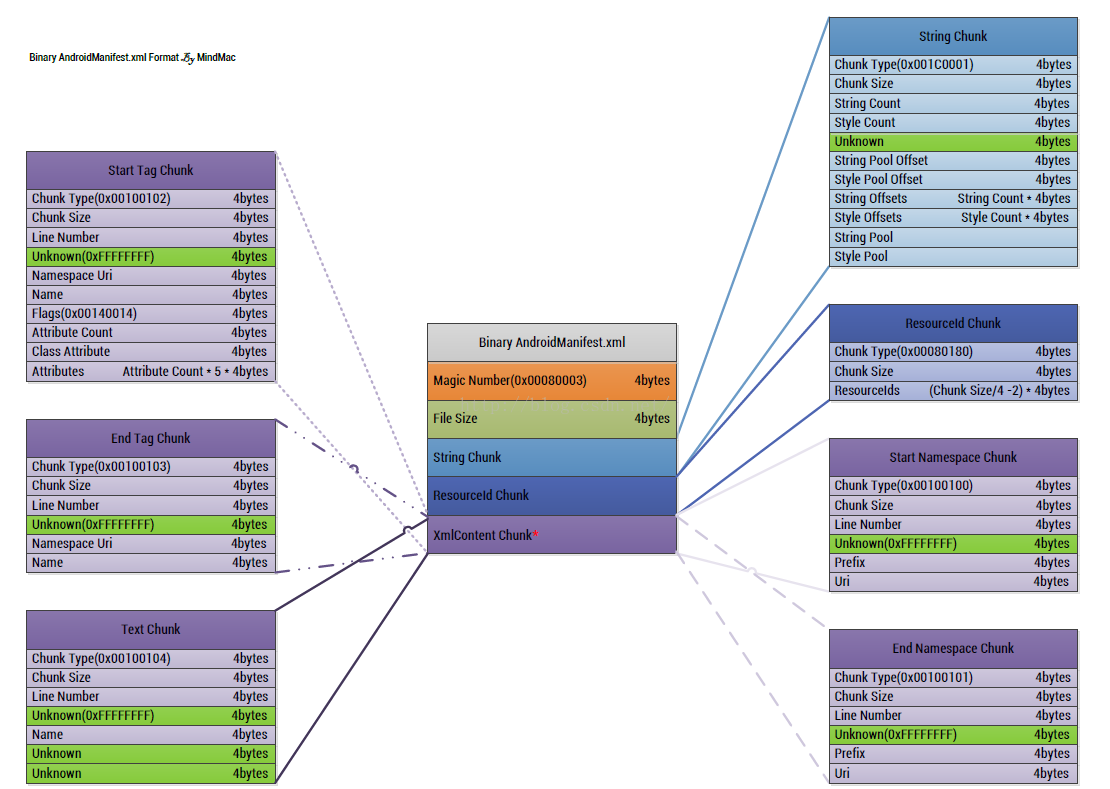
看到此圖是不是又很激動呢?這又是一張神圖,詳細的解析了AndroidManifest.xml檔案的格式,但是光看這張圖我們可以看不出來啥,所以要結合一個案例來解析一個檔案,這樣才能理解透徹,但是這樣圖是根基,下面我們就用一個案例來解析一下吧:
案例到處都是,誰便搞一個簡單的apk,用壓縮檔案開啟,解壓出AndroidManifest.xml就可以了,然後就開始讀取內容進行解析:
三、格式解析
第一、頭部資訊
任何一個檔案格式,都會有頭部資訊的,而且頭部資訊也很重要,同時,頭部一般都是固定格式的。

這裡的頭部資訊還有這些欄位資訊:
1、檔案魔數:四個位元組
2、檔案大小:四個位元組
下面就開始解析所有的Chunk內容了,其實每個Chunk的內容都有一個相似點,就是頭部資訊:
ChunkType(四個位元組)和ChunkSize(四個位元組)
第二、String Chunk內容
這個Chunk主要存放的是AndroidManifest檔案中所有的字串資訊
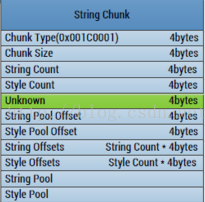
1、ChunkType:StringChunk的型別,固定四個位元組:0x001C0001
2、ChunkSize:StringChunk的大小,四個位元組
3、StringCount:StringChunk中字串的個數,四個位元組
4、StyleCount:StringChunk中樣式的個數,四個位元組,但是在實際解析過程中,這個值一直是0x00000000
5、Unknown:位置區域,四個位元組,在解析的過程中,這裡需要略過四個位元組
6、StringPoolOffset:字串池的偏移值,四個位元組,這個偏移值是相對於StringChunk的頭部位置
7、StylePoolOffset:樣式池的偏移值,四個位元組,這裡沒有Style,所以這個欄位可忽略
8、StringOffsets:每個字串的偏移值,所以他的大小應該是:StringCount*4個位元組
9、SytleOffsets:每個樣式的偏移值,所以他的大小應該是SytleCount*4個位元組
後面就開始是字串內容和樣式內容了。

