實戰:構建可伸縮Hadoop叢集的方法步驟
轉載
【IT168 技術】資料庫和檔案中儲存的資料量每天都在增長,因此我們需要構建能夠儲存大量資料(“大資料”),並且廉價、可維護、可伸縮的環境。傳統的關聯式資料庫(RDBMS)系統在當前的需求下成本過高並且不可伸縮,因此開發、使用能夠滿足需求的新技術正合時宜。
在這些方向中,雲端計算是其中一項領先的技術。雲端計算有許多不同的實現,我們選擇的是Hadoop,這是一個擁有Apache許可、基於Google Map Reduce的框架。
在本文中,我將嘗試說明如何構建一個可伸縮的Hadoop叢集,以儲存、索引、檢索和維護理論上無限容量的資料。
本文將逐步介紹這些部分的安裝和配置:
·網路體系結構
·作業系統
·硬體要求
·Hadoop軟體安裝/設定
網路架構
根據我們目前能夠拿到的文件,可以認為雲內的節點越在物理上接近,越能獲得更好的效能。根據經驗,網路延時越小,效能越好。
為了減少背景流量,我們為這個雲建立了一個虛擬專用網。另外,還為應用伺服器們建立了一個子網,作為訪問雲的入口點。
這個虛擬專用網的預計時延大約是1-2毫秒。這樣一來,物理臨近性就不再是一個問題,我們應該透過環境測試來驗證這一點。
建議的網路架構:
·專用TOR(Top of Rack)交換機
·使用專用核心交換刀片或
·確保應用“靠近”Hadoop
·考慮使用乙太網繫結
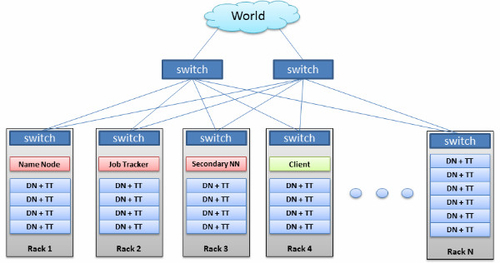
▲圖1 - Hadoop叢集的網路架構
我們選擇Linux作為作業系統。Linux有許多不同的發行版,包括Ubuntu、RedHat和CentOS等,無論選擇哪一個都可以。基於支援和許可費用的考慮,我們最終選擇了CentOS 5.7。最好是定製一個CentOS的映像,把那些需要的軟體都預裝進去,這樣所有的機器可以包含相同的軟體和工具,這是一個很好的做法。
根據Cloudera的建議,OS層應該採用以下設定:
·檔案系統
Ext3檔案系統
取消atime
不要使用邏輯卷管理
·利用alternatives來管理連結
·使用配置管理系統(Yum、Permission、sudoers等)
·減少核心交換
·撤銷一般使用者訪問這些雲端計算機的許可權
·不要使用虛擬化
·至少需要以下Linux命令:
ln、chmod、chown、chgrp、mount、umount、kill、rm、yum、mkdir
硬體要求
由於Hadoop叢集中只有兩種節點(Namenode/Jobtracker和Datanode/Tasktracker),因此叢集內的硬體配置不要超過兩種或三種。
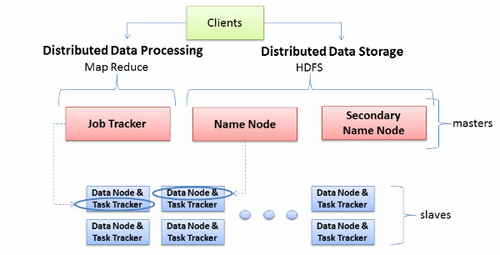
▲圖2 - Hadoop叢集伺服器角色
硬體建議:
·Namenode/Jobtracker:1Gb/s乙太網口x2、16GB記憶體、4個CPU、100GB磁碟
·Datanode:1Gb/s乙太網口x2、8GB、4個、多個磁碟,總容量500GB以上
實際的硬體配置可以與我們建議的配置不同,這取決於你們需要儲存和處理的資料量。但我們強烈建議不要在叢集中混用不同的硬體配置,以免那些較弱的機器成為系統的瓶頸。
Hadoop的機架感知
Hadoop有一個“機架感知”特性。管理員可以手工定義每個slave資料節點的機架號。為什麼要做這麼麻煩的事情?有兩個原因:防止資料丟失和提高網路效能。
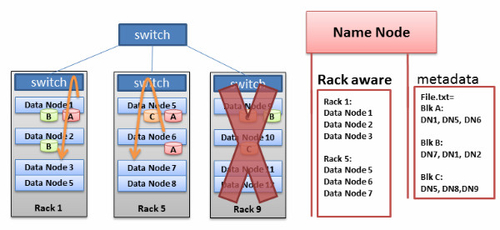
▲圖3 - Hadoop叢集的機架感知
