文字是傳遞資訊最常用的載體。在當前這個資訊爆炸的時代,人們接收資訊的速度已經小於資訊產生的速度,尤其是文字資訊。當大段大段的文字擺在面前,已經很少有耐心去認真把它讀完,經常是先找文中的圖片來看。這一方面說明人們對圖形的接受程度比枯燥的文字要高很多,另一方面說明人們急需一種更高效的資訊接收方式,文字視覺化正是解藥良方。「一圖勝千言」我們從小就有體會,教材裡的解釋圖、自己筆記裡總結的知識結構圖,一直到現在經常用的思維導圖等,其實都是簡單、實用的文字視覺化。本文將簡單介紹文字視覺化的基礎概念,然後重點通過各類文字視覺化的案例來闡述視覺化之美(多圖,不過為了學到知識這點流量不算什麼)。
為什麼要文字資料視覺化
雖然一般這種講必要性的段落很多人都略過不看,雖然文字視覺化的必要性大家用腳趾頭估計都能想到,但我還是稍微說一說吧。文字視覺化的作用有以下四點:
- 理解 – 理解主旨
- 組織 – 組織、分類資訊
- 比較 – 對比文件資訊
- 關聯 – 關聯文字的 pattern 和其他資訊
簡單來說就是讓你更加直觀迅速的獲取、分析資訊(所有視覺化的作用都是這個)。舉個例子,針對一篇文章,文字視覺化能更快的告訴我們文章在講什麼;針對社交網路上的發言,文字視覺化可以幫我們資訊歸類,情感分析;針對一個大新聞,文字視覺化可以幫我們捋順事情發展的脈絡、每個人物的關係等等;針對一系列的文件,我們可以通過文字視覺化來找到它們之間的聯絡等等。
一般來說,情報分析人員、網路內容分析人員、情感分析或文學研究者等相關職業更需要文字視覺化。不過隨著資訊圖(例如圖 1)等的普及,越來越多的人已經接受並善用文字視覺化了。
