Oracle行列互換總結
-
Oracle行列互換總結

最近論壇很多人提的問題都與行列轉換有關係,所以我對行列轉換的相關知識做了一個總結,希望對大家有所幫助,同時有何錯疏,懇請大家指出,我也是在寫作過程中學習,算是一起和大家學習吧!
行列轉換包括以下六種情況:
-
列轉行
-
行轉列
-
多列轉換成字串
-
多行轉換成字串
-
字串轉換成多列
-
字串轉換成多行
下面分別進行舉例介紹。
首先宣告一點,有些例子需要如下10g 及以後才有的知識:
A. 掌握model子句
B. 正規表示式
C. 加強的層次查詢
討論的適用範圍只包括8i,9i,10g 及以後版本。
-
列轉行
首先需要明白什麼是列轉行,簡單的說就是將原表中的列名作為轉換後的表的內容,這就是列轉行。
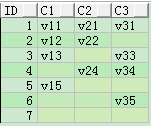
CREATE TABLE t_col_row(
ID INT,
c1 VARCHAR2(10),
c2 VARCHAR2(10),
c3 VARCHAR2(10));
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');
INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);
INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');
INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');
INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');
INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);
COMMIT;
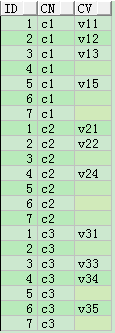
SELECT * FROM t_col_row;

-
UNION ALL ---主要方法
適用範圍:8i,9i,10g 及以後版本
-
例一
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv
FROM t_col_row;
若空行不需要轉換,只需加一個where條件,
WHERE COLUMN IS NOT NULL 即可。
如:
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
where c1 is not null
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
where c2 is not null
UNION ALL
SELECT id, 'c3' cn, c3 cv
FROM t_col_row
where c3 is not null;
-
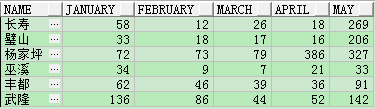
例二
create table TEST_LHR
(
NAME VARCHAR2(255),
JANUARY NUMBER(18),
FEBRUARY NUMBER(18),
MARCH NUMBER(18),
APRIL NUMBER(18),
MAY NUMBER(18)
)
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('長壽', 58, 12, 26, 18, 269);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('璧山', 33, 18, 17, 16, 206);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('楊家坪', 72, 73, 79, 386, 327);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('巫溪', 34, 9, 7, 21, 33);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('豐都', 62, 46, 39, 36, 91);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('武隆', 136, 86, 44, 52, 142);
commit;
SELECT *
FROM (SELECT t.name,
'january' MONTH,
t.january v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'february' MONTH,
t.february v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'march' MONTH,
t.march v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'april' MONTH,
t.april v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'may' MONTH,
t.may v_num
FROM TEST_LHR t)
ORDER BY NAME;

-
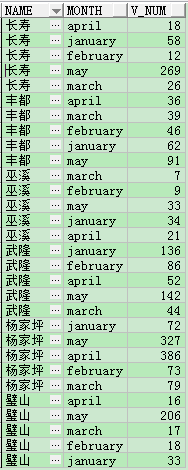
insert all into ... select
首先建立需要的表,test_lhr1,
SQL> desc test_lhr1
Name Type Nullable Default Comments
----- ------------- -------- ------- --------
NAME VARCHAR2(255) Y
MONTH VARCHAR2(8) Y
V_NUM NUMBER(18) Y
然後執行下邊的sql語句:
insert all
into test_lhr1(NAME,month,v_num) values(name, 'may', may)
into test_lhr1(NAME,month,v_num) values(name, 'april', april)
into test_lhr1(NAME,month,v_num) values(name, 'february', february)
into test_lhr1(NAME,month,v_num) values(name, 'march', march)
into test_lhr1(NAME,month,v_num) values(name, 'january', january)
select t.name,t.january,t.february,t.march,t.april,t.may from test_lhr t;
commit;
別忘記commit操作,然後再查詢test_lhr1,發現表中的資料就是列轉成行了。
select * from test_lhr1;
-
MODEL
適用範圍:10g 及以後
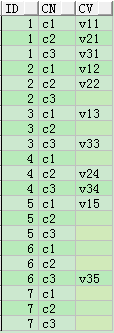
SELECT id,
cn,
cv
FROM t_col_row
MODEL RETURN
UPDATED ROWS PARTITION BY(ID)
DIMENSION BY(0 AS n)
MEASURES('xx' AS cn, 'yyy' AS cv, c1, c2, c3)
RULES UPSERT ALL(cn[1] = 'c1', cn[2] = 'c2', cn[3] = 'c3', cv[1] = c1[0], cv[2] = c2[0], cv[3] = c3[0])
ORDER BY ID,
cn;
-
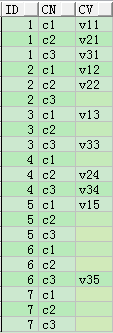
COLLECTION
適用範圍:8i,9i,10g 及以後版本
要建立一個物件和一個集合:
CREATE TYPE cv_pair AS OBJECT(cn VARCHAR2(10),cv VARCHAR2(10));
CREATE TYPE cv_varr AS VARRAY(8) OF cv_pair;
SELECT id,
t.cn AS cn,
t.cv AS cv
FROM t_col_row,
TABLE(cv_varr(cv_pair('c1', t_col_row.c1),
cv_pair('c2', t_col_row.c2),
cv_pair('c3', t_col_row.c3))) t
ORDER BY 1,
2;
-
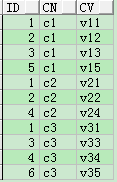
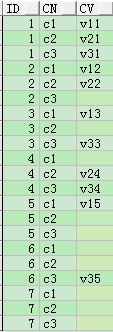
行轉列
行轉列就是將行資料內容作為列名。
CREATE TABLE t_row_col AS
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
SELECT * FROM t_row_col ORDER BY 1,2;
-
AGGREGATE FUNCTION(max+decode) ---主要方法
用聚集函式來實現,適用範圍:8i,9i,10g 及以後版本
-
例一
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1,
MAX(decode(cn, 'c2', cv, NULL)) AS c2,
MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col
GROUP BY id
ORDER BY 1;

