後設資料驅動設計 —— 設計一套用於API資料檢索的靈活引擎
如果你曾在企業開發方面具有一些經驗,那麼基本上可以斷言,你必定承擔過一些類似於搬運工的職責,將資料從你的資料庫中不斷地搬進搬出。此外,如果你在這方面有過過往的經驗,那麼你肯定也曾經做過將大量對共享檔案進行解析,並且載入到某個schema的表中的事。從純文字檔案到結構化的XML檔案,再到更為艱澀的檔案格式(例如ISO 2709),開發者與管理員在這些檔案之間不斷轉換,並從中獲取資料,這種狀態已經維持了數十年。
\\對於抽取資料檔案這種歷史悠久的做法,有人提倡也有人批評。批評者們認為,資料檔案不是來自於實時的資訊源,並且根據所選擇的資訊格式的不同,要正確地處理這些檔案可能需要經過大量的協調與策略。另一方面,提倡者分辯道,資料檔案的使用已經有幾十年的歷史了,而它的結果是產生了豐富的類庫與命令,即使是未經過訓練的初學者也能夠掌握它們的使用方法。
\\這些已經證實了它們實用性的工具讓資料檔案的解析與載入工作看起來只是舉手之勞,對於載入海量資料來說,這些工具通常也是最快的方式。那些資料檔案的支持者也會指出,雖然檔案並非實時的,但它們提供了資料快照的一個記錄集,可以將這些結果進行存檔,可用於今後審記員在檢查公司的行為是否合法時的有力證明。比方說,在美國法律中,塞班斯法案(Sarbannes-Oxley Act)規定公司必須保留最近至少五年以上1的相關資料。如果你當前的系統是根據這些需求規格處理檔案的,那麼你的資料流大概會像以下方式一樣:
\\(點選放大影像)
\
但是,雖然關於使用資料檔案的爭議還在繼續,但當今世界對於實時資訊的渴望卻一天比一天強烈,而通過API的方式進行資料檢索的這種實踐越來越多地開始滿足人們的這種渴望。在今後的許多年中,遺留程式與系統仍將從檔案中獲取資料,但這些系統最終很可能會因為干係人對實時資料的渴望而被取代。當然,為了讓這種轉變成功地實現,我們還需要新的系統與程式。此外,由於這種方式不會再將資料進行壓縮並歸檔至某個目標資料夾,因此我們必須建立一種自己的資料保留方案。
\\但一般來說,我們希望能夠使用一種與從檔案中獲取資料的解決方案類似的工作流:
\\(點選放大影像)
\
解決這一問題的方法有許多種,可以選擇一種臨時方案並快速地實現它。不過,如果你曾經閱讀過我之前所寫的文章2,你就知道我很喜歡使用一種更為系統化的方式處理這些問題。實際上,我們在這種情況下可以使用後設資料驅動設計以建立一種健壯的架構,它能夠承擔並執行這些我們所期望的職責。那麼,到底後設資料驅動設計是什麼呢?為了簡潔起見,可以將它簡單地歸結為一種軟體設計與實現的途徑,讓後設資料組成並整合這兩個開發階段。換句話說,在這種方式下,開發者能夠在整個軟體開發的生命週期3中採取敏捷式的迭代。通過使用由領域驅動設計所派生的後設資料,你可以進而進行下一步的後設資料驅動設計,並且建立出令人印象深刻的靈活架構。
\\正如Mike Amundsen所建議的一樣,API的建立應該貫穿整個設計4之中,在我們建立會呼叫這些API的系統時,也應該保持相同的心態。因此,為了讓具有高度複雜性的問題更易於解決,將這種難題分解為各個組成部分是一種良好的實踐(由於這種方式有助於使用簡潔的方案分別解決整體性問題中的每個部分,因此後設資料驅動設計天然的模組化特性對這種情況來說尤其合適)。舉例來說,由於API資料檢索方式通常會對某個請求所返回的資料的最大數量加以限制,因此我們需要設計一種自己的引擎,並且假設它會通過對該API的迴圈呼叫,在大量的資料集中進行列舉。