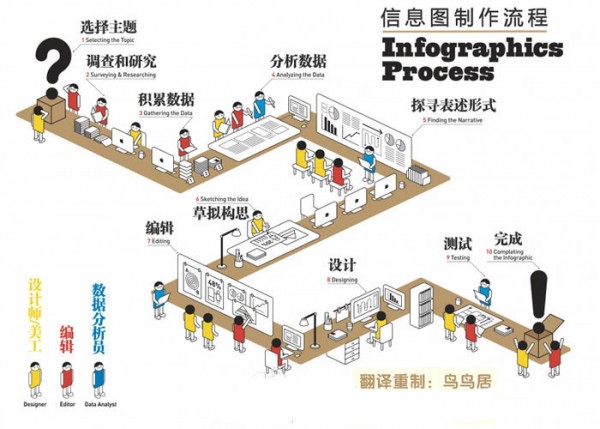
文字資料視覺化的流程
如圖 2 所示,其實任何視覺化的流程[1]都類似。
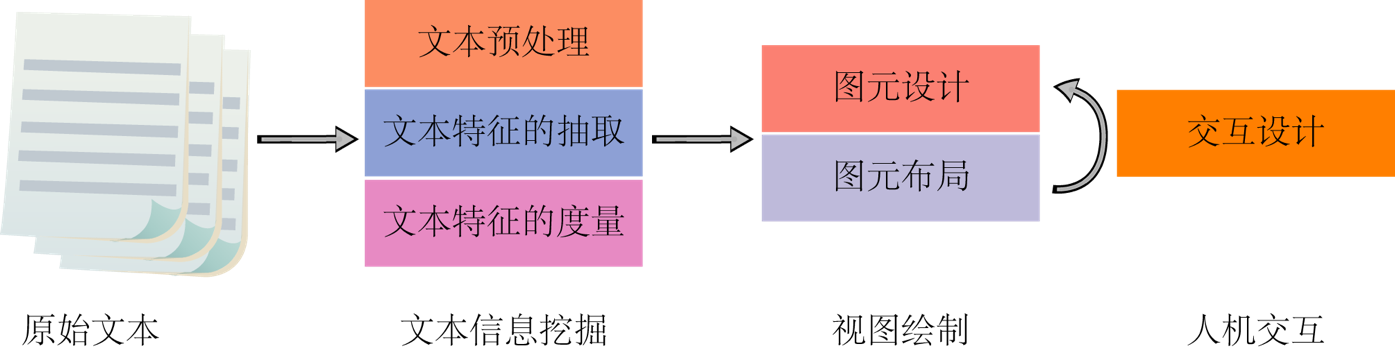
一般把對文字的理解需求分成三級:詞彙級(Lexical Level)、語法級(Syntactic Level)和語義級(Semantic Level)。不同級的資訊挖掘方法也不同,詞彙級當然是用各類分詞演算法,語法級用一些句法分析演算法,語義級用主題抽取演算法[2]。以上這些都在第二步文字資訊挖掘中進行,其中文字資料預處理是將無效資料過濾,提取有效詞等;文字特徵抽取是指提取文字的關鍵詞、詞頻分佈、語法級的實體資訊、語義級的主題等;文字特徵的度量是指在多種環境或多個資料來源所抽取的文字特徵進行深層分析,如相似性、文字聚類等。這裡就簡單籠統地說一下文字分析的基礎方法,有興趣的同學可以自行搜尋學習,我們把重點放在視覺化設計上。
![Wordcount[3] 統計了通常用的86800個單詞](https://ooo.0o0.ooo/2017/06/04/5933efa249cfe.png)
文字視覺化型別
文字資料大致可分為三種:單文字、文件集合和時序文字資料。對應的文字視覺化也可分為三類:
- 文字內容的視覺化
- 文字關係的視覺化
- 文字多層面資訊的視覺化
以下我們通過案例來一一介紹。
文字內容視覺化
上篇文章所說的標籤雲和 Wordle [4]是目前研究領域和 Web 上最受歡迎的文字內容視覺化方法了,它們都是基於關鍵詞的文字內容視覺化。
基於關鍵詞的文字內容視覺化