? 注意:
-
MAX聚集函式也可以用sum、min、avg 等其他聚集函式替代。
-
被指定的轉置列只能有一列,但固定的列可以有多列,如果轉置列有多列可以有2種辦法解決,① 採用1.3.2建立臨時表的方式
② 可以先轉為單列,單列採用字串的格式,然後將單列轉換為多列
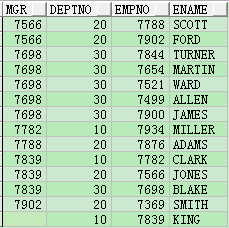
請看下面的例子:
SELECT mgr,
deptno,
empno,
ename
FROM emp
ORDER BY 1,
2;
SELECT mgr,
deptno,
MAX(decode(empno, '7788', ename, NULL)) "7788",
MAX(decode(empno, '7902', ename, NULL)) "7902",
MAX(decode(empno, '7844', ename, NULL)) "7844",
MAX(decode(empno, '7521', ename, NULL)) "7521",
MAX(decode(empno, '7900', ename, NULL)) "7900",
MAX(decode(empno, '7499', ename, NULL)) "7499",
MAX(decode(empno, '7654', ename, NULL)) "7654"
FROM emp
WHERE mgr IN (7566, 7698)
AND deptno IN (20, 30)
GROUP BY mgr, deptno
ORDER BY 1, 2;

這裡轉置列為empno,固定列為mgr,deptno。
1、固定列數的行列轉換
如
student subject grade
---------------------------
student1 語文 80
student1 數學 70
student1 英語 60
student2 語文 90
student2 數學 80
student2 英語 100
……
轉換為
語文 數學 英語
student1 80 70 60
student2 90 80 100
……
語句如下:
select student,sum(decode(subject,'語文', grade,null)) "語文",
sum(decode(subject,'數學', grade,null)) "數學",
sum(decode(subject,'英語', grade,null)) "英語"
from table
group by student
2、不定列行列轉換
如
c1 c2
--------------
1 我
1 是
1 誰
2 知
2 道
3 不
……
轉換為
1 我是誰
2 知道
3 不
這一型別的轉換必須藉助於PL/SQL來完成,這裡給一個例子
CREATE OR REPLACE FUNCTION get_c2(tmp_c1 NUMBER)
RETURN VARCHAR2
IS
Col_c2 VARCHAR2(4000);
BEGIN
FOR cur IN (SELECT c2 FROM t WHERE c1=tmp_c1) LOOP
Col_c2 := Col_c2||cur.c2;
END LOOP;
Col_c2 := rtrim(Col_c2,1);
RETURN Col_c2;
END;
/
SQL> select distinct c1 ,get_c2(c1) cc2 from table;即可
還有一種行轉列的方式,就是相同組中的行值變為單個列值,但轉置的行值不變為列名:
ID CN_1 CV_1 CN_2 CV_2 CN_3 CV_3
1 c1 v11 c2 v21 c3 v31
2 c1 v12 c2 v22 c3
3 c1 v13 c2 c3 v33
4 c1 c2 v24 c3 v34
5 c1 v15 c2 c3
6 c1 c2 c3 v35
7 c1 c2 c3
這種情況可以用分析函式實現:
SELECT id,
MAX(decode(rn, 1, cn, NULL)) cn_1,
MAX(decode(rn, 1, cv, NULL)) cv_1,
MAX(decode(rn, 2, cn, NULL)) cn_2,
MAX(decode(rn, 2, cv, NULL)) cv_2,
MAX(decode(rn, 3, cn, NULL)) cn_3,
MAX(decode(rn, 3, cv, NULL)) cv_3
FROM (SELECT id,
cn,
cv,
row_number() over(PARTITION BY id ORDER BY cn, cv) rn
FROM t_row_col)
GROUP BY ID;
-
例二
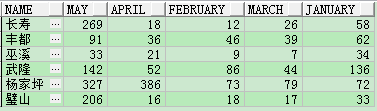
SELECT t.name,
MAX(decode(t.month, 'may', t.v_num)) AS may,
MAX(decode(t.month, 'april', t.v_num)) AS april,
MAX(decode(t.month, 'february', t.v_num)) AS february,
MAX(decode(t.month, 'march', t.v_num)) AS march,
MAX(decode(t.month, 'january', t.v_num)) AS january
FROM test_lhr1 t
GROUP BY t.name;
-
延伸
如果要實現對各個不同的區間進行統計,則:
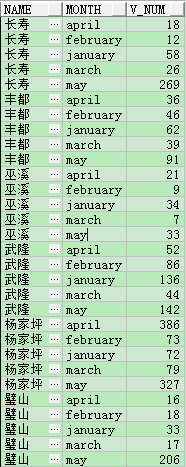
SELECT *
FROM test_lhr1 t
ORDER BY t.name,
t.month;
SELECT t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END AS grade,
COUNT(t.v_num) count_num
FROM test_lhr1 t
GROUP BY t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END;

