Linux 效能監測:IO
| 2013-08-16 09:50 收藏: 4
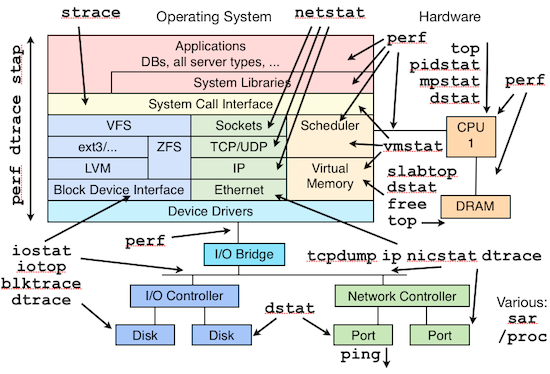
磁碟通常是計算機最慢的子系統,也是最容易出現效能瓶頸的地方,因為磁碟離 CPU 距離最遠而且 CPU 訪問磁碟要涉及到機械操作,比如轉軸、尋軌等。訪問硬碟和訪問記憶體之間的速度差別是以數量級來計算的,就像1天和1分鐘的差別一樣。要監測 IO 效能,有必要了解一下基本原理和 Linux 是如何處理硬碟和記憶體之間的 IO 的。
記憶體頁
上一篇 Linux 效能監測:Memory 提到了記憶體和硬碟之間的 IO 是以頁為單位來進行的,在 Linux 系統上1頁的大小為 4K。可以用以下命令檢視系統預設的頁面大小:
$ /usr/bin/time -v date ... Page size (bytes): 4096 ...
缺頁中斷
Linux 利用虛擬記憶體極大的擴充套件了程式地址空間,使得原來實體記憶體不能容下的程式也可以透過記憶體和硬碟之間的不斷交換(把暫時不用的記憶體頁交換到硬碟,把需要的記憶體頁從硬碟讀到記憶體)來贏得更多的記憶體,看起來就像實體記憶體被擴大了一樣。事實上這個過程對程式是完全透明的,程式完全不用理會自己哪一部分、什麼時候被交換進記憶體,一切都有核心的虛擬記憶體管理來完成。當程式啟動的時候,Linux 核心首先檢查 CPU 的快取和實體記憶體,如果資料已經在記憶體裡就忽略,如果資料不在記憶體裡就引起一個缺頁中斷(Page Fault),然後從硬碟讀取缺頁,並把缺頁快取到實體記憶體裡。缺頁中斷可分為主缺頁中斷(Major Page Fault)和次缺頁中斷(Minor Page Fault),要從磁碟讀取資料而產生的中斷是主缺頁中斷;資料已經被讀入記憶體並被快取起來,從記憶體快取區中而不是直接從硬碟中讀取資料而產生的中斷是次缺頁中斷。
上面的記憶體快取區起到了預讀硬碟的作用,核心先在實體記憶體裡尋找缺頁,沒有的話產生次缺頁中斷從記憶體快取裡找,如果還沒有發現的話就從硬碟讀取。很顯然,把多餘的記憶體拿出來做成記憶體快取區提高了訪問速度,這裡還有一個命中率的問題,運氣好的話如果每次缺頁都能從記憶體快取區讀取的話將會極大提高效能。要提高命中率的一個簡單方法就是增大記憶體快取區面積,快取區越大預存的頁面就越多,命中率也會越高。下面的 time 命令可以用來檢視某程式第一次啟動的時候產生了多少主缺頁中斷和次缺頁中斷:
$ /usr/bin/time -v date ... Major (requiring I/O) page faults: 1 Minor (reclaiming a frame) page faults: 260 ...