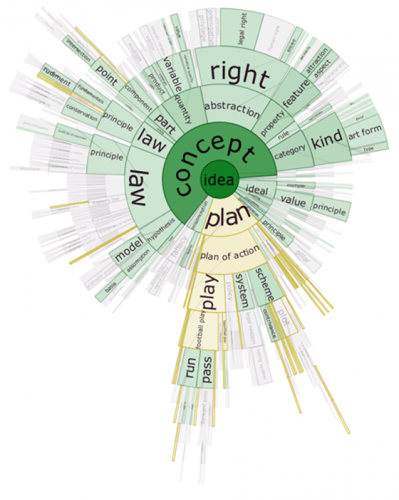
DocuBurst
文件散(DocuBurst [5])也是基於關鍵詞的文字視覺化,不過它還通過徑向佈局體現了詞的語義等級。如下圖所示,外層的詞是內層詞的下義祠,顏色飽和度的深淺用來體現詞頻的高低。
Document Cards
文件卡片(Document Cards)[6]則是結合了文件中的關鍵詞和關鍵圖片進行視覺化,佈局在一張小卡片中。其中的關鍵圖片是指採用智慧演算法抽取並根據顏色分類後的代表性圖片。

時序文字內容視覺化
時序資料是指具有時間或順序特性的文字,例如一篇小說故事情節的變化,或一個新聞事件隨時間的演化。
SparkClouds
SparkClouds[7]是在標籤雲的基礎上,在每個詞下面增加了一條折線圖,用以顯示該詞的詞頻隨時間的演變。

ThemeRiver
主題河流(ThemeRiver)[8]是一種經典的時序文字視覺化方法。光陰似水,用河流來隱喻時間的變化幾乎所有人都能非常好地理解。
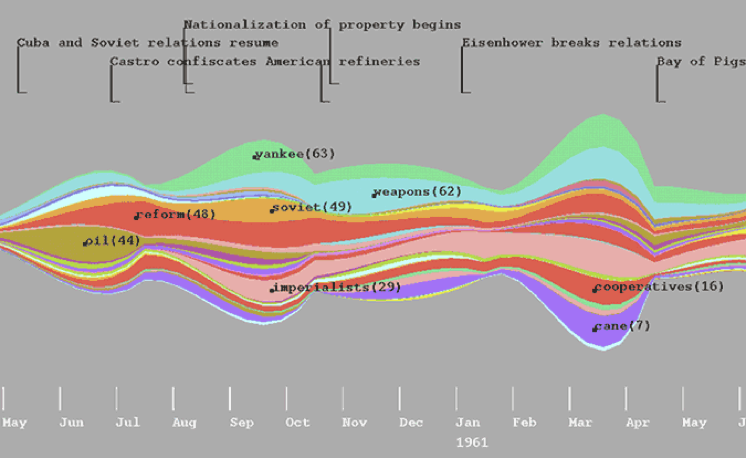
橫軸表示時間,每一條不同顏色線條可視作一條河流,而每條河流則表示一個主題,河流的寬度代表其在當前時間點上的一個度量(如主題的強度)。這樣既可以在巨集觀上看出多個主題的發展變化,又能看出在特定時間點上主題的分佈。
TIARA
TIARA[9]結合了標籤雲,通過主題分析技術(latent dirichlet allocation,LDA),將文字關鍵詞根據時間點放置在每條色帶上,並用詞的大小來表示關鍵詞在該時刻出現的頻率。因此用TIARA就可以幫助使用者快速分析文字具體內容隨時間變化的規律,而不是僅僅一個度量帶變化。