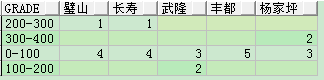
SELECT t2.grade,
MAX(decode(t2.name, '璧山', t2.count_num)) 璧山,
MAX(decode(t2.name, '長壽', t2.count_num)) 長壽,
MAX(decode(t2.name, '武隆', t2.count_num)) 武隆,
MAX(decode(t2.name, '豐都', t2.count_num)) 豐都,
MAX(decode(t2.name, '楊家坪', t2.count_num)) 楊家坪
FROM (SELECT t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END AS grade,
COUNT(t.v_num) count_num
FROM test_lhr1 t
GROUP BY t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END) t2
GROUP BY t2.grade;
-
建立臨時表
基本的行轉列可以透過建立臨時表來實現,首先將基礎表根據條件建立幾個臨時表,然後將這些臨時表關聯起來就可以了。
SELECT t1.id,
t1.cv C1,
t2.cv C2,
t3.cv C3
FROM (SELECT * FROM t_row_col t WHERE t.cn = 'c1') t1,
(SELECT * FROM t_row_col t WHERE t.cn = 'c2') t2,
(SELECT * FROM t_row_col t WHERE t.cn = 'c3') t3
WHERE t1.id = t2.id
AND t2.id = t3.id;
-
PL/SQL --存過
適用範圍:8i,9i,10g 及以後版本
這種對於行值不固定的情況可以使用。
下面是我寫的一個包,包中
p_rows_column_real 用於前述的第一種不限定列的轉換;
p_rows_column 用於前述的第二種不限定列的轉換。
CREATE OR REPLACE PACKAGE pkg_dynamic_rows_column AS
TYPE refc IS REF CURSOR;
PROCEDURE p_print_sql(p_txt VARCHAR2);
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
END;
/
CREATE OR REPLACE PACKAGE BODY pkg_dynamic_rows_column AS
PROCEDURE p_print_sql(p_txt VARCHAR2) IS
v_len INT;
BEGIN
v_len := length(p_txt);
FOR i IN 1 .. v_len / 250 + 1 LOOP
dbms_output.put_line(substrb(p_txt, (i - 1) * 250 + 1, 250));
END LOOP;
END;
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2 IS
v_first INT;
v_last INT;
BEGIN
IF p_seq < 1 THEN
RETURN NULL;
END IF;
IF p_seq = 1 THEN
IF instr(p_str, p_division, 1, p_seq) = 0 THEN
RETURN p_str;
ELSE
RETURN substr(p_str, 1, instr(p_str, p_division, 1) - 1);
END IF;
ELSE
v_first := instr(p_str, p_division, 1, p_seq - 1);
v_last := instr(p_str, p_division, 1, p_seq);
IF (v_last = 0) THEN
IF (v_first > 0) THEN
RETURN substr(p_str, v_first + 1);
ELSE
RETURN NULL;
END IF;
ELSE
RETURN substr(p_str, v_first + 1, v_last - v_first - 1);
END IF;
END IF;
END f_split_str;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_pivot_cnt INT;
v_max_cols INT;
v_partition VARCHAR2(4000);
v_partition1 VARCHAR2(4000);
v_partition2 VARCHAR2(4000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ','))
+ 1;
v_pivot_cnt := length(p_pivot_cols) -
length(REPLACE(p_pivot_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
FOR j IN 1 .. v_pivot_cnt LOOP
v_pivot(j) := f_split_str(p_pivot_cols, ',', j);
END LOOP;
v_sql := 'select max(count(*)) from ' || p_table || ' group by ';
FOR i IN 1 .. v_keep.LAST LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
EXECUTE IMMEDIATE v_sql
INTO v_max_cols;
v_partition := 'select ';
FOR x IN 1 .. v_keep.COUNT LOOP
v_partition1 := v_partition1 || v_keep(x) || ',';
END LOOP;
FOR y IN 1 .. v_pivot.COUNT LOOP
v_partition2 := v_partition2 || v_pivot(y) || ',';
END LOOP;
v_partition1 := rtrim(v_partition1, ',');
v_partition2 := rtrim(v_partition2, ',');
v_partition := v_partition || v_partition1 || ',' || v_partition2 ||
', row_number() over (partition by ' || v_partition1 ||
' order by ' || v_partition2 || ') rn from ' || p_table;
v_partition := rtrim(v_partition, ',');
v_sql := 'select ';
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
FOR i IN 1 .. v_max_cols LOOP
FOR j IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(rn,' || i || ',' || v_pivot(j) ||
',null))' || v_pivot(j) || '_' || i || ',';
END LOOP;
END LOOP;
IF p_where IS NOT NULL THEN
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition || ' ' ||
p_where || ') group by ';
ELSE
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition ||
') group by ';
END IF;
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_group_by VARCHAR2(2000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) +
1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
v_sql := 'select ' || 'cast(' || p_pivot_col ||
' as varchar2(200)) as ' || p_pivot_col || ' from ' || p_table ||
' group by ' || p_pivot_col;
EXECUTE IMMEDIATE v_sql BULK COLLECT
INTO v_pivot;
FOR i IN 1 .. v_keep.COUNT LOOP
v_group_by := v_group_by || v_keep(i) || ',';
END LOOP;
v_group_by := rtrim(v_group_by, ',');
v_sql := 'select ' || v_group_by || ',';
FOR x IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(' || p_pivot_col || ',' || chr(39) ||
v_pivot(x) || chr(39) || ',' || p_pivot_val ||
',null)) as "' || v_pivot(x) || '",';
END LOOP;
v_sql := rtrim(v_sql, ',');
IF p_where IS NOT NULL THEN
v_sql := v_sql || ' from ' || p_table || p_where || ' group by ' ||
v_group_by;
ELSE
v_sql := v_sql || ' from ' || p_table || ' group by ' || v_group_by;
END IF;
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
END;
/
-
多列轉換成字串
CREATE TABLE t_col_str AS
SELECT * FROM t_col_row;
這個比較簡單,用|| 或concat 函式可以實現:
SELECT concat('a','b') FROM dual;
-
|| OR CONCAT
適用範圍:8i,9i,10g 及以後版本
SELECT * FROM t_col_str;
SELECT ID,
c1 || ',' || c2 || ',' || c3 AS c123
FROM t_col_str;
-
多行轉換成字串
CREATE TABLE t_row_str(
ID INT,
col VARCHAR2(10)
);
INSERT INTO t_row_str VALUES(1,'a');
INSERT INTO t_row_str VALUES(1,'b');
INSERT INTO t_row_str VALUES(1,'c');
INSERT INTO t_row_str VALUES(2,'a');
INSERT INTO t_row_str VALUES(2,'d');
INSERT INTO t_row_str VALUES(2,'e');
INSERT INTO t_row_str VALUES(3,'c');
COMMIT;
SELECT * FROM t_row_str;

-
MAX + DECODE
適用範圍:8i,9i,10g 及以後版本
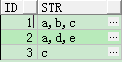
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
-
ROW_NUMBER + LEAD
適用範圍:8i,9i,10g 及以後版本
SELECT id,
str
FROM (SELECT id,
row_number() over(PARTITION BY id ORDER BY col) AS rn,
col || lead(',' || col, 1) over(PARTITION BY id ORDER BY col) || lead(',' || col, 2) over(PARTITION BY id ORDER BY col) || lead(',' || col, 3) over(PARTITION BY id ORDER BY col) AS str
FROM t_row_str)
WHERE rn = 1
ORDER BY 1;