下面我們就開始來看程式碼了,由於程式碼的篇幅有點長,所以這裡就分段說明,程式碼的整個工程,後面我會給出下載地址的,
1、首先我們需要把AndroidManifest.xml檔案讀入到一個byte陣列中:
byte[] byteSrc = null;
FileInputStream fis = null;
ByteArrayOutputStream bos = null;
try{
fis = new FileInputStream("xmltest/AndroidManifest1.xml");
bos = new ByteArrayOutputStream();
byte[] buffer = new byte[1024];
int len = 0;
while((len=fis.read(buffer)) != -1){
bos.write(buffer, 0, len);
}
byteSrc = bos.toByteArray();
}catch(Exception e){
System.out.println("parse xml error:"+e.toString());
}finally{
try{
fis.close();
bos.close();
}catch(Exception e){
}
}2、下面我們就來看看解析頭部資訊:
/**
* 解析xml的頭部資訊
* @param byteSrc
*/
public static void parseXmlHeader(byte[] byteSrc){
byte[] xmlMagic = Utils.copyByte(byteSrc, 0, 4);
System.out.println("magic number:"+Utils.bytesToHexString(xmlMagic));
byte[] xmlSize = Utils.copyByte(byteSrc, 4, 4);
System.out.println("xml size:"+Utils.bytesToHexString(xmlSize));
xmlSb.append("<?xml version=\"1.0\" encoding=\"utf-8\"?>");
xmlSb.append("\n");
}
3、解析StringChunk資訊
/**
* 解析StringChunk
* @param byteSrc
*/
public static void parseStringChunk(byte[] byteSrc){
//String Chunk的標示
byte[] chunkTagByte = Utils.copyByte(byteSrc, stringChunkOffset, 4);
System.out.println("string chunktag:"+Utils.bytesToHexString(chunkTagByte));
//String Size
byte[] chunkSizeByte = Utils.copyByte(byteSrc, 12, 4);
//System.out.println(Utils.bytesToHexString(chunkSizeByte));
int chunkSize = Utils.byte2int(chunkSizeByte);
System.out.println("chunk size:"+chunkSize);
//String Count
byte[] chunkStringCountByte = Utils.copyByte(byteSrc, 16, 4);
int chunkStringCount = Utils.byte2int(chunkStringCountByte);
System.out.println("count:"+chunkStringCount);
stringContentList = new ArrayList<String>(chunkStringCount);
//這裡需要注意的是,後面的四個位元組是Style的內容,然後緊接著的四個位元組始終是0,所以我們需要直接過濾這8個位元組
//String Offset 相對於String Chunk的起始位置0x00000008
byte[] chunkStringOffsetByte = Utils.copyByte(byteSrc, 28, 4);
int stringContentStart = 8 + Utils.byte2int(chunkStringOffsetByte);
System.out.println("start:"+stringContentStart);
//String Content
byte[] chunkStringContentByte = Utils.copyByte(byteSrc, stringContentStart, chunkSize);
/**
* 在解析字串的時候有個問題,就是編碼:UTF-8和UTF-16,如果是UTF-8的話是以00結尾的,如果是UTF-16的話以00 00結尾的
*/
/**
* 此處程式碼是用來解析AndroidManifest.xml檔案的
*/
//這裡的格式是:偏移值開始的兩個位元組是字串的長度,接著是字串的內容,後面跟著兩個字串的結束符00
byte[] firstStringSizeByte = Utils.copyByte(chunkStringContentByte, 0, 2);
//一個字元對應兩個位元組
int firstStringSize = Utils.byte2Short(firstStringSizeByte)*2;
System.out.println("size:"+firstStringSize);
byte[] firstStringContentByte = Utils.copyByte(chunkStringContentByte, 2, firstStringSize+2);
String firstStringContent = new String(firstStringContentByte);
stringContentList.add(Utils.filterStringNull(firstStringContent));
System.out.println("first string:"+Utils.filterStringNull(firstStringContent));
//將字串都放到ArrayList中
int endStringIndex = 2+firstStringSize+2;
while(stringContentList.size() < chunkStringCount){
//一個字元對應兩個位元組,所以要乘以2
int stringSize = Utils.byte2Short(Utils.copyByte(chunkStringContentByte, endStringIndex, 2))*2;
String str = new String(Utils.copyByte(chunkStringContentByte, endStringIndex+2, stringSize+2));
System.out.println("str:"+Utils.filterStringNull(str));
stringContentList.add(Utils.filterStringNull(str));
endStringIndex += (2+stringSize+2);
}
/**
* 此處的程式碼是用來解析資原始檔xml的
*/
/*int stringStart = 0;
int index = 0;
while(index < chunkStringCount){
byte[] stringSizeByte = Utils.copyByte(chunkStringContentByte, stringStart, 2);
int stringSize = (stringSizeByte[1] & 0x7F);
System.out.println("string size:"+Utils.bytesToHexString(Utils.int2Byte(stringSize)));
if(stringSize != 0){
//這裡注意是UTF-8編碼的
String val = "";
try{
val = new String(Utils.copyByte(chunkStringContentByte, stringStart+2, stringSize), "utf-8");
}catch(Exception e){
System.out.println("string encode error:"+e.toString());
}
stringContentList.add(val);
}else{
stringContentList.add("");
}
stringStart += (stringSize+3);
index++;
}
for(String str : stringContentList){
System.out.println("str:"+str);
}*/
resourceChunkOffset = stringChunkOffset + Utils.byte2int(chunkSizeByte);
}1、在上面的格式說明中,我們需要注意,有一個Unknow欄位,四個位元組,所以我們需要略過
2、在解析字串內容的時候,字串內容的結束符是:0x0000
3、每個字串開始的前兩個位元組是字串的長度
所以我們有了每個字串的偏移值和大小,那麼解析字串內容就簡單了:

這裡我們看到0x000B(高位和低位相反)就是字串的大小,結尾是0x0000
一個字元對應的是兩個位元組,而且這裡有一個方法:Utils.filterStringNull(firstStringContent):

public static String filterStringNull(String str){
if(str == null || str.length() == 0){
return str;
}
byte[] strByte = str.getBytes();
ArrayList<Byte> newByte = new ArrayList<Byte>();
for(int i=0;i<strByte.length;i++){
if(strByte[i] != 0){
newByte.add(strByte[i]);
}
}
byte[] newByteAry = new byte[newByte.size()];
for(int i=0;i<newByteAry.length;i++){
newByteAry[i] = newByte.get(i);
}
return new String(newByteAry);
}
每個字元是寬字元,很難看,其實願意就是每個字元後面多了一個00,所以過濾之後就可以了


這樣就好看多了。
上面我們就解析了AndroidManifest.xml中所有的字串內容。這裡我們需要用一個全域性的字元列表,用來儲存這些字串的值,後面會用索引來獲取這些字串的值。
第三、解析ResourceIdChunk
這個Chunk主要是存放的是AndroidManifest中用到的系統屬性值對應的資源Id,比如android:versionCode中的versionCode屬性,android是字首,後面會說道

1、ChunkType:ResourceIdChunk的型別,固定四個位元組:0x00080108
2、ChunkSize:ResourceChunk的大小,四個位元組
3、ResourceIds:ResourceId的內容,這裡大小是ResourceChunk大小除以4,減去頭部的大小8個位元組(ChunkType和ChunkSize)

/**
* 解析Resource Chunk
* @param byteSrc
*/
public static void parseResourceChunk(byte[] byteSrc){
byte[] chunkTagByte = Utils.copyByte(byteSrc, resourceChunkOffset, 4);
System.out.println(Utils.bytesToHexString(chunkTagByte));
byte[] chunkSizeByte = Utils.copyByte(byteSrc, resourceChunkOffset+4, 4);
int chunkSize = Utils.byte2int(chunkSizeByte);
System.out.println("chunk size:"+chunkSize);
//這裡需要注意的是chunkSize是包含了chunkTag和chunkSize這兩個位元組的,所以需要剔除
byte[] resourceIdByte = Utils.copyByte(byteSrc, resourceChunkOffset+8, chunkSize-8);
ArrayList<Integer> resourceIdList = new ArrayList<Integer>(resourceIdByte.length/4);
for(int i=0;i<resourceIdByte.length;i+=4){
int resId = Utils.byte2int(Utils.copyByte(resourceIdByte, i, 4));
System.out.println("id:"+resId+",hex:"+Utils.bytesToHexString(Utils.copyByte(resourceIdByte, i, 4)));
resourceIdList.add(resId);
}
nextChunkOffset = (resourceChunkOffset+chunkSize);
}
我們看到這裡解析出來的id到底是什麼呢?