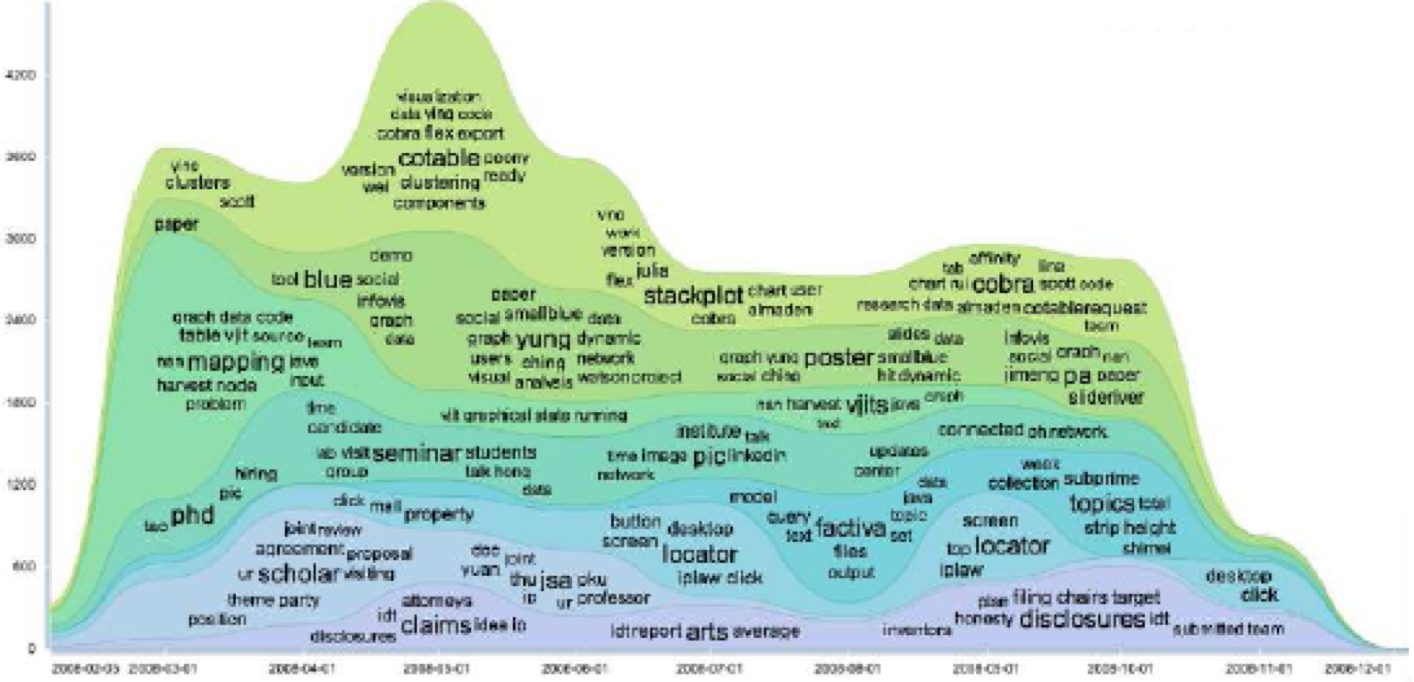
TextFlow
TextFlow [10]也算是 ThemeRiver 的一種擴充,它不僅表達了主題的變化,還表達了各個主題隨著時間的分裂與合併。如某個主題在某個時間分成了兩個主題,或多個主題在某個時間合併成了一個主題。

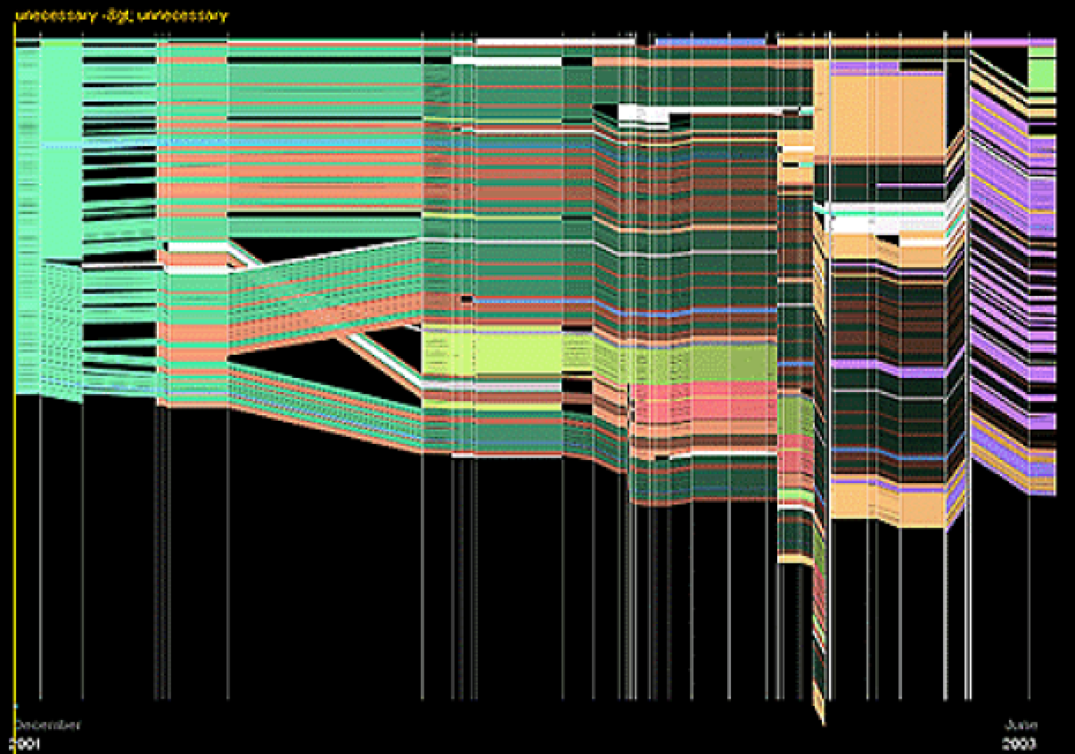
HistoryFlow
HistoryFlow [11]則主要研究文件內容隨時間的變化。下圖以維基百科一篇詞條的更新為例,縱軸表示文章的版本更新時間點,每一種顏色代表一個作者,在同一個時間軸上色塊代表相應的作者所貢獻的文字塊,並且色塊的位置代表該文字塊在文章中的順序。所以縱覽全圖就可以輕易看出文章的修改。
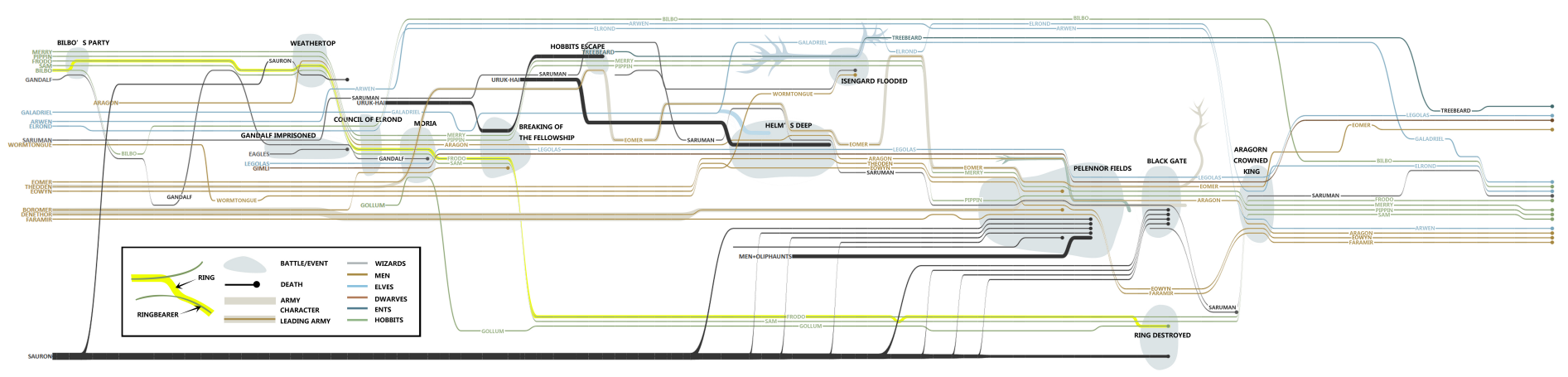
StoryFlow
我們看電影或小說經常說到時間線、劇情線等,都能用 StoryFlow [12]來表示,它通過層次渲染的方式,生成一個 StoryLine 佈局。每條線是一條人物線,當兩人在劇情中有某種聯絡(同時出場或其他交集)時會在圖中相交,橫軸表示時間。
StoryFlow 還允許使用者實時互動,包括捆綁操作、刪除、移動以及直線化等等。視訊演示非常精彩,需科學上網:https://www.youtube.com/watch?v=yoq82mC30Iw
文字特徵分佈模式視覺化
視覺化也能很好的表現文字特徵。
TextArc