-
MODEL
適用範圍:10g 及以後版本
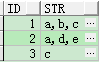
SELECT id, substr(str, 2) str FROM t_row_str
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY(row_number() over(PARTITION BY ID ORDER BY col) AS rn)
MEASURES (CAST(col AS VARCHAR2(20)) AS str)
RULES UPSERT
ITERATE(3) UNTIL( presentv(str[iteration_number+2],1,0)=0)
(str[0] = str[0] || ',' || str[iteration_number+1])
ORDER BY 1;
-
SYS_CONNECT_BY_PATH --主要方法
適用範圍:8i,9i,10g 及以後版本
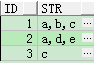
SELECT t.id id,
MAX(substr(sys_connect_by_path(t.col, ','), 2)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) rn
FROM t_row_str) t
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1
AND id = PRIOR id
GROUP BY t.id;
適用範圍:10g 及以後版本
SELECT t.id id,
substr(sys_connect_by_path(t.col, ','), 2) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) rn
FROM t_row_str) t
WHERE connect_by_isleaf = 1
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1
AND id = PRIOR id;
-
WMSYS.WM_CONCAT(col) +dbms_lob.substr(clobcloum,2000,1) --主要方法
適用範圍:10g 及以後版本
這個函式預定義按',' 分隔字串,若要用其他符號分隔可以用,replace 將',' 替換。
或者: to_char(wmsys.wm_concat(dic.COLUMN_NAME))
SELECT id,
REPLACE(wmsys.wm_concat(col), ',', '/') str
FROM t_row_str
GROUP BY id;
將clob轉換為字串型別為:
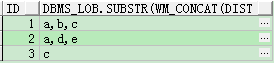
SELECT id,
dbms_lob.substr(wm_concat(DISTINCT col), 2000, 1)
FROM t_row_str t
GROUP BY t.id;
我們透過 10g 所提供的 WMSYS.WM_CONCAT 函式即可以完成 行轉列的效果 select t.rank, WMSYS.WM_CONCAT(t.Name) TIME From t_menu_item t GROUP BY t.rank;DEPTNO ENAME------ ---------- 10 CLARK, KING, MILLER 20 ADAMS, FORD, JONES, SCOTT, SMITH 30 ALLEN, BLAKE, JAMES, MARTIN, TURNER, WARD
例子如下:
SQL> create table idtable (id number,name varchar2(30));
Table created
SQL> insert into idtable values(10,'ab');
1 row inserted
SQL> insert into idtable values(10,'bc');
1 row inserted
SQL> insert into idtable values(10,'cd');
1 row inserted
SQL> insert into idtable values(20,'hi');
1 row inserted
SQL> insert into idtable values(20,'ij');
1 row insertedSQL> insert into idtable values(20,'mn');
1 row inserted
SQL> select * from idtable;
ID NAME---------- ------------------------------ 10 ab 10 bc 10 cd 20 hi 20 ij 20 mn
6 rows selectedSQL> select id,wmsys.wm_concat(name) name from idtable2 group by id;
ID NAME---------- -------------------------------------------------------------------------------- 10 ab,bc,cd 20 hi,ij,mn
SQL> select id,wmsys.wm_concat(name) over (order by id) name from idtable;
ID NAME---------- -------------------------------------------------------------------------------- 10 ab,bc,cd 10 ab,bc,cd 10 ab,bc,cd 20 ab,bc,cd,hi,ij,mn 20 ab,bc,cd,hi,ij,mn 20 ab,bc,cd,hi,ij,mn
6 rows selected
SQL> select id,wmsys.wm_concat(name) over (order by id,name) name from idtable;
ID NAME---------- -------------------------------------------------------------------------------- 10 ab 10 ab,bc 10 ab,bc,cd 20 ab,bc,cd,hi 20 ab,bc,cd,hi,ij 20 ab,bc,cd,hi,ij,mn
6 rows selected
個人覺得這個用法比較有趣.
SQL> select id,wmsys.wm_concat(name) over (partition by id) name from idtable;
ID NAME---------- -------------------------------------------------------------------------------- 10 ab,bc,cd 10 ab,bc,cd 10 ab,bc,cd 20 hi,ij,mn 20 hi,ij,mn 20 hi,ij,mn
6 rows selected
SQL> select id,wmsys.wm_concat(name) over (partition by id,name) name from idtable;
ID NAME---------- -------------------------------------------------------------------------------- 10 ab 10 bc 10 cd 20 hi 20 ij 20 mn
6 rows selected
-
注意
以下均不報錯:
Create Table aa nologging As
SELECT id,
to_char(wm_concat(DISTINCT col)) colss
FROM t_row_str t
GROUP BY t.id;
insert into aa
SELECT id,
to_char(wm_concat(DISTINCT col)) colss
FROM t_row_str t
GROUP BY t.id;
但是以上語句放在存過中報錯,編譯不能透過:
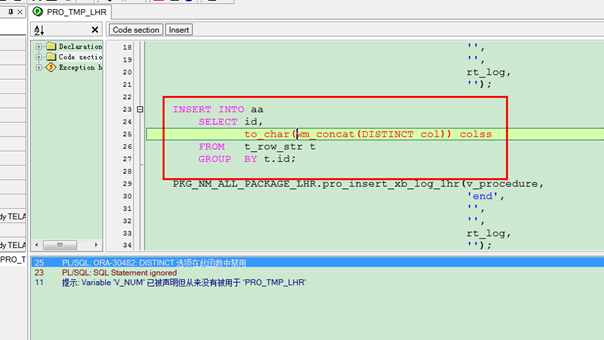
解決辦法:
-
透過動態sql語句執行
execute immediate 'INSERT INTO aa
SELECT id,
to_char(wm_concat(DISTINCT col)) colss
FROM t_row_str t
GROUP BY t.id';
-
-
SELECT id,
to_char(wm_concat(col)) colss
FROM (SELECT DISTINCT a.id,
a.col
FROM t_row_str a) t
GROUP BY t.id;
-
透過分析函式實現行轉列
對資料庫中的資料用SQL實現行列轉換,不但需要編寫複雜的程式程式碼,還需要編寫儲存過程。若引入ORACLE中的分析函式則會使該過程簡便很多。首先找出表中所有關鍵字的屬性個數的最大值,設為n,其次為每個關鍵字新新增n列,並用分析函式查詢關鍵字的屬性所處列的位置,然後將每個關鍵字的多行屬性轉換成多列屬性,最後把生成的多個新列拼成一個串形成一列,從而實現行列轉換。
-
引言
分析函式的設計目的是為了解決諸如"累計計算"等問題。雖然大部分的問題都可以用PL/SQL解決,但是效能並不理想,首先查詢本身並不容易編寫,其次有些很難在SQL中直接做的查詢但實際上是很普通的操作,比如實現資料表中行列傳換。這樣的問題在SQL中做查詢就很困難。在分析函式出現以前,我們必須使用自聯查詢或者子查詢甚至複雜的儲存過程實現的語句,現在只要一條簡單的SQL語句就可以實現了,而且在執行效率方面也有相當大的提高。本文將以一個例項來描述如何採用分析函式實現資料中的行列互換。
-
原理
2.1 分析函式的格式及語法
分析函式是在一個記錄行分組的基礎上計算它們的總值。行的分組被稱視窗,並透過分析語句定義。對於每記錄行,定義了一個"滑動"視窗。該視窗確定"當前行"計算的範圍。視窗的大小可由各行的實際編號或由時間等邏輯間隔確定。
分析函式以如下形式開頭:
Analytic-Function(,,...)
OVER ()
(1)Analytic-Function:分析函式的名稱,Oracle10gR2帶的內建分析函式有多個,包括:AVG、CORR、COVAR_POP、COVAR_SAMP、COUNT、LAG、LAST、LEAD、MAX、MIN、RANK、SUM等;對於使用者自定義的分析函式,分析函式名稱需要滿足識別符號規則。
(2)Arguments:引數,分析函式通常有0到3個引數,引數可以是任何數字型別或是可以隱式轉換為數字型別的資料型別。對於使用者自定義的引數,可以根據實際情況使用。
(3)OVER:是分析函式就必須使用的關鍵字,對於既可作為聚集函式又可作為分析函式的函式,Oracle無法識別,必須用over來標識此函式為分析函式。
(4)Query-Partition-Clause:查詢分組子句,根據劃分表示式設定的規則,PARTITION BY將一個結果邏輯分成N個分組劃分表示式。分析函式獨立應用於各個分組,並在應用時重置。
(5)Order-By-Clause:(按…排序分組),是排序子句,根據一個或多個排序表示式對分組進行排序。
(6)Windowing-Clause視窗生成語句:視窗生成語句用以定義滑動或固定資料視窗,分析函式在分組內進行分析。該語句能夠對分組中任意定義的滑動或固定視窗進行計算。
2.2 例項原理介紹
本例項是將具有相同關鍵字的多條記錄中的某一不同列合併成一列,例如在一個臨時表中包含有使用者的編號、電話號碼、產品名稱、所在營業區以及相關業務名稱5個欄位,而每個使用者的業務可能有多項,這樣建立資料表將會造成冗餘,現在要想辦法將表中編號、電話號碼、產品名稱、所在營業區四個欄位相同的使用者的相關業務屬性合併成一列解決冗餘問題,使用SQL語句會比較困難,甚至需要一定的儲存過程。使用Orcale中的分析函式來實現這樣的行列轉換就比較簡單方便了。
-
例項
1)建立臨時表
Drop Table temp;
Create Table temp
(
num varchar2(15),name varchar2(20),
sex varchar2(2),
classes varchar2(30),
course_name varchar2(50)
);
-----------------------------------------------------------------------------------
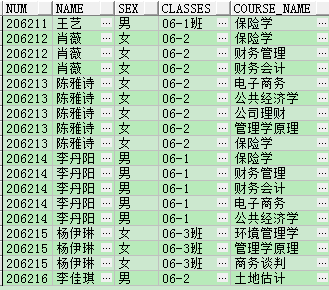
2)構造資料
insert into temp(num,name,sex,classes,course_name) values ('206211','王藝','男','06-1班','保險學');
insert into temp(num,name,sex,classes,course_name) values ('206212','肖薇','女','06-2','保險學');
insert into temp(num,name,sex,classes,course_name) values ('206212','肖薇','女','06-2','財務管理');
insert into temp(num,name,sex,classes,course_name) values ('206212','肖薇','女','06-2','財務會計');
insert into temp(num,name,sex,classes,course_name) values ('206213','陳雅詩','女','06-2','電子商務');
insert into temp(num,name,sex,classes,course_name) values ('206213','陳雅詩','女','06-2','公共經濟學');
insert into temp(num,name,sex,classes,course_name) values ('206213','陳雅詩','女','06-2','公司理財');
insert into temp(num,name,sex,classes,course_name) values ('206213','陳雅詩','女','06-2','管理學原理');
insert into temp(num,name,sex,classes,course_name) values ('206213','陳雅詩','女','06-2','保險學');
insert into temp(num,name,sex,classes,course_name) values ('206214','李丹陽','男','06-1','保險學');
insert into temp(num,name,sex,classes,course_name) values ('206214','李丹陽','男','06-1','財務管理');
insert into temp(num,name,sex,classes,course_name) values ('206214','李丹陽','男','06-1','財務會計');
insert into temp(num,name,sex,classes,course_name) values ('206214','李丹陽','男','06-1','電子商務');
insert into temp(num,name,sex,classes,course_name) values ('206214','李丹陽','男','06-1','公共經濟學');
insert into temp(num,name,sex,classes,course_name) values ('206215','楊伊琳','女','06-3班','環境管理學');
insert into temp(num,name,sex,classes,course_name) values ('206215','楊伊琳','女','06-3班','管理學原理');
insert into temp(num,name,sex,classes,course_name) values ('206215','楊伊琳','女','06-3班','商務談判');
insert into temp(num,name,sex,classes,course_name) values ('206216','李佳琪','男','06-2','土地估計');
Commit;
select * from temp;
-----------------------------------------------------------------------------------
3)先查一下course_name最多的組合
select max(count(course_name))
from temp
group by num,name,sex,classes;