但是,在我們開始處理這些小問題之前,我們需要提前預料到更高階別的問題,也就是在API資料檢索中存在著不同的風格。某些提供商在獲取本身資料時所採用的機制不夠強大,能夠參與查詢的引數數量有限,甚至完全沒有。使用者不得不在每次查詢中獲取完整的內容,並自行處理。某些使用者或許希望能夠用重複呼叫的方法獲取某個提供商的完整記錄,但有很多使用者(比如我自己)希望能夠獲取一部分資料子集,尤其是自最後一次資料獲取以來發生過變更的記錄(即增量記錄)。在更加直接的實現中,提供商或許只需要在URL查詢字串中加入一個引數,就可以獲得增量資料。但在更抽象的用例中,審計資訊與實際資料是通過兩種相互分享的API中獲取的。因此,審計API會被首先呼叫,在結果中提供了一份清單,其中詳細地說明了哪些記錄與欄位在某個日期之後產生了變更。隨後可以使用這份清單通過資料API獲取增量資料。在我們設計這套架構時,必須考慮到這種方案。
\\儘管我們可以對同時使用某個資料API與對應的審計API的方式進行一些調整,但我們要關注的是在通用的情況下如何系統地對API進行呼叫。在這兩種情況下,我們都需要考慮到某些因素:生成適當的URL、對格式(JSON、XML等等)進行解析,獲取特定屬性的值、過濾掉不需要的記錄等等。為了為這套架構建立一組合適的後設資料,最終的結果需要包括一套大範圍的數值,這些值能夠滿足每一個必要步驟的需求,無論是呼叫審計API或是資料API。為了展現這一點,以下分別顯示了一個增量清單以及對應的增量資料:
\\(點選放大影像)
\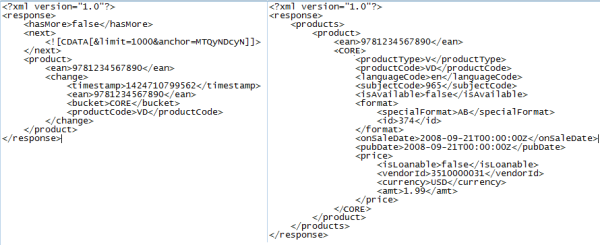
將記錄包裝在一個集合體(即\u0026lt;products\u0026gt;)內,並將每條記錄作為一個獨立的內容體(即\u0026lt;product\u0026gt;)進行儲存是一種常見的做法,儘管這一點並不總是成立。API也能夠幫助我們處理對大資料集進行重複式呼叫的問題(即分頁),其做法是提供一個對下一批資料(即\u0026lt;hasMore\u0026gt;與\u0026lt;next\u0026gt;)的連結,這種做法也十分普遍。這些模式能夠幫助我們在自己的引擎中打造泛用性的功能。為了在這些記錄中進行列舉,我們可以利用執行時環境中提供的底層機制來實現這一點。在本文的餘下部分中,我們將專注於.NET作為我們所選定的平臺。在這個案例中,.NET XPath庫與W3C XPath符號5為我們提供了在這些記錄間進行移動的必需功能。
\\在我們提供一種用以實現這套資料獲取引擎的後設資料之前,由於我們目前在討論的是原始的資料,因此我們應當趁此機會解決在法律方面的關注點。為了滿足對系統進行審計的人員的需求,我們應當將這些原始的資料持久化,以證實我們現有資料的真實性。我們接下來要建立一張表,它描述了我們的特定目標,此外還有一張表記錄了對我們的查詢所返回的API響應:
\\(點選放大影像)
\
這些資料不僅滿足了我們對於資料保留政策的需求,同時我們也有了一個潛在的健全性檢查工具,可以作為我們的資料處理管道中的第一個步驟。如果在之後的步驟中對於這個引擎的效能有任何疑問,我們都可以隨時檢查這個響應的“快照”,以確保我們正確地解析並載入了包含在響應中的值。
\\現在我們就具有了一個適當的基準線,我們終於可以設計這個後設資料了,它將用於對如何從指定的API中獲取資料進行配置。為了正確地執行以上描述的這個假想的流程,流程的第一步就是通過審計API獲取變更清單。有了這份變更清單之後,我們就可以獲取之前所描述的增量記錄了,可以選擇單獨獲取或批量獲取:
\\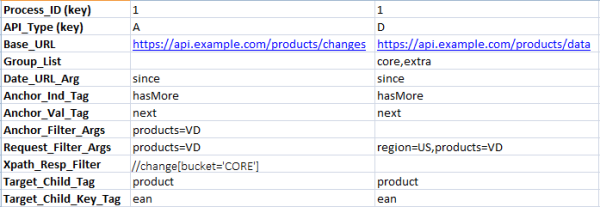
這個schema的原型與示例的行資料將成為我們為引擎進行後設資料驅動設計的第一步。它將試圖捕捉能夠驅動我們的軟體的抽象概念(正如領域驅動設計之父所說:“只有找到一組適用於所有細節的抽象概念後,工作才算成功6”)在這個示例中,型別’A’這一行表示獲取變更清單所必須的API配置資訊,而其它所有行中的值組成了我們用於進行實際資料檢索所需的配置。之前,我曾提到需要某種能力,通過重複式的呼叫獲取大資料集的內容。(儘管在XML中的內容所包含的資料集僅包含了一個增量資料,但在大多數情況下所指向的記錄集會大上許多)。我們已經有了對該URL進行第一次呼叫所需的後設資料了,並且’Anchor’列能夠幫助我們在一個大集合中進行列舉,以實現這些重複式的呼叫:
\\最初的Auditing API呼叫
\\http[s]://api.example.com/products/changes?since=1432746033000\u0026amp;products=VD
\\之後的Auditing API呼叫
\\http[s]://api.example.com/products/changes?limit=1000\u0026amp;anchor=MTQyNDcyN
\\這些後設資料不僅提供了用於生成URL的構建塊,我們現在還擁有了對API呼叫的響應內容進行解析與過濾的功能。作為一個小提示,我會建議你實現某個介面(例如IEnumerable),它會無縫地對響應內容中的資料進行列舉,並且將之後的API呼叫也作為整個列舉過程中的一部分。由於.NET平臺在這個示例中是我們的底層執行環境,因此這裡.NET XPath類庫就派上了用場。通過使用XPath符號查詢某個後設資料列(例如“Target_Child_Tag”和 “Target_Child_Key_Tag”)中的資料,我們就能夠在響應體中的記錄之間方便地跳轉,並獲取我們將進行處理的資料體。只需幾行程式碼,就能夠使用.NET LINQ功能獲取資料,並忽略響應體中我們並不感興趣的那部分資料:
\\List\u0026lt;Hashtable\u0026gt; CurrRecordList =\ (\ from tmp in CurrXmlResponse.Root.Elements(TargetChildTag)\ where tmp.XPathSelectElement(XPathRespFilter) != null\ \u0026amp;\u0026amp; tmp.XPathSelectElement(XPathRespFilter).Value != null\ select new Hashtable()\ {\ { targetChildKeyTag, tmp.Element(targetChildTag).Value }, \ { “body”, tmp.ToString() }\ }\ ).ToList();\\這個泛型功能允許我們將某個響應體中的記錄載入到某個容器之中。在審計API的情況下,這段LINQ程式碼的執行結果會生成一個列表,其中包括了我們的增量清單中的各個部分。而在資料API的情況下,這個結果列表將包含實際產品記錄的內容。這個變更清單容器的目的在於:它能夠作為一份指南,告訴我們應當通過資料API獲取哪些部分的產品記錄。不過,在資料記錄列表的情況下,我們還需要更多的說明。我們將如何處理這些資料?我們如何打造一套將這些資料持久化的機制?當然,我們需要進一步地實現後設資料驅動設計!