TextArc [13]用來視覺化一個文件中的詞頻和詞的分佈情況。整個文件用一條螺線表示,文件的句子按文字的組織順序佈局在螺線上,螺線包圍著的是文件中出現的單詞,每個單詞的位置由其在文字中的頻率和出現位置決定,飽和度用來對映詞頻。所以全域性出現頻率越高的詞越靠近中心,而區域性出現頻率越高的詞越靠近其相應的螺線區域。選中某個單詞後,自動用射線關聯到它在文中出現的位置。

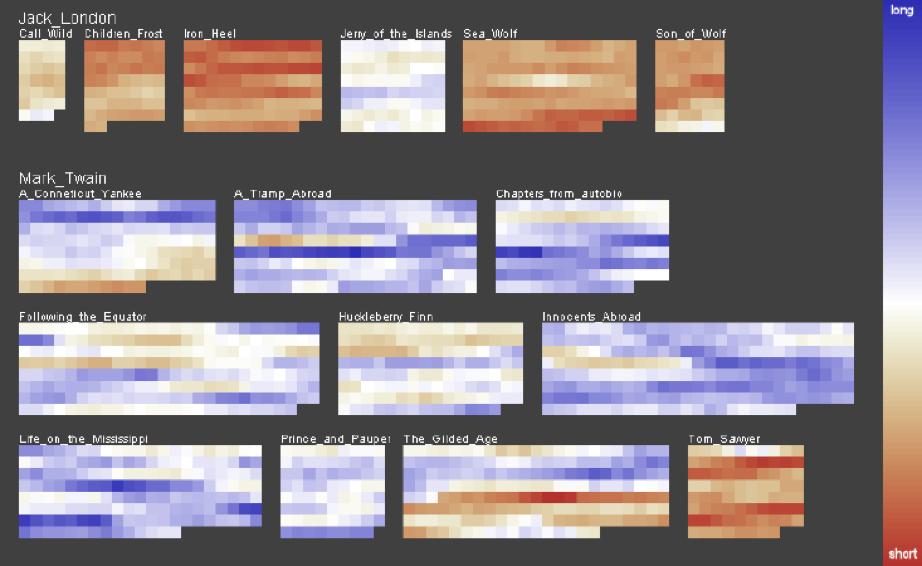
Literature Fingerprinting
文獻指紋(Literature Fingerprinting)[14]是體現全文特徵分佈的一項工作。一個畫素塊代表一段文字,一組畫素塊代表一本書。顏色對映的是文字特徵,下圖中是句子的平均長度。從圖中明顯看出兩人的寫作風格迥異。
情感分析視覺化
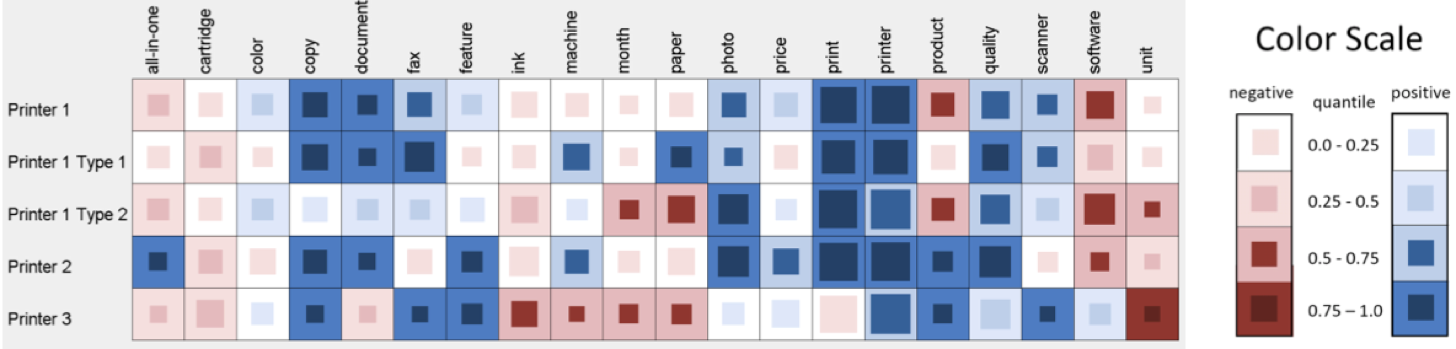
情感分析是指從文字中挖掘出心情、喜好、感覺等主觀資訊。現在人們把各類社交網路當作感情、觀點的出口,所以分析這類文字就能掌握人們對於一個事件的觀點或情感的發展。下圖是基於矩陣檢視的客戶反饋資訊的視覺化工作[15],其中的行是指文字(使用者觀點)的載體,列是使用者的評價,顏色表達的是使用者評價的傾向程度,紅色代表消極,藍色代表積極,每個方格內的小格子代表使用者評價的人數,評價人數越多小格子越大。
文字關係視覺化
顧名思義,文字關係視覺化研究的是文字或文件集合中的關係資訊,比如文字的相似性、互相引用的情況、連結等。說到關係佈局,一般都是樹或圖。
文字內容關係視覺化