-----------------------------------------------------------------------------------
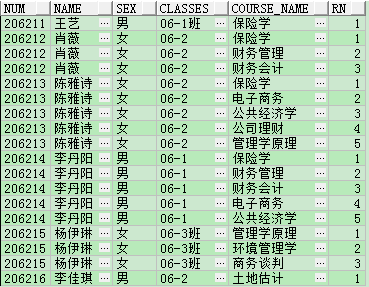
4) 列的位置
用分析函式中的row_number函式,在num,name,sex,classes相同的情況下course_name所處的列的位置(第幾列)。
row_number函式解釋:返回有序組中一行的偏移量,從而可用於按特定標準排序的行號。
SELECT num,
NAME,
sex,
classes,
course_name,
row_number() over(PARTITION BY num, NAME, sex, classes ORDER BY course_name) rn from temp;
-----------------------------------------------------------------------------------
5) 把course_name的所有的行換成列
SELECT num,
NAME,
sex,
classes,
MAX(decode(rn, 1, course_name, NULL)) course_name_1,
MAX(decode(rn, 2, course_name, NULL)) course_name_2,
MAX(decode(rn, 3, course_name, NULL)) course_name_3,
MAX(decode(rn, 4, course_name, NULL)) course_name_4,
MAX(decode(rn, 5, course_name, NULL)) course_name_5
FROM (SELECT num,
NAME,
sex,
classes,
course_name,
row_number() over(PARTITION BY num, NAME, sex, classes ORDER BY course_name) rn
FROM temp)
GROUP BY num,
NAME,
sex,
classes;