為了防止資料丟失,Hadoop會將每個資料塊複製到多個機器上。想象一下,如果某個資料塊的所有複製都在同一個機架的不同機器上,而這個機架剛好發生故障了(交換機壞了,或者電源掉了),這得有多悲劇?為了防止出現這種情況,必須要有一個人來記住所有資料節點在網路中的位置,並且用這些知識來確定——把資料的所有複製們放在哪些節點上才是最明智的。這個“人”就是Name Node。
另外還有一個假設,即相比不同機架間的機器,同一個機架的機器之間有著更大的頻寬和更小的延時。這是因為,機架交換機的上行頻寬一般都小於下行頻寬。而且,機架內的延時一般也小於跨機架的延時(但也不絕對)。
機架感知的缺點則是,我們需要手工為每個資料節點設定機架號,還要不斷地更新這些資訊,保證它們是正確的。要是機架交換機們能夠自動向Namenode提供本機架的資料節點列表,那就太棒了。
Hadoop軟體的安裝和配置
Hadoop叢集有多種構建方式:
1.手工下載tar檔案並複製到叢集中
2.利用Yum倉庫
3.利用Puppet等自動化部署工具
我們不建議採用手工方式,那隻適合很小的叢集(4節點以下),而且會帶來很多維護和排障上的問題,因為所有的變更都需要用scp或ssh的方式手工應用到所有的節點上去。
從以下方面來看,利用Puppet等部署工具是最佳的選擇:
·安裝
·配置
·維護
·擴充套件性
·監控
·排障
Puppet是Unix/Linux下的一個自動化管理引擎,它能基於一個集中式的配置執行增加使用者、安裝軟體包、更新伺服器配置等管理任務。我們將主要講解如何利用Yum和Puppet來安裝Hadoop。
利用Yum/Puppet搭建Hadoop叢集
要利用Puppet搭建Hadoop叢集,首先要符合以下前置條件:
·包含所有必需Hadoop軟體的中央倉庫
·用於Hadoop部署的Puppet裝載單(manifest)
·用於Hadoop配置管理的Puppet裝載單
·用於叢集維護的框架(主要是sh或ksh指令碼),以支援叢集的start/stop/restart
·利用puppet構建整個伺服器(包括作業系統和其它軟體)
注:如果要用Yum來安裝Hadoop叢集,則所有伺服器應該預先構建完成,包括作業系統和其它軟體都應安裝完畢,yum倉庫也應在所有節點上設定完畢。
構建Datanode/Tasktracker
如果用Yum安裝Datanode/Tasktracker,需在所有資料節點上執行以下命令:
yum install hadoop-0.20-tasktracker –y
換成Puppet的話,則是:
if ($is_datanode == true) {
make_dfs_data_dir { $hadoop_disks: }
make_mapred_local_dir { $hadoop_disks: }
fix_hadoop_parent_dir_perm { $hadoop_disks: }
}
# fix hadoop parent dir permissions
define fix_hadoop_parent_dir_perm() {
…
}
# make dfs data dir
define make_dfs_data_dir() {
…
}
# make mapred local and system dir
define make_mapred_local_dir() {
…
}
} # setup_datanode
構建Namenode(及輔助Namenode)
如果用Yum安裝Namenode,需在所有資料節點上執行以下命令:
yum install hadoop-0.20-secondarynamenode –y
換成Puppet的話,則是:
if ($is_namenode == true or $is_standby_namenode == true) {
...