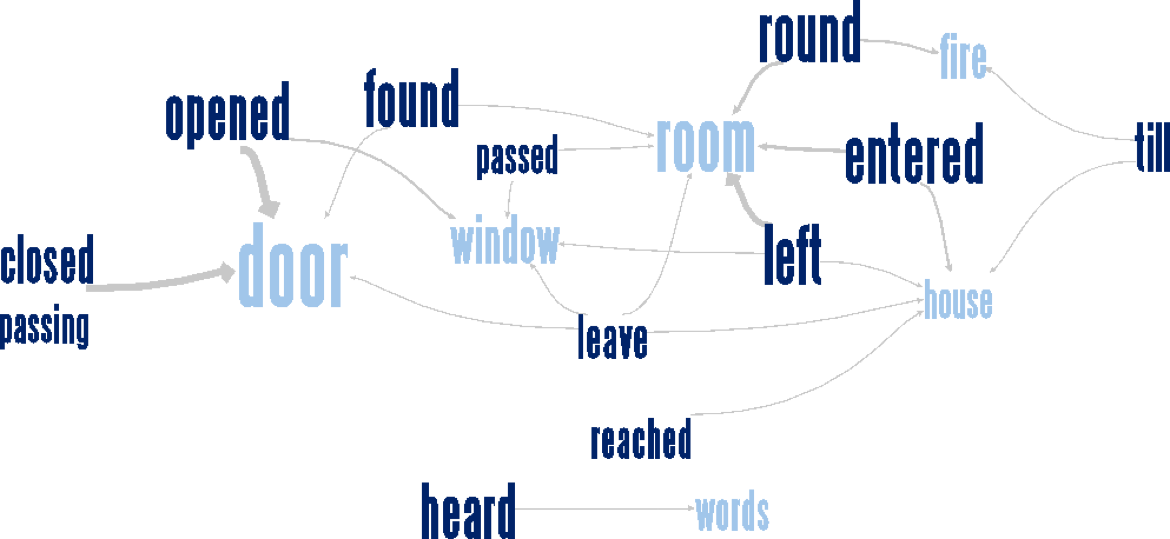
Word Tree
單詞樹(Word Tree)[16]很好理解,把文字中的句子按樹形結構佈局,可以很好的看出一個單詞在文字中出現的頻率和單詞前後的聯絡。

Phrase Nets
短語網路(Phrase Nets)[17]是經典的力導向圖結構,圖中的節點是從文字中挖掘出的詞彙級或語法級的語義單元,邊代表語義單元的聯絡,邊的方向即短語的方向,邊的寬度是短語在文字中出現的頻率。
NewsMap
TreeMap 也是一種經典的視覺化關係佈局。NewsMap 就是基於 TreeMap 展示新聞,顏色用於區分新聞型別。

文件集合關係視覺化
文件數量到一定量的時候,再針對文字做視覺化就不現實了,所以通常是對單個文件定義一個特徵向量,利用向量空間模型計算文件間的相似性,並採用相應的投影技術呈現文件集合的關係。
Galaxy View
星系圖(Galaxy View)[18]把一篇文件比作一顆星星,通過投影的方法把所有文件按照其主題的相似性投影為二維平面的點集,星星離的越近則代表文件越相似,因此一個星團可以非常直觀地看出文件主題的緊湊和離散。

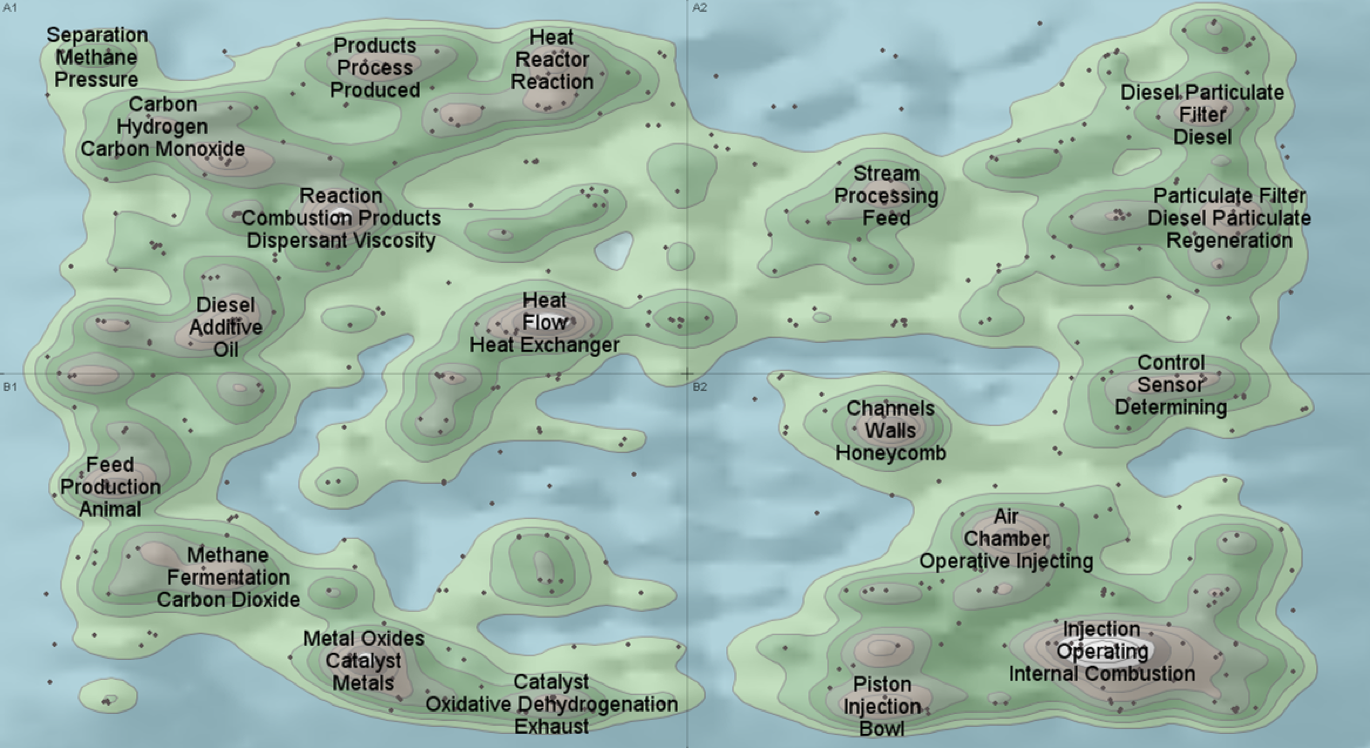
ThemeScape
主題地貌(ThemeScape)[18]是對星系圖的改進。地圖中的等高線我相信大家都理解,把等高線加入投影的二維平面中,文件相似性相同的放在一個等高線內,再用顏色來編碼文字分佈的密集程度,把二維平面背景變成一幅地圖,這樣就把剛才星系圖中的星團變成了一座座山丘。文件越相似,則分佈約密集,這座山峰就越高,是不是一目瞭然?