\\在這個架構遊戲中的倒數第二條功能就是將這些增量記錄指向它們最終的目的地。雖然我們可以選擇將這些增量記錄持久化到檔案系統(與變更清單一起)中,大多數企業系統都將資料庫選為他們的主要儲存機制,這一點應當不會令你感到吃驚。如果你只是需要顯示這些資料,那麼你可以選擇使用一種NoSQL資料庫,例如MongoDB以儲存這些增量記錄(甚至選擇儲存完整的原始響應資料),但由於查詢以及處理這些常見的需求,多數企業資料系統都會選擇將這些屬性分散儲存在關係型資料庫中的多張表中。在這種情況下,我們需要建立一系列後設資料,它們將幫助我們將增量記錄轉移到某個適當的預釋出區域:
\\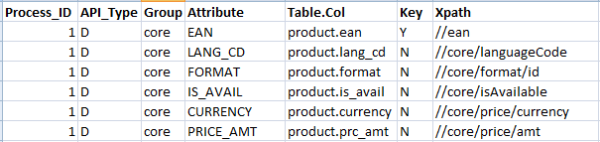
如果這套引擎的軟體實現足夠良好,我們還可以建立一個智慧的審計子系統,它能夠了解當資料進行這個預釋出區域時,將如何檢測變更並進行記錄。最重要的是,如果需要在記錄中加入額外的資料並進行持久化,只需方便地新增更多的行就可以了,這些改動對程式碼產生的修改要求減至了最低,甚至完全為零。
\\最後,我們還需要實現對這些響應記錄的歸檔操作。根據你的資料庫配置以及所預期的變更數量,可以合理地選擇暫時將這些記錄保留在響應體相應的表中,考慮到法律與所有權政策的迫切需求。不過,這些資料很有可能超出你的資料庫的空間限制,並且在相關人員進行查詢時會表現得很慢。在這種情況下,可以考慮其它幾種選擇。一種選擇是與一位DBA進行合作,共同建立一個對你的響應體表中的某些部分進行歸檔的策略。不過,在這種情況下,這個解決方案將不再屬於你的引擎的領域之內,同時也將脫離你的掌握範圍之外。對於不喜歡這種方式的其他人來說,還有一種替代方案。在過去幾年中,許多提供商都以合理的價格推出了資料歸檔服務(例如Microsoft Azure Backup)。雖然其中有些服務要求你安裝客戶端的軟體,但這種選擇能夠為你提供除了對資料進行簡單地歸檔之外的服務(例如資料恢復等等)。當然,這套API資料檢查引擎需要配合你的歸檔解決方案。在使用某些服務的情況下,該引擎或許要將原始的響應體搬到某個檔案系統中,通過它自動分發到遠端的地點。不過,只需要幾行後設資料與幾行程式碼,你就能夠充分利用這一服務,在你的引擎工作流中建立一種靈活的歸檔步驟。
\\不過,在我們開始感覺飄飄然之前,你或許該考慮到這種設計中缺乏了任何形式的保護機制。比方說,我們目前假設這套系統能夠以某種方式執行,也就是說這個API伺服器能夠提供指向一些增量記錄的變更清單。但是,如果今後這些變更的數量產生了變化,使我們目前的期望突然間變得與事實不符了呢?如果突然間產生了潮水般的變更數量,壓垮了我們的系統呢?又如果這個API伺服器突然間無法正常執行,開始了無限迴圈,不斷地傳送給我們相同的變更清單呢?在最後一種情況中,我們在潛在中也可能會無意間對API伺服器造成了一種DoS攻擊,而如果最終發現這個無意中產生的攻擊是來自於你的引擎本身,情況會變得更加嚴峻。這會令人感覺尷尬(至少可以這麼說),我們應該致力於避免這種情形,無論是出於技術原因還是政治上的原因。那麼為了避免這種情形出現,我們需要做些什麼呢?我們將再一次建立一個健壯的後設資料驅動解決方案,以幫助我們對應這些潛在的問題:
\\
當然,像“Email”與“開啟閥門”這樣的操作需要在你的引擎中實現,不過實現這些功能應當十分簡單。由於我們已經瞭解了領域模型,我們已有了足夠的業務知識,因而可以建立一些對問題場景進行量化的引數值,由此觸發應對這些問題的適當的回應。更重要的是,我們還可以簡單地對這些數值進行調整,以適應不斷變化的需求,因為隨著時間的推移,你的環境以及期望很可能會產生改變。