這裡需要腦補一個知識點了:
我們在寫Android程式的時候,都會發現有一個R檔案,那裡面就是存放著每個資源對應的Id,那麼這些id值是怎麼得到的呢?
Package ID相當於是一個名稱空間,限定資源的來源。Android系統當前定義了兩個資源命令空間,其中一個系統資源命令空間,它的Package ID等於0x01,另外一個是應用程式資源命令空間,它的Package ID等於0x7f。所有位於[0x01, 0x7f]之間的Package ID都是合法的,而在這個範圍之外的都是非法的Package ID。前面提到的系統資源包package-export.apk的Package ID就等於0x01,而我們在應用程式中定義的資源的Package
ID的值都等於0x7f,這一點可以通過生成的R.java檔案來驗證。
Type ID是指資源的型別ID。資源的型別有animator、anim、color、drawable、layout、menu、raw、string和xml等等若干種,每一種都會被賦予一個ID。
Entry ID是指每一個資源在其所屬的資源型別中所出現的次序。注意,不同型別的資源的Entry ID有可能是相同的,但是由於它們的型別不同,我們仍然可以通過其資源ID來區別開來。
關於資源ID的更多描述,以及資源的引用關係,可以參考frameworks/base/libs/utils目錄下的README檔案
我們可以得知系統資源對應id的xml檔案是在哪裡:frameworks\base\core\res\res\values\public.xml

那麼我們用上面解析到的id,去public.xml檔案中查詢一下:

查到了,是versionCode,對於這個系統資源id存放檔案public.xml還是很重要的,後面在講解resource.arsc檔案格式的時候還會繼續用到。
第四、解析StartNamespaceChunk
這個Chunk主要包含一個AndroidManifest檔案中的命令空間的內容,Android中的xml都是採用Schema格式的,所以肯定有Prefix和Uri的。
這裡在腦補一個知識點:xml格式有兩種:DTD和Schema,不瞭解的同學可以閱讀這篇文章
http://blog.csdn.net/jiangwei0910410003/article/details/19340975

1、ChunkType:Chunk的型別,固定四個位元組:0x00100100
2、ChunkSize:Chunk的大小,四個位元組
3、LineNumber:在AndroidManifest檔案中的行號,四個位元組
4、Unknown:未知區域,四個位元組
5、Prefix:名稱空間的字首(在字串中的索引值),比如:android
6、Uri:名稱空間的uri(在字串中的索引值):比如:http://schemas.android.com/apk/res/android

解析程式碼:
/**
* 解析StartNamespace Chunk
* @param byteSrc
*/
public static void parseStartNamespaceChunk(byte[] byteSrc){
//獲取ChunkTag
byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4);
System.out.println(Utils.bytesToHexString(chunkTagByte));
//獲取ChunkSize
byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4);
int chunkSize = Utils.byte2int(chunkSizeByte);
System.out.println("chunk size:"+chunkSize);
//解析行號
byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4);
int lineNumber = Utils.byte2int(lineNumberByte);
System.out.println("line number:"+lineNumber);
//解析prefix(這裡需要注意的是行號後面的四個位元組為FFFF,過濾)
byte[] prefixByte = Utils.copyByte(byteSrc, 16, 4);
int prefixIndex = Utils.byte2int(prefixByte);
String prefix = stringContentList.get(prefixIndex);
System.out.println("prefix:"+prefixIndex);
System.out.println("prefix str:"+prefix);
//解析Uri
byte[] uriByte = Utils.copyByte(byteSrc, 20, 4);
int uriIndex = Utils.byte2int(uriByte);
String uri = stringContentList.get(uriIndex);
System.out.println("uri:"+uriIndex);
System.out.println("uri str:"+uri);
uriPrefixMap.put(uri, prefix);
prefixUriMap.put(prefix, uri);
}解析的結果如下:

這裡的內容就是上面我們解析完String之後的對應的字串索引值,這裡我們需要注意的是,一個xml中可能會有多個名稱空間,所以這裡我們用Map儲存Prefix和Uri對應的關係,後面在解析節點內容的時候會用到。
第五、StratTagChunk
這個Chunk主要是存放了AndroidManifest.xml中的標籤資訊了,也是最核心的內容,當然也是最複雜的內容
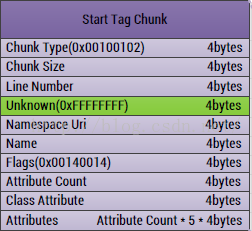
1、ChunkType:Chunk的型別,固定四個位元組:0x00100102
2、ChunkSize:Chunk的大小,固定四個位元組
3、LineNumber:對應於AndroidManifest中的行號,四個位元組
4、Unknown:未知領域,四個位元組
5、NamespaceUri:這個標籤用到的名稱空間的Uri,比如用到了android這個字首,那麼就需要用http://schemas.android.com/apk/res/android這個Uri去獲取,四個位元組
6、Name:標籤名稱(在字串中的索引值),四個位元組
7、Flags:標籤的型別,四個位元組,比如是開始標籤還是結束標籤等
8、AttributeCount:標籤包含的屬性個數,四個位元組
9、ClassAtrribute:標籤包含的類屬性,四個位元組
10,Atrributes:屬性內容,每個屬性算是一個Entry,這個Entry固定大小是大小為5的位元組陣列:
[Namespace,Uri,Name,ValueString,Data],我們在解析的時候需要注意第四個值,要做一次處理:需要右移24位。所以這個欄位的大小是:屬性個數*5*4個位元組