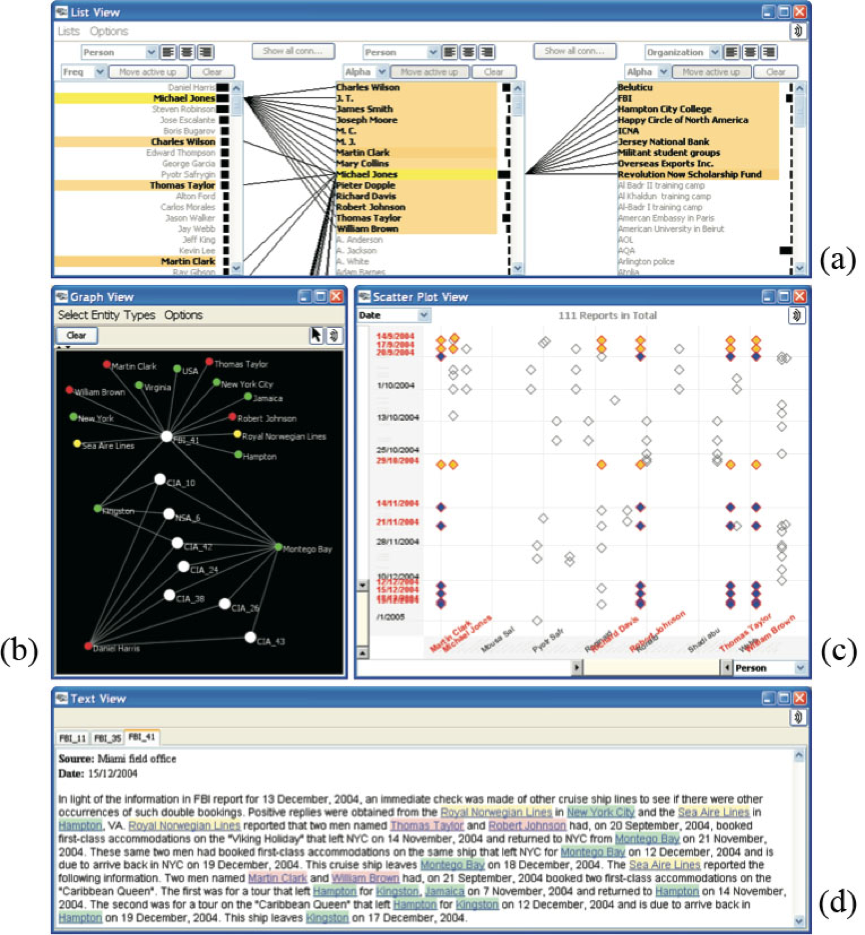
Jigsaw
Jigsaw [19]通過提供多種檢視讓使用者互動分析文件間的關係。最下面是文件檢視,裡面是單個文件的內容,最上面列表圖中每一行是文件中的一個實體,連線代表實體間的關係。中間部分,左面是一副節點-連結圖,白色節點表示一篇文件,其他節點是文件中的實體,連結同樣代表聯絡;右面的散點圖中,一個菱形代表兩個實體的聯絡。
文字多層面資訊視覺化
多層面或多維度是指從多個角度或提取多種特徵對文字集合分析。
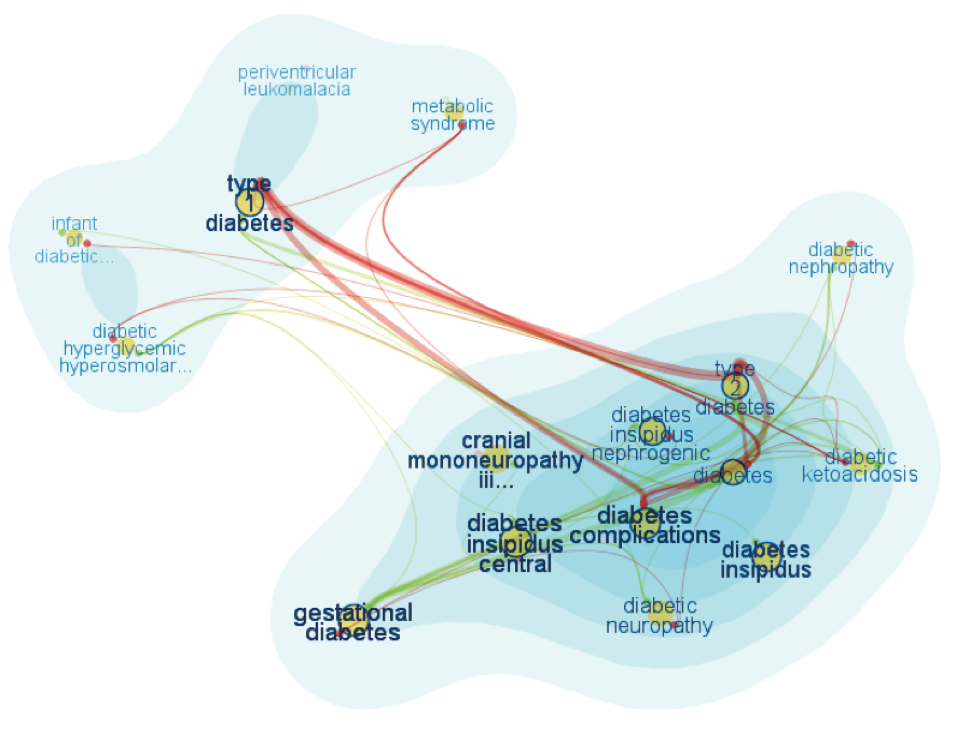
FaceAtlas
FaceAtlas [20]結合了氣泡集和節點-連結圖兩種檢視,用於表達文字各層面資訊內部和外部的關聯。每個節點表示一個實體,用 KDE 方法刻畫出氣泡圖的輪廓,然後用線將同一層面的實體連結起來,一種顏色代表一種實體。下圖是基於醫療健康文件,展示了病名、病因、症狀、診斷方案等多層面的資訊,兩團分別代表糖尿病1號和2號,連線是指他倆之間的併發症。
Parallel Tag Clouds
平行標籤雲(Parallel Tag Clouds)[21]結合了平行座標(該檢視在多維資料視覺化中經常使用)和標籤雲檢視。每一列是一個層面的標籤雲,然後連線的折線展現了選中標籤在多個層面的分佈。

總結
今天帶大家看了這麼多圖,相信大家一定眼花繚亂了。要理解文字資料視覺化,就要先了解文字資料的特點,如何從文字中挖掘出你想要的資訊,如何設計資料結構,最後再如何對映出實用又美觀的檢視都是你需要思考的問題。目前文字可視分析已經開始運用在各行各業,直觀的互動將人類的智慧引入到資料分析的過程中,幫助我們從浩瀚的文字中跳脫出來,避免一葉障目。希望我的文章能給大家帶來一些微小的幫助。
參考文獻
- [1] 資料視覺化基礎——視覺化流程
- [2] 陳為 沈則潛 陶煜波. 資料視覺化[M]. 電子工業出版社, 2013.
- [3] WordCount
- [4] 文字資料視覺化(上)——從 Wordle 談起
- [5] Collins C, Carpendale S, Penn G. Docuburst: Visualizing document content using language structure[C]//Computer graphics forum. Blackwell Publishing Ltd, 2009, 28(3): 1039-1046.
- [6] Strobelt H, Oelke D, Rohrdantz C, et al. Document cards: A top trumps visualization for documents[J]. IEEE Transactions on Visualization and Computer Graphics, 2009, 15(6): 1145-1152.
- [7] Lee B, Riche N H, Karlson A K, et al. Sparkclouds: Visualizing trends in tag clouds[J]. IEEE transactions on visualization and computer graphics, 2010, 16(6): 1182-1189.
- [8] Havre S, Hetzler E, Whitney P, et al. Themeriver: Visualizing thematic changes in large document collections[J]. IEEE transactions on visualization and computer graphics, 2002, 8(1): 9-20.
- [9] Wei F, Liu S, Song Y, et al. Tiara: a visual exploratory text analytic system[C]//Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2010: 153-162.
- [10] Cui W, Liu S, Tan L, et al. Textflow: Towards better understanding of evolving topics in text[J]. IEEE transactions on visualization and computer graphics, 2011, 17(12): 2412-2421.