}
exec {"namenode-dfs-perm":
...
}
exec { "make ${nfs_namenode_dir}/dfs/name":
...
}
exec { "chgrp ${nfs_namenode_dir}/dfs/name":
...
}
if ($standby_namenode_host != "") {
...
}
exec { "own $nfs_standby_namenode_dir":
...
}
}
# /standby_namenode_hadoop
if ($standby_namenode_host != "") {
...
}
exec { "own $standby_namenode_hadoop_dir":
...
}
}
}
}
class setup_secondary_namenode {
if ($is_secondarynamenode == true) {
...
}
....
}
exec {"namenode-dfs-perm":
...
}
}
}
構建JobTracker
如果用Yum安裝Jobtracker,需在所有資料節點上執行以下命令:
換成Puppet的話,則是使用與構建Namenode相同的裝載單,唯一的區別在於,在Jobtracker機器上,會啟動Jobtracker——即將該機器上的is_jobtracker設定為true。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/196700/viewspace-752532/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Redis 叢集伸縮原理Redis
- redis自學(37)叢集伸縮Redis
- 構建高效且可伸縮的結果快取快取
- Ubuntu上搭建Hadoop叢集環境的步驟UbuntuHadoop
- 完全分散式Hadoop叢集的安裝部署步驟分散式Hadoop
- 基於 HBase 構建可伸縮的分散式事務佇列分散式佇列
- Dubbo 3.0 前瞻系列:服務發現支援百萬叢集,帶來可伸縮微服務架構微服務架構
- 高可用可伸縮架構實用經驗談架構
- EMQX Operator 如何快速建立彈性伸縮的 MQTT 叢集MQQT
- 資料倉儲構建實施方法及步驟
- 可伸縮NoSQL資料庫的五條建議SQL資料庫
- Hadoop自由實現伸縮節點詳細說明-Hadoop商業環境實戰Hadoop
- centos7 hadoop3.2.0分散式叢集搭建步驟CentOSHadoop分散式
- redis 叢集構建Redis
- Node.js的可伸縮性Node.js
- 大型網站的可伸縮性架構如何設計?網站架構
- windows NLB+ARR實現Web負載均衡高可用/可伸縮的方法WindowsWeb負載
- Java微服務開發指南–使用Docker和Kubernetes構建可伸縮的微服務Java微服務Docker
- K8s 從懵圈到熟練-叢集伸縮原理K8S
- greenplum 6.9 for centos7叢集搭建步驟CentOS
- 構建MHA實現MySQL高可用叢集架構MySql架構
- 實戰mariadb-galera叢集架構架構
- 節點加入k8s 叢集的步驟K8S
- KubeSphere 最佳實戰:K8s 構建高可用、高效能 Redis 叢集實戰指南K8SRedis
- 可伸縮聚類演算法綜述(可伸縮聚類演算法開篇)聚類演算法
- 可伸縮性和重/輕量,誰是實用系統的架構主選?架構
- Redis 超詳細的手動搭建Cluster叢集步驟Redis
- DKHhadoop叢集新增節點管理功能的操作步驟Hadoop
- 修改RAC叢集私網地址和子網掩碼的實施步驟
- 基於 Raft 構建彈性伸縮的儲存系統的一些實踐Raft
- hadoop叢集篇--從0到1搭建hadoop叢集Hadoop
- Docker Swarm + Harbor + Portainer 打造高可用,高伸縮,叢集自動化部署,更新。DockerSwarmAI
- Twitter如何使用Redis提高可伸縮性Redis
- 思路+步驟+方法,三步教你如何快速構建使用者畫像?
- Docker構建redis叢集環境DockerRedis
- Hadoop叢集搭建Hadoop
- Hadoop搭建叢集Hadoop
- Hadoop 叢集命令Hadoop