解析程式碼:
/**
* 解析StartTag Chunk
* @param byteSrc
*/
public static void parseStartTagChunk(byte[] byteSrc){
//解析ChunkTag
byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4);
System.out.println(Utils.bytesToHexString(chunkTagByte));
//解析ChunkSize
byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4);
int chunkSize = Utils.byte2int(chunkSizeByte);
System.out.println("chunk size:"+chunkSize);
//解析行號
byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4);
int lineNumber = Utils.byte2int(lineNumberByte);
System.out.println("line number:"+lineNumber);
//解析prefix
byte[] prefixByte = Utils.copyByte(byteSrc, 8, 4);
int prefixIndex = Utils.byte2int(prefixByte);
//這裡可能會返回-1,如果返回-1的話,那就是說沒有prefix
if(prefixIndex != -1 && prefixIndex<stringContentList.size()){
System.out.println("prefix:"+prefixIndex);
System.out.println("prefix str:"+stringContentList.get(prefixIndex));
}else{
System.out.println("prefix null");
}
//解析Uri
byte[] uriByte = Utils.copyByte(byteSrc, 16, 4);
int uriIndex = Utils.byte2int(uriByte);
if(uriIndex != -1 && prefixIndex<stringContentList.size()){
System.out.println("uri:"+uriIndex);
System.out.println("uri str:"+stringContentList.get(uriIndex));
}else{
System.out.println("uri null");
}
//解析TagName
byte[] tagNameByte = Utils.copyByte(byteSrc, 20, 4);
System.out.println(Utils.bytesToHexString(tagNameByte));
int tagNameIndex = Utils.byte2int(tagNameByte);
String tagName = stringContentList.get(tagNameIndex);
if(tagNameIndex != -1){
System.out.println("tag name index:"+tagNameIndex);
System.out.println("tag name str:"+tagName);
}else{
System.out.println("tag name null");
}
//解析屬性個數(這裡需要過濾四個位元組:14001400)
byte[] attrCountByte = Utils.copyByte(byteSrc, 28, 4);
int attrCount = Utils.byte2int(attrCountByte);
System.out.println("attr count:"+attrCount);
//解析屬性
//這裡需要注意的是每個屬性單元都是由五個元素組成,每個元素佔用四個位元組:namespaceuri, name, valuestring, type, data
//在獲取到type值的時候需要右移24位
ArrayList<AttributeData> attrList = new ArrayList<AttributeData>(attrCount);
for(int i=0;i<attrCount;i++){
Integer[] values = new Integer[5];
AttributeData attrData = new AttributeData();
for(int j=0;j<5;j++){
int value = Utils.byte2int(Utils.copyByte(byteSrc, 36+i*20+j*4, 4));
switch(j){
case 0:
attrData.nameSpaceUri = value;
break;
case 1:
attrData.name = value;
break;
case 2:
attrData.valueString = value;
break;
case 3:
value = (value >> 24);
attrData.type = value;
break;
case 4:
attrData.data = value;
break;
}
values[j] = value;
}
attrList.add(attrData);
}
for(int i=0;i<attrCount;i++){
if(attrList.get(i).nameSpaceUri != -1){
System.out.println("nameSpaceUri:"+stringContentList.get(attrList.get(i).nameSpaceUri));
}else{
System.out.println("nameSpaceUri == null");
}
if(attrList.get(i).name != -1){
System.out.println("name:"+stringContentList.get(attrList.get(i).name));
}else{
System.out.println("name == null");
}
if(attrList.get(i).valueString != -1){
System.out.println("valueString:"+stringContentList.get(attrList.get(i).valueString));
}else{
System.out.println("valueString == null");
}
System.out.println("type:"+AttributeType.getAttrType(attrList.get(i).type));
System.out.println("data:"+AttributeType.getAttributeData(attrList.get(i)));
}
//這裡開始構造xml結構
xmlSb.append(createStartTagXml(tagName, attrList));
}解析屬性:
//解析屬性
//這裡需要注意的是每個屬性單元都是由五個元素組成,每個元素佔用四個位元組:namespaceuri, name, valuestring, type, data
//在獲取到type值的時候需要右移24位
ArrayList<AttributeData> attrList = new ArrayList<AttributeData>(attrCount);
for(int i=0;i<attrCount;i++){
Integer[] values = new Integer[5];
AttributeData attrData = new AttributeData();
for(int j=0;j<5;j++){
int value = Utils.byte2int(Utils.copyByte(byteSrc, 36+i*20+j*4, 4));
switch(j){
case 0:
attrData.nameSpaceUri = value;
break;
case 1:
attrData.name = value;
break;
case 2:
attrData.valueString = value;
break;
case 3:
value = (value >> 24);
attrData.type = value;
break;
case 4:
attrData.data = value;
break;
}
values[j] = value;
}
attrList.add(attrData);
}解析完屬性之後,那麼就可以得到一個標籤的名稱和屬性名稱和屬性值了:
看解析的結果:


標籤manifest包含的屬性:

這裡有幾個問題需要解釋一下:
1、為什麼我們看到的是三個屬性,但是解析列印的結果是5個?
因為系統在編譯apk的時候,會新增兩個屬性:platformBuildVersionCode和platformBuildVersionName
這個是釋出的到裝置的版本號和版本名稱

這個是解析之後的結果
2、當沒有android這樣的字首的時候,NamespaceUri是null

3、當dataType不同,對應的data值也是有不同的含義的:

這個方法就是用來轉義的,後面在解析resource.arsc的時候也會用到這個方法。
4、每個屬性理論上都會含有一個NamespaceUri的,這個也決定了屬性的字首Prefix,預設都是android,但是有時候我們會自定義一個控制元件的時候,這時候就需要匯入NamespaceUri和Prefix了。所以一個xml中可能會有多個Namespace,每個屬性都會包含NamespaceUri的。
其實到這裡我們就算解析完了大部分的工作了,至於還有EndTagChunk,那個和StartTagChunk非常類似,這裡就不在詳解了:
/**
* 解析EndTag Chunk
* @param byteSrc
*/
public static void parseEndTagChunk(byte[] byteSrc){
byte[] chunkTagByte = Utils.copyByte(byteSrc, 0, 4);
System.out.println(Utils.bytesToHexString(chunkTagByte));
byte[] chunkSizeByte = Utils.copyByte(byteSrc, 4, 4);
int chunkSize = Utils.byte2int(chunkSizeByte);
System.out.println("chunk size:"+chunkSize);
//解析行號
byte[] lineNumberByte = Utils.copyByte(byteSrc, 8, 4);
int lineNumber = Utils.byte2int(lineNumberByte);
System.out.println("line number:"+lineNumber);
//解析prefix
byte[] prefixByte = Utils.copyByte(byteSrc, 8, 4);
int prefixIndex = Utils.byte2int(prefixByte);
//這裡可能會返回-1,如果返回-1的話,那就是說沒有prefix
if(prefixIndex != -1 && prefixIndex<stringContentList.size()){
System.out.println("prefix:"+prefixIndex);
System.out.println("prefix str:"+stringContentList.get(prefixIndex));
}else{
System.out.println("prefix null");
}
//解析Uri
byte[] uriByte = Utils.copyByte(byteSrc, 16, 4);
int uriIndex = Utils.byte2int(uriByte);
if(uriIndex != -1 && prefixIndex<stringContentList.size()){
System.out.println("uri:"+uriIndex);
System.out.println("uri str:"+stringContentList.get(uriIndex));
}else{
System.out.println("uri null");
}
//解析TagName
byte[] tagNameByte = Utils.copyByte(byteSrc, 20, 4);
System.out.println(Utils.bytesToHexString(tagNameByte));
int tagNameIndex = Utils.byte2int(tagNameByte);
String tagName = stringContentList.get(tagNameIndex);
if(tagNameIndex != -1){
System.out.println("tag name index:"+tagNameIndex);
System.out.println("tag name str:"+tagName);
}else{
System.out.println("tag name null");
}
xmlSb.append(createEndTagXml(tagName));
}但是我們在解析的時候,我們需要做一個迴圈操作:

因為我們知道,Android中在解析Xml的時候提供了很多種方式,但是這裡我們沒有用任何一種方式,而是用純程式碼編寫的,所以用一個迴圈,來遍歷解析Tag,其實這種方式類似於SAX解析XML,這時候上面說到的那個Flag欄位就大有用途了。
這裡我們還做了一個工作就是將解析之後的xml格式化一下:

難度不大,這裡也就不繼續解釋了,這裡有一個地方需要優化的就是,可以利用LineNumber屬性來,精確到格式化行數,不過這個工作量有點大,這裡就不想做了,有興趣的同學可以考慮一下,格式化完之後的結果:

帥氣不帥氣,把手把手的將之前的16進位制的內容解析出來了,吊吊的,成就感爆棚呀~~
這裡有一個問題,就是我們看到這裡還有很多@7F070001這類的東西,這個其實是資源Id,這個需要我們後面解析完resource.arsc檔案之後,就可以對應上這個資源了,後面會在提到一下。這裡就知道一下可以了。
這裡其實還有一個問題,就是我們發現這個可以解析AndroidManifest檔案了,那麼同樣也可以解析其他的xml檔案:

擦,我們發現解析其他xml的時候,發現報錯了,定位程式碼發現是在解析StringChunk的地方報錯了,我們修改一下:

因為其他的xml中的字串格式和AndroidManifest.xml中的不一樣,所以這裡需要單獨解析一下:

修改之後就可以了。
四、技術擴充
在反編譯的時候,有時候我們只想反編譯AndroidManifest內容,所以ApkTool工具就有點繁瑣了,不過網上有個牛逼的大神已經寫好了這個工具AXMLPrinter.jar,這個工具很好用的:java -jar AXMLPrinter.java xxx.xml >demo.xml
將xxx.xml解析之後輸出到demo.xml中即可
工具下載下載地址:http://download.csdn.net/detail/jiangwei0910410003/9415323
不過這個大神和我一樣有著開源的精神,原始碼下載地址:
http://download.csdn.net/detail/jiangwei0910410003/9415342

從專案結構我們可以發現,他用的是Android中自帶的Pull解析xml的,主函式是:

注意:
到這裡我們還需要告訴一件事,那就是其實我們上面的解析工作,有一個更簡單的方法就可以搞定了?那就是aapt命令?關於這個aapt是幹啥的?網上有很多資料,他其實很簡單就是將Android中的資原始檔打包成resource.arsc即可:

只有那些型別為res/animator、res/anim、res/color、res/drawable(非Bitmap檔案,即非.png、.9.png、.jpg、.gif檔案)、res/layout、res/menu、res/values和res/xml的資原始檔均會從文字格式的XML檔案編譯成二進位制格式的XML檔案
這些XML資原始檔之所要從文字格式編譯成二進位制格式,是因為:
1. 二進位制格式的XML檔案佔用空間更小。這是由於所有XML元素的標籤、屬性名稱、屬性值和內容所涉及到的字串都會被統一收集到一個字串資源池中去,並且會去重。有了這個字串資源池,原來使用字串的地方就會被替換成一個索引到字串資源池的整數值,從而可以減少檔案的大小。
2. 二進位制格式的XML檔案解析速度更快。這是由於二進位制格式的XML元素裡面不再包含有字串值,因此就避免了進行字串解析,從而提高速度。
將XML資原始檔從文字格式編譯成二進位制格式解決了空間佔用以及解析效率的問題,但是對於Android資源管理框架來說,這只是完成了其中的一部分工作。Android資源管理框架的另外一個重要任務就是要根據資源ID來快速找到對應的資源。
那麼下面我們用aapt命令就可以檢視一下?
aapt命令在我們的AndroidSdk目錄中:

看到路徑了:Android-SDK目錄/build-tools/下面
我們也就知道了,這個目錄下全是Android中build成一個apk的所有工具,這裡再看一下這些工具的用途:
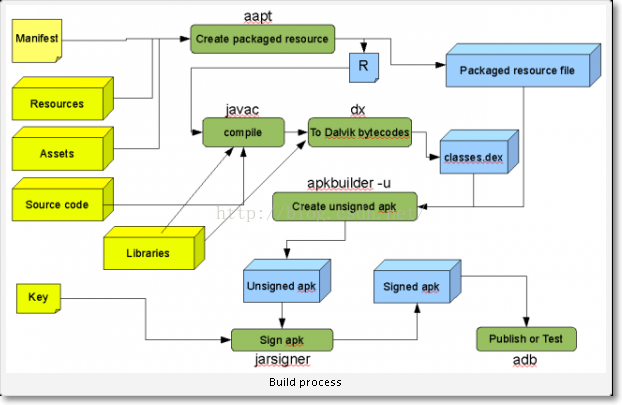
1、使用Android SDK提供的aapt.exe生成R.java類檔案
2、使用Android SDK提供的aidl.exe把.aidl轉成.java檔案(如果沒有aidl,則跳過這一步)
3、使用JDK提供的javac.exe編譯.java類檔案生成class檔案
4、使用Android SDK提供的dx.bat命令列指令碼生成classes.dex檔案
5、使用Android SDK提供的aapt.exe生成資源包檔案(包括res、assets、androidmanifest.xml等)
6、使用Android SDK提供的apkbuilder.bat生成未簽名的apk安裝檔案
7、使用jdk的jarsigner.exe對未簽名的包進行apk簽名
看到了吧。我們原來可以不借助任何IDE工具,也是可以出一個apk包的。哈哈~~
繼續看aapt命令的用法,命令很簡單:
aapt l -a apk名稱 > demo.txt
將輸入的結果定向到demo.txt中