6)把轉換後的name拼成一個字串,放在一行
SELECT num,
NAME,
sex,
classes,
(MAX(decode(rn, 1, course_name, NULL)) ||
MAX(decode(rn, 2, ',' || course_name, NULL)) ||
MAX(decode(rn, 3, ',' || course_name, NULL)) ||
MAX(decode(rn, 4, ',' || course_name, NULL)) ||
MAX(decode(rn, 5, ',' || course_name, NULL))) NAME
FROM (SELECT num,
NAME,
sex,
classes,
course_name,
row_number() over(PARTITION BY num, NAME, sex, classes ORDER BY course_name) rn
FROM temp)
GROUP BY num,
NAME,
sex,
classes;

-
總結
本文中的程式能夠實現以下功能:①計算具有相同關鍵字的最多的組合;②根據分析函式查詢某一關鍵字所處的列的位置;③把需合併列的所有的行換成列;④把需要合併的某幾列拼成一個串。
分析函式除了擁有以上所介紹的功能,還能夠實現諸如求和、Top-N查詢、統計某個範圍的資料行視窗、交叉表查詢等功能。
-
例題
CREATE TABLE tab_name(ID INTEGER NOT NULL PRIMARY KEY,cName VARCHAR2(20));
CREATE TABLE tab_name2(ID INTEGER NOT NULL,pName VARCHAR2(20));
INSERT INTO tab_name(ID,cName) VALUES (1,'百度');
INSERT INTO tab_name(ID,cName) VALUES (2,'Google');
INSERT INTO tab_name(ID,cName) VALUES (3,'網易');
INSERT INTO tab_name2(ID,pName) VALUES (1,'研發部');
INSERT INTO tab_name2(ID,pName) VALUES (1,'市場部');
INSERT INTO tab_name2(ID,pName) VALUES (2,'研發部');
INSERT INTO tab_name2(ID,pName) VALUES (2,'平臺架構');
INSERT INTO tab_name2(ID,pName) VALUES (3,'研發部');
COMMIT;
select * from tab_name;

select * from tab_name2;
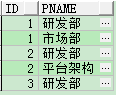
方法一:使用wmsys.wm_concat()
SELECT t1.ID,
t1.cName,
wmsys.wm_concat(t2.pName)
FROM tab_name t1,
tab_name2 t2
WHERE t1.ID = t2.ID
GROUP BY t1.cName,
t1.id;
方法二:使用sys_connect_by_path
SELECT id,
cName,
ltrim(MAX(sys_connect_by_path(pName, ',')), ',')
FROM (SELECT row_number() over(PARTITION BY t1.id ORDER BY cName) r,
t1.*,
t2.pName
FROM tab_name t1,
tab_name2 t2
WHERE t1.id = t2.id)
START WITH r = 1
CONNECT BY PRIOR r = r - 1
AND PRIOR id = id
GROUP BY id,
cName
ORDER BY id;
方法三:使用自定義函式
CREATE OR REPLACE FUNCTION coltorow(midId INT) RETURN VARCHAR2 IS
RESULT VARCHAR2(1000);
BEGIN
FOR cur IN (SELECT pName FROM tab_name2 t2 WHERE midId = t2.id) LOOP
RESULT := RESULT || cur.pName || ',';
END LOOP;
RESULT := rtrim(RESULT, ',');
RETURN(RESULT);
END coltorow;
SELECT t1.*,
coltorow(t1.ID)
FROM tab_name t1,
tab_name2 t2
WHERE t1.ID = t2.ID
GROUP BY t1.ID,
t1.cname
ORDER BY t1.ID;

-
字串轉換成多列
其實際上就是一個字串拆分的問題。
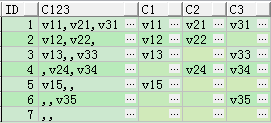
CREATE TABLE t_str_col AS
SELECT ID,c1||','||c2||','||c3 AS c123
FROM t_col_str;
SELECT * FROM t_str_col;

-
SUBSTR + INSTR
-
將單列分為多列
-
適用範圍:8i,9i,10g 及以後版本
SELECT id,
c123,
substr(c123, 1, instr(c123 || ',', ',', 1, 1) - 1) c1,
substr(c123,
instr(c123 || ',', ',', 1, 1) + 1,
instr(c123 || ',', ',', 1, 2) - instr(c123 || ',', ',', 1, 1) - 1) c2,
substr(c123,
instr(c123 || ',', ',', 1, 2) + 1,
instr(c123 || ',', ',', 1, 3) - instr(c123 || ',', ',', 1, 2) - 1) c3
FROM t_str_col
ORDER BY 1;
-
存過
將單列分為多列見以下存過

-
藉助excel辦公軟體
首先將需要轉換的字串列匯出到一個txt檔案或其它檔案中,然後新建一個excel檔案,開啟這個excel檔案後,在資料選項卡里選擇匯入資料,見截圖:

金山WPS

微軟辦公軟體
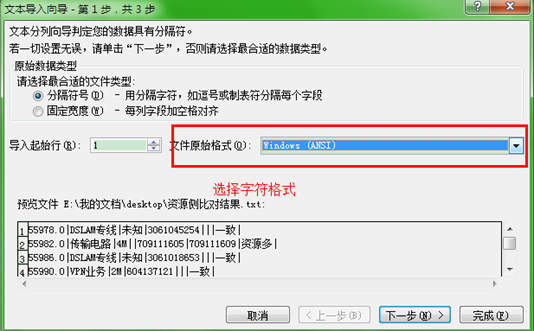
選擇字元格式
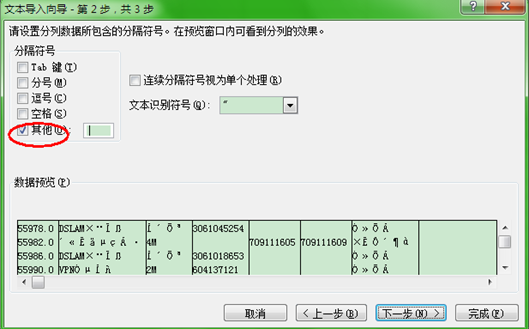
選擇分隔符號
最後確定就OK了,最後把excel裡轉換後的資料透過複製貼上的方式匯入到資料庫裡就可以了。
-
採用sqlldr
採用sqlldr的方式匯入到資料庫中。
-
將多列分為多列
CREATE TABLE t_str_col2 AS
SELECT ID,c1||','||c2||','||c3 AS c123,c3||','||c2 as c32
FROM t_col_str;
select * from t_str_col2;

SELECT id,
c123,
substr(c123, 1, instr(c123 || ',', ',', 1, 1) - 1) c1,
substr(c123,
instr(c123 || ',', ',', 1, 1) + 1,
instr(c123 || ',', ',', 1, 2) - instr(c123 || ',', ',', 1, 1) - 1) c2,
substr(c123,
instr(c123 || ',', ',', 1, 2) + 1,
instr(c123 || ',', ',', 1, 3) - instr(c123 || ',', ',', 1, 2) - 1) c3,
c32,
substr(c32, 1, instr(c32, ',') - 1) cc3,
substr(c32, instr(c32, ',') + 1) cc2
FROM t_str_col2
ORDER BY 1;

-
REGEXP_SUBSTR
適用範圍:10g 及以後版本
SELECT id,
c123,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 1), ',') AS c1,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 2), ',') AS c2,
rtrim(regexp_substr(c123 || ',', '.*?' || ',', 1, 3), ',') AS c3
FROM t_str_col
ORDER BY 1;
-
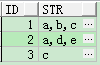
字串轉換成多行
CREATE TABLE t_str_row AS
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
FROM (SELECT id,
col,
row_number() over(PARTITION BY id ORDER BY col) AS rn
FROM t_row_str) t
GROUP BY id
ORDER BY 1;
SELECT * FROM t_str_row;
-
UNION ALL
適用範圍:8i,9i,10g 及以後版本
SELECT id,
1 AS p,
substr(str, 1, instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
2 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
UNION ALL
SELECT id,
3 AS p,
substr(str,
instr(str || ',', ',', 1, 1) + 1,
instr(str || ',', ',', 1, 2) - instr(str || ',', ',', 1, 1) - 1) AS cv
FROM t_str_row
ORDER BY 1,
2;
適用範圍:10g 及以後版本
SELECT id,
1 AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, 1), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id,
2 AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, 2), ',') AS cv
FROM t_str_row
UNION ALL
SELECT id,
3 AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, 3), ',') AS cv
FROM t_str_row
ORDER BY 1,
2;
-
VARRAY
適用範圍:8i,9i,10g 及以後版本
要建立一個可變陣列:
CREATE OR REPLACE TYPE ins_seq_type IS VARRAY(8) OF NUMBER;
SELECT * FROM TABLE(ins_seq_type(1, 2, 3, 4, 5));
SELECT t.id,
c.column_value AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.column_value) + 1,
instr(t.ca, ',', 1, c.column_value + 1) -
(instr(t.ca, ',', 1, c.column_value) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t
INNER JOIN TABLE(ins_seq_type(1, 2, 3)) c ON c.column_value <=
t.cnt
ORDER BY 1, 2;
-
SEQUENCE SERIES
這類方法主要是要產生一個連續的整數列,產生連續整數列的方法有很多,主要有:
CONNECT BY,ROWNUM+all_objects,CUBE 等。
適用範圍:8i,9i,10g 及以後版本
SELECT t.id,
c.lv AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.lv) + 1,
instr(t.ca, ',', 1, c.lv + 1) -
(instr(t.ca, ',', 1, c.lv) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 5) c
WHERE c.lv <= t.cnt
ORDER BY 1,
2;
SELECT t.id,
c.rn AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.rn) + 1,
instr(t.ca, ',', 1, c.rn + 1) -
(instr(t.ca, ',', 1, c.rn) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT rownum rn FROM all_objects WHERE rownum <= 5) c
WHERE c.rn <= t.cnt
ORDER BY 1,
2;
SELECT t.id,
c.cb AS p,
substr(t.ca,
instr(t.ca, ',', 1, c.cb) + 1,
instr(t.ca, ',', 1, c.cb + 1) -
(instr(t.ca, ',', 1, c.cb) + 1)) AS cv
FROM (SELECT id,
',' || str || ',' AS ca,
length(str || ',') - nvl(length(REPLACE(str, ',')), 0) AS cnt
FROM t_str_row) t,
(SELECT rownum cb FROM (SELECT 1 FROM dual GROUP BY CUBE(1, 2))) c
WHERE c.cb <= t.cnt
ORDER BY 1,
2;
適用範圍:10g 及以後版本
SELECT t.id,
c.lv AS p,
rtrim(regexp_substr(t.str || ',', '.*?' || ',', 1, c.lv), ',') AS cv
FROM (SELECT id,
str,
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL)) AS cnt
FROM t_str_row) t
INNER JOIN (SELECT LEVEL lv FROM dual CONNECT BY LEVEL <= 5) c
ON c.lv <= t.cnt
ORDER BY 1,
2;
drop table t_test
create table t_test (id number, names varchar2(200));
insert into t_test values (1,'a1,a2,a3,a4');
insert into t_test values (2,'b1,b2,b3');
insert into t_test values (3,'c1,c2,c3,c4,c5');
commit;
select * from t_test;