\\有了這套模型之後,我們就能夠實現一套架構,它對於已建立的IT部門來說是一種能夠令人心安的轉變。同時由於我們為通過API檢索到的資料保留了記錄快照,我們就能夠滿足管理者在法律問題以及心理上的需求。此外,一如既往,我們能夠在過程中採用敏捷,以進一步改善這個資料檢索引擎。如果你傾向於使用資料API(而不會產生一個相應的呼叫去獲取變更清單),那麼你完全可以選擇移除整個設計中關於變更清單的這一部分的功能,以及對應的程式碼。如果你還希望加入某種策略,使舊記錄能夠被自動移除,你也可以對設計進行迭代,加入另一個後設資料集(以及對應的程式碼)。這個新功能能夠基於某些數值,例如源標識以及已儲存記錄所允許存在的最長時間,將無效的記錄移除。無論在哪一種情況下,這種配置都能夠為資料檢查未來的需求提供一種靈活的設計。
\\關於作者
\\Aaron Kendall是一位居住在紐約的軟體工程師,在企業資料系統的設計與實現方面具有近20年的經驗。他剛開始是一位裝置驅動程式的開發者,隨後轉為專業軟體的開發者,在此過程中他表現出了對軟體設計及架構方面的熱情。他曾經在多個平臺上通過多種語言建立了具有創新性的商業解決方案,以及許多作為自由職業者建立的軟體專案,包括開源的軟體包,以及遊戲設計和移動應用。如果你想進一步瞭解他的工作,歡迎閱讀他在LinkedIn上的帳號以及他的部落格。
\\參考
\\- 美國證券交易委員會(2003年1月27日)最後規定:保留與審計和審查相關的記錄(Final Rule: Retention of Records Relevant to Audits and Reviews)17 CFR Part 210, RIN 3235-AI74\\
- Kendall, Aaron (2015年1月19日) 後設資料設計 —— 在設計與開發之間的一座敏捷橋樑\\
- Kendall, Aaron (2014年12月2日)如何在後設資料設計中整合Agile MetaDataDojo\\
- Amundsen, Mike (2014年12月7日)Web API設計方法論\\
- W3C (2008年9月)XML Path 語言 (XPath) Selectors RFC 5261\\
- Evans, Eric (2003年8月30日)領域驅動設計:軟體核心複雜性應對之道Addison-Wesley Professional\
檢視英文原文:Metadata-Driven Design: Designing a Flexible Engine for API Data Retrieval
相關文章
- 模型驅動設計(MDD)之靈活設計模型
- 資料驅動的介面設計
- 關於資料驅動設計的6個誤區
- LSM設計一個資料庫引擎資料庫
- 【資料庫設計】資料庫的設計資料庫
- 資料密集型應用儲存與檢索設計
- 設計更好的資料表格設計
- Salesforce和SAP Netweaver裡資料庫表的後設資料設計Salesforce資料庫
- 資料庫表設計之儲存引擎資料庫儲存引擎
- WebSphere adapters 7.0 讓您更靈活的開發後設資料WebAPT
- 關於資料過濾的設計
- 關於資料倉儲的設計!
- 靈活的查詢設計方案
- 我的理解——物件導向、事件驅動、後設資料物件事件
- 資料庫模型設計——主鍵的設計資料庫模型
- 資料庫設計資料庫
- 關於資料日誌的設計方案
- 資料驅動決策:決策智慧與設計思維
- 航班資訊查詢和檢索系統-資料結構課程設計資料結構
- 資料庫設計中使用設計模式資料庫設計模式
- 異地多活的資料一致性簡單設計
- 關於如何形成一個好的資料庫設計資料庫
- 關於一個資料庫列設計的問題資料庫
- 基於Hive進行數倉建設的資源後設資料資訊統計:Hive篇Hive
- 基於Hive進行數倉建設的資源後設資料資訊統計:Spark篇HiveSpark
- XML 程式設計思想: 學習物件後設資料(轉)XML程式設計物件
- IM 的資料庫設計資料庫
- 資料庫設計的流程資料庫
- 資料庫設計的折衷資料庫
- 資料治理--後設資料
- 如何進行“資料採集系統”的領域驅動設計
- 領域驅動設計與模型驅動設計的關係模型
- 資料庫設計---即資料庫架構設計的幾個步驟資料庫架構
- [譯] 微服務從設計到部署(五)事件驅動資料管理微服務事件
- 聊天資料表設計
- 資料庫設計技巧資料庫
- 資料庫表設計資料庫
- 資料庫原理-設計資料庫