- [11] Wattenberg M, Viégas F B. Historyflow: visualizing dynamic, evolving documents and the interactions of multiple collaborating authors, A preliminary report[J]. IBM Research, Collaborative User Experience research group, 2003.
- [12] Liu S, Wu Y, Wei E, et al. Storyflow: Tracking the evolution of stories[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(12): 2436-2445.
- [13] Paley W B. TextArc: Showing word frequency and distribution in text[C]//Poster presented at IEEE Symposium on Information Visualization. 2002, 2002.
- [14] Keim D A, Oelke D. Literature fingerprinting: A new method for visual literary analysis[C]//Visual Analytics Science and Technology, 2007. VAST 2007. IEEE Symposium on. IEEE, 2007: 115-122.
- [15] Oelke D, Hao M, Rohrdantz C, et al. Visual opinion analysis of customer feedback data[C]//Visual Analytics Science and Technology, 2009. VAST 2009. IEEE Symposium on. IEEE, 2009: 187-194.
- [16] Wattenberg M, Viégas F B. The word tree, an interactive visual concordance[J]. IEEE transactions on visualization and computer graphics, 2008, 14(6).
- [17] Van Ham F, Wattenberg M, Viégas F B. Mapping text with phrase nets[J]. IEEE transactions on visualization and computer graphics, 2009, 15(6).
- [18] Wise J A. The ecological approach to text visualization[J]. Journal of the Association for Information Science and Technology, 1999, 50(13): 1224.
- [19] Stasko J, Görg C, Liu Z. Jigsaw: supporting investigative analysis through interactive visualization[J]. Information visualization, 2008, 7(2): 118-132.
- [20] Cao N, Sun J, Lin Y R, et al. Facetatlas: Multifaceted visualization for rich text corpora[J]. IEEE transactions on visualization and computer graphics, 2010, 16(6): 1172-1181.
- [21] Collins C, Viegas F B, Wattenberg M. Parallel tag clouds to explore and analyze faceted text corpora[C]//Visual Analytics Science and Technology, 2009. VAST 2009. IEEE Symposium on. IEEE, 2009: 91-98.
本作品採用知識共享 署名-非商業性使用-禁止演繹 4.0 國際 許可協議進行許可。