File Buffer Cache
從上面的記憶體快取區(也叫檔案快取區 File Buffer Cache)讀取頁比從硬碟讀取頁要快得多,所以 Linux 核心希望能儘可能產生次缺頁中斷(從檔案快取區讀),並且能儘可能避免主缺頁中斷(從硬碟讀),這樣隨著次缺頁中斷的增多,檔案快取區也逐步增大,直到系統只有少量可用實體記憶體的時候 Linux 才開始釋放一些不用的頁。我們執行 Linux 一段時間後會發現雖然系統上執行的程式不多,但是可用記憶體總是很少,這樣給大家造成了 Linux 對記憶體管理很低效的假象,事實上 Linux 把那些暫時不用的實體記憶體高效的利用起來做預存(記憶體快取區)呢。下面列印的是 VPSee 的一臺 Sun 伺服器上的實體記憶體和檔案快取區的情況:
$ cat /proc/meminfo MemTotal: 8182776 kB MemFree: 3053808 kB Buffers: 342704 kB Cached: 3972748 kB
這臺伺服器總共有 8GB 實體記憶體(MemTotal),3GB 左右可用記憶體(MemFree),343MB 左右用來做磁碟快取(Buffers),4GB 左右用來做檔案快取區(Cached),可見 Linux 真的用了很多實體記憶體做 Cache,而且這個快取區還可以不斷增長。
頁面型別
Linux 中記憶體頁面有三種型別:
- Read pages,只讀頁(或內碼表),那些透過主缺頁中斷從硬碟讀取的頁面,包括不能修改的靜態檔案、可執行檔案、庫檔案等。當核心需要它們的時候把它們讀到記憶體中,當記憶體不足的時候,核心就釋放它們到空閒列表,當程式再次需要它們的時候需要透過缺頁中斷再次讀到記憶體。
- Dirty pages,髒頁,指那些在記憶體中被修改過的資料頁,比如文字檔案等。這些檔案由 pdflush 負責同步到硬碟,記憶體不足的時候由 kswapd 和 pdflush 把資料寫回硬碟並釋放記憶體。
- Anonymous pages,匿名頁,那些屬於某個程式但是又和任何檔案無關聯,不能被同步到硬碟上,記憶體不足的時候由 kswapd 負責將它們寫到交換分割槽並釋放記憶體。
IO’s Per Second(IOPS)
每次磁碟 IO 請求都需要一定的時間,和訪問記憶體比起來這個等待時間簡直難以忍受。在一臺 2001 年的典型 1GHz PC 上,磁碟隨機訪問一個 word 需要 8,000,000 nanosec = 8 millisec,順序訪問一個 word 需要 200 nanosec;而從記憶體訪問一個 word 只需要 10 nanosec.(資料來自:Teach Yourself Programming in Ten Years)這個硬碟可以提供 125 次 IOPS(1000 ms / 8 ms)。
順序 IO 和 隨機 IO
IO 可分為順序 IO 和 隨機 IO 兩種,效能監測前需要弄清楚系統偏向順序 IO 的應用還是隨機 IO 應用。順序 IO 是指同時順序請求大量資料,比如資料庫執行大量的查詢、流媒體服務等,順序 IO 可以同時很快的移動大量資料。可以這樣來評估 IOPS 的效能,用每秒讀寫 IO 位元組數除以每秒讀寫 IOPS 數,rkB/s 除以 r/s,wkB/s 除以 w/s. 下面顯示的是連續2秒的 IO 情況,可見每次 IO 寫的資料是增加的(45060.00 / 99.00 = 455.15 KB per IO,54272.00 / 112.00 = 484.57 KB per IO)。相對隨機 IO 而言,順序 IO 更應該重視每次 IO 的吞吐能力(KB per IO):
$ iostat -kx 1
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 2.50 25.25 0.00 72.25
Device:rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 24.00 19995.00 29.00 99.00 4228.00 45060.00 770.12 45.01 539.65 7.80 99.80
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 1.00 30.67 0.00 68.33
Device:rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 3.00 12235.00 3.00 112.00 768.00 54272.00 957.22 144.85 576.44 8.70 100.10
隨機 IO 是指隨機請求資料,其 IO 速度不依賴於資料的大小和排列,依賴於磁碟的每秒能 IO 的次數,比如 Web 服務、Mail 服務等每次請求的資料都很小,隨機 IO 每秒同時會有更多的請求數產生,所以磁碟的每秒能 IO 多少次是關鍵。
$ iostat -kx 1
avg-cpu: %user %nice %system %iowait %steal %idle
1.75 0.00 0.75 0.25 0.00 97.26