常規做法:
SELECT id,
REGEXP_SUBSTR(names, '[^,]+', 1, l) AS NAME
FROM t_test,
(SELECT LEVEL l FROM DUAL CONNECT BY LEVEL <= 100)
WHERE l <= LENGTH(names) - LENGTH(REPLACE(names, ',')) + 1
ORDER BY 1,
2;
SELECT DISTINCT REGEXP_SUBSTR(PARAM_VALUES, '[^,]+', 1, LEVEL) AS SOC_NAME FROM CM9_BATCH_CONTROLWHERE PARAM_NAME = 'OFFER' AND JOB_NAME = 'xxxxxxx' AND JOB_REC = 'ENDDAY'CONNECT BY REGEXP_SUBSTR((SELECT PARAM_VALUES FROM CM9_BATCH_CONTROL WHERE JOB_NAME = 'xxxxx' AND PARAM_NAME = 'OFFER'), '[^,]+', 1, LEVEL) IS NOT NULL;
SELECT CO.SOC_CD FROM (SELECT REGEXP_SUBSTR(PARAM_VALUES,'[^,]+',1,l) AS SOC_NAME FROM CM9_BATCH_CONTROL ,(SELECT LEVEL l FROM DUAL CONNECT BY LEVEL<=100)WHERE PARAM_NAME = 'OFFER' AND JOB_NAME = 'xxxx' AND JOB_REC = 'ENDDAY' AND l <=LENGTH(PARAM_VALUES) - LENGTH(REPLACE(PARAM_VALUES,','))+1)T, CSM_OFFER CO WHERE T.SOC_NAME = CO.SOC_NAMEand T.SOC_NAME is not null
-
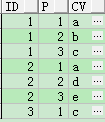
HIERARCHICAL + DBMS_RANDOM
適用範圍:10g 及以後版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = PRIOR id
AND PRIOR dbms_random.VALUE IS NOT NULL
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1,
2;
-
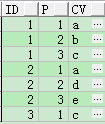
HIERARCHICAL + CONNECT_BY_ROOT
適用範圍:10g 及以後版本
SELECT id,
LEVEL AS p,
rtrim(regexp_substr(str || ',', '.*?' || ',', 1, LEVEL), ',') AS cv
FROM t_str_row
CONNECT BY id = connect_by_root
id
AND LEVEL <=
length(regexp_replace(str || ',', '[^' || ',' || ']', NULL))
ORDER BY 1,
2;
-
MODEL
適用範圍:10g 及以後版本
SELECT id, p, cv FROM t_str_row
MODEL
RETURN UPDATED ROWS
PARTITION BY(ID)
DIMENSION BY( 0 AS p)
MEASURES( str||',' AS cv)
RULES UPSERT
(cv
[ FOR p
FROM 1 TO length(regexp_replace(cv[0],'[^'||','||']',null))
INCREMENT 1
] = rtrim(regexp_substr( cv[0],'.*?'||',',1,cv(p)),','))
ORDER BY 1,2 ;

-
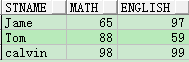
例題
drop table course;
create table course (stname varchar(10), math int, english int);
insert into course values('Jame', 65, 97);
insert into course values('Tom',88,59);
insert into course values('calvin',98,99);
select * from course;
create table pivot (id int);
insert into pivot values (1);
insert into pivot values (2);
select * from pivot;
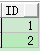
select * from course;
select * from pivot;
SELECT stname,
CASE id
WHEN 1 THEN
'Math'
WHEN 2 THEN
'English'
ELSE
'0'
END AS subject,
CASE id WHEN 1 THEN math WHEN 2 THEN english ELSE 0end AS grade
FROM course,
pivot;
About Me
...............................................................................................................................
● 本文作者:小麥苗,只專注於資料庫的技術,更注重技術的運用
● 本文在itpub(http://blog.itpub.net/26736162)、部落格園(http://www.cnblogs.com/lhrbest)和個人微信公眾號(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/viewspace-1272538/
● 本文部落格園地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麥苗雲盤地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 資料庫筆試面試題庫及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 聯絡我請加QQ好友(646634621),註明新增緣由
● 於 2017-07-01 09:00 ~ 2017-07-31 22:00 在魔都完成
● 文章內容來源於小麥苗的學習筆記,部分整理自網路,若有侵權或不當之處還請諒解
● 版權所有,歡迎分享本文,轉載請保留出處
...............................................................................................................................
拿起手機使用微信客戶端掃描下邊的左邊圖片來關注小麥苗的微信公眾號:xiaomaimiaolhr,掃描右邊的二維碼加入小麥苗的QQ群,學習最實用的資料庫技術。




來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/26736162/viewspace-1272538/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- oracle 行列互換總結Oracle
- Oracle 行列轉換總結Oracle
- Oracle行列轉換總結Oracle
- Oracle 行列轉換小結Oracle
- 行列轉換問題總結
- Oracle-行列轉換Oracle
- 報表如何實現行列互換效果?
- [轉]decode函式和行列互換函式
- Oracle 行列轉換 經典Oracle
- sqlserver 行列互轉實現小結SQLServer
- 實現二維陣列的行列互換陣列
- oracle行列轉換-多行轉換成字串Oracle字串
- oracle行列轉換-行轉列Oracle
- oracle行列轉換-列轉行Oracle
- oracle和mysql的行列轉換OracleMySql
- 在Word中實現表格的行列互換 (轉)
- oracle行列轉換-字串轉換成多列Oracle字串
- oracle行列轉換-多列轉換成字串Oracle字串
- pivot、unpivot實現oracle行列轉換Oracle
- Oracle--SQL行列轉換實戰OracleSQL
- web 展現資料時如何實現行列互換Web
- 行列轉換
- Oracle行列轉換及pivot子句的用法Oracle
- oracle 11g 使用 pivot/unpivot 行列轉換Oracle
- 用ORACLE分析函式實現行列轉換Oracle函式
- Kettle行列轉換
- 偽行列轉換!
- 行列轉換sqlSQL
- 使用IEWebBrowser元件進行列印的總結Web元件
- Oracle11新特性——行列轉換語句(二)Oracle
- Oracle11新特性——行列轉換語句(一)Oracle
- Oracle多行轉換成字串方法總結Oracle字串
- MySQL行列轉換拼接MySql
- 行列轉換之大全~~~
- sql server 行列轉換SQLServer
- 試驗Oracle中實現行列轉換的方法(轉)Oracle
- mysql行列轉換詳解MySql
- sql server行列轉換案例SQLServer