看到我們弄出來的內容,發現就是我們上面解析的AndroidManifest.xml內容,所以這個也是一個方法,當然aapt命令這裡我為什麼最後說呢?之前我們講解的AndroidManifest.xml格式肯定是有用的,aapt命令只是系統提供給我們一個很好的工具,我們可以在反編譯的過程中藉助這個工具也是不錯的選擇。所以這裡我就想說,以後我們記得有一個aapt命令就好了,他的用途還是很多的,可以單獨編譯成一個resource.arsc檔案來,我們後面會用到這個命令。
專案下載地址:http://download.csdn.net/detail/jiangwei0910410003/9415325
五、為什麼要寫這篇文章
那麼現在我們也可以不用這個工具了,因為我們自己也寫了一個工具解析,是不是很吊吊的呢?那麼我們這篇文章僅僅是為了解析AndroidManifest嗎?肯定不是,寫這篇文章其實是另有目的的,為我們後面在反編譯apk做準備,其實現在有很多同學都發現了,在使用apktool來反編譯apk的時候經常報出一些異常資訊,其實那些就是加固的人,用來對抗apktool工具的,他們專門找apktool的漏洞,然後進行加固,從而達到反編譯失敗的效果,所以我們有必要了解apktool的原始碼和解析原理,這樣才能遇到反編譯失敗的錯誤的時候,能定位到問題,在修復apktool工具即可,那麼apktool的工具解析原理其實很簡單,就是解析AndroidManifest.xml,然後是解析resource.arsc到public.xml(這個檔案一般是反編譯之後存放在values資料夾下面的,是整個反編譯之後的工程對應的Id列表),其次就是classes.dex。還有其他的佈局,資源xml等,那麼針對於這幾個問題,我們這篇文章就講解了:解析XML檔案的問題。後面還會繼續講解如何解析resource.arsc和classes.dex檔案的格式。當然後面我會介紹一篇關於如果通過修改AndroidManifest檔案內容來達到加固的效果,以及如何我們做修復來破解這種加固。
六、總結
這篇文章到這裡就算結束了,寫的有點累了,解析程式碼已經有下載地址了,有不理解的同學可以聯絡我,加入公眾號,留言問題,我會在適當的時間給予回覆,謝謝,同時記得關注後面的兩篇解析resource.arsc和classes.dex檔案格式的文章。謝謝~~
相關文章
- Android逆向之旅---解析編譯之後的Dex檔案格式Android編譯
- Android逆向之旅---解析編譯之後的Resource.arsc檔案格式Android編譯
- Android逆向之旅---SO(ELF)檔案格式詳解Android
- Android學習筆記之AndroidManifest.xml檔案解析(詳解)Android筆記XML
- AndroidManifest.xml檔案解析AndroidXML
- Android逆向(一) —— AndroidManifest.xml 二進位制解析AndroidXML
- iOS逆向之五 MACH O檔案解析iOSMac
- Android逆向之旅---Android應用的安全的攻防之戰Android
- 使用Reflector和Filedisassembler逆向編譯反編譯.cs.dll檔案程式碼編譯
- iOS逆向之旅(基礎篇) — Macho檔案iOSMac
- Go語言專案編譯之後找不到配置檔案Go編譯
- VirtualView Android實現詳解(一)—— 檔案格式與模板編譯ViewAndroid編譯
- Android之XML檔案解析AndroidXML
- Android與Python之批量修改AndroidManifest.xml檔案AndroidPythonXML
- 安卓逆向之Luac解密反編譯安卓解密編譯
- BVH檔案格式解析
- Android-ffmpeg編譯so檔案Android編譯
- Qt的.pro檔案格式解析QT
- [android]AndroidManifest.xml解析AndroidXML
- 文字檔案的編碼格式
- Reflector反編譯.NET檔案後修復編譯
- java class 檔案格式解析Java
- Android逆向之旅---反編譯利器Apktool和Jadx原始碼分析以及錯誤糾正Android編譯APK原始碼
- 如何修改檔案的編碼格式
- Android逆向之旅--免Root實現微信訊息同步原理解析Android
- Reflector反編譯.NET檔案後修復【轉】編譯
- MP4檔案格式解析
- Java解析ELF檔案:ELF檔案格式規範Java
- [android]快速檢視apk內androidmanifest檔案內容AndroidAPK
- iOS逆向之旅(基礎篇) — 彙編(五) — 彙編下的BlockiOSBloC
- Android.mk各種檔案編譯彙總Android編譯
- 檔案上傳之解析漏洞編輯器安全
- PE檔案格式詳細解析(一)
- C語言編譯器開發之旅(二):解析器C語言編譯
- gcc編譯cpp檔案GC編譯
- maven編專案編譯後在target下的zip檔案損壞無法開啟Maven編譯
- iOS逆向之旅(基礎篇) — 彙編(四) — 彙編下的函式iOS函式
- iOS逆向之旅(基礎篇) — 彙編(二) — 彙編下的 IF語句iOS