Device:rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 52.00 0.00 57.00 0.00 436.00 15.30 0.03 0.54 0.23 1.30
avg-cpu: %user %nice %system %iowait %steal %idle
1.75 0.00 0.75 0.25 0.00 97.24
Device:rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
sdb 0.00 56.44 0.00 66.34 0.00 491.09 14.81 0.04 0.54 0.19 1.29
按照上面的公式得出:436.00 / 57.00 = 7.65 KB per IO,491.09 / 66.34 = 7.40 KB per IO. 與順序 IO 比較發現,隨機 IO 的 KB per IO 小到可以忽略不計,可見對於隨機 IO 而言重要的是每秒能 IOPS 的次數,而不是每次 IO 的吞吐能力(KB per IO)。
SWAP
當系統沒有足夠實體記憶體來應付所有請求的時候就會用到 swap 裝置,swap 裝置可以是一個檔案,也可以是一個磁碟分割槽。不過要小心的是,使用 swap 的代價非常大。如果系統沒有實體記憶體可用,就會頻繁 swapping,如果 swap 裝置和程式正要訪問的資料在同一個檔案系統上,那會碰到嚴重的 IO 問題,最終導致整個系統遲緩,甚至崩潰。swap 裝置和記憶體之間的 swapping 狀況是判斷 Linux 系統效能的重要參考,我們已經有很多工具可以用來監測 swap 和 swapping 情況,比如:top、cat /proc/meminfo、vmstat 等:
$ cat /proc/meminfo MemTotal: 8182776 kB MemFree: 2125476 kB Buffers: 347952 kB Cached: 4892024 kB SwapCached: 112 kB ... SwapTotal: 4096564 kB SwapFree: 4096424 kB ... $ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 2 260008 2188 144 6824 11824 2584 12664 2584 1347 1174 14 0 0 86 0 2 1 262140 2964 128 5852 24912 17304 24952 17304 4737 2341 86 10 0 0 4

相關文章
- 磁碟IO效能監控(Linux 和 Windows)LinuxWindows
- Linux iostat監測IO狀態LinuxiOS
- Linux-iostat監測IO狀態LinuxiOS
- Linux的IO效能監控工具iostat詳解LinuxiOS
- Linux效能監測皮膚 | NETDATALinux
- linux監測I/O效能-iostatLinuxiOS
- IOSTAT對linux硬碟IO效能進行檢測iOSLinux硬碟
- fio 命令 測試IO效能
- 如何監測 Linux 的磁碟 I/O 效能Linux
- Chrome 效能監測Chrome
- Windows IO 效能簡單測試Windows
- windows下測試IO效能的工具Windows
- Linux 效能優化之 IO 篇Linux優化
- zabbix監控linux磁碟io的模板Linux
- dbms_resource_manager.calibrate_io測試資料庫IO效能資料庫
- linux效能監控命令Linux
- Linux 效能監控工具Linux
- nagios監控linux磁碟io的bugiOSLinux
- Orion - oracle提供的測試io效能的工具Oracle
- 效能測試之Docker監控Docker
- PHP程式碼效能監測工具PHP
- Linux 監測命令Linux
- Linux 效能優化之 IO 子系統Linux優化
- [linux]系統效能監測工具詳解iostat,mpstat,sarLinuxiOS
- 【轉】Orion - oracle提供的測試io效能的工具Oracle
- 使用Bonnie進行系統IO效能測試 (zt)
- wait event監測效能瓶頸AI
- linux 監測命令(vmstat)Linux
- Linux程式管理與效能監控Linux
- linux效能監控利器20個Linux
- IO效能探索分析
- MySQL 5.6 innodb_io_capacity引數效能測試MySql
- iostat來對linux硬碟IO效能進行了解iOSLinux硬碟
- 效能測試之JVM的監控GrafanaJVMGrafana
- PHP 7.0 安裝使用與效能監測!PHP
- berserkJS —— 前端網路(效能)監測工具JS前端
- 效能測試-基於 Python 的 Linux 伺服器資源監控PythonLinux伺服器
- Linux 常用系統效能監控命令Linux